

RabbitMQ 使用详细介绍
1. 实现最简单的队列通信
2. producer端
# !/usr/bin/env python
import pika
#通过这个实例,先去建立一个socket,默认端口15672
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost')
)
channel = connection.channel() #声明一个管道,在管道里发消息
# 在管道里面声明queue队列。
channel.queue_declare(queue='hello')
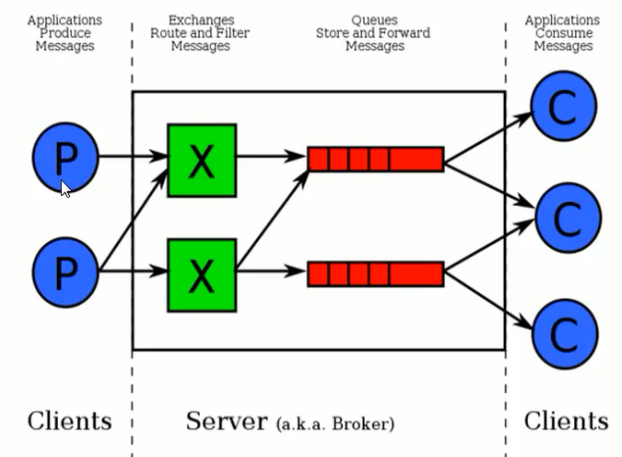
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
#在管道里发消息
channel.basic_publish(exchange='',
routing_key='hello', #队列名字
body='Hello World!') #消息
print(" [x] Sent 'Hello World!'")
connection.close() #直接把链接关闭,不需要关闭管道。
3.consumer端
# _*_coding:utf-8_*_
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost')) #建立链接
channel = connection.channel() #建立管道
# You may ask why we declare the queue again ‒ we have already declared it in our previous code.
# We could avoid that if we were sure that the queue already exists. For example if send.py program
# was run before. But we're not yet sure which program to run first. In such cases it's a good
# practice to repeat declaring the queue in both programs.
# 为什么又声明了一个‘hello’队列?
# 如果确定已经声明了,可以不声明。但是你不知道那个机器先运行,所以可以再次声明,这样就不会报错。
channel.queue_declare(queue='hello') #说明从哪个队列里面收消息
# ch 管道的内存对象地址
def callback(ch, method, properties, body):
print('---->',ch,method,properties)
print(" [x] Received %r" % body)
#开始消费消息
channel.basic_consume(callback, #如果收到消息,就调用callback函数来处理消息
queue='hello', #表示从哪个队列里收消息
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #之前的只是声明了语法,这条语句才是真正开始收数据
4.运行

5. 上面实现的实例是一个生产者,一个消费者模型。下面尝试建立一个生产者,多个消费者的模型。
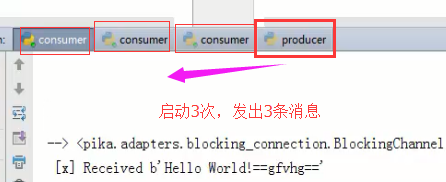
启动3个客户端, consumer1,consumer2, consumer3。再启动producer,producer发的第1条消息被consumer1收到了,producer发的第2条消息被consumer2收到了,producer发的第3条消息被consumer3收到了,可以看出一对多情况下,默认采用的是轮询机制。
6. 如果消费者收到消息以后,处理的过程中down机了。当生产者收到消费者端发来的消息处理完的确认函以后,生产者才会把消息从队列中删除。
如果处理的过程中突然down机了,客户端就没法发确认函了。生产者就认为没有处理完。
consumer.py 中 no_ack=True # no acknowledge 不管有没有处理完,都不会给生成者端发消息.
一般都会注释掉这句,#no_ack=True.意思就是处理完了,请给我一个确认函。然后服务器就把把这个任务从队列里面删除掉。
- 假如消费者处理消息需要15秒,如果当机了,那这个消息处理明显还没处理完,怎么处理? (可以模拟消费端断了,分别注释和不注释 no_ack=True 看一下) 你没给我回复确认,就代表消息没处理完。
-
上面的效果消费端断了就转到另外一个消费端去了,但是生产者怎么知道消费端断了呢? 因为生产者和消费者是通过socket连接的,socket断了,就说明消费端断开了。
- 如果服务器端发了一个任务给消费者1,消费者1在处理的过程中,突然down机了(socket断了)。服务器端没有收到确认函,则这个任务还存在于队列中,就会发给消费者2进行处理,直至处理完毕为止。通过这种机制,就会保证消息会被全部处理完。
7. 在安装目录下的 sbin文件夹下,有一个rabbitmqctl的文件,它是管理rabbitMQ的一个工具。

