

Redis安装配置及使用详解
1. 简介-两个程序通信,除了socket就是文件了,但是通过磁盘效率太低了,之前的RabbitMQ只是实现了消息的传递,现在要是实现数据的共享(一份数据,可供多人查阅),可以通过缓存实现,一个中间商broker。
可是程序之间是无法访问对方的内存地址的。所以其他程序和中间商的之间的通信是通过socket实现的。
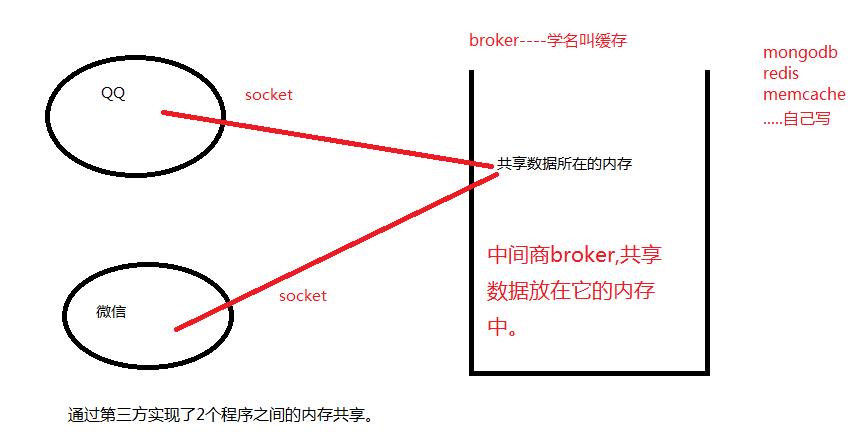
2.主流缓存系统
mongodb 直接持久化 :既存在内存,又同步到硬盘。 redis 半持久化 :默认是存在内存,通过手工调动,才会存到硬盘。 memcache 只能在内存,轻量级缓存。不能持久化。
参考源:http://blog.csdn.net/fgf00/article/details/52917154
一、Redis简介
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set –有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步.
单线程的,通过异步实现了高并发。
redis的安装请参照:http://www.cnblogs.com/momo8238/p/7580423.html
简单使用:
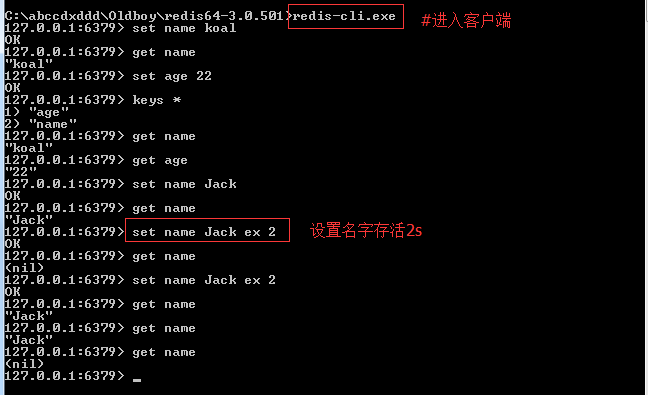
2、Python操作Redis
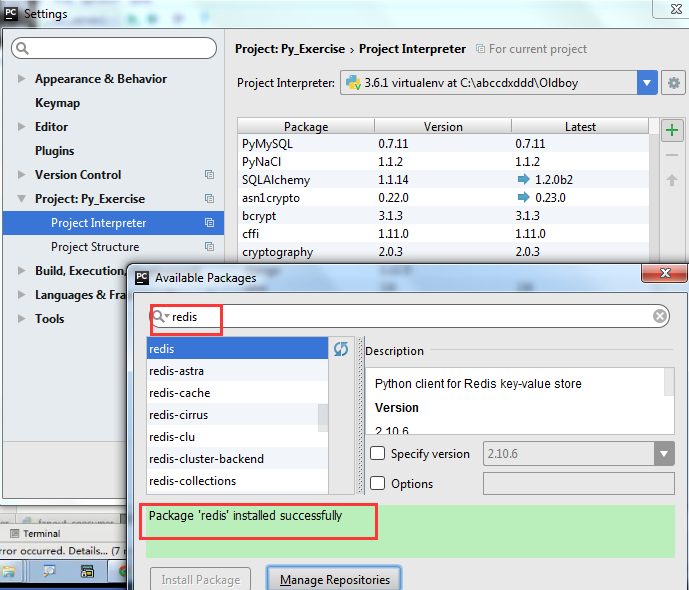
1)操作模式 redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py.在Pycharm中安装redis模块
先下载安装
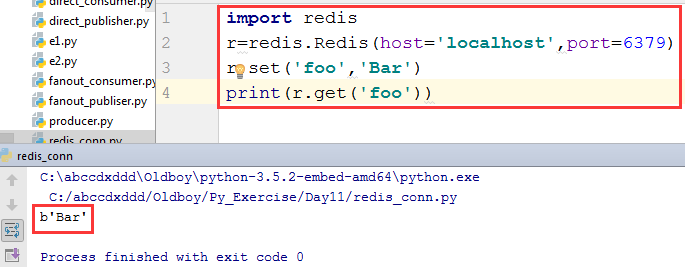
连接方法1:
import redis
r=redis.Redis(host='localhost',port=6379)
r.set('foo','Bar')
print(r.get('foo'))
效果:返回的是bytes类型。
2)连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print(r.get('foo'))
二、Redis 操作
1、string操作
- set(name, value, ex=None, px=None, nx=False, xx=False)
help set
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,当前set操作才执行
- setnx 、 setex 、 psetex
- mset(*args, **kwargs)
批量设置值
如:
mset n1 fgf a1 02
- mget(keys, *args)
批量获取
如:
mget a1 n1
- getset(name, value)
设置新值并获取原来的值
127.0.0.1:6379> getset a1 07
- getrange(key, start, end)
获取子序列(根据字节获取,非字符),相当于切片操作
参数:
name,Redis 的 name
start,起始位置(字节)
end,结束位置(字节)
> 127.0.0.1:6379> getrange n1 1 2
> "gf"
如: "中国人" ,3~5表示 "国"
- setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
127.0.0.1:6379> setrange n1 1 zh
127.0.0.1:6379> get n1
"fzh"
- setbit(name, offset, value)
# 对name对应值的二进制进行位操作。参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
127.0.0.1:6379> set name abcd # 我们对值内a进行修改
OK
127.0.0.1:6379> setbit name 6 1
(integer) 0
127.0.0.1:6379> get name
"cbcd" # 改b的话,从第8位开始数
----------------------------------
>>> ord('a')
97
>>> bin(97) # 把a改成c,97 ——> 99
'0b1100001' # 0110 0001 ——> 0110 0011 (第六位改为1)
- bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数 127.0.0.1:6379> set n a # a ——> 0110 0001 OK 127.0.0.1:6379> bitcount n # 3个1,统计二进制字符串里面有多少个1 (integer) 3 127.0.0.1:6379> setbit n 10 1 # 虽然a一个字节只有8位,但是这里没有限制。 (integer) 0 127.0.0.1:6379> setbit n 11 1 (integer) 0 127.0.0.1:6379> get n "a0"
什么时候用?一般用不到,不过有一个牛逼的场景可以用: (先转成ASCII码,再转成二进制)
统计在线用户数有多少,一般会怎么去算?当前有哪些用户在线
如果数据库存,每个字段都存在线用户有谁,都会占用很多空间。
