
Chrome 页面呈现原理与性能优化
Chrome 基本架构介绍
整体架构
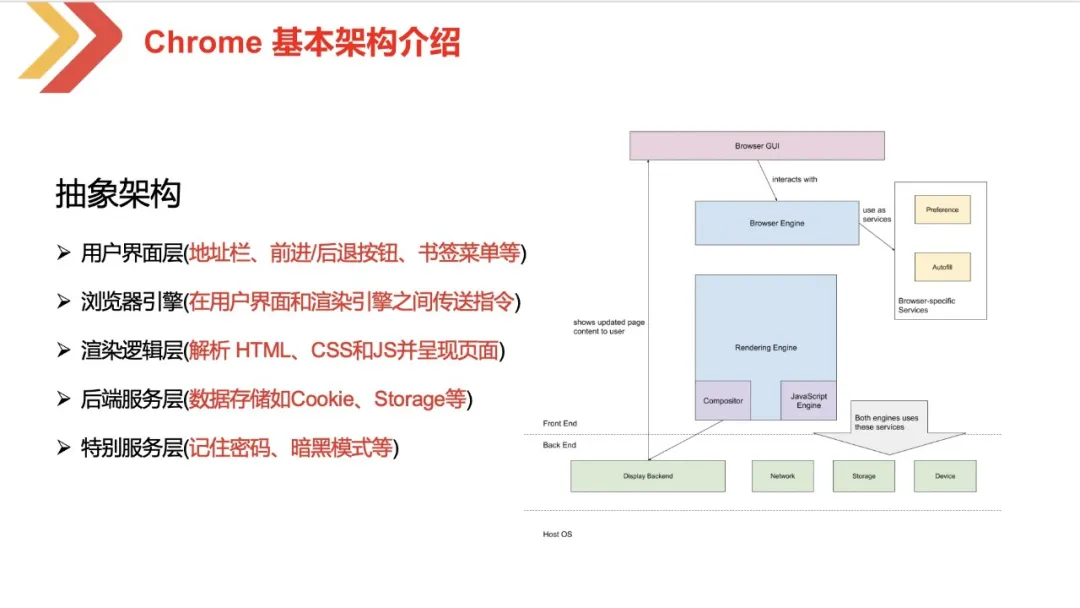
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源,这里所说的资源一般是指 HTML 文档,也可以是 PDF、图片或其他的类型。大体上,浏览器可以分为五部分:
-
用户界面,主要负责展示页面中,除了 page 本身的内容,我们可以粗略地理解为打开一个空页面的时候呈现的界面就是浏览器的用户界面(GUI)。
-
浏览器引擎,这里个人认为主要指的是在用户界面和渲染引擎之间传递指令,以及调度浏览器各方面的资源,协调为呈现页面、完成用户指令而工作。
-
呈现引擎,按图中看,包含了一个 compositor(合成器)和 Javascript Engine(JS解释引擎)。分别是负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上 和 用于解析和执行 JavaScript 代码。
-
后端服务层,这里包含了一些后端服务。比如网络请求层(network)、数据存储,浏览器需要在硬盘上保存各种数据,例如 Cookie、Storage等。
-
特别服务层,这里主要指的是一些浏览器自带的服务,比如你填完某个网站的账号密码,浏览器可以帮你记住账号密码,又比如开启浏览器的暗黑模式等特殊的服务。
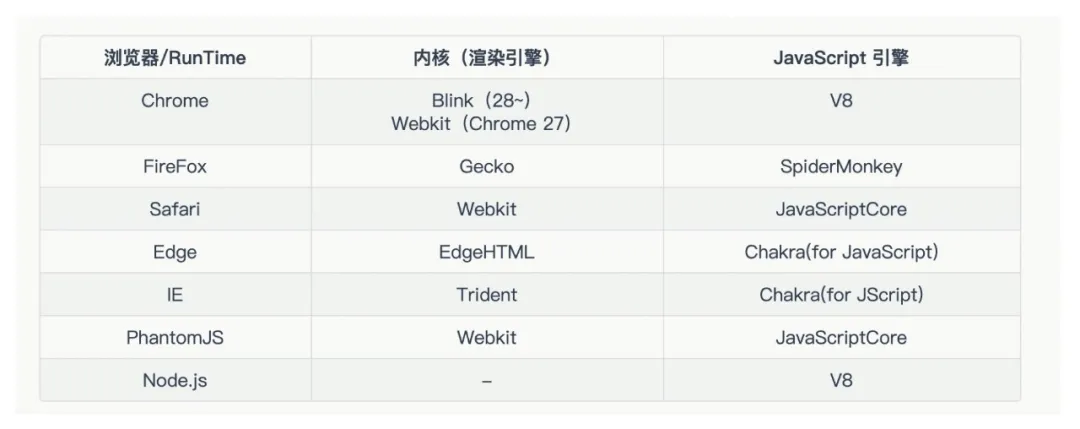
以上,对前端来说,比较重要的是渲染引擎(一些文章也叫浏览器引擎)。我们可以看看都有哪些渲染引擎的内核。
多进程架构
早期的web浏览器是单进程的,发生⻚⾯⾏为不当、浏览器错误、浏览器插件等错误都会引起整个浏览器或当前运 ⾏的选项卡关闭。因此Chrome将chromium应⽤程序放在相互隔离的独⽴的进程,也就是多进程的一个架构。

多进程的优势有:
- 防⼀个⻚⾯崩溃影响整个浏览器
- 安全性和沙盒,由于操作系统提供了限制进程权限的方法,因此浏览器可以从某些功能中,对某些进程进行沙箱处理。例如,Chrome 浏览器可以对处理用户输入(如渲染器)的进程,限制其文件访问的权限。