rabbitmqctl.bat list_queues 用这条命令可以查看当前有几个队列,以及每个队列里面存在的消息个数。

8. 客户端处理完消息以后,必须主动跟服务器端确认。否则如果客户端处理完消息以后,又拿着这条消息去干别的事情的话,服务器端一直收不到确认函,就不合理了。
9.如果队列里面还有一条消息,此时服务器端down机了,会发生什么呢?
尝试down掉服务器端机器,rum中输入services.msc,然后找到这个程序,右击点停止。

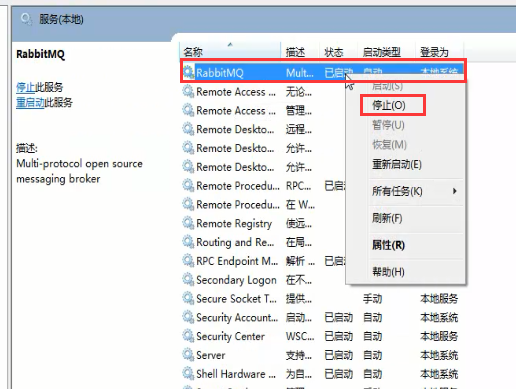
然后重启,测试效果:发现队列都丢了。因为队列是保存在内存中的。
10. 为了保证队列不再丢失,在每次声明队列的时候,参数中加上durable=True 这句,服务器端和客户端都需要写上这句。把队列持久化了,但是里面的消息丢失了。如果想要消息也保留住,需要在生产者端加下面一句。
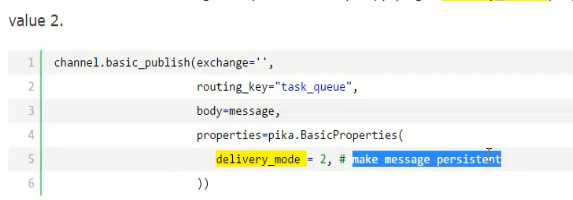
11. 测试上面的效果

