

12 递归下降语法分析
一、实验目的:
利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验原理
每个非终结符都对应一个子程序。
该子程序根据下一个输入符号(SELECT集)来确定按照哪一个产生式进行处理,再根据该产生式的右端:
- 每遇到一个终结符,则判断当前读入的单词是否与该终结符相匹配,若匹配,再读取下一个单词继续分析;不匹配,则进行出错处理
- 每遇到一个非终结符,则调用相应的子程序
三、实验要求说明
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”,并指出语法错误的类型及位置。
例如:
输入begin a:=9;x:=2*3;b:=a+x end #
输出success
输入x:=a+b*c end #
输出‘end' error
四、实验步骤
1.待分析的语言的语法(参考P90)
2.将其改为文法表示,至少包含
–语句
–条件
–表达式
3. 消除其左递归
4. 提取公共左因子
5. SELECT集计算
6. LL(1)文法判断
7. 递归下降分析程序
#include <stdio.h> #include <string.h> #include <stdlib.h> char prog[80],token[8]; char ch; int syn,p,m,n,sum=0; //单词符号类型syn,整数sum,p当前要识别程序段第一个字符指针p char *word[6]={"begin","if","then","while","do","end"}; int flag=0; void E(); void T(); void E1(); void T1(); void F(); void error(); void scaner() { for(n=0;n<20;n++) token[n]=NULL; m=0; sum=0; ch=prog[p++]; while(ch==' ') { ch=prog[p++]; } if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){ while((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch>='0'&&ch<='9')) { token[m++]=ch; ch=prog[p++]; } syn=10; p--; for(n=0;n<6;n++) if(strcmp(token,word[n])==0){ syn=n+1; break; } } else if(ch>='0'&&ch<='9') { while(ch>='0'&&ch<='9') { sum=sum*10+(ch-'0'); ch=prog[p++]; } p--; syn=11; } else switch(ch){ case '<': m=0; token[m++]=ch; ch=prog[p]; if(ch=='>'){ syn=21; token[m++]=ch; }else if(ch=='='){ syn=22; token[m++]=ch; }else{ syn=20; p--; } p++; token[m]='\0'; break; case '>': m=0; token[m++]=ch; ch=prog[p++]; if(ch=='='){ syn=24; token[m++]=ch; }else{ syn=23; p--; } break; case ':': m=0; token[m++]=ch; ch=prog[p++]; if(ch=='='){ syn=18; token[m++]=ch; }else{ syn=17; p--; } break; case '+': syn=13; token[0]=ch; break; case '-': syn=14; token[0]=ch; break; case '*': syn=15; token[0]=ch; break; case '/': syn=16; token[0]=ch; break; case ';': syn=26; token[0]=ch; break; case '(': syn=27; token[0]=ch; break; case ')': syn=28; token[0]=ch; break; case '=': syn=25; token[0]=ch; break; case '#': syn=0; token[0]=ch; break; default: syn=-1; break; } } void E() { if(syn==1){ scaner(); T(); while(syn==26){ scaner(); T(); } printf("syn=%d",syn); if(syn==6){ scaner(); if(syn==0 && flag==0){ printf("Success!\n"); } } else{ error(); } }else{ error(); } return ; } void E1(){ if(syn==13||syn==14){ scaner(); T1(); } return ; } void T(){ if(syn==10){ scaner(); if(syn==18){ scaner(); E1(); } else{ error(); } }else{ if(flag!=1){ error(); } } } void T1(){ F(); while(syn==15||syn==16){ scaner(); F(); } return ; } void F(){ if(syn==10||syn==11){ scaner(); }else if(syn==27){ scaner(); E1(); if(syn==28) scaner(); else{ error(); } } else{ error(); } return ; } void error(){ printf("语法有误!错误为:%s\n",token); flag=1; } int main(){ p=0; int i; printf("请输入源程序:\n"); do{ scanf("%c", &ch); prog[p++]=ch; } while(ch!='#'); p=0; scaner(); E(); printf("分析结束!"); }
运行结果:
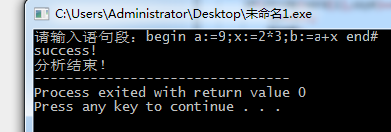
图1

图2

图3