- 进程有⾃⼰的私有内存空间,可以拥有更多的内存。
多进程的劣势有:
- 给每个进程分配了单独的内存,尽管Chrome本身有一些优化策略,比如为了节省内存,Chrome限制了它可以启动的进程数量。限制因设备的内存和CPU功率⽽异,但当Chrome达到限制时,它会在⼀个进程中开始从同⼀站点运⾏多个选项卡。
- 有更高的资源占用。因为每个进程都会包含公共基础结构的副本(如 JavaScript 运行环境),这就意味着浏览器会消耗更多的内存资源。
多进程的架构,还有优化的地方,因此 Chrome 未来的架构是一个面向服务的架构,将浏览器程序的每个部分,作为一项服务运行,从而可以轻松拆分为不同的流程或汇总为同一个流程。这样可以做到,当 Chrome 在强大的硬件上运行时,它可能会将每个服务拆分为不同的进程,从而提供更高的稳定性,但如果它位于资源约束的设备上,Chrome 会将服务整合到一个进程中,从而整合流程以减少内存使用。
关于架构这章,更详细的内容可以看我这篇文章,《一文带你看透 Chrome 浏览器架构》
浏览器中页面渲染过程
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、栅格化和显示。如图:
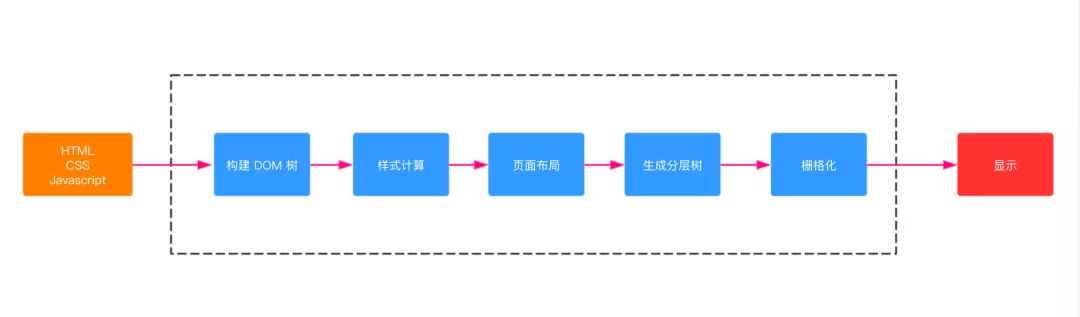
- 渲染进程将 HTML 内容转换为能够读懂DOM 树结构。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的styleSheets,计算出 DOM 节点的样式。
- 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
- 合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上。
构建 DOM 树
浏览器从网络或硬盘中获得HTML字节数据后会经过一个流程将字节解析为DOM树,先将HTML的原始字节数据转换为文件指定编码的字符,然后浏览器会根据HTML规范来将字符串转换成各种令牌标签,如html、body等。最终解析成一个树状的对象模型,就是dom树。

