模块化程序和面向对象
- 模块化程序
- 为什么要模块化
- 函数(function)的定义和传参
- 模块(module)的构建和导入
- 包(package)的概念
- 标准的包结构
- 面向对象编程(Object Oriented Programming)
- 面向对象的概念和特点
- Python里的面向对象
- 工业里,OOP的必要性
- 总结
1. 模块化程序
1.1 为什么要模块化
模块化的定义
模块化程序设计是指:在进行程序设计时,将一个大程序 按照功能 划分为若干小程序模块,每个小程序模块完成一个确定的功能,并在这些模块之间建立必要的联系,通过模块的互相协作完成整个功能 的程序设计方法。
简单来说:
模块化就是:将大程序按照功能拆解成若干个独立的小模块,然后通过协调这些小模块,完成整个功能。
模块化的优点
- 将复杂的程序简化了;
- 提高了代码的重用性;
- 易于维护和功能扩展;
- 有利于团队开发;
我们接下来所讲的 函数、模块、包和类,都是不同级别的模块化。
1.2 函数(function)的定义和传参
函数的定义
函数是组织好的、实现特定功能的代码段,函数是最小级别的模块化
定义函数
def 函数名(参数列表):
函数体
return 返回值
def func(a, b):
print('a={}, b={}'.format(a, b))
c = a + b
return c
函数传参
函数传参包括:顺序传参、关键字传参、列表传参和字典传参。
- 顺序传参,按照参数位置传参
func(1, 2)
- 关键字传参,明确声明传给函数哪个参数
func(a=1, b=2) func(b=2, a=1) # 关键字传参是无序的
- 列表传参,使用一个序列(比如list或tuple),按顺序解析参数
args = (1, 2) func(*args)
- 字典传参,使用一个字典,按字典的key解析参数
kwargs = {'a': 1, 'b': 2}
func(**kwargs)
参数定义
常见的函数参数可以被定义为:位置参数、关键字参数、不定长参数
我们定义如下func2函数:
def func2(a, b, c=0, d=0, *args, **kwargs):
print('a={}, b={}, c={}, d={}, args={}, kwargs={}'.format(a, b, c, d, args, kwargs))
以上函数定义,
a、b两个参数均为位置参数,传参时必填;c、d两个参数均为关键字参数,它允许我们指定其默认值,传参时选填;args和kwargs两个均为不定长参数,它允许我们传递变长的参数给此函数;其中,args用来解析多余的顺序传参,参数被解析为tuple;kwargs用来解析多余的关键字传参,参数被解析为dict;
我们下面使用func2函数
func2(1, 2) # 只传位置参数 func2(1, 2, 3, 4) # 传位置参数和关键字参数 func2(1, 2, 3, 4, 5, 6, 7, e=8, f=9, g=10) # 额外多传一些参数
匿名函数
匿名函数不通过def关键字定义,而是通过lambda表达式定义。它总是一行,主要用来封装简单的代码。
add = lambda x, y : x + y # x,y为参数,x+y为返回值 add(1, 2) add(3, 4)
实践经验
- 你应该总是使用函数来模块化你的程序,提高代码的可读性和复用性;
- 函数定义时,使用不定长参数可以增加函数的扩展性,所谓扩展性好,是指比如在调用时需要新增传参时,函数签名(函数名+参数列表)无需发生任何改动;
- 比如我们定义好的
func2函数,假设调用时想传一个新参数model,可以直接
- 比如我们定义好的
func2(1, 2, model='LSTM')
函数签名未改变,新的参数model顺利被传到kwargs里面了。
想象一下,你写了一个函数给别人用,现在需求一直在变,不断有新的参数你需要别人传过来,假设你的函数没有扩展性,你只能不停地修改函数签名,以匹配人家的参数调用,一旦你俩没有同步修改,代码就会挂掉。- 匿名函数常被用作max、min、sort等函数的key参数,表示对元素做一个转换,比如:
l = ['22', '1', '4444', '333']
max(l, key=lambda x: len(x)) # 取列表中最长的元素
我们使用lambda表达式,将元素转换为其长度,然后取其最大值的原始元素1.3 模块(module)的构建和导入
模块
在python里面,一个py文件就是一个模块,在模块里面,你可以定义一些类或者函数、并执行它。
模块的导入
- 模块只有被导入后,才能使用;
- 你可以导入的三种模块包括:python内置模块(比如
