Docker入门实战
写在前面的话
从2014年11月到现在,DockerOne已经成立了5个月。这5个月的时间里,我们为喜欢Docker的人们做了很多不大不小的事儿,翻译了很多大家喜欢的技术文章,正如当初建站的时候所说:我们要做最专业的Docker交流平台。Docker是一个可以让我为之热血沸腾的开源软件,为此,每天我都会给予Docker/DockerOne我10个多小时的时间,同时,也有很多的社区人在背后不懈地支持着我们。从一开始翻译Deis文档到现在,我所认识的是这样一群社区人,他们不求回报,他们不争你我,他们为Docker而沸腾,这让我深刻并且真切地感受到什么是社区。正如前几天我们有位译者对我说:我们聚集了一帮志同道合的人,总要干出点拿得出手的事。还有位译者说:要做就做到最好,要翻译就让它成为精品........
社区的力量是无穷的,截至目前,我们已经翻译了200余篇文章,内容涉及Docker、CoreOS、Kubernetes、OpenStack、Mesos、Yarn、Swarm、Machine、Cocker、CoreOS、Kubernetes、OpenStack、Mesos、Yarn、Swarm、Machine、Compose、Deis等,其中有新闻,有教程,有深度解读,我想我们真的是做了一件酷的不得了的事情!
当然,Docker在成长的过程中同样会面临一些问题,比如,网站内容组织不合理、翻译协作流程复杂等等。但是有一点是确认的,也是值得肯定的,那就是所有的问题终将不会是问题,一切都在变好!
网站内容组织不合理,我们已经开始解决了,思路是根据内容主题将相同的内容聚合到电子书中,以免费的形式送给读者。同时,为了帮助国内的Docker爱好者能更好的学习使用Docker,这本倾注我们心血的电子书《Docker入门实战》已经制作完成,这也是我们的第一本电子书。书的内容包括Docker指南、命名空间教程、Docker生态系统介绍、Dockerfile最佳实践、Swarm入门和Docker应用实战。如果你喜欢,就多多支持我们吧!
我们会用心,把这件事做好!
最后的最后,感谢那些可爱的译者们,田浩浩、陈杰、肖劲、左伟、叶可强、梁晓勇、王哲、郭蕾、崔婧雯、吴佳兴、隋鑫、吴锦晟 、钟最龙、孙科、路兴强、刘凯宁、张逸仙........
Docker终极指南
【编者的话】Docker入门的好文章,之前在微博上就有很多人推荐,也是2015年的新文章,DockerOne作了翻译。
Docker是一个相对较新且发展非常快速的项目,可用来创建非常轻量的“虚拟机”。注意,这里的引号非常重要,Docker创建的并非真正的虚拟机,而更像是打了激素的chroot,嗯,是大量的激素。
在我们继续之前,我先说下,截至目前(2015年1月4日),Docker只能在Linux上工作,暂不支持Windows或OSX(译者注:不直接支持)。我稍后会讲到Docker的架构,你会明白其中的原因。所以,如果想在非Linux平台上使用Docker,你需要在虚拟机里运行Linux。
本教程有三个目标:说明Docker解决的问题、说明它如何解决这个问题、以及说明它使用了哪些技术来解决这个问题。这不是一篇教你怎么运行安装Docker的教程,Docker此类教程已经有很多,包括Docker作者的在线互动教程(译者注:作者很喜欢在一个句子里引用多个链接,下同)。本文最后有一个步骤说明,目的是用一个明确的现实世界的例子来串联文章中所有的理论,但不会太过详细。
Docker能做什么?
Docker可以解决虚拟机能够解决的问题,同时也能够解决虚拟机由于资源要求过高而无法解决的问题。Docker能处理的事情包括:
• 隔离应用依赖
• 创建应用镜像并进行复制
• 创建容易分发的即启即用的应用
• 允许实例简单、快速地扩展
• 测试应用并随后销毁它们
Docker背后的想法是创建软件程序可移植的轻量容器,让其可以在任何安装了Docker的机器上运行,而不用关心底层操作系统,就像野心勃勃的造船者们成功创建了集装箱而不需要考虑装在哪种船舶上一样。
Docker究竟做了什么?
这一节我不会说明Docker使用了哪些技术来完成它的工作,或有什么具体的命令可用,这些放在了最后一节,这里我将说明的是Docker提供的资源和抽象。
Docker两个最重要的概念是镜像和容器。除此之外,链接和数据卷也很重要。我们先从镜像入手。
镜像
Docker的镜像类似虚拟机的快照,但更轻量,非常非常轻量(下节细说)。
创建Docker镜像有几种方式,多数是在一个现有镜像基础上创建新镜像,因为几乎你需要的任何东西都有了公共镜像,包括所有主流Linux发行版,你应该不会找不到你需要的镜像。不过,就算你想从头构建一个镜像,也有好几种方法。
要创建一个镜像,你可以拿一个镜像,对它进行修改来创建它的子镜像。实现前述目的的方式有两种:在一个文件中指定一个基础镜像及需要完成的修改;或通过“运行”一个镜像,对其进行修改并提交。不同方式各有优点,不过一般会使用文件来指定所做的变化。
镜像拥有唯一ID,以及一个供人阅读的名字和标签对。镜像可以命名为类似ubuntu:latest、ubuntu:precise、django:1.6、django:1.7等等。
容器
现在说容器了。你可以从镜像中创建容器,这等同于从快照中创建虚拟机,不过更轻量。应用是由容器运行的。
举个例子,你可以下载一个Ubuntu的镜像(有个叫docker registry的镜像公共仓库),通过安装Gunicorn和Django应用及其依赖项来完成对它的修改,然后从该镜像中创建一个容器,在它启动后运行你的应用。

容器与虚拟机一样,是隔离的(有一点要注意,我稍后会讨论到)。它们也拥有一个唯一ID和唯一的供人阅读的名字。容器对外公开服务是必要的,因此Docker允许公开容器的特定端口。
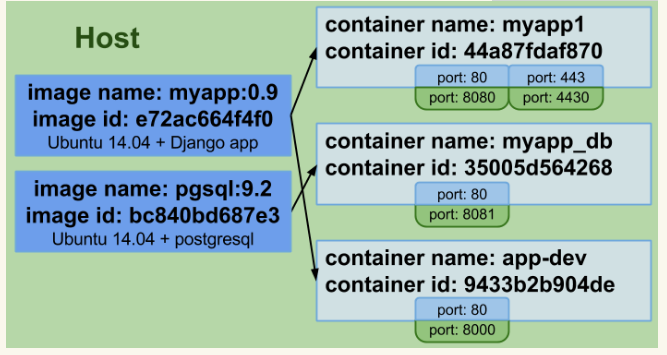
与虚拟机相比,容器有一个很大的差异,它们被设计用来运行单进程,无法很好地模拟一个完整的环境(如果那是你需要的,请看看LXC)。你可能会尝试运行runit或supervisord实例来启动多个进程,但(以我的愚见)这真的没有必要。
单进程与多进程之争非常精彩。你应该知道的是,Docker设计者极力推崇“一个容器一个进程的方式”,如果你要选择在一个容器中运行多个进程,那唯一情况是:出于调试目的,运行类似ssh的东西来访问运行中的容器,不过docker exec命令解决了这个问题。
【容器和虚拟机的第二个巨大差异是:当你停止一个虚拟机时,可能除了一些临时文件,没有文件会被删除;当你停止一个Docker容器,对初始状态(创建容器所用的镜像的状态)做的所有变化都会丢失。】(译者注:该论述不正确,已与作者确认,感谢lostsnow指正)
容器是设计来运行一个应用的,而非一台机器。你可能会把容器当虚拟机用,但如我们所见,你将失去很多的灵活性,因为Docker提供了用于分离应用与数据的工具,使得你可以快捷地更新运行中的代码/系统,而不影响数据。
数据卷
数据卷让你可以不受容器生命周期影响进行数据持久化。它们表现为容器内的空间,但实际保存在容器之外,从而允许你在不影响数据的情况下销毁、重建、修改、丢弃容器。Docker允许你定义应用部分和数据部分,并提供工具让你可以将它们分开。使用Docker时必须做出的最大思维变化之一就是:容器应该是短暂和一次性的。
卷是针对容器的,你可以使用同一个镜像创建多个容器并定义不同的卷。卷保存在运行Docker的宿主文件系统上,你可以指定卷存放的目录,或让Docker保存在默认位置。保存在其他类型文件系统上的都不是一个卷,稍后再具体说。
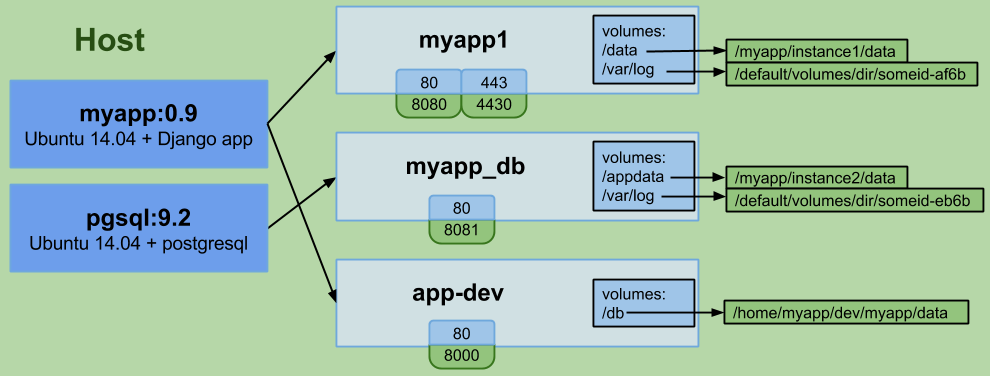
卷还可以用来在容器间共享数据,建议你阅读卷的文档做进一步了解。
链接
链接是Docker的另一个重要部分。
容器启动时,将被分配一个随机的私有IP,其它容器可以使用这个IP地址与其
进行通讯。这点非常重要,原因有二:一是它提供了容器间相互通信的渠道,二是容器将共享一个本地网络。我曾经碰到一个问题,在同一台机器上为两个客户启动两个elasticsearch容器,但保留集群名称为默认设置,结果这两台elasticsearch服务器立马变成了一个自主集群。注:限制容器间通讯是可行的,请阅读Docker的高级网络文档做进一步了解。
要开启容器间通讯,Docker允许你在创建一个新容器时引用其它现存容器,在你刚创建的容器里被引用的容器将获得一个(你指定的)别名。我们就说,这两个容器链接在了一起。
因此,如果DB容器已经在运行,我可以创建web服务器容器,并在创建时引用这个DB容器,给它一个别名,比如dbapp。在这个新建的web服务器容器里,我可以在任何时候使用主机名dbapp与DB容器进行通讯。
Docker更进一步,要求你声明容器在被链接时要开放哪些端口给其他容器,否则将没有端口可用。
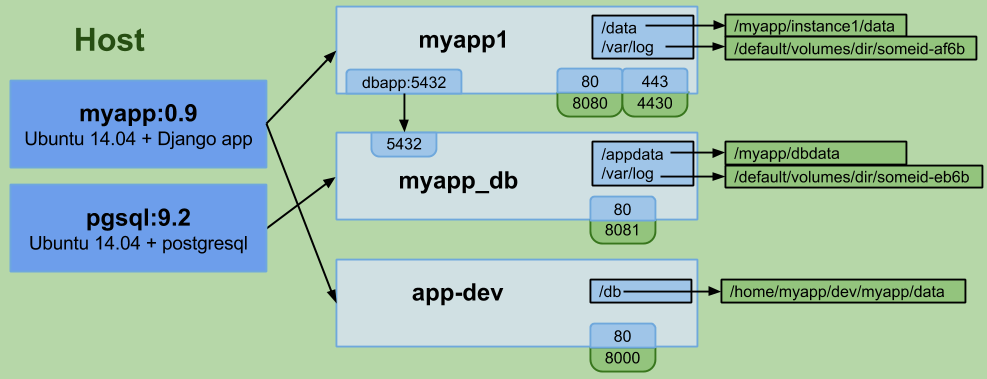
Docker镜像的可移植性
在创建镜像时有一点要注意。Docker允许你在一个镜像中指定卷和端口。从这个镜像创建的容器继承了这些设置。但是,Docker不允许你在镜像上指定任何不可移植的内容。
例如,你可以在镜像里定义卷,只要它们被保存在Docker使用的默认位置。这是因为如果你在宿主文件系统里指定了一个特定目录来保存卷,其他使用这个镜像的宿主无法保证这个目录是存在的。
你可以定义要公开的端口,但仅限那些在创建链接时公开给其他容器的端口,你不能指定公开给宿主的端口,因为你无从知晓使用那个镜像的宿主有哪些端口可用。
你也不能在镜像上定义链接。使用链接要求通过名字引用其他容器,但你无法预知每个使用那个镜像的宿主如何命名容器。
镜像必须完全可移植,Docker不允许例外。
以上就是主要的部分,创建镜像、用它们创建容器、在需要时暴露端口和创造卷、通过链接将几个容器连接在一起。不过,这一切如何能在不引起额外支出条件下达成?
Docker如何完成它需要完成的东西?
两个词:cgroups和union文件系统。Docker使用cgroup来提供容器隔离,而union文件系统用于保存镜像并使容器变得短暂。
Cgroups
这是Linux内核功能,它让两件事情变成可能:
[图片]限制Linux进程组的资源占用(内存、CPU)[图片]为进程组制作 PID、UTS、IPC、网络、用户及装载命名空间
这里的关键词是命名空间。比如说,一个PID命名空间允许它里面的进程使用隔离的PID,并与主PID命名空间独立开来,因此你可以在一个PID命名空间里拥有自己的PID为1的初始化进程。其他命名空间与此类似。然后你可以使用cgroup创建一个环境,进程可以在其中运行,并与操作系统的其他进程隔离开,但这里的关键点是这个环境上的进程使用的是已经加载和运行的内核,因此额外支出与运行其他进程几乎是一样的。Chroot之于cgroup就好像我之于绿巨人(The Hulk)、贝恩(Bane)和毒液(Venom)的组合(译者注:本文作者非常瘦弱,后三者都非常强壮)。
Union文件系统
Union文件系统允许通过union装载来达到一个分层的积累变化。在union文件系统里,文件系统可以被装载在其他文件系统之上,其结果就是一个分层的积累变化。每个装载的文件系统表示前一个文件系统之后的变化集合,就像是一个diff。
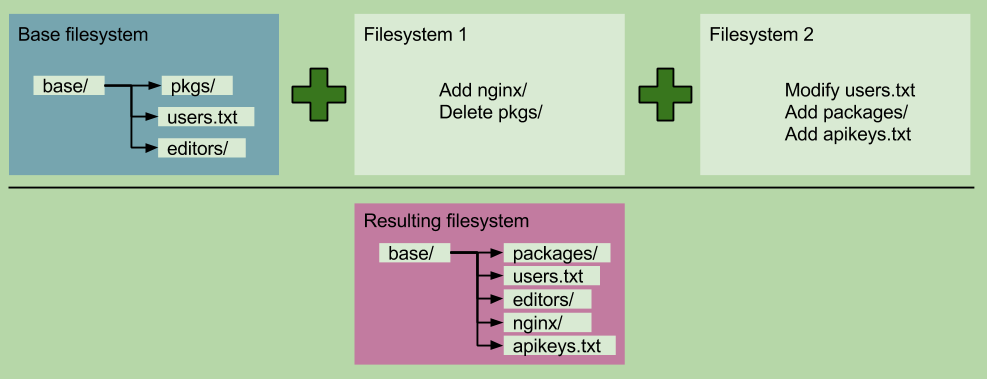
当你下载一个镜像,修改它,然后保存成新版本,你只是创建了加载在包裹基础镜像的初始层上的一个新的union文件系统。这使得Docker镜像非常轻,比如:你的DB、Nginx和Syslog镜像都可以共享同一个Ubuntu基础,每一个镜像保存的只是在它们需要的功能的基础上的变化。
截至2015年1月4日,Docker允许在union文件系统中使用aufs、btrfs或设备映射(device mapper)。
镜像
我们来看一下postgresql的一个镜像:

[{
"AppArmorProfile": "",
"Args": ["postgres"
],
"Config": {
"AttachStderr": true,
"AttachStdin": false,
"AttachStdout": true,
"Cmd": ["postgres"
],
"CpuShares": 0,
"Cpuset": "",
"Domainname": "",
"Entrypoint": [
"/docker-entrypoint.sh"
],
"Env": ["PATH=/usr/lib/postgresql/9.3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"LANG=en_US.utf8",
"PG_MAJOR=9.3",
"PG_VERSION=9.3.5-1.pgdg70 1",
"PGDATA=/var/lib/postgresql/data"
],
"ExposedPorts": {
"5432/tcp": {}
},
"Hostname": "6334a2022f21",
"Image": "postgres",
"MacAddress": "",
"Memory": 0,
"MemorySwap": 0,
"NetworkDisabled": false,
"OnBuild": null,
"OpenStdin": false,
"PortSpecs": null,
"StdinOnce": false,
"Tty": false,
"User": "",
"Volumes": {
"/var/lib/postgresql/data": {}
},
"WorkingDir": ""
},
"Created": "2015-01-03T23:56:12.354896658Z",
"Driver": "devicemapper",
"ExecDriver": "native-0.2",
"HostConfig": {
"Binds": null,
"CapAdd": null,
"CapDrop": null,
"ContainerIDFile": "",
"Devices": null,
"Dns": null,
"DnsSearch": null,
"ExtraHosts": null,
"IpcMode": "",
"Links": null,
"LxcConf": null,
"NetworkMode": "",
"PortBindings": null,
"Privileged": false,
"PublishAllPorts": false,
"RestartPolicy": {
"MaximumRetryCount": 0,
"Name": ""
},
"SecurityOpt": null,
"VolumesFrom": ["bestwebappever.dev.db-data"
]
},
"HostnamePath": "/mnt/docker/containers/6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da/hostname",
"HostsPath": "/mnt/docker/containers/6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da/hosts",
"Id": "6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da",
"Image": "aaab661c1e3e8da2d9fc6872986cbd7b9ec835dcd3886d37722f1133baa3d2db",
"MountLabel": "",
"Name": "/bestwebappever.dev.db",
"NetworkSettings": {
"Bridge": "docker0",
"Gateway": "172.17.42.1",
"IPAddress": "172.17.0.176",
"IPPrefixLen": 16,
"MacAddress": "02:42:ac:11:00:b0",
"PortMapping": null,
"Ports": {
"5432/tcp": null
}
},
"Path": "/docker-entrypoint.sh",
"ProcessLabel": "",
"ResolvConfPath": "/mnt/docker/containers/6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da/resolv.conf",
"State": {
"Error": "",
"ExitCode": 0,
"FinishedAt": "0001-01-01T00:00:00Z",
"OOMKilled": false,
"Paused": false,
"Pid": 21654,
"Restarting": false,
"Running": true,
"StartedAt": "2015-01-03T23:56:42.003405983Z"
},
"Volumes": {
"/var/lib/postgresql/data": "/mnt/docker/vfs/dir/5ac73c52ca86600a82e61279346dac0cb3e173b067ba9b219ea044023ca67561",
"postgresql_data": "/mnt/docker/vfs/dir/abace588b890e9f4adb604f633c280b9b5bed7d20285aac9cc81a84a2f556034"
},
"VolumesRW": {
"/var/lib/postgresql/data": true,
"postgresql_data": true 112
}
}
]
也就是说,镜像只是一个json,它指定了从该镜像运行的容器的特性,union装载点保存在哪里,要公开什么端口等等。每个镜像与一个union文件系统相关联,每个Docker上的union文件系统都有一个上层,就像是计算机科技树(不像其他树有一大堆的家族)。如果它看起来有点吓人或有些东西串不起来,不要担心,这只是出于教学目的,你并不会直接处理这些文件。
容器
容器之所以是短暂的,是因为当你从镜像上创建一个容器,Docker会创建一个空白的union文件系统加载在与该镜像关联的union文件系统之上。
由于union文件系统是空白的,这意味着没有变化会被应用到镜像的文件系统上,当你创建一些变化时,文件就能体现出来,但是当容器停止,该容器的union文件系统会被丢弃,留下的是你启动时的原始镜像文件系统。除非你创建一个新的镜像,或制作一个卷,你所做的变化在容器停止时都会消失。
卷所做的是在容器内指定一个目录,以便在union文件系统之外保存它。
这是一个bestwebappever的容器:
[{
"AppArmorProfile": "",
"Args": ["postgres"
],
"Config": {
"AttachStderr": true,
"AttachStdin": false,
"AttachStdout": true,
"Cmd": ["postgres"
],
"CpuShares": 0,
"Cpuset": "",
"Domainname": "",
"Entrypoint": [
"/docker-entrypoint.sh"
],
"Env": ["PATH=/usr/lib/postgresql/9.3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"LANG=en_US.utf8",
"PG_MAJOR=9.3",
"PG_VERSION=9.3.5-1.pgdg70 1",
"PGDATA=/var/lib/postgresql/data"
],
"ExposedPorts": {
"5432/tcp": {}
},
"Hostname": "6334a2022f21",
"Image": "postgres",
"MacAddress": "",
"Memory": 0,
"MemorySwap": 0,
"NetworkDisabled": false,
"OnBuild": null,
"OpenStdin": false,
"PortSpecs": null,
"StdinOnce": false,
"Tty": false,
"User": "",
"Volumes": {
"/var/lib/postgresql/data": {}
},
"WorkingDir": ""
},
"Created": "2015-01-03T23:56:12.354896658Z",
"Driver": "devicemapper",
"ExecDriver": "native-0.2",
"HostConfig": {
"Binds": null,
"CapAdd": null,
"CapDrop": null,
"ContainerIDFile": "",
"Devices": null,
"Dns": null,
"DnsSearch": null,
"ExtraHosts": null,
"IpcMode": "",
"Links": null,
"LxcConf": null,
"NetworkMode": "",
"PortBindings": null,
"Privileged": false,
"PublishAllPorts": false,
"RestartPolicy": {
"MaximumRetryCount": 0,
"Name": ""
},
"SecurityOpt": null,
"VolumesFrom": ["bestwebappever.dev.db-data"
]
},
"HostnamePath": "/mnt/docker/containers/6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da/hostname",
"HostsPath": "/mnt/docker/containers/6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da/hosts",
"Id": "6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da",
"Image": "aaab661c1e3e8da2d9fc6872986cbd7b9ec835dcd3886d37722f1133baa3d2db",
"MountLabel": "",
"Name": "/bestwebappever.dev.db",
"NetworkSettings": {
"Bridge": "docker0",
"Gateway": "172.17.42.1",
"IPAddress": "172.17.0.176",
"IPPrefixLen": 16,
"MacAddress": "02:42:ac:11:00:b0",
"PortMapping": null,
"Ports": {
"5432/tcp": null
}
},
"Path": "/docker-entrypoint.sh",
"ProcessLabel": "",
"ResolvConfPath": "/mnt/docker/containers/6334a2022f213f9534b45df33c64437081a38d50c7f462692b019185b8cbc6da/resolv.conf",
"State": {
"Error": "",
"ExitCode": 0,
"FinishedAt": "0001-01-01T00:00:00Z",
"OOMKilled": false,
"Paused": false,
"Pid": 21654,
"Restarting": false,
"Running": true,
"StartedAt": "2015-01-03T23:56:42.003405983Z"
},
"Volumes": {
"/var/lib/postgresql/data": "/mnt/docker/vfs/dir/5ac73c52ca86600a82e61279346dac0cb3e173b067ba9b219ea044023ca67561",
"postgresql_data": "/mnt/docker/vfs/dir/abace588b890e9f4adb604f633c280b9b5bed7d20285aac9cc81a84a2f556034"
},
"VolumesRW": {
"/var/lib/postgresql/data": true,
"postgresql_data": true 112
}
}
]
卷基本上与镜像相同,不过现在还指定了一些公开给宿主的端口,也声明了卷位于宿主的位置,容器状态是从现在直到结束,等等。与前面一样,如果它看起来让人生畏,不要担心,你不会直接处理这些json。
超级、无比简单的步骤说明
第一步,安装Docker。
Docker命令工具需要root权限才能工作。你可以将你的用户放入docker组来避免每次都要使用sudo。
第二步,使用以下命令从公共registry下载一个镜像:
$ > docker pull ubuntu: latest
ubuntu: latest: The image you are pulling has been verified
b363fd9d7da: Pull complete
.... < bunch of downloading - stuff output > .....
8e aa4ff06b53: Pull complete
Status: Downloaded newer imagefor ubuntu: latest
$ >
这个公共registry上有你需要的几乎所有东西的镜像:Ubuntu、Fedora、Postgresql、MySQL、Jenkins、Elasticsearch、Redis等等。Docker开发人员在这个公共registry里维护着数个镜像,不过你能从上面拉取大量来自用户发布的自建镜像。
也许你需要或想要一个私有的registry(用于开发应用之类的容器),你可以先看看这个。现在,有好几个方式可以设置你自己的私有registry。你也可以买一个。
第三步,列出你的镜像:

第四步,从该镜像上创建一个容器。

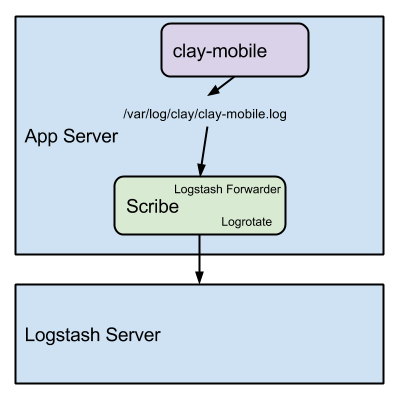
注意logstash-forwarder不会rotate(分割)日志,日志ratation是一个将老的日志按照大小或者日期存储到buckets的过程,做这项工作的工具是[logrotate]
(http://linuxcommand.org/man_pages/logrotate8.html)。
Logstash进程会运行ElasticSearch和Kibana来分析日志,ElasticSearch支持多条件查询和过滤日志数据。
注意你不能对外公开ElasticSearch的端口,以免服务器遭受攻击。我们就曾经被攻击过,解决方案是将我们的基础架构迁移到Amazon VPC,这样所有的服务都在内网环境中。
Journalist + Scribe
我们已经开源了我们的Docker容器,这样所有人都可以在几秒钟内构建一个分布式的日志系统。
Logstash Server:clay/journalist-public
Logstash-forwarder Server:clay/scribe-public
10x系列之Docker在Clay.io
【编者的话】近日,Clay.io的Zoli Kahan开始了“10X”系列博文的撰写。通过这个系列博文,Zoli将分享如何只使用一个很小的团队支撑Clay.io的大规模应用。本文是整个系列的第三篇,DockerOne接下来将会对整个系列文章进行翻译。
简介
在Clay,我们的部署过程非常有趣。真的!因为我们使用Docker。Docker是一个用于简化应用隔离与部署的容器化工具。其基本思路是,Docker会在一个虚拟的隔离环境中运行你的应用,这有点像虚拟机,但没有额外开销。你以一个“基础镜像”起步,然后使用一个Dockerfile描述如何创建一个“容器”。
综述