插播一句,有可能会遇到以下问题

原因:这是因为已经定义的队列,再次定义是无效的,这就是幂次原理。RabbitMQ不允许重新定义一个已有的队列信息,也就是说不允许修改已经存在的队列的参数。如果你非要这样做,只会返回异常。所以做测试的时候,可以使用不同的队列进行比较。不能在同一个队列中做修改。
producer.py中的程序
# !/usr/bin/env python
import pika
#通过这个实例,先去建立一个socket,默认端口15672
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost')
)
channel = connection.channel() #声明一个管道,在管道里发消息
# 在管道里面声明queue队列。
channel.queue_declare(queue='hello1',durable=True)
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
#在管道里发消息
channel.basic_publish(exchange='',
routing_key='hello', #队列名字
body='Hello World!', #消息
properties=pika.BasicProperties(
delivery_mode=2,#把消息持久化。
)
)
print(" [x] Sent 'Hello World!'")
connection.close() #直接把队列关闭,不需要关闭管道。
consumer.py中的程序
# _*_coding:utf-8_*_
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost')) #建立链接
channel = connection.channel() #建立管道
# You may ask why we declare the queue again ‒ we have already declared it in our previous code.
# We could avoid that if we were sure that the queue already exists. For example if send.py program
# was run before. But we're not yet sure which program to run first. In such cases it's a good
# practice to repeat declaring the queue in both programs.
# 为什么又声明了一个‘hello’队列?
# 如果确定已经声明了,可以不声明。但是你不知道那个机器先运行,所以可以再次声明,这样就不会报错。
channel.queue_declare(queue='hello1',durable=True) #说明从哪个队列里面收消息
#ch:管道的内存对象地址
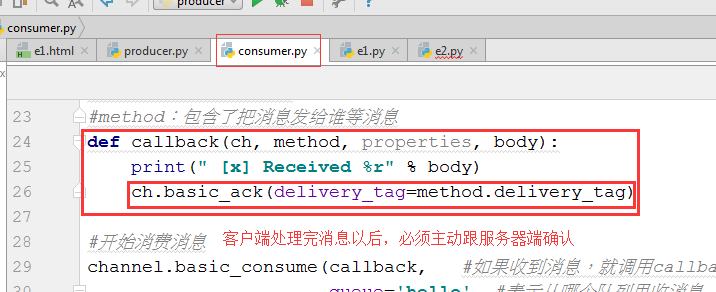
#method:包含了把消息发给谁等消息
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
#开始消费消息
channel.basic_consume(callback, #如果收到消息,就调用callback函数来处理消息
queue='hello', #表示从哪个队列里收消息
#no_ack=True #no acknowledgement,不管有没有处理完,都不会给生成者端发消息。
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #之前的只是声明了语法,这条语句才是真正开始收数据
12. 上面的例子是1个生产者,3个消费者。平均分发消息。下面引入权重分配任务。----能者多劳
服务器端给客户端发消息的时候,如果当期队列中有1条那么,那么就不给你发了。
只需要在消费者端加一句话:channel.basic_qos(prefetch_count=1)
做模拟的时候,可以写2个消费者,其中1个sleep30秒-代表性能较差的机器。生产者一直不停发消息,当性能较差的机器一直没有处理完任务的时候,所有的任务都跑到了另外一个消费者处。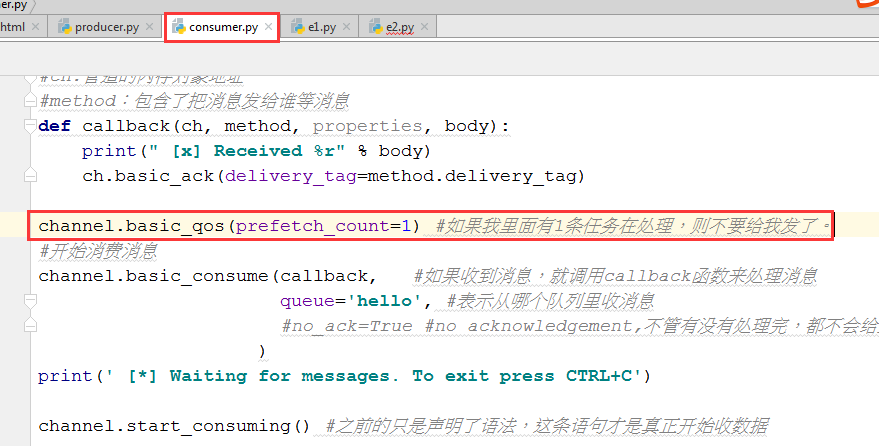
13, 做一个广播的实例,一个生产者发消息,所有的消费者都能收到。需要用到exchange。exchange类似于一个转发器。
exchange必须精确的知道收到的消息要发给谁。exchange的类型决定了怎么处理, 类型有以下几种:
- fanout: 所有绑定到此exchange的queue都可以接收消息
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
- topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息。
1)fanout 纯广播、all
需要queue和exchange绑定,因为消费者不是和exchange直连的,消费者是连在queue上,queue绑定在exchange上,消费者只会在queu里读消息.消息是实时的,如果生产者发的时候,消费者错过了,那就再也收不到这条消息了。类似于收音机的模型。