具体步骤:
- 转码(Bytes -> Characters)—— 读取接收到的 HTML 二进制数据,按指定编码格式将字节转换为 HTML 字符串
- Tokens 化(Characters -> Tokens)—— 解析 HTML,将 HTML 字符串转换为结构清晰的 Tokens,每个 Token 都有特殊的含义同时有自己的一套规则
- 构建 Nodes(Tokens -> Nodes)—— 每个 Node 都添加特定的属性(或属性访问器),通过指针能够确定 Node 的父、子、兄弟关系和所属 treeScope(例如:iframe 的 treeScope 与外层页面的 treeScope 不同)
- 构建 DOM 树(Nodes -> DOM Tree)—— 最重要的工作是建立起每个结点的父子兄弟关系
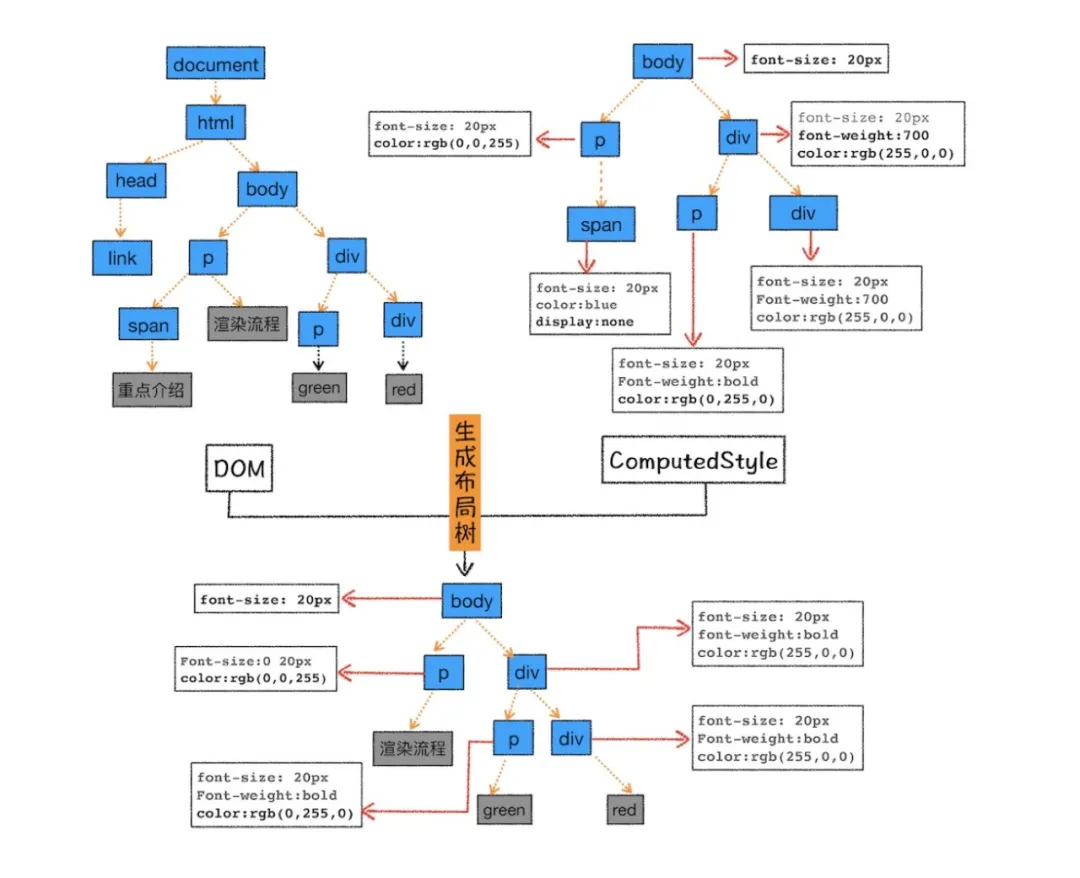
样式计算
渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
CSS 样式来源主要有 3 种,分别是通过 link 引用的外部 CSS 文件、style标签内的 CSS、元素的 style 属性内嵌的 CSS。,其样式计算过程主要为:

可以看到上面的 CSS 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。处理完成后再处理样式的继承和层叠,有些文章将这个过程称为CSSOM的构建过程。
页面布局
布局过程,即排除 script、meta 等功能化、非视觉节点,排除 display: none 的节点,计算元素的位置信息,确定元素的位置,构建一棵只包含可见元素布局树。如图:
其中,这个过程需要注意的是回流和重绘,关于回流和重绘,详细的可以看我另一篇文章《浏览器相关原理(面试题)详细总结二》,这里就不说了~
生成分层树
页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree),如图:
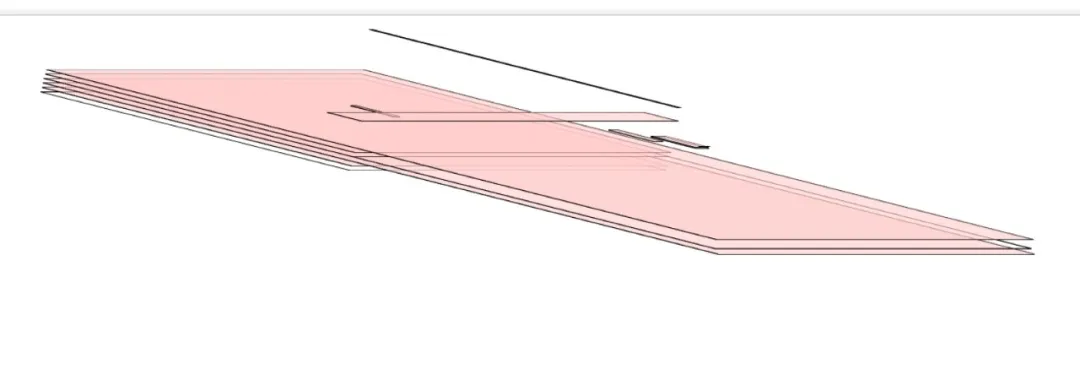
