
统计学一:描述统计
待处理数据的缺失和错误会极大地影响后续的数据分析,因:我们首先需要评估数据质量,进行诸如缺失值发现、极端值诊断、统计分布(样本数据的分布情况)观察和描述性统计(包括均值、方差、标准差、偏度、峰度等)等操作。
在本课节中,老师从北京市空气质量监测数据集入手,系统介绍以上知识点,帮助学员获得洞察数据的能力,包括:
-
数据质量评估
-
极端值诊断
-
统计分布
-
基本描述统计
截面数据(cross-section data)是指在同一时间(时期或时点)截面上反映一个总体的一批(或全部)个体的同一特征变量的观测值,是样本数据中的常见类型之一。例如,工业普查数据、人口普查数据、家庭收入调查数据。在数学,计量经济学中应用广泛。


监测站点:35个;
忽略时间上的差异:将供暖季120天的数据全部作为截面数据;

第一步:样本数据的描述统计;
剔除缺失数据:

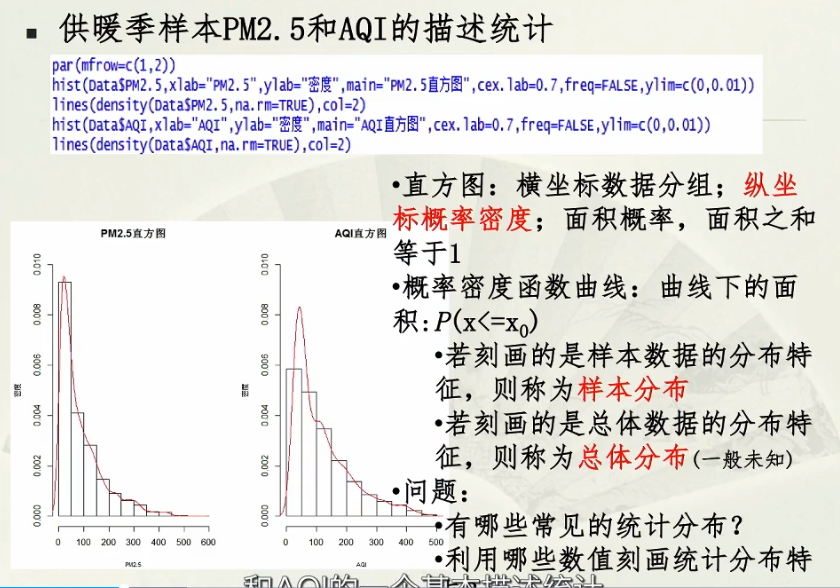
横坐标:分组;纵坐标:频率;
曲线:概率密度曲线;
大部分都为样本分布;
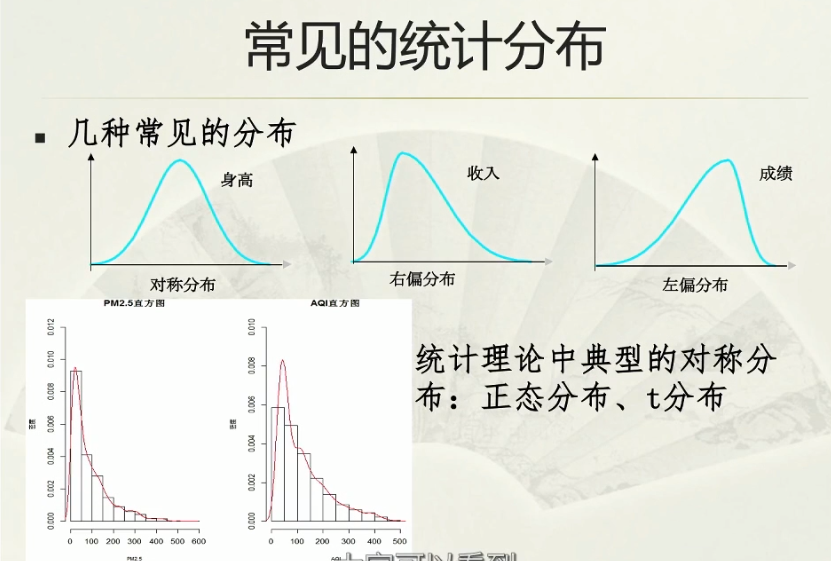
对称分布/左偏分布/右偏分布:较低的线在哪边就是哪偏分布;