sys)、第三方模块(比如sklearn)、你自己写的模块 - 模块的导入使用
import语句,你可以:- 直接import模块,例如
import sys - 也可以使用
from ... import ...语句,从模块里面import变量、类或函数,例如from sys import exit - 你可以使用
from ... import *语句,将模块里的所有内容import进来,但是不推荐这么做,你应该明确引入你需要的内容
- 直接import模块,例如
模块的执行
模块的执行直接输入命令:python <module>.py 或 python -m <module>
你应该将模块内主函数的执行放到if __name__ == '__main__'条件内,__name__内置变量只有在你运行当前module时,才为__main__
例如:
module.py
def func():
pass
if __name__ == '__main__':
func()如果func()没有被放在上述if语句中,那么当你在其它地方import module时,func函数也会执行,但你只是想运行此模块时才调用func函数
模块的查找
想要成功import某个模块,必须确保其在搜索路径中被找到。
- 所谓搜索路径,就是一系列存放python模块的目录,比如:系统的
site-packages目录,会被默认添加到搜索路径里面(通过pip安装的所有包都会被放到site-package下面);
- 搜索路径被保存在
sys.path中,我们可以将其打印出来; -
import sys sys.path
- 解释器查找模块时,会按照搜索路径内目录顺序,依次从里面查找同名模块,找到了就import成功,否则就会报错;
- 搜索路径里,当前脚本目录
''和site-packages目录已经被默认添加,这里注意:当前目录的优先级更高;
- 你可以往
sys.path后面追加目录,这样新目录里面的模块就可以被成功import了,但是不推荐这么做,标准的做法是将这个模块做成一个包,安装到site-package下面;
实践经验
-
新手经常会创建一个与库名重名的脚本,比如
tensorflow.py,准备在里面写一些测试代码,然后准备import官方的tensorflow,结果发现库里啥也没有,实际上,你import到的是你当前的这个tensorflow脚本!原因就是搜索路径的优先级,当前目录高于
site-package;
1.4 包(package)的概念
-
一个包含
__init__.py文件(经常为空)的目录就被视为一个包下面是一个包结构示例:

上面包有两个级别,都有自己的
__init__.py文件
-
一个包含
__init__.py文件(经常为空)的目录就被视为一个包
- 如果我们要导入
module1,应该使用from package.sub_pkg1 import module1
- 模块的导入分为绝对导入和相对导入,
- 明确声明完整
包+模块名的导入即为绝对导入,如上述 - 使用了
.表示当前包的导入即为相对导入,比如from . import module1就属于相对导入, - 为了代码可读性更高,建议无特殊情况都使用绝对导入,故相对导入这里不展开
- 明确声明完整
1.5 标准包结构
函数、类、模块、包的关系
包 -> 模块 -> 函数/类,其中->表示由……构成
标准包结构
1.4节图示即是一个标准的包结构;
- 企业级大项目一定是一个标准的包,你应该总是尝试用标准的包结构组织你的代码;
-
中文分词工具
jieba的包结构: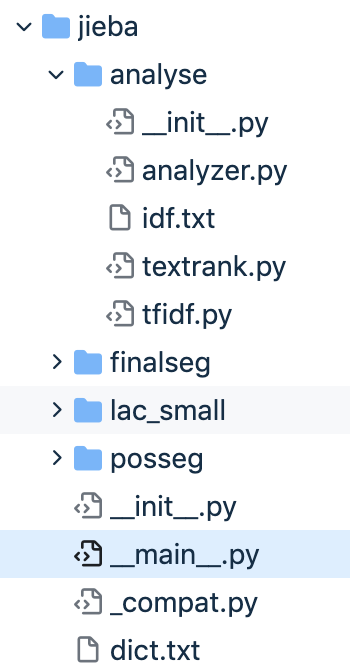

标准包结构的执行
标准包结构的执行推荐使用python -m <pkg>.<module>命令,而不是python <pkg>/<module>.py命令
两者的主要区别在于:
-
前者将
执行目录加入到sys.path, -
而后者是将
执行目录/<pkg>加入到sys.path,想在其它地方成功地
import <pkg>.<module>,显然你需要的是前者
2. 面向对象编程
2.1 面向对象的概念和特点
面向对象的概念(Object Oriented Programming,简称OOP)
面向对象方法,把相关的数据和操作组织为一个整体,从更高的层次来进行系统建模,这很贴近客观事物的运行规律。
- 在现实生活中,对象是指具体的某一个事物,它看得见摸得着;
- 在OOP中,对象被抽象为数据和动作的结合体,数据用属性(变量)表示,动作用方法表示;
一个例子
class People:
max_age = 150
def __init__(self, name, age, weight):
self.name = name