如果你熟悉 PS,相信你会很容易理解图层的概念,正是这些图层叠加在一起构成了最终的页面图像。在浏览器中,你可以打开 Chrome 的"开发者工具",选择"Layers"标签。渲染引擎给页面分了很多图层,这些图层按照一定顺序叠加在一起,就形成了最终的页面。
并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。那么需要满足什么条件,渲染引擎才会为特定的节点创建新的层呢?详细的可以看我另一篇文章《浏览器相关原理(面试题)详细总结二》,这里就不说了~
栅格化
合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。如图:
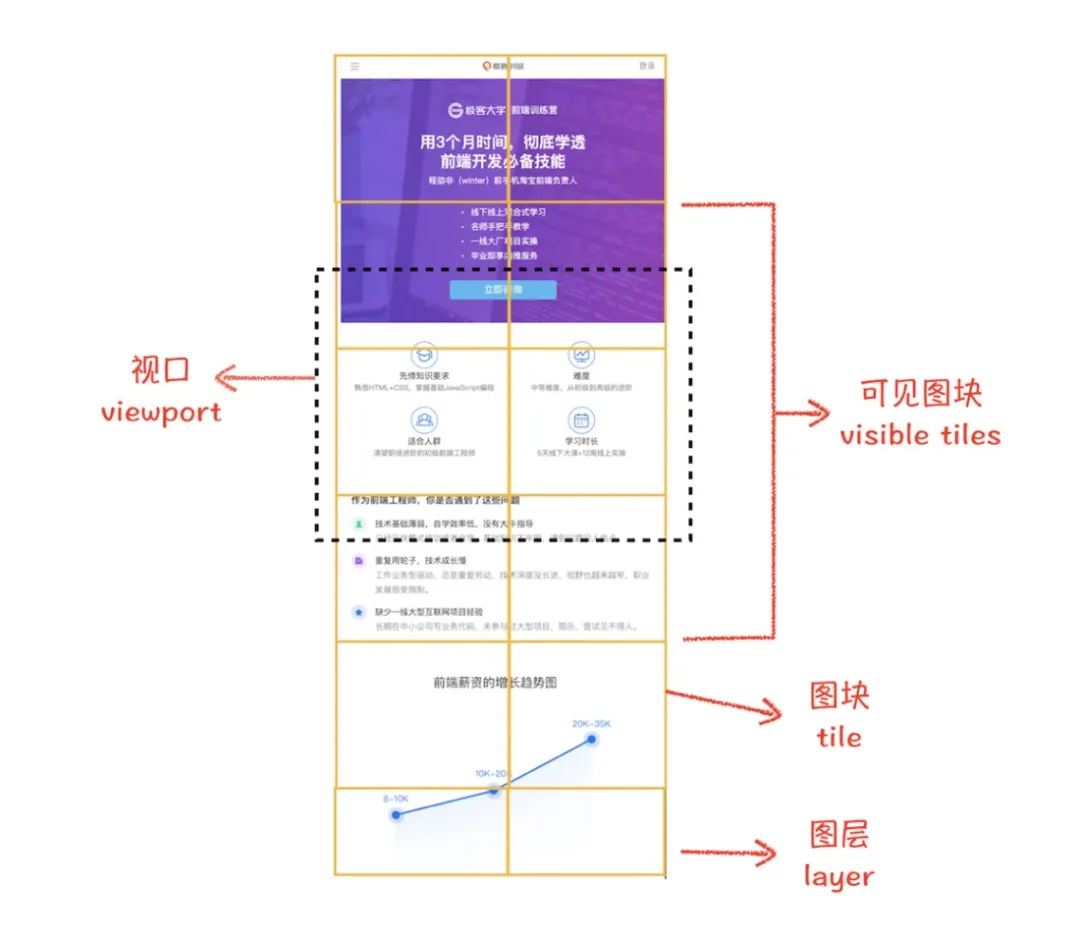
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
显示
最后,合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上,渲染过程完成。
浏览器中的JavaScript运行机制
JavaScript如何工作的,首先要理解几个概念,分别是JS Engine(JS引擎)、Context(执行上下文)、Call Stack(调用栈)、Event Loop(事件循环)。
JS Engine(JS引擎)
JavaScript引擎就是用来执行JS代码的, 通过编译器将代码编译成可执行的机器码让计算机去执行。目前比较流行的就是V8引擎,Chrome浏览器和Node.js采用的引擎就是V8引擎。引擎主要由堆(Memory Heap)和栈(Call Stack)组成。
- Heap(堆) - JS引擎中给对象分配的内存空间是放在堆中的
- Stack(栈)- 这里存储着JavaScript正在执行的任务。每个任务被称为帧(stack of frames)
Context(执行上下文)
执行上下文是 JavaScript 执行一段代码时的运行环境,比如调用一个函数,就会进入这个函数的执行上下文,确定该函数在执行期间用到的诸如 this、变量、对象以及函数等。
JavaScript 中有三种执行上下文类型。