# 每个用户是不是一个ID,ID是唯一的,假如2亿用户、1亿在线 127.0.0.1:6379> setbit user 1000 1 # 假如用户ID 1000登录 127.0.0.1:6379> setbit user 27 1 127.0.0.1:6379> setbit user 6000 1 127.0.0.1:6379> bitcount user # 查看在线用户 (integer) 3 127.0.0.1:6379> getbit user 27 # 查看用户在不在线,用户27在线 (integer) 1 127.0.0.1:6379> getbit user 28 # 0 说明用户不在线,用户28没在线 (integer) 0
按位来存,2亿用户,只占用2亿个位空间。increment
- incr(self, name, amount=1),increase
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(必须是整数)
# 注:同incrby
- decr(self, name, amount=1), decrease
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
# 参数:
# name,Redis的name
# amount,自减数(整数)
127.0.0.1:6379> incr login_users (integer) 1 127.0.0.1:6379> incr login_users (integer) 2 127.0.0.1:6379> incr login_users (integer) 3 127.0.0.1:6379> decr login_users (integer) 2 127.0.0.1:6379> decr login_users (integer) 1
- incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(浮点型)
127.0.0.1:6379> incrbyfloat nu 1.2
"1.2"
127.0.0.1:6379> incrbyfloat nu 1.2
"2.4"
127.0.0.1:6379> incrbyfloat nu 1.2
"3.6"
- append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
127.0.0.1:6379> set name gf
OK
127.0.0.1:6379> get name
"gf"
127.0.0.1:6379> append name feng
(integer) 6
127.0.0.1:6379> get name
"gffeng"
2、hash操作
hash 大家都比较熟悉(哈希算法:将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。)。那redis里的hash指的什么呢? 上面的str操作,name和age之间没有关系,如果特别多,就混了。 Hash操作,redis中Hash在内存中的存储格式如下图:
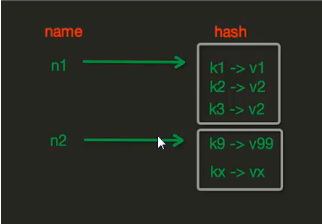
- hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)类似于字典
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
127.0.0.1:6379> hset user name fgf
(integer) 1
127.0.0.1:6379> hset user id 27
(integer) 1
127.0.0.1:6379> hgetall user # 查看所有
1) "name"
2) "fgf"
3) "id"
4) "27"
127.0.0.1:6379> hkeys user # 查看所有key
1) "name"
2) "id"
127.0.0.1:6379> hvals user # 查看所有值
1) "fgf"
2) "27"
- hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
127.0.0.1:6379> hmset info k1 1 k2 2
127.0.0.1:6379> hmget info k1 k2
1) "1"
2) "2"
- hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值
- hlen(name)
# 获取name对应的hash中键值对的个数
- hexists(name, key)
# 检查name对应的hash是否存在当前传入的key 127.0.0.1:6379> hexists user name (integer) 1 127.0.0.1:6379> hexists user age (integer) 0
- hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
- hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
127.0.0.1:6379> hincrby info k2 1
(integer) 3
127.0.0.1:6379> hincrby info k2 1