self.age = age
self.weight = weight
def speak(self):
msg = "%s 说: 我 %d 岁。" % (self.name, self.age)
print(msg)
class Student(People):
def __init__(self, name, age, weight, grade):
super().__init__(name, age, weight)
self.grade = grade
def speak(self):
msg = "%s 说: 我 %d 岁了,我在读 %d 年级" % (self.name, self.age, self.grade)
print(msg)
if __name__ == '__main__':
laowang = Student('laowang', 20, 49, 6)
一些概念
- 类(Class): 用来定义每个对象所共有的属性和方法,是对事物的抽象。
- 实例化:创建类实例的过程,通过构造方法完成实例化。
- 对象:类实例化后就是一个对象,它是一个具体的东西。
- 实例变量:属于某个具体对象的变量称为实例变量,用 self 修饰。
- 类变量:属于类级别的变量成为类变量。类变量在方法外定义。
- 局部变量:定义在方法中的变量,只作用于当前方法。
- 方法:类中定义的函数,分为实例方法、类方法和静态方法。
- 继承:即子类继承父类属性和方法,并准备增加一些新特性或修改一些特性。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
2.2 Python里的面向对象
类的定义、实例化、对象引用
这里定义一个People类,
class People:
max_age = 150 # 类变量
def __init__(self, name, age, weight): # 带三个参数的构造函数,实例化时会调用此方法
self.name = name # 定义实例变量name
self.age = age # 定义实例变量age
self.__weight = weight # 定义实例变量__weight,通过__,我们定义为私有的,仅内部可以访问
self._weight = weight # 定义实例变量_weight,通过_,我们定义为半私有,意为:建议内部访问,但外部访问也可以
def speak(self):
msg = "%s 说: 我 %d 岁,体重 %.2f KG" % (self.name, self.age, self.__weight)
print(msg)
laowang = People('laowang', 20, 49) # 实例化,调用构造函数,返回对象
laowang.name, laowang.age # 引用实例变量
laowang.__weight # 外部引用私有变量,报错
laowang._weight # 外部引用半私有变量,不推荐,但不会报错
laowang.speak() # 引用对象方法
laowang.max_age, People.max_age # 类变量可以使用对象引用,也可以使用类来引用,推荐使用类来引用
实例方法、类方法和静态方法
我们再看一个类Foo,
class Foo:
class_var = '类变量'
def __init__(self):
self.instance_var = '实例变量'
def instance_method(self): # 定义实例方法,第一个参数必须为self,表示当前对象
print("实例方法,只能被实例对象调用")
print(self.instance_var) # 通过self, 在实例方法里引用实例变量
@classmethod
def class_method(cls): # 通过classmethod装饰器,定义类方法,第一个参数必须为cls,表示当前类
print("类方法")
print(cls.class_var) # 通过cls, 类方法里引用类变量
@staticmethod
def static_method(): # 通过staticmethod装饰器,定义静态方法
print("静态方法")
我们来实例化这个类,并调用对应的方法
foo = Foo() foo.instance_method() # 调用实例方法,通过对象来引用 实例方法,只能被实例对象调用 实例变量 Foo.class_method() # 调用类方法,通过类来引用;类方法也可以用对象foo引用,但推荐使用类Foo来引用 类方法 类变量 Foo.static_method() # 调用静态方法,通过类来引用; 静态方法
如何确定使用哪种变量、哪种方法?