生产者的关键代码:
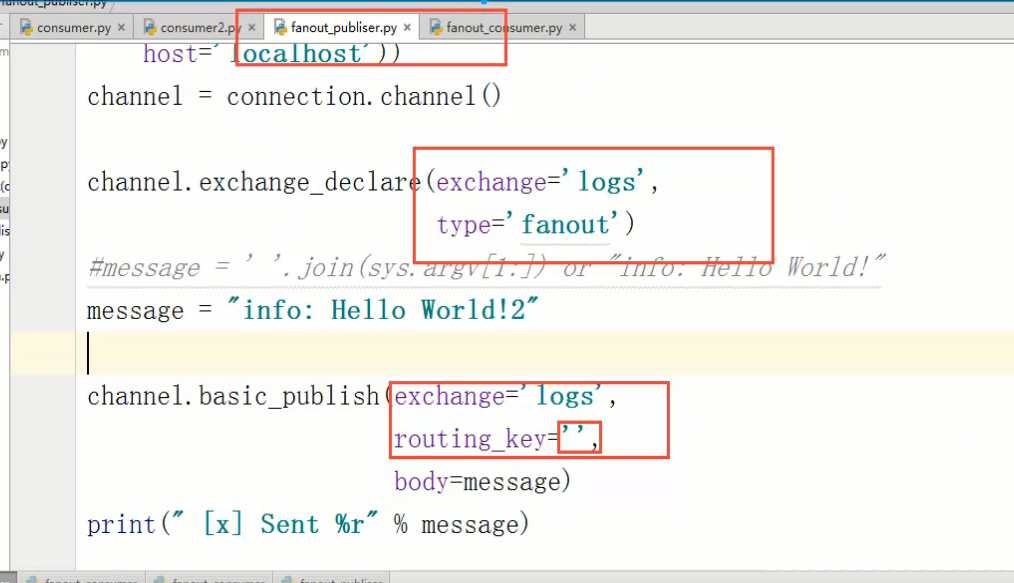
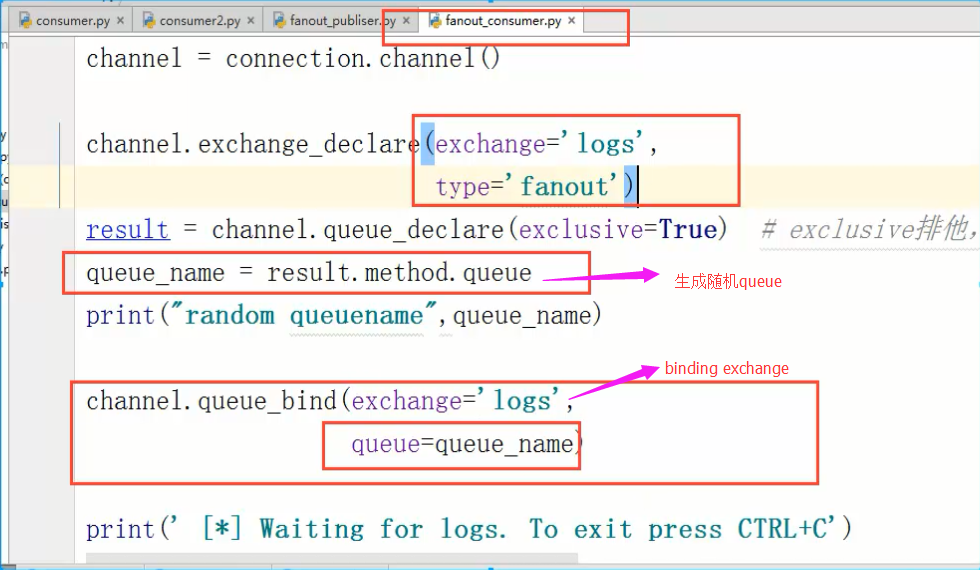
消费者的关键代码:
发送端 publisher 发布、广播
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost')
)
channel = connection.channel()
#注意:这里是广播,不需要声明queue
channel.exchange_declare(exchange='logs', #声明广播管道
type='fanout'
)
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='', #queue名字为空,因为是广播,所以不需要声明queue。但是这句必须有。
body=message)
print(" [x] Sent %r" % message)
connection.close()
接收端 subscriber 订阅
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost')
)
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True)
# exclusive-排它的,唯一的。不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
#随机生成,自动删除。queue对象的名字叫result。
queue_name = result.method.queue
channel.queue_bind(exchange='logs', #queue绑定到转发器上。
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
可能因为程序版本的问题,没法使用type关键词。否则会报错,可以把下面的注释掉,直接按照顺序写参数即可正常运行。