我们的部署过程是这样的:
• 将所有要发布的代码合并到git的master分支
• 用git tag打上发布标签(比如 v1.0.0)
• 构建Docker镜像(代码锁定)
• 用docker tag打上发布标签(比如 v1.0.0)
• 将Docker镜像推送到registry
• 更新集群容器版本(零停机)
• 确认备用容器正在运行
• 升级主容器
• 等待新的主容器上线
• 升级备用容器
• 更新生产集群容器版本(零停机)
这个过程确保了在过渡环境和生产环境中运行的是完全相同的代码,同时允许我们在发生错误时回滚到上一个Docker容器发布版本。
Clay.io的Dockerfile
这是来自我们的移动应用的一个示例Dockerfile(源码):
1 FROM dockerfile / nodejs: latest
2Install Git
3
4 RUN apt - get install - y git
5 Add source
6
7 ADD. / node_modules / opt / clay - mobile / node_modules
8 ADD. / opt / clay - mobile
9
10 WORKDIR / opt / clay - mobile
11 Install app deps
12
13 RUN npm install
14
15 CMD["npm", "start"]
这个文件不言自明。它只是简单的从当前目录复制源码到容器中。环境变量将用于引入敏感的或动态的配置。重点说明一下:npm start实际上是在为生产环境编译并压缩代码:
// package.json
{
"scripts": {
"build": "node_modules/gulp/bin/gulp.js build"
"start": "npm run build &&
. / node_modules / pm2 / bin / pm2 start. / bin / server.coffee -
i max 8--name clay_mobile
--no - daemon -
o /
var / log / clay / clay_mobile.log -
e /
var / log / clay / clay_mobile.error.log ",
}
}
这是因为我们需要使用生产环境变量重新构建静态文件。请访问我们的GitHub查看更多示例:github.com/clay.io。
Docker镜像的基本部署
在Clay,我们将镜像托管在docker registry上。
因为Docker,部署我们的应用到过渡环境和生产环境中非常简单。整个过程(从未标记容器,到过渡环境,由Ansible自动完成)如下:
Local machine / Build server
docker build - t clay / mobile.
docker push clay / mobile
Staging / Production server
docker pull clay / mobile
docker run
--restart on - failure -
v /
var / log / clay: /var/log / clay -
p 50000: 3000 -
e CLAY_MOBILE_HOST = XXXX -
e CLAY_API_URL = XXXX -
e FC_API_URL = XXXX -
e NODE_ENV = production -
e PORT = 3000
--name mobile -
d -
t clay / mobile: VERSION
(注意:49,152 - 65,535端口通常用于私有应用)
零停机更新
你可能注意到在上述启动脚本中,我们使用PM2来处理集群多个服务器进程。PM2支持零停机更新,不过因为它存在于容器内,而我们从不在运行时修改容器内代码,所以我们没使用这个功能。PM2只是单纯的用于获取多个服务器的核心。
零停机更新的关键点在于运行两个服务器进程。一个主进程和一个备用进程。我们通过给两个容器部署分配不同的端口实现这一点:
docker run ... -e PORT=50000 --name mobile
docker run ... -e PORT=50001 --name mobile-backup
HAProxy负责在主服务器宕机时将流量重分配到备用服务器上:
example haproxy.cfg
backend mobile
mode http
balance roundrobin
server app1 x.x.x.x: 50000 check
server app1b x.x.x.x: 50001 check backup
server app2 x.x.x.x: 50000 check
server app2b x.x.x.x: 50001 check backup
后续将有篇关于HAProxy的文章,介绍更多关于我们是如何使用HAProxy在服务器间进行负载均衡的详情。
1.确认备用健康容器状态(Ansible)
2.docker pull clay/mobile:v1.0.0
3.杀死主容器(网络请求自动重分配到备用服务器)
4.docker rm -f mobile更新
5.更新主容器,并重启
6.docker run ...
7.一旦主容器恢复,网络请求将移回到主服务器
8.杀死并更新备用容器
9.docker rm -f mobile-backup && docker run ...
如果发生了任何错误,只要简单的恢复到上一个镜像版本:
docker run -t clay/mobile:v0.0.12
10x系列之Clay.io的服务发现
【编者的话】Clay.io的Zoli Kahan撰写了“10X”系列博文,分享如何只使用一个很小的团队支撑Clay.io的大规模应用。本文是整个系列的第四篇,介绍如何构建一个服务发现系统。
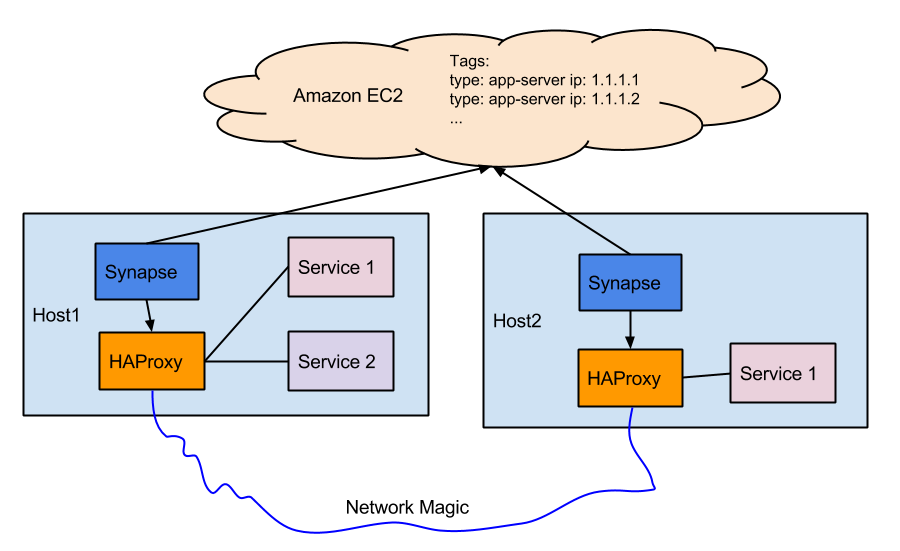
架构
面向服务的架构是构建绝大多数产品的最可迭代和可用的软件配置之一。这些系统也遇到过很多问题,其中最大的问题可能就是服务发现问题。服务发现实际定义了你的服务如何与其它服务通信。Docker里也有这个问题。
教程
Synapse(https://github.com/claydotio/synapse)是一个动态配置本地HAproxy的后台程序。HAproxy负责在集群内将请求转发到服务,它会根据配置文件的定义,寻找Amazon EC2(或其它)服务。我们用的是ec2tag,可以很容易地通过标签化服务器将其添加到集群。
HAProxy
让我们从服务入手。服务之间通过本地的HAProxy实例互相通信。因为服务运行在Docker内部,我们需要为服务指定宿主IP在某个特定端口寻找服务。
我们使用Ansible将本地IP和端口传给运行在机器上的服务。
SERVICE_API=http://{ ansible_default_ipv4.address }:{ service_port }
对于要使用其它服务的服务,只需要简单地调用IP/端口。这里的关键点是IP是本地机器的IP,它可以被HAProxy处理。我们发布了一个HAProxy docker容器,它监控挂载着的配置文件,在有变化时自动更新:
https://github.com/claydotio/haproxy
docker run
--restart always
--name haproxy
-
v /
var / log: /var/log -
v / etc / haproxy: /etc/haproxy -
d -
p 50001: 50001 -
p 50002: 50002 -
p 50003: 50003 -
p 50004: 50004
...
-p 1937: 1937 -
t clay / haproxy
我们默认在/etc/haproxy 使用noop config,它会挂载到Docker容器中并监控变化。我们也会将相同的HAproxy config挂载到Synapse容器。需要注意的是,如果这个容器关闭了,机器上的所有服务就不会被其它服务发现。因此,我们给容器也分配了另外的端口以供未来的新服务使用(因为无法被动态分配)。
Synapse
好了,现在开始搭建Synapse。
Synapse的运行很简单(归功于公共Docker容器库)。
docker run
--restart always
--name synapse
-
v /
var / log: /var/log -
v / etc / synapse: /etc/synapse -
v / etc / haproxy: /etc/haproxy -
e AWS_ACCESS_KEY_ID = XXX -
e AWS_SECRET_ACCESS_KEY = XXX -
e AWS_REGION = XXX -
d -
t clay / synapse
synapse - c / etc / synapse / synapse.conf.json
注意我们如何在容器里挂载Synapse config以及HAproxy config。HAProxy配置就是上文提到的noop config(因为其会由Synapse自动生成),我们来看看如何配置Synapse。
配置Synapse有些难,因为文档写得不是很好。如下是示例配置,可以解释所有文档里缺失的信息:
{
"services": {
"myservice": {
"discovery": {
// use amazon ec2 tags
"method": "ec2tag",
"tag_name": "servicename",
"tag_value": "true",
// if this is too low, Amazon will rate-limit and block requests
"check_interval": 120.0
},
"haproxy": {
// This is the port other services will use to talk to this service
// e.g. http://10.0.1.10:50003
"port": 50003,
"listen": [
"mode http"
],
// This is the port that the service exposes itself
"server_port_override": "50001",
// This is our custom (non-documented) config for our backup server
// See http://zolmeister.com/2014/12/10x-docker-at-clay-io.html
// for details on how our zero-downtime deploys work
"server_backup_port": "50002",
"server_options": "check"
}
}
},
// See the manual for details on parameters:
// http://cbonte.github.io/haproxy-dconv/configuration-1.5.html
"haproxy": {
// This is never used because HAProxy runs in a separate container
// Reloads happen automatically via the file-watcher
"reload_command": "echo noop",
"config_file_path": "/etc/haproxy/haproxy.cfg",
"socket_file_path": "/var/haproxy/stats.sock",
"do_writes": true,
"do_reloads": true,
"do_socket": false,
// By default, this is localhost, however because HAProxy is running
// inside of a container, we need to expose it to the host machine
"bind_address": "0.0.0.0",
"global": [
"daemon",
"user haproxy",
"group haproxy",
"chroot /var/lib/haproxy",
"maxconn 4096",
"log 127.0.0.1 local0",
"log 127.0.0.1 local1 notice"
],
"defaults": [
"log global",
"mode http",
"maxconn 2000",
"retries 3",
"timeout connect 5s",
"timeout client 1m",
"timeout server 1m",
"option redispatch",
"balance roundrobin",
"default-server inter 2s rise 3 fall 2",
"option dontlognull",
"option dontlog-normal"
],
"extra_sections": {
"listen stats :1937": [
"stats enable",
"stats uri /", "stats realm Haproxy Statistics"
]
}
}
结论
特别感谢Airbnb开源了他们的工具,这使得我们可以以简单可扩展的方式搭建服务发现系统。对于没有使用Amazon EC2的人,可以使用Zookeeper watcher(我们没有到),或者即将可以使用的etcd watcher。
一旦代码被合并,我们可能会选择使用Nerve和etcd替代EC2标签,来发布服务。以下etcd示例的Docker信息仅供参考:
curl https: //discovery.etcd.io/new?size=3
docker run
--restart always
--name etcd -
d -
p 2379: 2379 -
p 2380: 2380 -
v / opt / etcd: /opt/etcd -
v /
var / log: /var/log -
v / etc / ssl / certs: /etc/ssl / certs
quay.io / coreos / etcd: v2 .0 .0 -
data - dir / opt / etcd -
name etcd - unique - name -
listen - client - urls http: //0.0.0.0:2379
-listen - peer - urls http: //0.0.0.0:2380
-advertise - client - urls http: //localhost:2379
-initial - advertise - peer - urls http: //localhost:2380
-discovery https: //discovery.etcd.io/XXXXXXXXXXXX
-initial - cluster - token cluster - token - here
Shopify的Docker实战经验(一)用Docker和CoreOS构建内部云
【编者的话】Shopify是一个电子商务平台,提供专业的网上店面。目前的客户超过12万,包括GE、特斯拉汽车、GitHub等。作为首家市值超过10亿美元的加拿大网络公司,Shopify在欧美市场的影响力也与日俱增。Shopify是一个大型的Ruby on Rails应用,其产品服务器能通过给1700个处理核心和6TB RAM分配任务来完成每秒处理8000多个请求。Shopify在其博客上分享了系列内容来介绍他们的Docker使用经验。
这是系列文章的第一篇,介绍我们如何借助容器让服务器更易于扩展和管理,从而跟上业务需求的步伐。

关键元素是:
1.Docker:容器技术,使应用更加便携和易于管理
2.CoreOS:提供最小化的操作系统,便于流程规划和Docker容器的运行
Shopify是一个大型的Ruby on Rails应用程序,这些年底层做过大规模的扩
展。我们的生产服务器扩容到使用1700个核以及6 TB内存,能支持每秒超过8000次的请求。
Docker备受瞩目,因为它能够将应用打包进便携的容器,从而实现版本控制和快速部署。
容器听上去很像虚拟机(virtual machine,VM),它有独立的文件系统、网络环境等等。但是容器又比虚拟机更加轻量,能够更高效地利用硬件资源。Docker容器不是像VM一样去模拟物理硬件的行为,而是允许多个应用程序安全地共享Linux宿主机器,通过:
1.内核命名空间使应用间相互隔离
2.cgroups限制资源的上限并实现计费
3.多层文件系统减少容器的大小
Docker在开发和维护团队中迅速走红,主要是因为:
1.超高利用率:容器最大限度地共享宿主机器(比如,单核机器),相比VM能更为有效地利用硬件资源。这意味着在同样的硬件配置上可以运行更多应用。
2.快速启动:容器可以快速启动和运行,只需要几秒时间。如果需要,可以利用容器构建的时间做一些其他耗时的操作。快速启动意味着快速部署。
3.一致性:容器确保每个实例启动时是完全一致。
4.开发友好的工作流:容器由纯文本的Dockerfile构建,Dockerfile可以做版本控制从而帮助区分容器版本。另外,开发人员可以用很熟悉很像git的push/pull操作来发布容器。
5.运维友好的工作流:容器包含操作系统,因此,如果你需要安装一个package或者自定义的配置,开发人员就可以完成这项工作,而不需要推给运维人员。这是工作职责的重要改变:开发人员负责容器,运维人员则可以关注于提供可靠的硬件和网络。
最重要的容器特性是可以实现一机多用。做不同工作的容器可以在相同的硬件系统上和平共处。这使得数据中心真正成为普遍意义上的计算资源。比如:
1.可以很快很容易地增加应用服务器容器的数量,这意味着我们随时可以应对突然的流量尖峰。
2.可以轻松地拿出生产服务器的闲置资源去进行所需资源密集型的操作,比如数据分析。
听上去不可抗拒吧?我们也有同感,而且我们已经准备来分享我们的经验,如何将这些愿景变为生产级别的现实。我们不仅仅高谈阔论,我们还会在社区里分享尽可能多的代码。
这里有很多内容可以讲,我们将分期介绍:
1.容器化:如何以一种能让自以为是的开发团队满意的方式,将已有的应用放到容器里?
2.管理诀窍:真实的应用包括很多API秘钥和数据库密码,这些都需要安全得保存(最好是能版本控制,并能在Heartbleed这样的事件再次发生的时候迅速把它们找出来)。我们在这里有不错的解决方案。
1.路由:怎样将容器连接到外部世界,并能和生产环境的基础架构(比如负载均衡器)完美合作?
2.监控:我们的容器化架构需要达到或者超越Shopify的99.97%的在线时长。维护系统时需要花费大量的工作,在问题变得严重之前发现并解决它。在容器化的世界里解决这个问题需要和纯物理机环境不同的解决方案。调整已有的监控系统来监控新环境是保证Shopify稳定性的重要环节。
3.健壮性:优雅且可预见地抛错很难。我们在处理内存耗尽(out-of-memory),请求队列化和signal处理上的经验可以供大家参考。
4.部署:我们的系统构建在Chef和Ubuntu之上,现在计划更新为纯物理机上的CoreOS。之后会介绍我们如何部署节点使其能够运行容器,并且在全是容器的世界里实现高效监控。
Shopify的Docker实战经验(二)如何用容器支持10万的在线商店
【编者的话】Shopify是一个电子商务平台,提供专业的网上店面。目前的客户超过12万,包括GE、特斯拉汽车、GitHub等。作为首家市值超过10亿美元的加拿大网络公司,Shopify在欧美市场的影响力也与日俱增。Shopify是一个大型的Ruby on Rails应用,其产品服务器能通过给1700个处理核心和6TB RAM分配任务来完成每秒处理8000多个请求。Shopify在其博客上分享了系列内容来介绍他们的Docker使用经验。