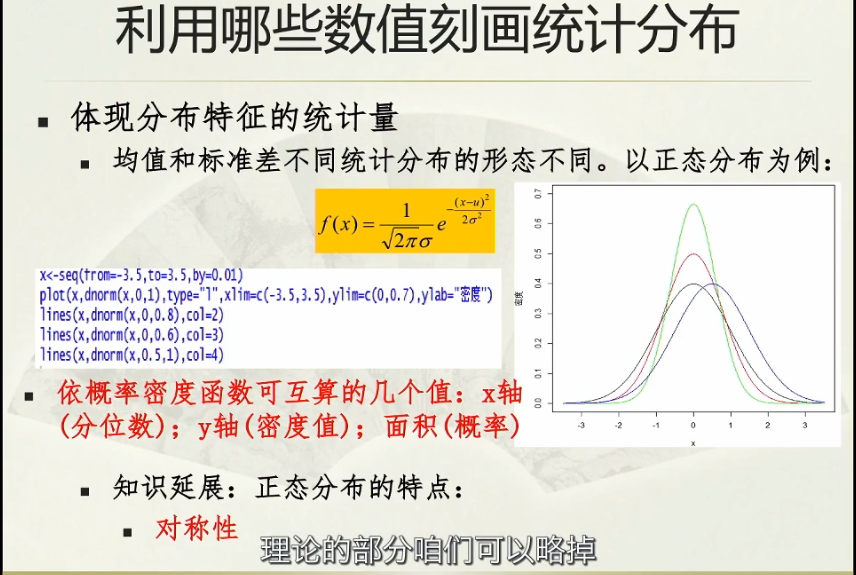
统计量刻画分布特征;
离差平方和:越大,离散程度越大;
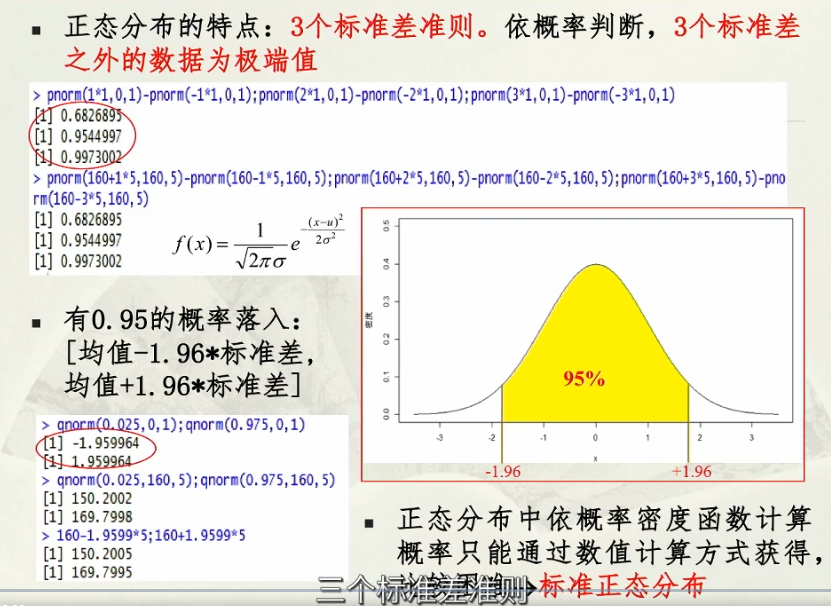
极端值;
陡峭程度不同,也就是标准差不同时,面积不同:通过标准正态分布来计算——标准化处理;