#channel.exchange_declare(exchange='logs', #声明广播管道
# type='fanout'
# )
channel.exchange_declare('logs', #声明广播管道
'fanout'
)
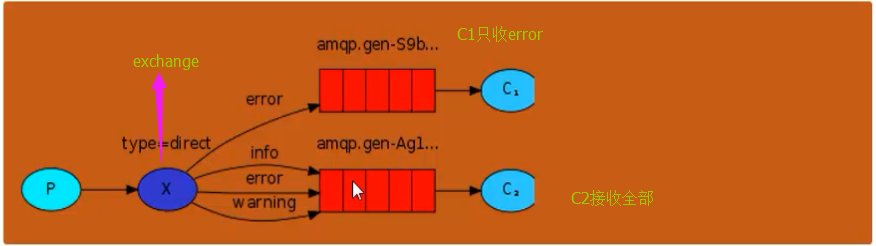
2)有选择地接收消息 (exchange type=direct),接收者可以过滤消息,只收我想要的消息.
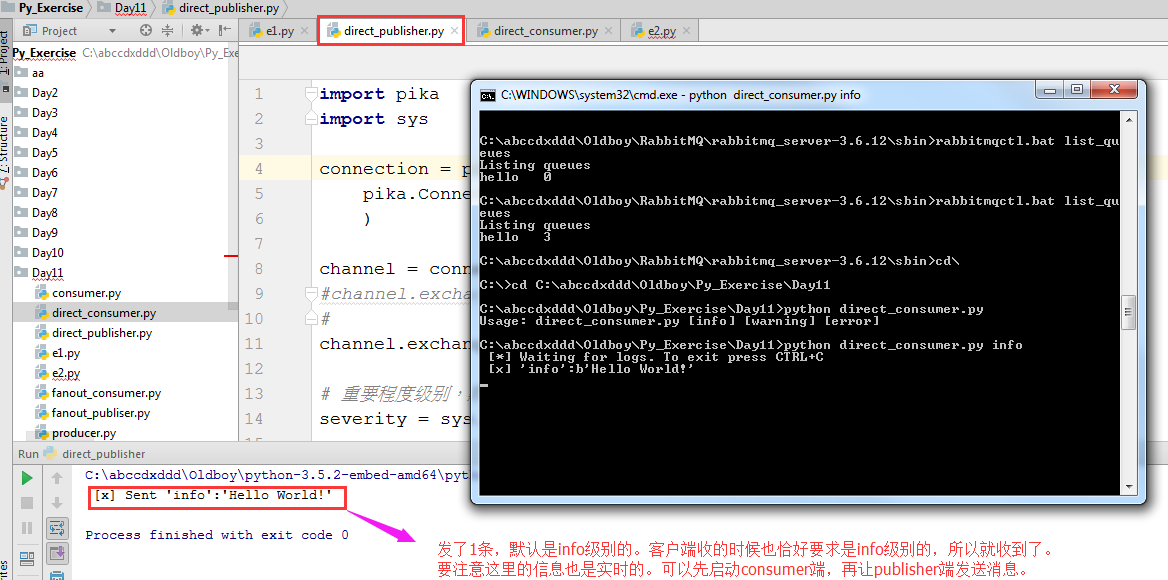
当运行服务器端,后运行客户端以后,发现报错了,因为没有带参数。


想带参数的话,只能用cmd了。
再启动一个客户端


服务器端启动,默认用info模式发,看效果。该收的收到了,不该收的没收到。

用cmd启动服务器端,带参数的,发1条warning消息。测试效果:
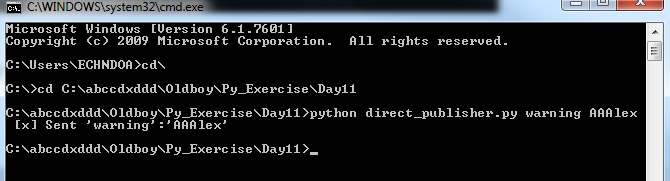
效果如下:
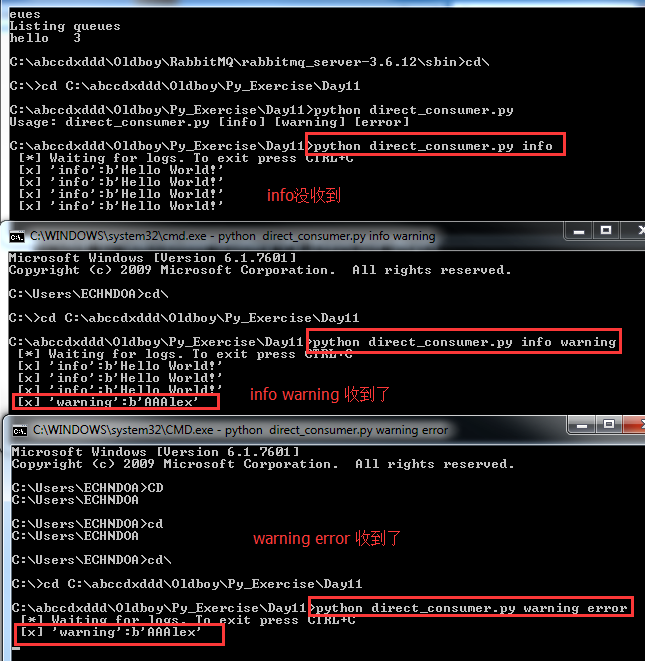
测试结果一切良好。
14. 细致的消息过滤广播模式。现在是收所有的info,所有的warning,所有的error。想区分哪个警告是哪个客户端发来的,就需要更细致的消息过滤了。分别代表1.“所有包含orange的”;2-“所有以rabbit结尾的”; 3-"所有以lazy开头的”.类似于一个动态的匹配。