全局执行上下文— 这是默认或者说基础的上下文,任何不在函数内部的代码都在全局上下文中。它会执行两件事:创建一个全局的 window 对象(浏览器的情况下),并且设置 this 的值等于这个全局对象。一个程序中只会有一个全局执行上下文。函数执行上下文— 每当一个函数被调用时, 都会为该函数创建一个新的上下文。每个函数都有它自己的执行上下文,不过是在函数被调用时创建的。函数上下文可以有任意多个。每当一个新的执行上下文被创建,它会按定义的顺序(将在后文讨论)执行一系列步骤。Eval 函数执行上下文— 执行在 eval 函数内部的代码也会有它属于自己的执行上下文,但由于 JavaScript 开发者并不经常使用 eval,所以在这里我不会讨论它。
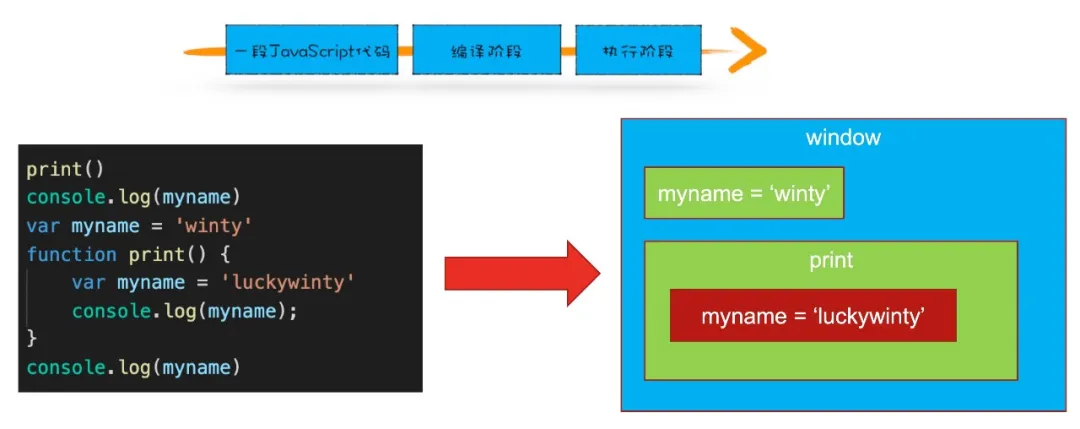
创建执行上下文有两个阶段:1) 编辑(创建)阶段 和 2) 执行阶段。举个例子:
Call Stack(调用栈)
JavaScript 引擎正是利用栈的这种结构来管理执行上下文的。在执行上下文创建好后,JavaScript 引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈。
浏览器中查看调用栈的方法:
- 当你执行一段复杂的代码时,你可能很难从代码文件中分析其调用关系,这时候你可以在你想要查看的函数中加入断点,然后当执行到该函数时,就可以查看该函数的调用栈了。
- console.trace()
调用栈是有大小的,当入栈的执行上下文超过一定数目,JavaScript 引擎就会报错,我们把这种错误叫做栈溢出。正常业务需求一般不会发生栈溢出的错误,只有递归忘记写边界的时候会出现栈溢出,我们写代码的时候要注意一下。
Event Loop(事件循环)
JavaScript代码的执行过程中,除了依靠函数调用栈来搞定函数的执行顺序外,还依靠任务队列(task queue)来搞定另外一些代码的执行。整个执行过程,我们成为事件循环过程。一个线程中,事件循环是唯一的,但是任务队列可以拥有多个。任务队列又分为macro-task(宏任务)与micro-task(微任务),在最新标准中,它们被分别称为task与jobs。
macro-task大概包括:
- script(整体代码)
- setTimeout
- setInterval
- setImmediate
- I/O
- UI rendering
micro-task大概包括:
- process.nextTick
- Promise
- Async/Await(实际就是promise)
- MutationObserver(html5新特性)
整体执行,我画了一个流程图:
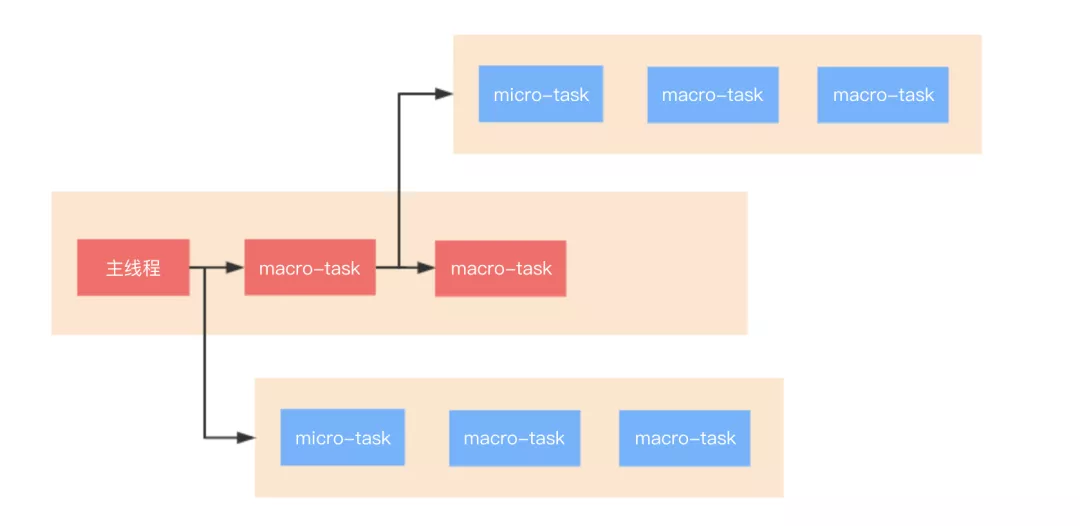
总的结论就是,执行宏任务,然后执行该宏任务产生的微任务,若微任务在执行过程中产生了新的微任务,则继续执行微任务,微任务执行完毕后,再回到宏任务中进行下一轮循环。举个例子:

结合流程图理解,答案输出为:async2 end => Promise => async1 end => promise1 => promise2 => setTimeout
垃圾回收与内存泄露
通常情况下,垃圾数据回收分为手动回收和自动回收两种策略。
- 手动回收策略,何时分配内存、何时销毁内存都是由代码控制的。
- 自动回收策略,产生的垃圾数据是由垃圾回收器来释放的,并不需要手动通过代码来释放。
V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。
新生代算法
新生代中用Scavenge 算法来处理,把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域。新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。

在新生代空间中,内存空间分为两部分,分别为 From 空间和 To 空间。在这两个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满时,新生代 GC 就会启动了。算法会检查 From 空间中存活的对象并复制到 To 空间中,如果有失活的对象就会销毁。当复制完成后将 From 空间和 To 空间互换,这样 GC 就结束了。