这是系列文章的第二篇,讲述Shopify如何使用Docker来支撑容器化的数据中心。这篇文章重点介绍当用户访问Shopify商店门户的时候我们底层的生产环境是如何创建出容器的。
为什么选择容器化?
在深入讨论构建容器的原理之前,先讨论下我们的动机。容器对于数据中心的作用可能类似于控制台对于游戏的作用。在PC游戏发展的早期阶段,游戏在玩之前一般都会要求显卡和声卡驱动massaging。然而,游戏控制台提供了不一样的方式:
1.可预测:cartridge是自包含的:随时可用,无需下载或更新。
2.快速:cartridge使用只读内存,所以可以非常快。
3.简易:cartridge健壮并且被大范围证明 - 仅需插上即可游戏。
可预测、快速、简易都是闪亮的优点。Docker容器提供了构建模块,可以将应用放到自包含,随时可运行的单元里,这样使得运行数据中心更为简单,也更加灵活,就像cartridge带给控制台游戏的改进一样。
Bootstrapping
要完成容器化的转变需要开发和运维双方面的配合。首先,需要和运维团队沟通,确保容器能够完全复制现在的生产环境。
如果你在OSX(或者Windows)上运行,部署到Linux上,需要使用虚拟机,比如Vagrant作为本地的测试环境。首先需要得到操作系统信息和其上需要安装的支持包。选择符合生产环境(我们用的是Ubuntu 14.04)的基础镜像,拒绝任何非紧急的系统升级请求,谁都不想同时既进行容器化改进又要升级操作系统/包。
选择容器封装格式
Docker提供封装格式的选择,从“纤薄”单进程容器到更像传统意义虚拟机的“胖”容器(比如,Phusion)。
我们选择了“纤薄”容器路径,并尽量隔绝外部影响。在这两种封装格式之间很难做决定,但是更小、更简单的容器消耗的CPU和内存更少。Docker官方博客上有这种解决方案更为详细的介绍。
环境搭建
我们使用Chef管理生产节点。虽然可以简单地在容器内部运行Chef,但是这会带进一些不想复制到每个容器里的服务(比如,日志索引和stats收集)。与其忍受重复,倒不如给每个Docker主机共享一个单独的这些服务的拷贝。
构建“纤薄”容器的路径要求把Chef请求转换成Dockerfile(后来我们更换成了自定义的构建流程 - 不过这在另一篇文章里讨论)。这样的转换也给了我们很好的机会去审查生产环境并记录下真正需要的东西(可能需要些考古学知识)。尽可能的删除不需要的东西,并且在这一阶段安排尽可能多的代码审查。
这个过程其实没有听上去那么痛苦。我们最后得到了一个125行,包含很多注释的Dockerfile,它定义了Shopify所有容器共享的基础镜像。这个基础镜像包含25个包,涉及各种编程语言的运行环境(Ruby、Python、Node),开发工具(Git、Vim、Build-essential、Go)和一些常用库。它还包括完成一些任务的实用脚本,比如,用优化的参数启动Ruby,或者给Datadog发送事件。
应用程序也可以向这个基础镜像添加特殊的需求。即使这样,我们最大的应用程序也只是另外添加了两个操作系统包,因此我们的基础镜像是非常精简的。
100法则
当选择将什么服务放到容器里时,先假定在一台主机上运行了100个小容器,然后,问自己是否真的需要运行100个这样的服务,还是最好只共享一台主机的服务。
以下是一些实际的例子,展示100法则如何影响我们的容器:
1.日志索引:日志对于诊断生产环境问题至关重要,在容器化的世界里更为重要,因为文件系统在容器退出后就消失了。我们尽量不要改变应用自己的日志行为(比如强制应用日志重新定向到syslog中),而是应该允许应用继续记录日志到文件系统里。运行100个日志传递代理看上去并不合理,因此我们构建了一个后台程序来处理一些核心任务:
1.在宿主机器上运行,并订阅Docker事件
2.当容器启动时,配置日志索引器监控容器
3.当容器销毁时,移除索引指令
注意有时在容器退出后需要延迟容器的销毁从而确保所有的日志都建立了索引。
1.统计:Shopify进行多个层级的运行统计:系统,中间件和应用层面。统计数据通常是由代理转发或者从应用代码里直接发出。
2.我们大部分统计数据是由StatsD收集的,也很幸运地能配置主机端的Datadog收集器来接受容器的消息(比如,网络流量和代理配置)。因为有这些配置,只需要将StatsD的地址转发到容器里就可以了。
3.主机端系统监控代理能够跨越容器界限,因为容器归根到底就是个进程树。因此可以共享一个系统监控器。
4.从以容器为中心的视角看,要考虑Datadog的Docker集成,这样可以将Docker矩阵加入到主机端的监控代理上。
5.应用级别上,大部分情况都可以工作,因为它们要么想要发送事件给StatsD,要么直接和其他服务通信。定义容器的名字很重要,这样日志里才会记录下有效名字。
6.Kafka:我们使用Kafka作为事件总线将Shopify的实时事件传送到感兴趣的组件里。构建消息并将其放置到SysV消息队列,这样可以将Ruby on Rails里的Kafka事件发布出去。一个简单的用Go写的后台程序会清空队列并且发送消息给Kafka。这样的架构减少了Ruby处理时间,帮助我们很好地解决了Kafka服务器过载的问题。不幸的是,SysV消息队列是IPC命名空间的一部分,所以我们无法为容器使用队列:主机连接。我们通过给主机添加了一个socket接入点,使用它将消息放到SysV队列里来解决了这个问题。当然,我们需要将这个接入点的地址通过Kafka:我们使用Kafka作为事件总线将Shopify的实时事件传送到感兴趣的组件里。构建消息并将其放置到SysV消息队列,这样可以将Ruby on Rails里的Kafka事件发布出去。一个简单的用Go写的后台程序会清空队列并且发送消息给Kafka。这样的架构减少了Ruby处理时间,帮助我们很好地解决了Kafka服务器过载的问题。不幸的是,SysV消息队列是IPC命名空间的一部分,所以我们无法为容器使用队列:主机连接。我们通过给主机添加了一个socket接入点,使用它将消息放到SysV队列里来解决了这个问题。当然,我们需要将这个接入点的地址通过息放到SysV队列里来解决了这个问题。当然,我们需要将这个接入点的地址通过环境变量传递给容器。另外一篇文章详细介绍了这个问题。
容器化应用
环境搭好后,接下来需要关注容器化应用本身。
在Shopify里,我们倾向于只做一件事情的“纤薄”容器,比如unicorn master和响应web请求的worker,或者响应某个特定队列的Resque worker。“纤薄”容器允许细粒度按需扩展。比如,可以增加Resque worker的数量来检查蠕虫从而应对攻击。
我们总结了一些将代码放到容器里的标准原则:
1.根目录始终在容器/app目录下的应用
2.服务公开在单一端口的应用
我们也发现一些git仓库适合被容器化:
1./container/files 包含的文件树是在容器构建时直接拷贝过来的。比如,请求某个应用日志的Splunk索引/container/files/etc/splunk.d/inputs.conf 文件指向git仓库。注意:这是一个微妙且重要的职责转换 - 开发人员现在控制日志索引,而以前这是属于运维领域的事情。
2./container/complie是编译应用的shell脚本,它输出随时可运行的容器。构建这个文件并且适应自己的应用是很复杂的。
3./container/roles.json包含执行工作的命令行,以机器语言存在。很多应用用多个角色运行同一段代码 - 一些在处理后台任务时处理web消息。这一部分是受Heroku的procfile启发。这里有个roles.json示例。Heroku的procfile启发。这里有个roles.json示例。
我们用一个也能在本地运行的简单的Makefile构建build。Dockerfile看上去像:
记住编译阶段的目的是输出一个即刻可用的容器。Docker的重要优点之一就是极快的启动时间,尽量不要在容器启动时做额外的工作从而延长启动时间。为了达到这个目标,我们需要理解整个部署流程。一些例子说明:
1.使用Capistrano将代码部署到机器上,组件编译已经在部署过程中完成了。将组件编译挪到容器构建过程中进行,使得部署新的代码仅仅需要几分钟,简单快速。
2.Unicorn master启动时需要询问数据库得到表类型。这不仅仅很慢,而且很小的容器空间意味着需要更多的数据库连接。所以,可以考虑在容器构建的同时来做这个从而降低启动时间。
我们的编译环节包括以下逻辑步骤:
1.bundle安装
2.组件编译
3.数据库启动
注意:为了控制这篇文章的篇幅,我们简化了一些细节,没有在此讨论管理诀窍,没有将其签入源代码控制系统。很快会有一片文章重点讨论这个问题。
调试及其细节
在大多数情况下,应用运行在容器里时的行为和它运行在非容器化环境下没有什么不同。因此,大多数我们标准的调试技术(strace、gdb、/proc文件系统)在Docker宿主机上也都适用。
一个需要额外注意的工具是:nsenter或者nsinit,它让大家可以连接到一个正在运行的容器里去调试。Docker 1.3里有一个新的docer exec工具,可以将一个进程注入到正在运行的容器里。不幸的是,如果你想要注入的进程有root权限,还是需要nsenter。
还有些领域没能像预期那样工作,包括:
进程层次结构
尽管我们运行的是瘦容器,也始终会有一个init进程(pid=1),它允许和监控工具,秘密管控,服务发现紧密集成,允许我们进行细粒度的健康检查。
除了init进程,我们增加了ppidshim进程,在每个容器里这个进程pid=2,它只是简单去启动应用进程(pid=3)。ppidshim是为了让应用进程不直接继承于init(也就是说,ppid!=1),因为那样会让它们认为自己是后台程序而出错。
最后进程层次结构是:
Signals
如果你要容器化,很可能需要改变现有的脚本,或者重写一个新脚本,里面包含调用docker run。默认地,docer run会发出signal到你的应用,也就意味着你需要理解应用是如何处理signal的。
标准UNIX规范是发送SIGTERM请求来正常关闭进程。确保你的应用是遵守这个规范的,因为我们发现不止一个应用,比如Resque,使用SIGQUIT来正常关闭,而使用SIGTERM来紧急关闭。幸运的是,Resque(>1.22)能够配置使用SIGTERM来触发的关闭。
主机名
使用容器名来描述容器的工作内容(比如,unicorn-1,resque-2),并且将这个名字和机器的主机名结合使用,方便问题的跟踪。最后的结果类似:runicorn-1.server2.shopify.com。
使用Docker的--hostname标志将主机名传进容器,这使得大部分应用能使用正确的主机名。一些程序(Ruby)会使用短名(unicorn-1)而不是FQDN。
因为Docker管理/etc/resolv.conf,而现在的版本不允许随意改动,我们使用LD_PRELOAD来注入库,这个库拦截并且重载gethostname()和uname()函数。最终结果是监控工具发布我们需要的主机名而不需要更改应用代码。
注册和部署
我们发现构建能够复制“纯物理机”行为的容器的流程其实就是一个调试的过程。一旦你构建了稳健的容器之后就自然想要自动化整个构建过程。
我们使用github commit hook为每次主推触发容器的构建,并且commit statuses来标志构建是否成功。使用git commit SHA 来给容器起标签:因此可以对容器里包含的是哪个版本的代码一目了然。我们也将SHA放进容器里的文件(/app/REVISION),以便调试和脚本的调用。
一旦构建出稳定的build,就需要将这个容器放到一个中央注册表里。我们选择搭建自己的注册表以便提高部署速度,同时减少对外部的依赖。我们使用nginx反向代理来缓存GET请求,在Nginx之后,使用多个相同的标准python注册表。拓扑看上去如图:
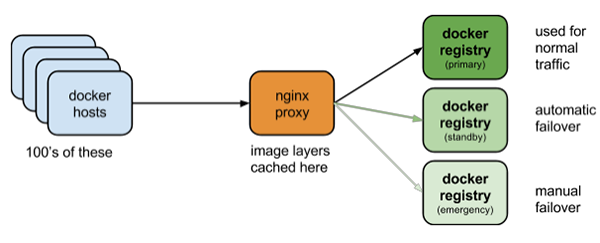
我们发现庞大的网络接口(10 Gbps)和反向代理可以有效对抗当多个Docker主机申请同一个镜像时引起的“惊群效应”。这种采用代理的解决方法允许我们同时运行多个注册表,并且在某个注册表崩溃的时候提供自动故障转移。
如果按照我们的方法,那么你会得到自动构建的容器,它们安全地存储在中央注册表里,随时可以被用来部署。
我们的下一篇文章会讲述如何管理应用,并深入探讨如何自定义构建流程来创建尽可能小的容器。
Dockerfile最佳实践(一)
【编者的话】本文是Docker入门教程第三章-DockerFile的进阶篇,作者主要介绍了缓存、标签、端口以及CMD与ENTRYPOINT的最佳用法,并通过案例分析了注意事项,比如我们应该使用常用且不变的Dockerfile开头、通过-t标记来构建镜像、勿在Dockerfile映射公有端口等等。
Dockerfile使用简单的语法来构建镜像。下面是一些建议和技巧以帮助你使用Dockerfile。
1、使用缓存
Dockerfile的每条指令都会将结果提交为新的镜像,下一个指令将会基于上一步指令的镜像的基础上构建,如果一个镜像存在相同的父镜像和指令(除了ADD),Docker将会使用镜像而不是执行该指令,即缓存。
为了有效地利用缓存,你需要保持你的Dockerfile一致,并且尽量在末尾修改。我所有的Dockerfile的前五行都是这样的:
FROM ubuntu
MAINTAINER Michael Crosby < michael @crosbymichael.com >
RUN echo "deb http://archive.ubuntu.com/ubuntu precise main universe" > /etc/apt / sources.list
RUN apt - get update
RUN apt - get upgrade - y
更改MAINTAINER指令会使Docker强制执行RUN指令来更新apt,而不是使用缓存。
所以,我们应该使用常用且不变的Dockerfile开始(译者注:上面的例子)指令来利用缓存。
2、使用标签
除非你正在用Docker做实验,否则你应当通过-t选项来docker build新的镜像以便于标记构建的镜像。一个简单的可读标签将帮助你管理每个创建的镜像。
docker build -t="crosbymichael/sentry" .
注意,始终通过-t标记来构建镜像。
3、公开端口
两个Docker的核心概念是可重复和可移植。镜像应该可以运行在任何主机上并且运行尽可能多的次数。在Dockerfile中你有能力映射私有和公有端口,但是你永远不要通过行一个容器化应用程序实例。(译者注:运行多个端口不就冲突啦)Dockerfile映射公有端口。通过映射公有端口到主机上,你将只能运行一个容器化应用程序实例。(译者注:运行多个端口不就冲突啦)
#private and public mapping
EXPOSE 80:8080
#private only 5EXPOSE 80
如果镜像的使用者关心容器公有映射了哪个公有端口,他们可以在运行镜像时通过-p参数设置,否则,Docker会自动为容器分配端口。
切勿在Dockerfile映射公有端口。
4、CMD与ENTRYPOINT的语法
CMD和ENTRYPOINT指令都非常简单,但它们都有一个隐藏的容易出错的“功能”,如果你不知道的话可能会在这里踩坑,这些指令支持两种不同的语法。