server端:
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost')
)
channel = connection.channel()
#channel.exchange_declare(exchange='topic_logs',
# type='topic')
channel = connection.channel()
channel.exchange_declare('topic_logs',
'topic')
#可以自己填要发的消息,也可以使用默认的,但是格式是XXX.info的格式。
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
客户端
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost')
)
channel = connection.channel()
#channel.exchange_declare(exchange='topic_logs',
# type='topic')
channel.exchange_declare('topic_logs',
'topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
测试效果:
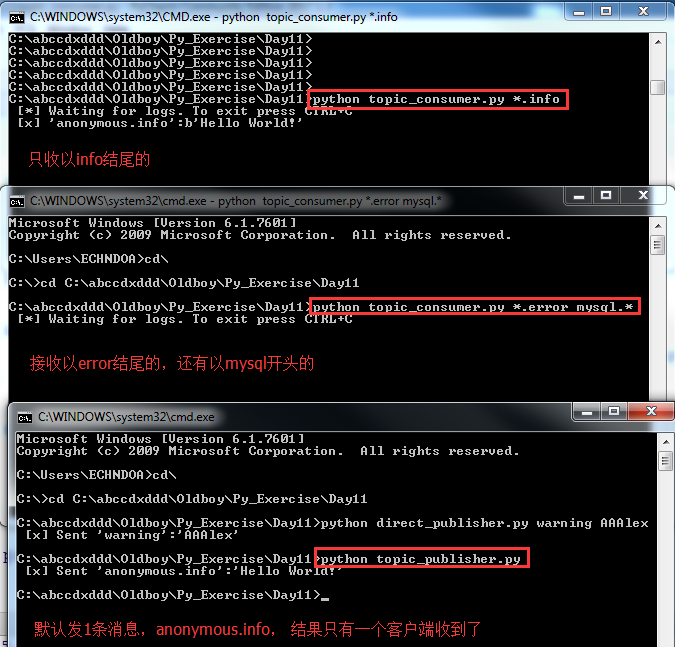
python topic_consumer.py # 代表什么都收。
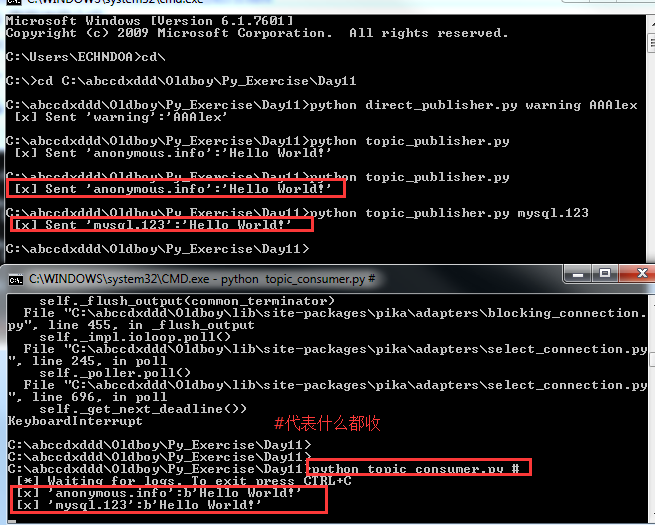
书写接收内容的规则如下:

