


13-垃圾邮件分类2
1.读取
# 读取 path = r'C:\Users\mgx13\venv\data\SMSSpamCollection' sms = open(path, 'r', encoding='utf-8') # 数据读取 sms_data = [] sms_label = [] csv_reader = csv.reader(sms, delimiter='\t') for line in csv_reader: # 预处理 sms_label.append(line[0]) sms_data.append(preprocessing(line[1])) sms.close()
2.数据预处理
# 预处理 # 根据词性,生成还原参数pos def get_wordnet_pos(treebank_tag): if treebank_tag.startswith('J'): return nltk.corpus.wordnet.ADJ elif treebank_tag.startswith('V'): return nltk.corpus.wordnet.VERB elif treebank_tag.startswith('N'): return nltk.corpus.wordnet.NOUN elif treebank_tag.startswith('R'): return nltk.corpus.wordnet.ADV else: return nltk.corpus.wordnet.NOUN def preprocessing(text): tokens=[word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)] stops=stopwords.words('english') tokens=[token for token in tokens if token not in stops] tokens = [token.lower() for token in tokens if len(token)>=3] # 大小写、长度<3 lmtzr = WordNetLemmatizer() tag = nltk.pos_tag(tokens) # 词性 # 词性还原 tokens = [lmtzr.lemmatize(token, pos=get_wordnet_pos(tag[i][1])) for i,token in enumerate(tokens)] preprocessing_text=' '.join(tokens) return preprocessing_text
3.数据划分—训练集和测试集数据划分
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)
# 划分 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(sms_data, sms_label, test_size=0.2, random_state=0, stratify=sms_label) len(sms_label) len(x_train) len(y_test)
4.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
观察邮件与向量的关系
向量还原为邮件
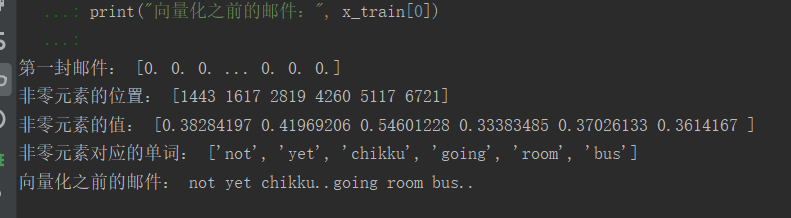
# 转化为向量 from sklearn.feature_extraction.text import TfidfVectorizer tfidf2 = TfidfVectorizer() X_train = tfidf2.fit_transform(x_train) X_test = tfidf2.transform(x_test) X_train.toarray() # 转换成数组 # 向量还原成邮件 import numpy as np print("第一封邮件:", X_train.toarray()[0]) a = np.flatnonzero(X_train.toarray()[0]) # 该函数输入一个矩阵,返回扁平化后矩阵中非零元素的位置(index) print("非零元素的位置:", a) print("非零元素的值:", X_train.toarray()[0][a]) b = tfidf2.vocabulary_ # 生成词汇表 key_list =[] for key, value in b.items(): if value in a: key_list.append(key) # key非0元素对应的单词 print("非零元素对应的单词:", key_list) print("向量化之前的邮件:", x_train[0])
结果:
4.模型选择
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
# 模型选择 from sklearn.naive_bayes import MultinomialNB mnb = MultinomialNB() mnb.fit(X_train, y_train) y_mnb = mnb.predict(X_test) print("预测的准确率:", sum(y_mnb == y_test)/len(y_test))
结果:

原因:选择多项式模型,是因为每个单词出现的频率都是随机的,而且它n次重复实验随机事件出现的次数概率符合多项式的分布概率。
5.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
说明混淆矩阵的含义
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
# 混淆矩阵、分类报告 from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report cm = confusion_matrix(y_test, y_mnb) cr = classification_report(y_test, y_mnb) print("混淆矩阵:\n", cm) print("分类报告:", cr) print("模型准确率:", (cm[0][0]+cm[1][1])/np.sum(cm))
结果:

混淆矩阵:
TP(True Positive):将正类预测为正类数,真实为0,预测也为0
FN(False Negative):将正类预测为负类数,真实为0,预测为1
FP(False Positive):将负类预测为正类数, 真实为1,预测为0
TN(True Negative):将负类预测为负类数,真实为1,预测也为1
准确率:对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。(TP + TN) / 总样本
精确率:针对预测结果,在被所有预测为正的样本中实际为正样本的概率。TP / (TP + FP)
召回率:在实际为正的样本中被预测为正样本的概率。TP / (TP + FN)
F值:同时考虑精确率和召回率,让两者同时达到最高,取得平衡。F值=正确率 * 召回率 * 2 / (正确率 + 召回率 )
6.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
答:对于每一个训练文本,CountVectorizer 只考虑每种词汇在该训练文本中出现的频率,而TfidfVectorizer 除了考量某一词汇在当前训练文本中出现的频率之外,同时关注包含这个词汇的其它训练文本数目的倒数。相比之下,训练文本的数量越多,TfidfVectorizer 这种特征量化方式就更有优势。