这看起来好像没什么问题,但仔细一看其实两种方式差距很大。如果你使用第二个语法:CMD(或ENTRYPOINT)是一个数组,它执行的命令完全像你期望的那样。如果使用第一种语法,Docker会在你的命令前面加上/bin/sh -c,我记得一直都是这样。
如果你不知道Docker修改了CMD命令,在命令前加上/bin/sh -c可能会导致一些意想不到的问题以及难以理解的功能。因此,在使用这两个指令时你应当使用数组语法,因为数组语法会确切地执行你打算执行的命令。
使用CMD和ENTRYPOINT时,请务必使用数组语法。
5、CMD和ENTRYPOINT 结合使用更好
docker run命令中的参数都会传递给ENTRYPOINT指令,而不用担心它被覆盖(跟CMD不同)。当与CMD一起使用时ENTRYPOINT的表现会更好。让我们来研究一下我的Rethinkdb Dockerfile,看看如何使用它。
#
Dockerfile
for Rethinkdb# http: //www.rethinkdb.com/
FROM ubuntu
MAINTAINER Michael Crosby < michael @crosbymichael.com >
RUN echo "deb http://archive.ubuntu.com/ubuntu precise main universe" > /etc/apt / sources.list
RUN apt - get update
RUN apt - get upgrade - y
RUN apt - get install - y python - software - properties
RUN add - apt - repository ppa: rethinkdb / ppa
RUN apt - get update
RUN apt - get install - y rethinkdb # Rethinkdb process
EXPOSE 28015# Rethinkdb admin console
EXPOSE 8080 # Create the / rethinkdb_data dir structure
RUN / usr / bin / rethinkdb create E NTRYPOINT["/usr/bin/rethinkdb"]
CMD["--help"]
这是Docker化Rethinkdb的所有配置文件。在开始我们有标准的5行来确保基础镜像是最新的、端口的公开等。当ENTRYPOINT指令出现时,我们知道每次运行该镜像,在docker run过程中传递的所有参数将成为ENTRYPOINT(/usr/bin/rethinkdb)的参数。
在Dockerfile中我还设置了一个默认CMD参数--help。这样做是为了docker run期间如果没有参数的传递,rethinkdb将会给用户显示默认的帮助文档。这是你所期望的与rethinkdb交互相同的功能。
这是Docker化Rethinkdb的所有配置文件。在开始我们有标准的5行来确保基础镜像是最新的、端口的公开等。当ENTRYPOINT指令出现时,我们知道每次运行该镜像,在docker run过程中传递的所有参数将成为ENTRYPOINT(/usr/bin/rethinkdb)的参数。
在Dockerfile中我还设置了一个默认CMD参数--help。这样做是为了docker run期间如果没有参数的传递,rethinkdb将会给用户显示默认的帮助文档。这是你所期望的与rethinkdb交互相同的功能。
docker run crosbymichael/rethinkdb
输出
Running 'rethinkdb'
will create a new data directory or use an existing one,
and serve as a RethinkDB cluster node.
File path options:
-d[--directory] path specify directory to store data and metadata
--io - threads n how many simultaneous I / O operations can happen
at the same time
Machine name options:
-n[--machine - name] arg the name
for this machine(as will appear in
the metadata). If not specified, it will be
randomly chosen from a short list of names.
Network options:
--bind {
all | addr
}
add the address of a local interface to listen
15 on when accepting connections;
loopback
addresses are enabled by
default
--cluster - port port port
for receiving connections from other nodes
--driver - port port port
for rethinkdb protocol client drivers
-
o[--port - offset] offset all ports used locally will have this value
added
-
j[--join] host: port host and port of a rethinkdb node to connect to
.................
现在,让我们带上--bind all参数来运行容器。
docker run crosbymichael/rethinkdb --bind all
输出
info: Running rethinkdb 1.7.1-0ubuntu1~precise (GCC 4.6.3)...
info: Running on Linux 3.2.0-45-virtual x86_64
info: Loading data from directory /rethinkdb_data
warn: Could not turn off filesystem caching for database file: "/rethinkdb_data/metadata" (Is the file located on a filesystem that doesn't support direct I/O (e.g. some encrypted or journaled file systems)?) This can cause performance problems.
warn: Could not turn off filesystem caching for database file: "/rethinkdb_data/auth_metadata" (Is the file located on a filesystem that doesn't support direct I/O (e.g. some encrypted or journaled file systems)?) This can cause performance problems.
info: Listening for intracluster connections on port 29015
info: Listening for client driver connections on port 28015
info: Listening for administrative HTTP connections on port 8080
info: Listening on addresses: 127.0.0.1, 172.16.42.13 10info: Server ready
info: Someone asked for the nonwhitelisted file /js/handlebars.runtime-1.0.0.beta.6.js, if this should be accessible add it to the whitelist.
就这样,一个全面的可以访问db和管理控制台的Rethinkdb实例就运行起来了,你可以用与镜像交互一样的方式来与其交互。虽然简单小巧但它的功能非常强大。、
CMD和ENTRYPOINT 结合在一起使用更好。
我希望这篇文章可以帮助你使用Dockerfiles以及构建镜像。Dockerfile是Docker的重要一部分,无论你是构建或是使用镜像,它都非常简单而且使用方便。我打算投入更多的时间来提供一个完整的、功能强大但简单的解决方案来使用Dockerfile构建Docker镜像。
Dockerfile最佳实践(二)
【编者的话】本文是 Docker 入门教程第三章-DockerFile 进阶篇的第二部分。作者主要介绍了 Docker 的变化、常用指令以及基础镜像的最佳用法。
自从我上一篇 Dockerfile 最佳实践后,Docker 发生了很大变化。上一篇会继续留着,这篇文章将介绍 Docker 有什么变化以及你现在应当做些什么。
1、不要开机初始化
容器模型是进程而不是机器。如果你认为你需要开机初始化,那么你就错了。
2、可信任构建
即使你不喜欢这个题目但它是很棒的一个功能。我把大部分 GitHub 仓库添加到可信任构建,因此当我提交一个新镜像之后不久,就在等待索引。另外,我不必再创建单独的 Dockerfile 仓库与他人分享,它们都在同一个地方。
请记住,这不是你尝试新东西的试验场。在你推送之前,请在本地先构建一下。Docker 可以确保你在本地的构建和运行,与你推送到任何地方的构建和运行是一样的。本地开发和测试、提交和推送、以及等待索引上的官方镜像都是建立在可信任构建的基础之上的。
3、不要在构建中升级版本
更新将发生在基础镜像里,你不需要在你的容器内来apt-get upgrade更新。因为在隔离情况下,如果更新时试图修改 init 或改变容器内的设备,更新可能会经常失败。它还可能会产生不一致的镜像,因为你不再有你的应用程序该如何运行以及包含在镜像中依赖的哪种版本的正确源文件。
如果基础镜像需要安全更新,那么让上游的知道,让他们给大家更新,并确保你再次构建的一致性。
4、使用小型基础镜像
有些镜像比其他的更臃肿。我建议使用debian:jessie作为你的基础镜像。如果你熟悉Ubuntu,你将发现一个更轻量和巧妙的自制 debian,它足够小并且没有包含任何不需要的包。
5、使用特定的标签
对于你的基础镜像这是非常重要的。Dockerfile 中FROM应始终包含依赖的基础镜像的完整仓库名和标签。比如说FROM debian:jessie而不仅仅是FROM debian。
6、常见指令组合
您的apt-get update应该与apt-get install组合。此外,你应该采取\的优势使用多行来进行安装。
#
Dockerfile
for https: //index.docker.io/u/crosbymichael/python/
FROM debian: jessie
RUN apt - get update && apt - get install - y\
git\
libxml2 - dev\
python\
build - essential\
make\
gcc\
python - dev\
locales\
python - pip
RUN dpkg - reconfigure locales && \
locale - gen C.UTF - 8 && \
/usr/sbin / update - locale LANG = C.UTF - 8
ENV LC_ALL C.UTF - 8
谨记层和缓存都是不错的。不要害怕过多的层,因为缓存是大救星。当然,你应当尽量使用上游的包。
7、使用自己的基础镜像
我不是在谈论运行 debbootstrap 来制作自己的 debian。你不是 tianon(Tianon Gravi),没有人想要你认为别人需要你的 500mb 的狗屎垃圾基础镜像。我说的是,如果你要运行 python 应用程序需要有一个python基础镜像。前面示例中用于构建 crosbymichael/python 的 Dockerfile 也被用于其他很多构建 Python 应用程序的镜像。
FROM crosbymichael/python
RUN pip install butterfly
RUN echo "root\nroot\n" | passwd root
EXPOSE 9191
ENTRYPOINT ["butterfly.server.py"]
CMD ["--port=9191", "--host=0.0.0.0"]
另一个:
FROM crosbymichael/python
RUN pip install --upgrade youtube_dl && mkdir /download
WORKDIR /download
ENTRYPOINT ["youtube-dl"]
CMD ["--help"]
正如你看到的,这使得使用你的基础镜像非常小,从而使你集中精力在应用程序上。
深入理解Docker Volume(一)
【编者的话】本文主要介绍了Docker Volume的原理以及使用方式,是Docker入门教程的延伸。作者通过从数据的共享、数据容器、备份、权限以及删除Volume五方面深入介绍了Volume的工作原理,从实战中帮助读者了解Volume。
从Docker IRC频道以及stackoverflow的问题来看,很多人还不是很明白Docker Volume的工作原理。在这篇文章中,我会尽最大的努力来解释Volume是如何工作的,并展示一些最佳实践。这篇文章主要是针对那些对Volume不了解的Docker用户,当然有经验的用户也可以通过本文了解一些Volume的细节。
想要了解Docker Volume,首先我们需要知道Docker的文件系统是如何工作的。Docker镜像是由多个文件系统(只读层)叠加而成。当我们启动一个容器的时候,Docker会加载只读镜像层并在其上(译者注:镜像栈顶部)添加一个读写层。如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层。如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件的只读版本仍然存在,只是已经被读写层中该文件的副本所隐藏。当删除Docker容器,并通过该镜像重新启动时,之前的更改将会丢失。在Docker中,只读层及在顶部的读写层的组合被称为Union File System(联合文件系统)。
为了能够保存(持久化)数据以及共享容器间的数据,Docker提出了Volume的概念。简单来说,Volume就是目录或者文件,它可以绕过默认的联合文件系统,而以正常的文件或者目录的形式存在于宿主机上。
我们可以通过两种方式来初始化Volume,这两种方式有些细小而又重要的差别。我们可以在运行时使用-v来声明Volume:
$ docker run -it --name container-test -h CONTAINER -v /data debian /bin/bash
root@CONTAINER:/# ls /data
root@CONTAINER:/#
上面的命令会将/data挂载到容器中,并绕过联合文件系统,我们可以在主机上直接操作该目录。任何在该镜像/data路径的文件将会被复制到Volume。我们可以使用docker inspect命令找到Volume在主机上的存储位置:
$ docker inspect -f {{.Volumes}} container-test
你会看到类似的输出:
map[/data:/var/lib/docker/vfs/dir/cde167197ccc3e138a14f1a4f...b32cec92e79059437a9]
这说明Docker把在/var/lib/docker下的某个目录挂载到了容器内的/data目录下。让我们从主机上添加文件到此文件夹下:
$ sudo touch /var/lib/docker/vfs/dir/cde167197ccc3e13814f...b32ce9059437a9/test-file
进入我们的容器内可以看到:
$ root@CONTAINER:/# ls /data test-file
只要将主机的目录挂载到容器的目录上,那改变就会立即生效。我们可以在Dockerfile中通过使用VOLUME指令来达到相同的目的:

如果您没有执行此命令,那么你的容器会一直存在,依旧可以启动、停止等。如果你找不到你的容器,可以运行此命令:
但还有另一件只有-v参数能够做到而Dockerfile是做不到的事情就是在容器上挂载指定的主机目录。例如:

该命令将挂载主机的/home/adrian/data目录到容器内的/data目录上。任何在/home/adrian/data目录的文件都将会出现在容器内。这对于在主机和容器之间共享文件是非常有帮助的,例如挂载需要编译的源代码。为了保证可移植性(并不是所有的系统的主机目录都是可以用的),挂载主机目录不需要从Dockerfile指定。当使用-v参数时,镜像目录下的任何文件都不会被复制到Volume中。(译者注:Volume会复制到镜像目录,镜像不会复制到卷)
数据共享
如果要授权一个容器访问另一个容器的Volume,我们可以使用-volumes-from参数来执行docker run。

值得注意的是不管container-test是否运行,它都会起作用。只要有容器连接Volume,它就不会被删除。
数据容器
常见的使用场景是使用纯数据容器来持久化数据库、配置文件或者数据文件等。官方的文档上有详细的解释。例如:

该命令将会创建一个已经包含在Dockerfile里定义过Volume的postgres镜像,运行echo命令然后退出。当我们运行docker ps命令时,echo可以帮助我们识别某镜像的用途。我们可以用-volumes-from命令来识别其它容器的Volume:


使用数据容器的两个注意点:
1.不要运行数据容器,这纯粹是在浪费资源。
2.不要为了数据容器而使用“最小的镜像”,如busybox或scratch,只使用数据库镜像本身就可以了。你已经拥有该镜像,所以并不需要占用额外的空间。
备份
如果你在用数据容器,那做备份是相当容易的:

该示例应该会将Volume里所有的东西压缩为一个tar包(官方的postgres Dockerfile在/var/lib/postgresql/data目录下定义了一个Volume)
权限与许可
通常你需要设置Volume的权限或者为Volume初始化一些默认数据或者配置文件。要注意的关键点是,在Dockerfile的VOLUME指令后的任何东西都不能改变该Volume,比如:
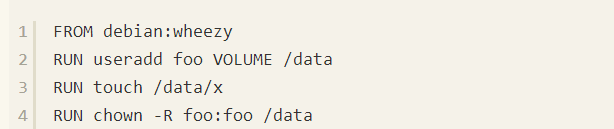
该Docker file不能按预期那样运行,我们本来希望touch命令在镜像的文件系统上运行,但是实际上它是在一个临时容器的Volume上运行。如下所示:

Docker可以将镜像中Volume下的文件挂载到Volume下,并设置正确的权限。如果你指定Volume的主机目录将不会出现这种情况。
如果你没有通过RUN指令设置权限,那么你就需要在容器启动时使用CMD或ENTRYPOINT指令来执行(译者注:CMD指令用于指定一个容器启动时要运行的命令,与RUN类似,只是RUN是镜像在构建时要运行的命令)。
删除Volumes
这个功能可能会更加重要,如果你已经使用docker rm来删除你的容器,那可能有很多的孤立的Volume仍在占用着空间。
Volume只有在下列情况下才能被删除:
1.该容器可以用docker rm -v来删除且没有其它容器连接到该Volume(以及主机目录是也没被指定为Volume)。注意,-v是必不可少的。
2.docker run中使用rm参数
除非你已经很小心的,总是像这样来运行容器,否则你将会在/var/lib/docker/vfs/dir目录下得到一些僵尸文件和目录,并且还不容易说出它们到底代表什么。
深入理解Docker Volume(二)
【编者的话】继上一篇文章深入理解Docker Volume(一)后,DockerOne翻译了深入理解Volume的第二篇文章。本文重点介绍了两种创建Volume方式的异同以及使用docker run命令创建Volume时,指定主机目录与不指定主机目录的区别。
Docker的难点之一就是Volume的使用,这也是很多人都会问到的问题。所以让我们一起来深入看看Docker Volume是如何工作的。
很多人都对Volume有一个误解,他们认为Volume是为了持久化。如此想法是因为他们觉得容器不能持久化,所以Volume应该是为了满足这个需求而设计的。其实容器会一直存在,除非你删除它们:
这可能来自于容器不是持久的想法,这样确实是不对的。容器是持久的,直到你删除他们,并且你只能这样做:

如果您没有执行此命令,那么你的容器会一直存在,依旧可以启动、停止等。如果你找不到你的容器,可以运行此命令:

docker ps只能显示正在运行的容器,但是容器也会处于停止状态,这种情况下,上面的命令(译者注:-a参数会列出所有的容器)会显示所有的容器,无论它们处于什么状态。docker run ...命令可以有很多的组合(译者注:它提供了Docker容器从创建到启动的所有功能),它会创建一个新的容器,然后启动它。
综上,再次声明:Volume并不是为了持久化。
什么是Volume
Volume可以将容器以及容器产生的数据分离开来,这样,当你使用docker rm my_container删除容器时,不会影响相关的数据。
Volume可以使用以下两种方式创建:
1.在Dockerfile中指定VOLUME /some/dir
2.执行docker run -v /some/dir命令来指定
无论哪种方式都是做了同样的事情。它们告诉Docker在主机上创建一个目录(默认情况下是在/var/lib/docker下),然后将其挂载到指定的路径(例子中是:/some/dir)。当删除使用该Volume的容器时,Volume本身不会受到影响,它可以一直存在下去。
如果在容器中不存在指定的路径,那么该目录将会被自动创建。
你可以告诉Docker同时删除容器和其Volume:

有时候,你想在容器中使用主机上的某个目录,你可以通过其它的参数来指定(译者注:注意冒号前面的和后面的内容)

这明确地告诉Docker使用指定的主机路径来代替Docker自己创建的根路径并挂载到容器内指定的路径(以上例子为/some/path)。需要注意的是,这种方式同样支持文件。在Docker术语中,这通常被称为bind-mounts(虽然技术层面上是这样讲的,但是实际的感觉是所有的Volume都是bind-mounts的)。如果主机上的路径不存在,目录将自动在给定的路径中创建。
对待bind-mount Volume和一个“正常”的Volume有一点不同,它不会修改主机上那些非Docker创建的东西:
1.一个“正常”的Volume,Docker会自动将指定Volume路径(如上面的示例/some/path)上的数据复制到由Docker创建的新的目录下,如果是“bind-mount”,Volume就不会这样做。(译者注:这样做会将主机上的目录复制到容器)
2.当你执行docker rm -v my_container命令时,“bind-mount” 类型的Volume不会被删除。
容器也可以与其它容器共享Volume。

上面的命令将告诉Docker从第一个容器挂载相同的Volume到第二个容器,它可以在两个容器之间共享数据。
如果你执行docker rm -v my_container命令,而上方的第二容器依然存在,那Volume不会被删除,如果你不使用docker rm -v my_container2命令删除第二个容器,那它会一直存在。
Dockerfiles里的VOLUME
正如前面提到的,Dockerfile中的VOLUME指令也可以做同样的事情,类似docker run命令中的-v参数(除了你不能在Dockerfile指定主机路径)。也正因为如此,构建镜像时可以得到惊奇的效果。
在Dockerfile中的每个命令都会创建一个新的用于运行指定命令的容器,并将容器提交到镜像,每一步都是在前一步的基础上构建。因此在Dockerfile中ENV FOO=bar等同于:

下面让我们来看看这个Dockerfile的例子发生了什么:

我们期待的是Docker创建一个名为my_debian并且Volume是/foo/bar的镜像,以及在/foo/bar/baz下添加了一个空文件,但是让我们看看等同的CLI命令行实际上做了哪些:


真实过程可能并不是这样,但是类似。
在这里,/foo/bar会首先创建,所以我们每次通过这个镜像启动一个容器,都会有一个空的/foo/bar目录。正如前面所说,Dockerfile中每个命令都会创建一个新容器。也就是说,每次都会创建一个新的Volume。由于例子的Dockerfile中是先指定Volume的,所以当执行touch /foo/bar/baz命令的容器创建时,一个Volume会被挂载到/foo/bar,然后baz才能被写入此Volume,而不是实际的容器或镜像的文件系统内。
所以,牢记Dockerfile中VOLUME指令的位置,因为它在你的镜像内创建了不可改变的目录。
docker cp(#8509),docker commit和docker export还不支持Volume
(在文章截稿时)。
目前,在容器的创建/销毁期间来管理Volume(创建/销毁)是唯一的方式,这有点古怪,因为Volume是为了从容器的生命周期中分离容器内的数据。Docker团队正在处理这个问题,但尚未合并(#8484)。
Docker的大坑小洼
【编者的话】Docker成为云计算领域的新宠儿已经是不争的事实,作为高速发展的开源项目,难免存在这样或那样的瑕疵。笔者最近在开发实战中曾经跌进一些坑里,有些坑还很深,写出来分享,相当于是在坑边挂个警示牌,避免大家重蹈覆辙。话不多说,一起来领略Docker的大坑小洼。
1.Docker中同种类型不同tag的镜像并非可互相替代
问题描述
Docker中同种类型的镜像,一般会用tag来进行互相区分。如Docker中的mysql镜像,镜像tag有很多种,有5.6.17,5.6.22,latest等。用户的环境中若已经熟练使用mysql:5.6.17,并不代表用户如果使用mysql:5.6.22,环境依旧工作。
熟练使用mysql:5.6.17,并不代表用户如果使用mysql:5.6.22,环境依旧工作。
原因剖析
不同tag同种类型的Docker镜像,会因为以下的原因导致镜像差异。 (1).Docker镜像内容不同。同种类型Docker镜像的tag不同,很大程度上是因为镜像中应用版本的差异。Dockerfile代表Docker镜像的制作流程,换言之是Dockerfile的不同,导致Docker镜像的不同。 (2).Docker镜像的entrypoint.sh不同。entrypoint.sh代表容器中应用进程按照何种形式启动,entrypoint.sh的差异直接导致应用容器的使用差异。举例说明:mysql:5.6.17和mysql:5.6.22的entrypoint.sh存在很大差异,两者对于隔离认为重要的环境变量的定义就不一致,使用的差异自然存在。
解决方案
1.不同tag的同类型镜像作为替代品时,需谨慎。查看Docker镜像layer层的差异,查阅Dockerfile与entrypoint.sh的差异,可以提供起码的保障
2.不同时间段使用tag为latest的镜像,效果不尽相同
问题描述
在一个时间点使用latest镜像,应用容器运行正常;之后的另一个时间点按照相应的Dockerfile,build出镜像再运行应用容器,失效。
原因剖析
Docker官方关于同种类型Docker镜像的latest标签,并未永久赋予某一指定的Docker镜像,而是会变化。举例说明:某一个时间点ubuntu镜像的latest标签属于ubuntu:12.04,之后的另一时间点,该latest标签属于ubuntu:14.04,若Dockerfile在这两个时间点进行build时,结果必然相异。原因回归至上文的第一个坑。
解决方案
慎用latest标签,最好不用,Docker镜像都使用指定的tag。
3.使用fig部署依赖性强的容器时出错
问题描述
使用fig部署两个有依赖关系的容器A和B,容器A内部应用的启动依赖于容器B内应用的完成。容器A内应用程序尝试连接容器B内部应用时,由于容器B内应用程序并未启动完毕,导致容器A应用程序启动失败,容器A停止运行。
原因剖析
容器的启动分为三个阶段,依次为dockerinit、entrypoint.sh以及cmd,三个阶段都会消耗时间,不同的容器消耗的时间不一样,这主要取决于docker容器中entrypoint和command到底做了什么样的操作。如mysql容器B的启动,首先执行dockerinit;然后通过dockerinit执行entrypoint.sh,由于entrypoint.sh执行过程中需要执行mysql_install_db等操作,会占据较多时间;最后由entrypoint.sh来执行cmd,运行真正的应用程序mysqld。综上所述,从启动容器到mysqld的运行,战线拉得较长,整个过程docker daemon都认为mysql容器存活,而mysqld正常运行之前,mysql容器并未提供mysql服务。如果fig中的容器A要访问mysql容器B时,fig会简单辨别依赖关系,让B先启动,再启动A,当fig无法辨别容器应用的状态,导致A去连接B时,B中应用仍然未启动完毕,最终A异常退出。
解决方案
对自身环境有起码的预估,如从容器B的启动到容器B内应用的启动完毕,所需多长时间,从而在容器A内的应用程序逻辑中添加延时机制;或者在A内应用程序逻辑中添加尝试连接的机制,等待容器B内应用程序的启动完毕。 笔者认为,以上解决方案只是缓解了出错的可能性,并未根除。
4.Swarm管理多个Docker Node时,Docker Node注册失败
问题描述
笔者的Docker部署方式如下:在vSphere中安装一台ubuntu 14.04的虚拟机,在该虚拟机上安装docker 1.4.1;在虚拟机上制作vm使用的镜像;创建虚拟机节点时通过该镜像创建,从而虚拟机中都含有已经安装好的docker。如果使用Swarm管理这些虚拟机上的docker daemon时,仅一个Docker Node注册成功,其他Docker Node注册失败,则错误信息为:docker daemon id已经被占用。
原因剖析
如果多个Docker Host上的Docker Daemon ID一样的话,Swarm会出现Docker Node注册失败的情况。原理如下: (1).Docker Daemon在启动的时候,会为自身赋一个ID值,这个ID值通过trustKey来创建,trustkey存放的位置为~/.docker/key.json。 (2).如果在IaaS平台,安装了一台已经装有docker的虚拟机vm1,然后通过制作vm1的镜像,再通过该镜像在IaaS平台上创建虚拟机vm2,那么vm1与vm2的key.json文件将完全一致,导致Docker Daemon的ID值也完全一致。
解决方案
(1)创建虚拟机之后,删除文件~/.docker/key.json ,随后重启Docker Daemon。Docker Daemon将会自动生成该文件,且内容不一致,实现多Docker Host上Docker Daemon ID不冲突。 (2)创建虚拟机镜像时,删除key.json文件。 建议使用方案二,一劳永逸。
5.Docker容器的DNS问题
问题描述
Dockerfile在build的过程中只要涉及访问外网,全部失效。
原因剖析
用户在创建docker容器的时候,不指定dns的话,Docker Daemon默认给Docker Container的DNS设置为8.8.8.8和8.8.4.4。而在国内这个特殊的环境下,这两个DNS地址并不提供稳定的服务。如此一来,只要Docker Container内部涉及到域名解析,则立即受到影响。
docker run命令dns失效的解决方案
使用docker run命令启动容器的时候,设定–dns参数,参数值为受信的DNS地址,必须保证Docker Container可访问该DNS地址。
以上解决方案的弊端
如果按以上方案做修改,仅适用于docker run命令。而使用docker build的时候其实是多个docker run的叠加,由于docker build没有dns参数的传入,因此docker container不能保证域名的成功解析。
docker build命令dns失效的解决方案
启动Docker Daemon的时候设定DOCKER_OPTS,添加–dns参数,这样可以保证所有的docker run默认使用这个DNS地址。
以上这些坑深浅不一,但基本上都集中在Docker外围的配置、行为模式等方
面。最近虽然在Docker的坑里摔得鼻青脸肿,但是“Docker虐我千百遍,我待Docker如初恋”的情怀始终不变。我坚信,这货一定是云计算的未来。前方的大坑,我来了,duang。。。 。。。
写于文章最后
对于本文,xds2000先生在百忙之中抽出时间,阅读本文并发表了自己的看法再谈《Docker的大坑小洼》。我非常赞成肖老师的观点,也很感谢肖老师,及时提出文章题目的偏差。本文取名《Docker的大坑小洼》,大部分为Docker使用的经验之谈。不论Docker的坑也好,Docker使用的坑也好,笔者希望大家更多的关注Docker的原理,从Docker原理出发,更好的掌握Docker技术。
再谈《Docker的大坑小洼》
今天闲暇看了一下宏亮同学写的一篇《Docker的大坑小洼》,非常受启发。因为Docker的文章真的很多了,但大家如果只是玩一玩,有很多坑是不会碰到的。通读完宏亮同学列出来的坑之后,可能是角度不同,我有一些不同的理解,借此机会分享给大家:
1.Docker中同种类型不同tag的镜像并非可互相替代
这个问题描述的挺绕的,看了好几遍才理解了笔者的问题。意思就是不同版本的Mysql镜像不能混用。用户的环境如果想依赖不同版本Mysql镜像,一定要再测试一遍,因为镜像变了,内容也变了。所以我更认为这是使用方法的问题,不是Docker的坑。
2.不同时间段使用tag为latest的镜像,效果不尽相同
这个是Docker设计成这样的,在分布式计算中,自动升级镜像后是无法知道下次启动的job会启动哪个镜像。所以增加了这个设计。我认为还是使用方法的问题,不是Docker的坑。或者说,掌握最佳实践,如宏亮说的,不要用latest tag。
3.使用fig部署依赖性强的容器时出错
我在实际使用fig做开发时也遇到这个问题,我觉得fig就是一个不可用的工具。如果你大量使用fig就会知道我想吐槽。目前还不如直接Build。
4.Swarm管理多个Docker Node时,Docker Node注册失败
我没有用过,没法发表意见。
5.Docker容器的DNS问题
这个坑有点冤枉Docker设计成这样了。但到了中国,确实变成了坑。实际使用中,不要用Docker镜像去访问外网的内容,最好做到本地访问。
从SDN以及Docker看网络模型发生的变革
【编者的话】本文选自New Stack,是介绍SDN的系列文章之一,这一系列之前的几篇文章主要是介绍SDN相关的技术和工具,这篇文章以Docker容器集群的网络模型为出发点,大致介绍了SocketPlane如何将SDN与Docker结合起来,在跨主机的容器之间建立虚拟局域网,同时作者还展望了未来基于容器的网络模型的发展趋势,文中介绍的一些相关的理念可能会给读者一些启发。
New Stack 曾经在软件自定义网络方面发表了一系列的文章。今天的这篇文章可以算是这个系列的一部分。在part 1中,我们对SDN进行了定义,并且详尽地说明了各种SDN控制器及相关框架之间的区别。在这个系列的part 2 ,我们介绍了Trema,这是一个用开发OpenFlow控制器的框架,是用Ruby和C语言所写的。在Part 3中,我们探索了NOX,这个是最开始的OpenFlow控制器。在part4中,
我们介绍了Ryu,这是一个由NTT实验室所维护的开源SDN控制器。在part5,我们了解了FloodLight,这也是一个OpenFlow控制器,有着超过15000次的下载次数。在part6中,我们主要想介绍的是OpenDayLight,这也是一个SDN控制器,被很多厂家所支持。
在不久之前,一个同行告诉我,他发现许多人都希望把传统的网络转化成软件自定义网络。
我同意他的观点,那么对于Docker呢?在SDN之前,Docker已经带来了许多新的变化,让资源密度和新的计算理念变成了焦点话题。由于Docker所带来的影响,传统应用和各层服务平台正发生着不同程度的改变,这些不同层次的服务如何被SDN所影响,反过来它们又如何影响SDN?
当越来越多的服务和软件开始运行在复杂的、快速的、分布式的基础设施上时,问题就出现了。越来越多的应用在架构设计上可能需要跨数据中心进行同步。
这些应用可能由一些可交互的服务构成,并且对于实时流数据的处理上(processing real-time streaming data)具有事件驱动能力。监控服务也会变得越来越重要,用户需要检测运行在OpenStack、AWS云服务或者其他基础设施平台上的容器所发生的异常。
这些新的应用在架构上的复杂性对于大多数开发者而言将是不可见的。我们也希望网络可以在没有服务人员帮助的状态下正常工作。目前为止,大家的注意力主要集中在Docker上,Docker被视为是一个新的堆栈转化(stack’s transformation)的标志。随着Docker及相关技术的到来,在技术栈(technology stack)的各个层面上将会产生许多新的需求。
在过去的几周,Sridhar Rao对软件自定义网络的相关内容进行了一系列的介绍。内容从市场上的第一代SDN工具开始,一直到SDN是如何走向成熟。现在我们将兴趣转移到容器相关技术上。Docker以及其相关的应用平台的出现,让我们对于网络模式的思考有了一种既熟悉又陌生的感觉。Docker中所使用的新的网络
技术一方面可以作为SDN应用的一个先例,另一方面,它还对其他因素进行了考虑,比如资源利用密度以及数据引力(data gravity),这些议题也随着轻量级容器技术和微服务理念的发展逐渐产生。
SocketPlane是一个正在发展中的混合的网路模型,它基于SDN的原则构建,并且可以被应用到Docker的环境中。
SocketPlane正在逐渐发展成为一个可编程的平台,它把DevOps放在一个网络环境中。这里有一篇关于SocketPlane的不错的文章。文中介绍了 SocketPlane如何在不同的主机之间建立一个 VXLAN隧道,以此来将不同主机上的Docker容器连接起来,使其处在同一个虚拟逻辑网络中,整个过程并不需要远程或者额外的 SDN控制器进行控制。
用户可以通过命令行工具与Docker容器进行交互,也可以使用socketplane的相关命令来创建、删除虚拟网络或进行其他的操作。
SocketPlane使用Hashicorp的Consul工具,使其作为一个轻量级的控制平台。在网络的连通性上,SocketPlane通过Open vSwitch来连接到Consul集群上。一旦Docker主机被加入进来,代理程序就会启动一个Docker实例,并且连接到集群中。之后容器看起来就像一个虚拟机。
由于Docker相关技术带来的变化,新一代的网络技术将会被重新定义,容器在跨多服务器、多主机的环境中的协同工作能力也会得到加强。产业界预期容器的数目的使用上可能至少有两个数量级的增长,随着容器使用数目的增加,后续的容器的相关管理技术也会不断发展,这将有可能在相关领域产生更多的创新。
“你可能会看到,对于短时间周期内执行的大量的计算任务,容器数目可能会达到一个新的数量级 ” SocketPlane的John Willis这样说,“现在所关注的问题可以算是‘纳秒级计算任务’,在每一周,开启或者停止运行的实例的数目级别可能会从1000个实例到1亿个不等。
在去年12月份的Dockercon Europe上,Wills让我们了解了他的观点,Willis从供应商的角度上进行了反思,告诉我们接下来的网络世界可能会发生什么。许多其他的供应商也做了演讲,我们可能会在接下来的文章中进行具体的介绍。特别地,Weave作为一个使用以容器为中心的网络技术的例子,也引起了一些关注。CoreOS也开发了Flannel,包括Docker也有其自己相关的网络配置功能。
Wills认为 SDN这个术语需要包含的内容太多,因此可以从各种不同的角度对其进行解释。为什么会这样?因为网络的确很难管理,并且适应性很差,发展更新也很困难,理解起来也不太容易。如果把这些因素都考虑进来,网络问题的确会变得非常复杂。在另一方面,SDN期望数据层可以有更好的适应性,并且可以将控制层从物理设备上移除。但是这样做会使控制层的集中化程度过高,以这样的方式管理一个以容器为中心的生态系统是不切实际的。
“中央大脑”模式所存在的问题
MarkBurgess的这篇文章很有启发,集中化的网络可能就像是以下这样:我们需要一个大脑,但是大脑实际上能处理的内容是有限的。因此我们需要许多大脑来一起工作。这好比我们通过创建一个社群来继承我们的知识,而不仅仅是依赖一个单独个体来掌握全部的知识。
长久以来,集中化的模型一直发挥着作用。比如你可以通过硬件来构建一个网络,这个网络可能由一个中心结点来控制。SDN通常就是基于这个原则来创建的。它所依赖的理念是:将集中化的控制层和数据层相分离。但更有意义的一种情况应该是使用一个非集中化(de-centralized)的网络,这个思路借用了我们社会构成中的“集中式的大脑”和“分散式的知识存储”的原理。在现实社会中,从来没有一个大脑可以控制我们的生活和工作方式。正是由于社会的“集群性质”(collective nature of society),于是我们就产生出了一系列的概念和想法,这也反应出了人类社会的本质。更进一步来说,一个大脑所能处理的信息是有限的,而一个有集体智慧的社会群体是由进行成千上万个协同工作的大脑所组成的。Burgess通过下面的方式来说明:

Burgess帮助构建了CF引擎,并且和SocketPlane一同工作了几个月。Burgess把这个问题比作,我们如何把工作负载推动到边缘(push the loads to the edges)。暴力模型可能看起来更有效率但是它们实际上很慢并且容易产生很多问题:
对于我们的问题,用社会模型打比方可能比用大脑模型要更恰当,因为在一个社会中,可以形成许多局部的“团体” ,这些“团体”之间可以在边界处进行微弱的交互,或者信息的交换。如果其中某一个连接失败,并没有必要把它与剩余的部分切断,它有一定的自治能力来重新配置并且适应。也没有必要把系统的每个部分之间都连通起来,这样的话,对于负载的处理和决策的制定就可能变成一个纯粹的暴力破解问题。
Docker很好地融入了SocketPlane提供的这种混合的网络模式。如果Docker的网络模式仅仅依赖于一个中央化的,“单一大脑”的方式,情况可能会变得很难处理。比如:一个服务器上有50台虚拟机,则一个集中式的SDN平台大约可以支持500个主机,每台主机上有50个虚拟机。如果每一个虚拟机上有5000个容器,你将怎样操作?在这种环境下,集中化的操作可能会变得难以实施。因此我们需要新的方法来应对网络行为的固有变化,这种网络行为所发生的变化可能是由容器的数量增减或者挂载的数据卷增减所引起的。
Wills还指出了Docker的两个发展趋势:
1.资源密度:正如他的同事Brent Salisbury在上周所写的那样,操作系统正变得越来越碎片化。由于Docker相关技术的到来,资源的利用状况会发生变化,这将会改变应用在网络环境中的行为方式。现今,OS之间相互合并的趋势变得越来越强,或许最终会从客户端上消失。在一个有成百上千个主机的环境中,可能会有几千个容器运行在同一个物理服务器上,
2.数据重力:这个概念由Basho CTO Dave McCrory所提出,是指数据应该被看成是一种能够吸引更多其他事物的东西。更多的数据会吸引更多的服务和应用。随着搜集到的数据越来越多,不可避免的,我们需要更多的计算资源,需要更多的方式来调用服务。计算能力可能是流式的或者是集群式的,就像是在AWS Lambda中已经实现的那样。
Adrian Cockcroft在Dockercon Europe的演讲中也谈到了这一点:
SocketPlane把它们的解决方案称为 retro-SDN,控制层有一个逻辑可以填充到数据层。它符合flow tables 的要求。举例来说,当一个packet经过的时候,按照程序对其进行路由,允许为其进行动态的决策。VMware把这称为微分段(micro-segmentation),Willis说。它将每一个分段隔离,创建隧道。VLAN是一个在交换机上多租户的抽象概念。但是这个是基于硬件的解决方案来说的。在云端,用户的计算资源并没有在某一个具体的服务器上,而是动态地分布在虚拟的网络中。这从更广泛的层面而言,就涉及到Willis如何定义他所说的叠加网络(overlay network),创建这样一个逻辑上的网络并不需要与任何物理交换机耦合,还能很容易地进行修改,这些操作可以由控制层到数据层全部完成。这就是SDN所希望实现的。服务可以移动到数据层并且被操纵。在Github上,SocketPlane的叠加网络被这样描述:
叠加网络在主机端点之间建立起隧道,在我们的例子中,这些端点都是Open vSwitch。对于这样的场景,优势是用户不需要担心 子网/vlan 或者其他任何的第
二层网络的使用限制。这只是我们提出的在网络中部署容器的其中一种方法。Open vSwitch的重要性在于网络的性能和一些用于高级网络配置的API。Willis认为容器的使用可能会达到一个新的数量级,上千个容器可能在一个服务器上,这会引起很多的问题。随着微服务理念的发展,任何数量的服务都可能运行在容器上。这意味着以数据重力、资源密度等概念为理念的新的设计模式将会创建一个完全不同的方法来对计算资源进行分配。
新的准则可能是:计算资源只生存几分钟或者几秒。(“The norm may be compute living for minutes or maybe seconds.”)以后不再需要集中控制的网络。就像一个社会的组织形态。也没有必要去进行集中化的组织以专制的形式运行。我们需要考虑的是如何构建中心枢纽。我们看到在一些极客社区中,并没有一个人试图去掌握所有的知识,社区的知识深度更多的通过集体智慧的形式来体现。
这提供了一种不同的方法来看待我们的网络本身。它不是一个“单一大脑”的形式,更像是一个集中数据平台的网络,可以动态地进行决策。
或许这对我们而言,可以用一种不同的方式来思考底层基础设施,网络作为一个社区的形式并非是一个单一的个体,我们可以参考这种新的思路来构建新的系统。
Mesos vs OpenStack?谁才是私有云的未来?
【编者的话】本文是Quora上的一个问题,提问者对于私有云未来的发展趋势感到疑惑,Mesos和OpenStack的关系是怎样的,它们之间是否可以相互替代?来自Mesosphere以及Rackspace的专家们从OpenStack与Mesos的功能和产品定位上对这个问题进行了解读,它们之间的关系并非互相替代,而是各有侧重,相辅相成,这取决于用户的实际需求。希望本文内容可以帮助读者对私有云领域的开源产品和相关概念有更好的了解。
Quora上的问题
私有云未来的发展趋势是什么,是Mesos?还是OpenStack?
在私有云方面,Mesos和Docker二者似乎是一个完美的结合,Google一直致
力于这方面的研究,我很好奇私有云的未来会是怎样的,大家怎样认为的?
回答者:Lukas Löschea(在Mesosphere工作,之前在工作中曾使用OpenStack)
Mesosphere和Openstack解决的是完全不同的问题。实际上,它们是可以在一起协同工作的。用户完全可以在OpenStack的集群上面运行Mesos,这样做可以带来很多额外的好处,比如提高系统的利用率和容错性。
我发现OpenStack的初始配置工作比Mesos要困难许多,但是对于OpenStack系统的整体理解要容易许多,因为OpenStack集群的运行方式基本上与我们过去几年运行系统的方式类似。OpenStack的基本理念是提供虚拟的服务器,为了实现这一目的,OpenStack也提供很好的硬件层抽象。但是虚拟机构成的集群可能会让你感到难以运维,对于每个虚拟机的维护也并非容易,用户遇到的问题基本上和以前在直接维护物理机集群基本相似。你仍然需要一个操作系统,一些配置和管理的工具,就像是Puppet、Chef、Salt、Ansible等等,并且需要采用独立的主机来运
工具,就像是Puppet、Chef、Salt、Ansible等等,并且需要采用独立的主机来运行这些工具。容器化的思想是在这之后才有的技术。虽然在OpenStack上已经有了Docker Nova的驱动,但是在我看来,大多数人使用OpenStack是为了创建虚拟机而并非容器。他们使用OpenStack的方式更类似于对AWS的使用方式。
而现实情况是,用户并不需要那么多的服务器,用户只是希望能够将它们的服务运行起来,使其可以发挥作用。从这个角度来看,OpenStack能做的事情并不多。提供服务器是一种终极解决方案,最终来看,所有的服务都要运行在服务器上。但是如果我有其他选择,我宁愿采用这样的方式来运行我的服务:服务可以无限扩展(我不用在乎它们是怎样运行以及运行在哪),当服务失败的时候能够被自动检测并且可以自动修复,我也不需要在凌晨3点的时候被叫醒,对服务进行维护。这就是Mesos所能完成的事情。
Mesos的用户可以按照新的方式调整他们的工作模式,这样可以大大简化工作流程。比如,如果用户使用Marathon来长时间地运行服务,就可以这样来设置工
作流程:开发者可以将代码提交到staging分支中,CI(Continuous integration)服务器(运行在Mesos集群当中)会构建一个docker image并且升级Marathon REST API来通过docker image进行部署。如果在staging阶段,服务运行的都很正常,开发者就会把他新提交的代码合并到master/production分支中,从而完成了产品系统的升级和部署。
最终的效果应该是这样的:对用户而言,所谓的部署过程仅仅意味着开发者将他的代码提交到对应的分支。类似于滚动部署(rolling deployments),服务之间的依赖,健康检查以及自动重启这些功能都可以由Mesos/Marathon来提供。
这是一种完全不同的工作方式,因为在这种模式下,运维人员不再需要去打包应用部署代码,或者启动特定的监控服务。
从复杂性的角度来看,我认为,如果用户想基于OpenStack来运行私有云平台,至少需要了解 Heat、Nova、Glance、Keystone、Neutron以及Cinder这些
组件。我过去曾经做过OpenStack部署的工作,我发现由于OpenStack本身的设计原因,在维护过程中会出现来一些很复杂的问题。因为Openstack本身是一个企业级的产品,并非社区产品,你会发现,OpenStack平台的安装和运维工作至少需要来自不同部门的几个人一起负责。因此,如果你在一个大的公司或组织里面工作,OpenStack平台的维护工作可能恰好可以按照公司本身的组织结构来进行分工(系统支持、服务器硬件、基础设施及网络、安全等等)
在网上可以找到相关的教程,基本上可以帮助你在半个小时左右就设置好可以用于生产环境的Mesos集群。
从个人的观点来看,Mesos的工作方式可能是未来我们运行数据中心的方式。所谓数据中心就是说我所有的硬件资源都可以协同工作就像一整台电脑一样,而并非是以单个主机的方式进行工作,并且用户不需要通过手工决定服务要在哪里运行。
回答者:Florian Leibert
对于私有云平台的构建,Mesos+Marathon+Docker是一个很好的解决方案。Mesos是一个被实际验证过的可以提供伸缩性服务的工具(Mesos被Twitter、Airbnb、Netflix、ebay、PayPal等等公司采纳)。Marathon是一个集群范围的初始化和控制系统,它可以帮助用户在cgroup和Docker容器中运行Linux服务。许多公司都看好这个技术。该技术所有的关键组件都是开源的,也是我公司的DCOS(Mesosphere Datacenter Operating System)商业产品的核心组成部分。
Mesos以及Mesophere系列技术可以提供一个类似的云环境,这个环境可以运行已有的Linux任务,也可以提供一个本地的环境用于构建新的分布式系统。
Mesos是一个分布式的系统内核,针对数据中心直接提供了编程所需的API。它将底层的硬件(裸机或者虚拟机)进行抽象,将这些硬件以一致的资源的形式提
供给用户。它包含着用于构建分布式系统的基本功能(例如,Mesos支持Spark App、还有Chronos等等)例如消息传递、任务执行等等。这样,用户就可以利用Mesos来构建完整的服务。Apache Spark就是其中的一个例子,Spark框架在Mesos的基础上进行构建,这很大程度上提升了开发工作的效率。比如Spark的开发者不用担心网络相关的问题,不用考虑如何将任务分布在不同的结点上来执行,这些都是Mesos所具备的基础核心功能。
可以参考Mesos在Apache.org上的页面,Mesosphere及其合作伙伴正在对这些服务进行认证,并且正在将这些服务打包进Mesosphere DCOS Datacenter Service中,这样这些服务就可以通过一条指令直接被安装完成。
Mesos另一个很好的特性就是它可以运行在已有的OpenStack集群上,也可以直接在裸机上运行,只需要在每个节点上运行一个小的Linux进程即可。
我认为Mesos是云计算的未来,因为它提供了良好的服务伸缩性,有利于数据
中心自动化运维,可以进行自我诊断并且提供丰富的本地服务生态系统(rich native application ecosystem),与此同时,还可以不用对代码进行修改就可以让已有服务正常运行。
回答者:Nati Shalom(构建了第一个Java PaaS解决方案, 与Amazon、RackSpace、Azure、VMware、Xen、JClouds专家一起工作,设计了一款在云端提供自动化服务和编排服务的产品。)
在IT行业,每隔一段时间,就会有新的技术出现,代替原有的“新的技术”,Mesos的案例似乎很符合这个情况。
事实上,虽然Mesos很成功,但并不能使其成为一个取代已有基础云设施的通用的解决方案。在之前的一篇文章中:如果我使用Docker我还需要OpenStack吗?,我就指出,在特定的领域内,OpenStack与Docker一样流行,因此Docker暂时还无法取代OpenStack。
我的观点是,如果想回答这个问题,我们需要回顾一下最初的时候我们希望从类似于OpenStack一样的云基础设施中得到什么,并且对比一下,Mesos是否能提供覆盖所有这些功能的替代方案。
像OpenStack一样的云环境,除了可以主动获取资源,分配工作负载之外,还可以针对各种各样的计算、存储以及网络等核心功能提供基于多租户的资源管理。
随着许多主要的云服务提供商不断投入到公有云基础设施的研发中,OpenStack也逐渐发展成一个生态系统。
对于跨主机分配工作负载,Mesos也做得很好。但是我觉得不应该把它看做是OpenStack云平台的替代方案。如果想要替代OpenStack,就需要提供与OpenStack同样级别的安全、存储、网络以及多租户的服务。我也不认为Mesos需要在所有方面做得都要比OpenStack更好。在我看来,Mesos至多可以和OpenStack运行的一样好,而并非替代OpenStack。
回答者:Dale Bracey(Rackspace私有云OpenStack产品工程师)
虽然我根本不熟悉Mesos,但是我大致了解,这是另外一个可以共享主机内核的容器化服务。
我尝试在Lukas Lösche的观点上再进行一些补充。你完全可以将之前回答中所提到的内容结合起来为你服务。OpenStack可以用来提供伸缩性,并且可以更方便地管理你的开发工具、网站、服务以及服务器。即使是直接对裸机的管理,OpenStack也是可以完成的(Ironic-OpenStack).
OpenStack整体的部署维护比较困难,虽然文档内容非常详细,但是仍然缺少细节性的指导,比如告诉用户从开始到最后整个的步骤应该怎样完成。毕竟OpenStack是一个很大的项目,这种复杂性也是正常的。
OpenStack试图成为一个可以管理多种Hypervisor、虚拟机以及存储服务的
编排层,但是目前仍然缺乏足够的能力。之前提到了OpenStack-Docker Nova驱动,这个项目将Docker安装在计算节点上,将容器按照虚拟机的方式提交给Nova/Glance,但实际上,容器并不是虚拟机,这样用户不仅可以利用容器技术本身的优势,还可以利用OpenStack提供的控制管理功能。此外还有一个CoreOS-OpenStack的项目,这个项目同样也很流行,这两个项目都有类似的特性。
当然,用户仍然需要使用一些配置系统来帮助你管理系统,除非想让事情变得更复杂。我们曾经使用Chef,之后使用Ansible。令人难过得是,我刚刚才知道,Ansible的CTO Michael Dehaan今天离开了Ansible公司。我不知道这个公司今后将会怎样发展,当然这是题外话。
如果你仅仅希望自己的系统能够运行,而不是去关心虚拟机和服务器,OpenStack的开箱即用并不能为你提供完全自动化的环境,但是你可以利用些现成的工具来实现这一目的。这些工具也是完全开放的,你可以对它们定制开发并且按照你希望的方式来工作。你可以将Heat-OpenStack、Ceilometer-OpenStack、以及各
种DevOps工具结合起来为你提供自动化服务。
最后为新产品做一个广告:Rackspace也承认OpenStack的部署工作确实很困难,我们一直致力于帮助客户简化部署的难度,我们在github上提供用于部署私有云的OpenStack结点,可以让用户免费使用(在stackgorge中有一个社区项目stackforge/os-ansible-deployment)我们也提供了其他的私有云的解决方案。
你可以尝试使用一下,去阅读部署文档,提交bug提交新的特性请求,并为社区做贡献,让我们来共同努力,简化OpenStack的部署流程。用户只需要关注服务的开发过程,不用考虑底层的基础设施。我们会一直为你提供帮助。
从容器和Kubernetes技术看现代云计算的发展轨迹