标准正态分布:均值为0,标准差为1;
转为标准正态分布的目的:算面积;
任何一个正态分布,都可以转为标准正态分布;
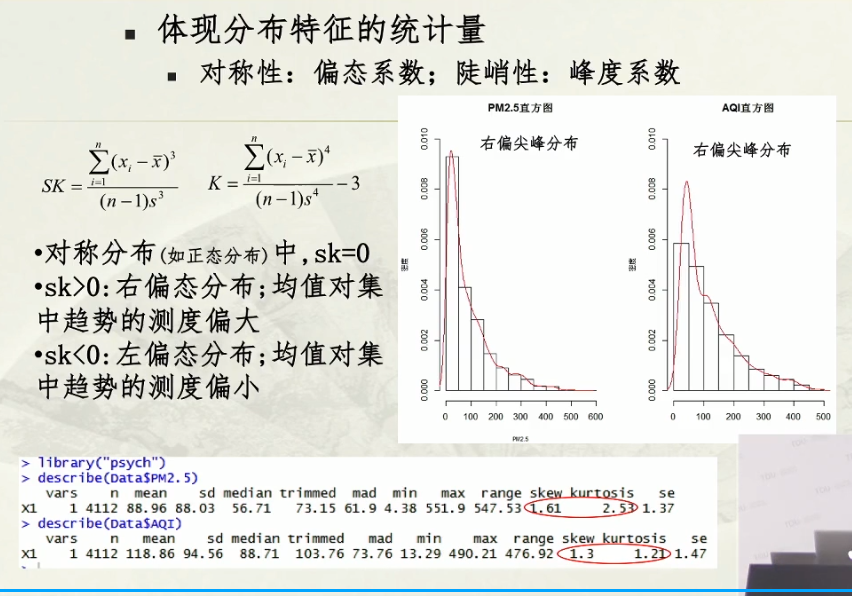
SK:偏态系数;

大部分PM2.5值都在0-100之间;
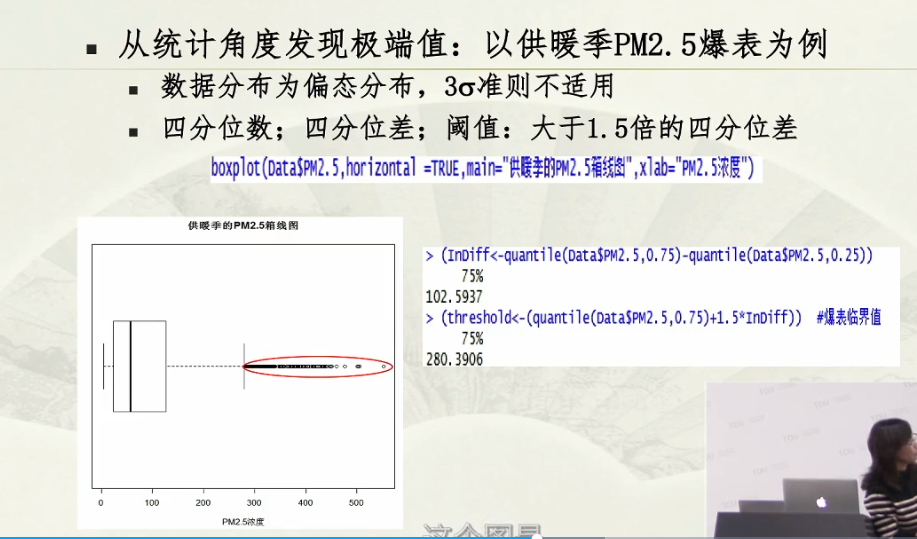
红框框住的左边为下四分位数;
红框框住的为极端值;

对于非对称性分布:用1.5的四分位差的标准来算;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号