(integer) 4
- hincrbyfloat(name, key, amount=1.0)
- hscan(name, cursor=0, match=None, count=None) 过滤
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,
并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
127.0.0.1:6379> hscan info 0 match k*
1) "0"
2) 1) "k1"
2) "1"
3) "k2"
4) "4"
- hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
3、列表操作
127.0.0.1:6379> lpush names fgf fzh js # 左边放
(integer) 3
127.0.0.1:6379> lrange names 0 -1 # 先入后出
1) "js"
2) "fzh"
3) "fgf"
127.0.0.1:6379> rpush names A B # 右边放
(integer) 5
127.0.0.1:6379> lrange names 0 -1
1) "js"
2) "fzh"
3) "fgf"
4) "A"
5) "B"
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
127.0.0.1:6379> linsert names before B C
(integer) 6
127.0.0.1:6379> lrange names 3 -1
1) "A"
2) "C"
3) "B"
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
lindex(name, index)
# 在name对应的列表中根据索引获取列表元素
ltrim(name, start, end)
# 保留start-end索引之的值,移除其他值
127.0.0.1:6379> ltrim names 0 2
OK
127.0.0.1:6379> lrange names 0 -1
1) "js"
2) "fzh"
3) "fgf"
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
127.0.0.1:6379> rpush names2 AB
(integer) 1
127.0.0.1:6379> rpoplpush names names2
"fgf"
127.0.0.1:6379> lrange names 0 -1
1) "js"
2) "fzh"
127.0.0.1:6379> lrange names2 0 -1
1) "fgf"
2) "AB"
blpop(keys, timeout)
# 从左到右去删除对应列表的元素,无元素则等待设置的超时时间
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
4、集合操作
- sadd(name,values)
# name对应的集合中添加元素 127.0.0.1:6379> sadd name3 fgf a b b (integer) 3 127.0.0.1:6379> smembers name3 1) "fgf" 2) "b" 3) "a"
- scard(name)
# 获取name对应的集合中元素个数
- sdiff(keys, *args)
# 在第一个name对应的集合中且不在其他name对应的集合的元素集合 127.0.0.1:6379> sadd name4 b c d (integer) 3 127.0.0.1:6379> sdiff name3 name4 1) "fgf" 2) "a"
- sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
- sinter(keys, *args)
# 获取多一个name对应集合的交集
- sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
- sismember(name, value)
# 检查value是否是name对应的集合的成员
- smembers(name)
# 获取name对应的集合的所有成员
- smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
- spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
- srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
- srem(name, values)
# 在name对应的集合中删除某些值
- sunion(keys, *args)
# 获取多一个name对应的集合的并集
- sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
有序集合
- zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素 127.0.0.1:6379> zadd z1 10 fgf 7 fzh 2 js 5 ajs (integer) 3 127.0.0.1:6379> zrange z1 0 -1 1) "js" 2) "ajs" 3) "fzh" 4) "fgf" 127.0.0.1:6379> zrange z1 0 -1 withscores 1) "js" 2) "2" 3) "ajs" 4) "5" 5) "fzh" 6) "7" 7) "fgf" 8) "10"
- zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数 127.0.0.1:6379> zcount z1 5 10 (integer) 3
- zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
- zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始) 127.0.0.1:6379> zrank z1 fgf (integer) 3 127.0.0.1:6379> zrank z1 ajs (integer) 1
- zrem(name, values)
# 删除name对应的有序集合中值是values的成员
- zremrangebyrank(name, min, max)
# 根据排行范围删除 127.0.0.1:6379> zremrangebyrank z1 1 3 (integer) 3
- zremrangebyscore(name, min, max)
# 根据分数范围删除
- zremrangebylex(name, min, max)
# 根据值返回删除
- zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
- zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集 # aggregate的值为: SUM MIN MAX 127.0.0.1:6379> zadd z2 98 fgf 100 fzh 90 js (integer) 3 127.0.0.1:6379> zadd z3 88 fgf 89 fzh 92 js (integer) 3 127.0.0.1:6379> ZINTERSTORE z4 2 z2 z3 # 2 指后边2个集合的交集 (integer) 3 127.0.0.1:6379> zrange z2 0 -1 withscores 1) "js" 2) "90" 3) "fgf" 4) "98" 5) "fzh" 6) "100" 127.0.0.1:6379> zrange z3 0 -1 withscores 1) "fgf" 2) "88" 3) "fzh" 4) "89" 5) "js" 6) "92" 127.0.0.1:6379> zrange z4 0 -1 withscores 1) "js" 2) "182" 3) "fgf" 4) "186" 5) "fzh" 6) "189"
- zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集 # aggregate的值为: SUM MIN MAX
5、其他操作
del(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名
move(name, db))
# 将redis的某个值移动到指定的db下,若有则不移动
select db_name
# 切换到其他db,redis有16个db
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
三、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis
import time
pool = redis.ConnectionPool(host='10.211.55.4', port=6379, db=5)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.set('name', 'alex')
time.sleep(60)
pipe.set('role', 'sb')
pipe.execute()
四、发布订阅
收音机举例发布订阅
redishelper.py
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='10.211.55.4')
self.chan_sub = 'fm104.5'
self.chan_pub = 'fm104.5'
def public(self, msg):
self.__conn.publish(self.chan_pub, msg)
return True
def subscribe(self):
pub = self.__conn.pubsub() # 打开收音机
pub.subscribe(self.chan_sub) # 调频道
pub.parse_response() # 准备接收
return pub
订阅方
from RedisHelper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response()
print (msg)
发布方
from RedisHelper import RedisHelper
obj = RedisHelper()
obj.public('hello')