【编者的话】本文选自 Google Cloud Platform Blog,是一个主要介绍容器技术的系列博客的开篇。文中通过对容器技术和kubernetes的大致介绍,阐述了容器技术的优势以及Google对于容器技术的理解。基于单台服务器的容器虚拟化技术可以为测试和部署提供方便,但是在生产环境中,客户往往面对的是整个集群的资源。Google的kubernetes产品为容器的集群化部署和管理提供了解决方案,kubernetes从另一个角度对资源进行了抽象,把每一个服务当作一个整体来对待。作者认为容器技术仅仅是当前计算模型演变的一个开端,而Google将会在这场新的技术革命中扮演重要的角色。
在接下来的几周,我们将会发布一个新的系列博客,在这个系列中,我们想阐述Google对于容器技术的一些观点,此外我们还会和读者分享Google在过去十年间,在容器中运行服务的一些经验。我们是一支由Google的产品经理、一线技术员以及架构师组成的团队,团队共同的目标是要帮助读者了解“容器技术革命”如何能更有效的构建和运行服务。这次我们邀请了“Google 云平台全球解决方案”的专家Miles Ward来做分享,作为这一系列博客的开篇。
各位好!欢迎来到我们新的系列博客,在这个系列中,我们将要为大家介绍当今计算模型创新中最时髦的领域之一:容器化技术(containerization)。
你可能会有很多疑惑:容器到底是什么,它究竟怎样工作?Docker、Kubernetes到底指的是什么,Google Container Engine以及Managed VM又有什么用?它们之间有何关联,我们如何通过容器来构建一个功能强大的服务,并且能让它们在生产环境的大规模集群中使用? 用户采用这种技术,怎样才能获得商业价值?好了,我们不再卖关子,接下来就直入主题。我们首先会对容器技术进行具体的介绍,之后讲述容器技术究竟如何使我们更好地进行工作。
随着计算模型(computing models)的不断发展衍化,我们曾经经历过几次计算模型解决方案的转变。回顾在过去的10年,我们从虚拟化技术的角度可以很清楚看到这种变化的过程。受益于虚拟化技术的发展,我们对整体资源的使用效率有了巨大的提升,与此同时,我们工作的时间价值和为了交付服务所做的重复性工作得到了相应减少。随着多租户、基于API的管理以及公有云计算技术的到来,这一趋势更是被不断加强。这其中,最关键的突破就是资源使用方式所发生的变化。通过虚拟化的方式,我们可以在几分钟之内,虚拟出一个小的、独立的、随需随用CPU内核,这个虚拟的CPU内核感觉像是直接运行在物理机之外。那么问题来了,当你仅仅需要使用一小部分资源的时候,是否还有必要虚拟出一整台机器?
Google在很早的时候就已经遇到了这个问题:我们需要更快、更便宜的方式发布软件,并且支撑服务运行所需要的计算资源的规模也是以前从未有过的,那么这一问题应该如何解决?为了满足这一需求,我们需要对已有资源进行更高级别的抽象,使得服务可以通过更细的粒度对资源进行控制。为此,我们为Linux内核添
加了新的技术,这便是众所周知的cgroup,我们通过这一技术来对服务运行时的环境进行隔离,这种被隔离起来的运行时的环境就被称为容器。这是一种新的虚拟化技术,通过这一技术,我们简化了Google全部服务运行所需要的底层OS环境。之后的几年一直到现在,容器相关的技术不断发展,随着Docker的出现,这一技术的影响得到了进一步扩大,Docker也正是通过使用这一技术为基于容器的应用创建了一种可互操作的格式(interoperable format)。
为何使用容器?
容器技术究竟提供了哪些虚拟机所没有的?
简化部署(Simple deployment):容器技术可以将你的应用打包成单一地址访问的、registry存储的(registry-stored)、仅通过一行命令就可以部署完成的组件。不论你想将服务部署在哪里,容器都可以从根本上简化你的服务部署工作。
快速可用(Rapid availability):容器技术对操作系统的资源进行再次抽象,而并非对整个物理机资源进行虚拟化,通过这种方式,打包好的服务可以在1/20秒的时间内启动,相比之下,可能需要一分钟的时间才能启动一台虚拟机。
微服务化(Leverage microservices):容器可以允许开发者和系统管理人员对计算资源进行进一步细分,如果一个小型的虚拟机所提供的资源相对于服务运行所需要的资源来说过于庞大,或者对于你的系统而言,一次性地扩展出一台虚拟机会需要很多的工作量,那么容器可能会很好的改善这一状况。
容器技术的这些优点能为你的工作带来哪些帮助?
最明显的一个方面就是:开发者只需要通过他们的笔记本电脑就能同时运行多个容器,并进行方便快速的服务部署。虽然在一台笔记本电脑上运行多个虚拟机也是可以的,但是显然通过容器的方式可以更快速、简单、轻量级。
不仅如此,容器还可以使得服务发行版的管理变得更加容易,发布一个新的容器版本仅仅需要一个单独的命令就能完成。同时,测试工作也变得更加容易,在公有云平台中,虚拟机的计费方式可能至少以10分钟为单位(或者,一整个小时?),如果仅运行单个测试程序,测试所消耗的资源可能并不多。但是,如果你每天要运行上千个测试驱动导向的程序,资源成本就可能直线上升。如果改用容器进行同样的测试工作,你只需要用同样的资源消耗(与使用一台虚拟机相同的资源消耗)来完成这上千个测试,这将会大大节省你的服务运行成本。
另外一个重要的优势就是组合特性,采用容器的方式进行部署,整个系统会变得易于组合,特别是对于那些需要使用到开源软件的系统。对于系统管理人员,以下的工作可能会使人望而却步:安装和配置MySQL、Memcached、MongoDB、Hadoop、GlusterFS、RabbitMQ、Node.js、Nginx等等,之后再将这些软件封装起来,为服务提供一个运行平台。然而,这些复杂的工作完全可以通过启动几个容器来完成:先将这些服务封装在对应
的容器中,之后结合一些脚本使这些容器按照要求相互协作,这样操作不仅可以简化部署难度还可以降低操作风险。
如果你想按照前面所描述的过程构建一个服务平台,可能会有许多容易出错的地方,整个配制过程也需要具备很专业的知识, 中间可能还会有许多重复的劳动。因此,我们可以先将核心的容器组件以规范的方式来实现,之后将它们添加在公共的registry服务中。这样其他用户就可以通过registry服务随时获得所需要的容器,拥有高质量组件的容器生态系统就这样被构建起来。
在相当长的一段时间内,容器技术最重要的价值就是为不同主机上的运行服务提供一个轻便的、一致的格式。例如,如果你今天要构建一个服务,你可能先要接入裸机服务器,并且使用虚拟化之后的预先定义好的基础设施,或者直接使用共有或者私有的云服务平台,当然也有许多PaaS提供商可以供你选择。然而,你为了使自己的服务能够运行在不同的服务平台上,可能需要通过多种不通的方式对服务进行打包!而如果通过容器格式进行标准化操作,这些不同的计算模型的提供商们
就可以给用户提供一种独特的交付体验,这就允许用户方便地对工作负载地进行迁移,用户可以选择将工作任务部署在最便宜和最快的平台上,避免局限于单一的平台提供商。
Docker
网上已经有很多的对于容器技术和Docker相关技术如何实现的细致的介绍文。这些文档已经足够说明,Docker是一个“很棒的解决方案”,也就是说,目前可能还没有其它方案能够和它相媲美。
容器技术增强了对资源控制的力度,这一点确实有很高的实用价值,但是对于那些需要上千台服务器一起来运行的服务而言,单纯的容器技术并没有从本质上提高任何工作负载的运行效率。如今的Docker仅仅是为了在单一的机器操作而设计,于是我们又可以提出一连串的问题:这些在集群上所运行的容器和容器中运行的工作负载应该被如何分配和协调,它们怎样才能按照资源的消耗量来进行管理?
它们如何在多租户的网络环境下进行运行?它们的安全性能又该如何被保证?
或许从系统设计的角度来看,我们可以提出一个更本质的问题:当前我们所讨论的到底是不是正确的资源抽象方式?与我交流过的大多数开发者以及公司的赞助商,他们对在指定的机器上的指定容器并不感兴趣,他们真正想要的是自己的服务如何能被启动运行,产生价值,并且易于监管和维护,他们并不想了解全部的琐碎细节(至少他们希望这样),例如指定个机器上的指定个容器到底在做什么。
Kubernetes
Google通过产品的不断迭代解决了这个问题:我们构建了一个管理系统,它可以用来管理集群、网络以及命名系统。这个管理系统的第一个版本被称为Brog,它的后续的版本称为Omega。通过这个管理系统,我们可以在Google的大规模的集群资源上使用容器技术。我们现在每秒会启动大约7000个容器,每周可能会超过20亿个容器。我们利用Google在容器技术上的实践经验和技术积累,
构建了Kubernetes(在论坛上有些时候被简写为K8s)。
Kubernetes从另一个角度对资源进行抽象,它让开发人员和管理人员共同着眼于服务的行为和性能的提升,而不是仅仅关注单一的组件或者是基础资源。
那么Kubernetes集群到底提供了哪些单一容器所没有的功能?它主要关注的是对服务级别的控制而并非仅仅是对容器级别的控制,Kubernetes提供了一种“机智”的管理方式,它将服务看成一个整体。在Kubernete的解决方案中,一个服务甚至可以自我扩展,自我诊断,并且容易升级。例如,在Google中,我们使用机器学习技术来保证每个运行的服务的当前状态都是最高效的。
如果说单一容器能够帮助开发者减少部署工作的繁琐,那么Kubernetes就可以最大化的减少团队开发过程中协同工作的复杂性。Kubernets可以让团队以容器的方式将服务结合在一起,并且让这些容器按照指定的规则来进行部署,以确保服务能够正确运行。在传统的方式下,由于缺乏隔离性,服务之间或服务之间的各个
部分很容易产生相互干扰,但是通过Kubernetes,这些矛盾可以从系统的角度上被避免,在Google,通过使用这种增强的协同工作的方式,开发者的生产力得以提高,服务的可用性也进一步增强,这也使得在大规模的集群上的部署变得更加敏捷。
然而我们的技术仍然处于早期的发展阶段。目前,Kubernetes已经被许多客户和公司的知名团队所采用,包括RedHat 、VMware、CoreOS以及Mesosphere等等。这些公司迫切地希望通过Kubernete进行的规模化部署来帮助他们的客户提取出容器技术的商业价值。
Container Engine
Google Container Engine在Google的云平台上引入了“容器即服务”的理念。基于Kubernetes的技术,容器引擎为开发者提供了快速构建和运行容器的方法,此外,容器引擎还可以对容器进行部署、管理、并且使容器按着设定的边界进
行扩展。在接下来的文章中我们会对容器引擎进行更多的介绍。
Deployment options
我们可以看到,容器化技术已经成为了计算模型演化的一个开端,Google在这场技术革命中扮演重着要的角色。随着读者开始逐渐接触容器,并对容器部署方式了解不断深入,在实际服务部署中,可以对下面几种方式进行调研,并从中选出最适合的一种:
如果你打算运行一个被管理的集群或者启动几十个容器,使用Google Container Engine试一试。如果你想要在共有的基础设施上或者是自己的系统中构建自己的集群,可以使用Kubernetes来操作。想要在已经被管理好的基础设施上运行一个容器,可以尝试使用Google App Engine或者是Managed VMs。
最后,我们要说明的是,我们对你的使用容器技术的经历,对容器技术的需求以及想法(甚至你在github中提出的每个请求)都很感兴趣。不要犹豫,请联系我们,我们会尽所能举办尽量多的会议和Meetup。我们期望能与你联系。让我们一起讨论关于容器技术如何给你的工作带来改变。期待与你交流!
Mesosphere 携手Kubernetes 拥抱Google Cloud Platform
【编者的话】集群管理服务Mesos最早由伯克利大学提出,后来被Twitter引入生产环境,并以此为基础构建资源管理平台。Mesosphere在Mesos的基础上构建而成,可以支持在同一个集群上对不同的分布式服务进行部署和管理,文中通过介绍Mesosphere如何与Kubernetes和Google Cloud Platform结合,阐述了Mesosphere for Google Cloud Platform在集群构建时候的优势。
今天来给我们做介绍的是Mesophere的联合创始人兼CEO:Florian Leibert。在创建Mesophere之前,Florian Leibert曾是Twitter公司的技术主管,在他的帮助下,Twitter成功引入了Mesos服务,现在Twitter的所有新服务都运行在Mesos上。之后,他又在Mesos的基础上帮助Airbnb公司构建了分析堆栈(ana
lytics stack)。此外,他还是Chronos的主要作者,Chronos是一个Apache Mesos框架,主要用于对ETL系统进行管理和调度(managing and scheduling)。
Mesosphere可以允许用户来管理他们的数据中心或云服务,使用Mesosphere会让用户感觉就像是在一台大型服务器上直接进行操作。为了实现这一特性,Mesosphere创建了一个高伸缩性的资源池,所有的服务都可以从这个资源池中获取所需的资源(物理机或者是虚拟机)作为计算结点,并在此基础上构建出复杂的集群。所有由Mesosphere构建的集群都是高可用的,用户可以在同一个集群上对不同的工作负载进行扩展调度。例如可以在同一个集群上运行像 Marathon、Chronos、 Hadoop 以及Spark这样的分布式服务。Mesosphere基于开源软件Apache Mesos分布式系统内核所构建, Mesos被许多大公司所使用,像 Twitter、 Airbnb 以及Hubspot 都通过Mesos为网络规模级的服务提供了便利。Mesosphere使得应用的开发和部署过程变得更加快捷流畅,可以通过更大规模和更小的开销对服务进行部署和操作,而且几乎不需要对源码进行修改就可以获得更高的健壮性同时提升资源的利用效率。
我们正在与Google合作,并且将Mesosphere、kubernetes以及Google Cloud Platform三者结合起来,使得客户可以通过更大的规模启动服务和运行容器。今天,我们要宣布一个激动人心的消息:我们正在把Mesosphere和Google Cloud Platform结合起来,用户可以通过web app的方式,在几分钟之内就能部署好一个Mespsphere集群。此外,我们也把Kubernetes的功能融合进了Mesos,新版本的Mesos可以通过Docker的方式对工作负载进行操作。我们还将以上所介绍的技术结合在一起,给用户提供了商业级别的、高可用的、可用于生产环境的计算结构(compute fabric)。
通过我们新的web app ,开发者只需要通过轻点鼠标,就能创建一个容器集群。集群在创建过程中可以使用标准化的配置也可以使用由用户自己自定义的配置。App会自动安装并且帮用户配置好需要运行一个Mesosphere集群所需要的全部资源:包括Mesos内核、Zookeeper和Marathon以及OpenVPN ,这样用户就可以登录自己的集群进行操作。此外,令我们兴奋的是,这个功能很快就会被集成到Google Cloud Platform dashboard中,用户只要通过鼠标点击的方式,就能实现所有的复杂操作。也就是说,用户如果使用这样的服务,除了在Google Cloud Platform上运行配置好的实例之外,几乎不需要什么额外的成本。如果想要启动你自己的Mesosphere App,只需通过Google的身份认证登录,鼠标轻点,就可以很快创建出一个Mesos集群。
我们还将Kubernetes的功能融入进了Mesos,这样我们的Mesosphere产品生态系统就可以来管理和部署以Docker方式工作的服务。这种联合的计算结构可以让用户在任何地方运行服务,除了Google Cloud Platform,用户还可以将服务运行在自己的计算中心,或者其他的云平台上。用户可以在同一个Mesosphere集群上对Docker容器进行扩展,这种方式可以使用户感觉就像是在运行传统的Linux工作任务一样, 用户不论是通过Spark以及Hadoop进行数据分析,或者是执行shell脚本以及jar文件这样的传统任务,都可以在这个平台上进行。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步