为了执行效率,一般新生区的空间会被设置得比较小,也正是因为新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象,会被移动到老生区中。
老生代算法
老生代中用 标记 - 清除(Mark-Sweep)和 标记 - 整理(Mark-Compact)的算法来处理。标记阶段就是从一组根元素开始,递归遍历这组根元素(遍历调用栈),能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据.然后在遍历过程中标记,标记完成后就进行清除过程。
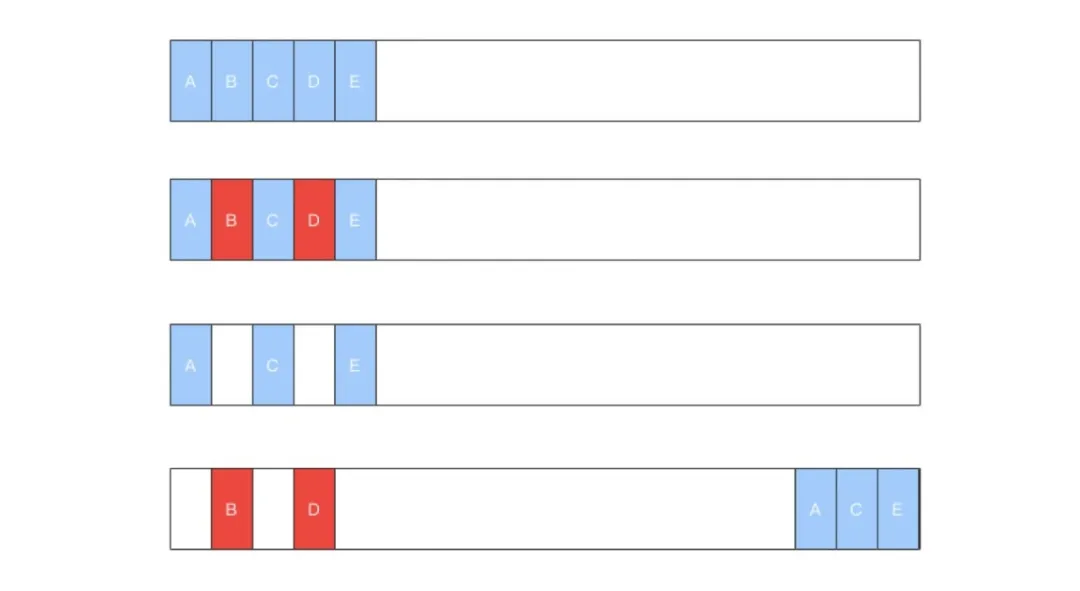
算法比较
在上述三种算法执行时,都需要将暂停应用逻辑(JS 执行),GC 完成后再执行应用逻辑。此时会有一个停顿时间(称为全停顿,stop-the-world) 故 V8 采用了增量标记(Incremental Marking)算法,将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成。
内存泄露
不再用到的内存,没有及时释放,就叫做内存泄漏(memory leak)。泄露的原因主要有缓存、闭包、全局变量、计时器中引用没有清除等原因。
这里我写了一篇更详细具体的文章,《Chrome 浏览器垃圾回收机制与内存泄漏分析》。
大家可以看一下,这里就不详细说了~
利用浏览器进行性能分析
这部分的内容,比较重要。我用了2篇文章来详细说了。
大家可以看一下,这里就不详细说了~
参考资料
- 极客时间《浏览器工作原理与实践》
- Chrome开发者文档,https://developers.google.com/web/tools/chrome-devtools/evaluate-performance/reference
- JavaScript运行机制深入浅出学习,https://zhuanlan.zhihu.com/p/33125763
- Winty blog,https://github.com/LuckyWinty/blog

 浙公网安备 33010602011771号
浙公网安备 33010602011771号