上面我们介绍了两种变量:类变量和实例变量,介绍了三种方法:类方法、实例方法、静态方法,那么,开发中如何决定使用哪种呢?
-
当此变量或方法和抽象的类相关,和具体对象无关时,请定义其为类变量或类方法。
比如上面例子,人类的最长寿命
max_age与People人相关,与具体的对象老王、张三等无关,因此应该被定义为类变量; 类方法同理,比如一个打印最长寿命max_age的方法
-
当此变量或方法和具体对象强相关时,请定义为实例变量或实例方法。
比如上面例子,人的名字、年龄、体重因人而异,由具体对象老王、张三决定,因此应该被定义为实例变量; 实例方法同理,比如上面
speak方法
- 通俗点说,所有对象一模一样的变量或者方法,将其定义为类的;因对象不同而不同的变量或方法,将其定义为实例的;
- 静态方法无法获取类变量、类方法、实例变量、实例方法(无
self或cls参数),所以它只适合做一些逻辑独立(相对于类)的小功能,比如:加工一个字符串;
继承与多继承
我们使用最开始的例子
class People(object): # 不声明父类,默认继承object类,object类是所有类的始祖
max_age = 150
def __init__(self, name, age, weight):
self.name = name
self.age = age
self.weight = weight
def speak(self):
msg = "%s 说: 我 %d 岁。" % (self.name, self.age)
print(msg)
class Student(People): # Student类继承了People类,即得到父类People的所有属性(变量)和方法
def __init__(self, name, age, weight, grade):
super().__init__(name, age, weight) # 调用父类的构造函数,初始化name age weight变量
self.grade = grade # 子类新增了grade变量
def speak(self): # 子类重写了父类的speak方法,实现自己的逻辑
msg = "%s 说: 我 %d 岁了,我在读 %d 年级" % (self.name, self.age, self.grade)
print(msg)
student = Student('laowang', 18, 50, 9) # 使用子类实例化对象
student.speak()
laowang 说: 我 18 岁了,我在读 9 年级
python支持多继承,即一个类允许有多个父类,你可以通过class Son(Parent1, Parent2)语法来定义
- 多继承下,当多个父类有同名方法或变量时,子类继承到的是左边父类的相应内容;
-
不推荐使用多继承,这会增加代码的复杂性。
假设
Parent1和Parent2同时有两个同名方法method1和method2,子类使用了多继承,它如何实现同时继承到Parent1的method1和Parent2的method2?看起来有点棘手,你应该规避这种问题。
经验
- 变量或者方法应该被定义为哪种(实例的、或者类的、或者静态的),应该谨慎思考,做出合理选择;
- 所有类外部需要使用的变量或者方法,需要定义其为共有的(即名字不以
_开头);否则,定义为私有的;
-
实践中,推荐将私有方法或者变量定义为半私有的,即名字以单
_开头,而不是__开头,这样便于在单元测试内测试他们;单元测试是对函数或类方法进行的测试,即:实例化类,然后调其方法,跑一些样例数据,确保方法不出错。
工业上,你需要对你的类进行单元测试,确保代码质量。
2.3 工业里,OOP的必要性
工业里,复杂的需求导致一个项目代码量庞大(bt点的 代码量能达到百万千万行),比如一个大型APP(支付宝、微信等)、几十个开发者共同维护,如果没有 大家易于理解的类封装、清晰的类调用关系的设计、基于OOP的设计模式,那么 这么多人一起维护好它 就是一件很难的事情。
OOP代码的在 可读性、可重用性、团队协作便利性 、扩展性、易维护性 等方面都很好,建议大家一开始就养成好的OOP习惯,写出高质量的代码。
这些年,github上存在一些开源的算法项目,注重算法实现,在代码质量上面没有过多关注,再加上python语言本身也比较自由,所以代码质量比较差,这给初学者带来了一些不好的示范。
3. 总结
本文章主要讲了两个知识点:模块化程序和面向对象编程。
除了在探究python语言里面,这些东西的具体使用外,我们还传达了一个重要的观点:利用标准包结构和面向对象编程,组织我们的代码,写出高质量的Python项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号