

编码好文
参考来源:http://blog.csdn.net/pipisorry/article/details/44136297
查看默认编码方式:
import sys print(sys.getdefaultencoding())
Python源码的编码方式
str与字节码
s = "人生苦短"s是个字符串,它本身存储的就是字节码(这个s可能是文件中的一行,或者命令行中的一行?)。那么这个字节码是什么格式的?
如果这段代码是在解释器上输入的,那么这个s的格式就是解释器的编码格式,对于windows的cmd而言,就是gbk。
如果将段代码是保存后才执行的,比如存储为utf-8,那么在解释器载入这段程序的时候,就会将s初始化为utf-8编码。
unicode与str
我们知道unicode是一种编码标准,具体的实现标准可能是utf-8,utf-16,gbk ......
Python 在内部使用两个字节来存储一个unicode,使用unicode对象而不是str的好处,就是unicode方便于跨平台。
你可以用如下两种方式定义一个unicode:(在python2中)
1 s1 = u"人生苦短"
2 s2 = unicode("人生苦短", "utf-8")
python3
字符串实际就是用的unicode,直接s = "人生苦短"
py3定义bytes使用sb = b'abcd'
a='人生苦短' print(type(a)) b=b'abcd' print(type(b))
<class 'str'> <class 'bytes'>
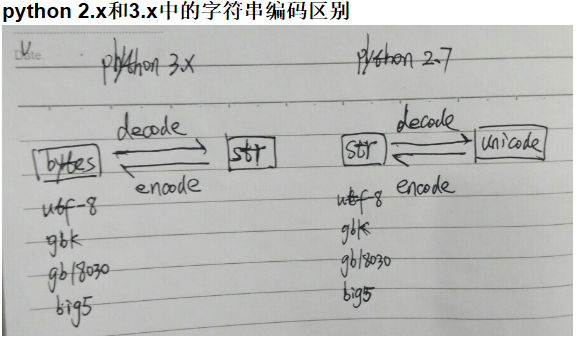
2.x中字符串有str和unicode两种类型,str有各种编码区别,unicode是没有编码的标准形式。unicode通过编码转化成str,str通过解码转化成unicode。
3.x中将字符串和字节序列做了区别,字符串str是字符串标准形式与2.x中unicode类似,bytes类似2.x中的str有各种编码区别。bytes通过解码转化成str,str通过编码转化成bytes。
2.x中可以查看unicode字节序列,3.x中不能。
Python 2:Python 2的源码.py文件默认的编码方式为ASCII
如果想使用一种不同的编码方式来保存python代码,我们可以在每个文件的第一行放置编码声明(encoding declaration)。
以下声明定义.py文件使用windows-1252编码方式:# -*- coding: windows-1252 -*-
Note: 1. 从技术上说,字符编码的重载声明也可以放在第二行,如果第一行被类UNIX系统中的hash-bang命令占用了。
2. 了解更多信息,请参阅PEP263: 指定Python源码的编码方式。
Python 3:Python 3的源码.py文件 的默认编码方式为UTF-8
Python 3.x中的Unicode
在Python 3.0之后的版本中,所有的字符串都是使用Unicode编码的字符串序列,同时还有以下几个改进:
1、默认编码格式改为unicode
2、所有的Python内置模块都支持unicode
3、不再支持u中文的语法格式
所以,对于Python 3.x来说,编码问题已经不再是个大的问题,基本上很少遇到编码异常。
在Python 3,所有的字符串都是使用Unicode编码的字符序列。不再存在以UTF-8或者CP-1252编码的情况。也就是说,这个字符串是以UTF-8编码的吗?不再是一个有效问题。UTF-8是一种将字符编码成字节序列的方式。如果需要将字符串转换成特定编码的字节序列,Python 3可以为你做到。如果需要将一个字节序列转换成字符串,Python 3也能为你做到。字节即字节,并非字符。字符在计算机内只是一种抽象。字符串则是一种抽象的序列。
>>> s = "深入 Python">>> len(s)9>>> s[0]"深">>> s + " 3""深入 Python 3"
-
Python中,字符串可以想像成由字符组成的元组。
-
Just like getting individual items out of a list, you can get individual characters out of a string using index notation. 与取得列表中的元素一样,也可以通过下标记号取得字符串中的某个字符。
python中设置默认编码defaultencoding
设置defaultencoding的代码如下:
1 reload(sys)
2 sys.setdefaultencoding('utf-8')如果你在python中进行编码和解码的时候,不指定编码方式,那么python就会使用defaultencoding。
比如上一节例子中将str编码为另一种格式,就会使用defaultencoding。
s.encode("utf-8") 等价于 s.decode(defaultencoding).encode("utf-8")
Note: 这个过程是s先通过defaultencoding解码为unicode,再编码为utf-8类型的编码。
再比如你使用str创建unicode对象时,如果不说明这个str的编码格式,那么程序也会使用defaultencoding。
u = unicode("人生苦短") 等价于 u = unicode("人生苦短",defaultencoding)
默认的defaultcoding ascii是许多错误的原因,所以早早的设置defaultencoding是一个好习惯。
文件头声明编码
关于python文件头部分知识的讲解
顶部的:# -*- coding: utf-8 -*-或者# coding: utf-8目前有三个作用
- 如果代码中有中文注释,就需要此声明。
- 比较高级的编辑器(比如我的emacs),会根据头部声明,将此作为代码文件的格式。
- 程序会通过头部声明,解码初始化 u"人生苦短",这样的unicode对象,(所以头部声明和代码的存储格式要一致)。
Python 3.4.1 (v3.4.1:c0e311e010fc, May 18 2014, 10:38:22) [MSC v.1600 32 bit (In
02.tel)] on win32
03.Type "help", "copyright", "credits" or "license" for more information.
04.>>> ss = '北京市'
05.>>> type(ss)
06.<class 'str'>
07.>>> us = ss.encode('gbk')
08.>>> type(us)
09.<class 'bytes'>
10.>>> us
11.b'\xb1\xb1\xbe\xa9\xca\xd0'
12.>>> utfs = ss.encode('utf-8')
13.>>> print(utfs)
14.b'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82'
15.>>> type(utfs)
16.<class 'bytes'>
17.>>> xx = utfs.decode('utf-8')
18.>>> type(xx)
19.<class 'str'>
20.>>> print(xx)
21.北京市
直接encode, decode后对应的打印结果是内存地址。

