快速搭建ELK日志分析系统
什么是ELK?
通俗来讲,ELK是由Elasticsearch、Logstash、Kibana 三个开源软件的组成的一个组合体,ELK是elastic公司研发的一套完整的日志收集、分析和展示的企业级解决方案,在这三个软件当中,每个软件用于完成不同的功能,ELK 又称为ELK stack,官方域名为elastic.co,ELK stack的主要优点有如下几个:
处理方式灵活:elasticsearch是实时全文索引,具有强大的搜索功能
配置相对简单:elasticsearch的API全部使用JSON 接口,logstash使用模块配置,kibana的配置文件部分更简单。
检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
集群线性扩展:elasticsearch和logstash都可以灵活线性扩展
前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单
什么是Elasticsearch:
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供API接口,可以处理大规模日志数据,比如Nginx、Tomcat、系统日志等功能。
Elasticsearch使用Java语言开发,是建立在全文搜索引擎ApacheLucene基础之上的搜索引擎,https://lucene.apache.org/。
Elasticsearch的特点:
实时搜索、实时分析
分布式架构、实时文件存储
文档导向,所有对象都是文档
高可用,易扩展,支持集群,分片与复制
接口友好,支持json
什么是LogstashLogstash
是一个具有实时传输能力的数据收集引擎,其可以通过插件实现日志收集和转发,支持日志过滤,支持普通log、自定义json格式的日志解析,最终把经过处理的日志发送给elasticsearch。
什么是kibana:
Kibana为elasticsearch提供一个查看数据的web界面,其主要是通过elasticsearch的API接口进行数据查找,并进行前端数据可视化的展现,另外还可以针对特定格式的数据生成相应的表格、柱状图、饼图等。
为什么使用ELK?
ELK组件在海量日志系统的运维中,可用于解决以下主要问题:
-分布式日志数据统一收集,实现集中式查询和管理
-故障排查-安全信息和事件管理-报表功能
ELK的好处:ELK组件在大数据运维系统中,主要可解决的问题如下:
-日志查询,问题排查,故障恢复,故障自愈
-应用日志分析,错误报警
-性能分析,用户行为分析
一:elasticsearch集群部署:
1.1:环境初始化:
最小化安装Centos 7.x/Ubuntu x86_64操作系统的虚拟机,vcpu 2,内存4G或更多,操作系统盘50G,主机名设置规则为linux-fairies1.exmaple.com,其中host1和host2为elasticsearch服务器,为保证效果特额外添加一块单独的数据磁盘大小为100G并格式化挂载到/data的目录下,我的虚拟机配置信息如下
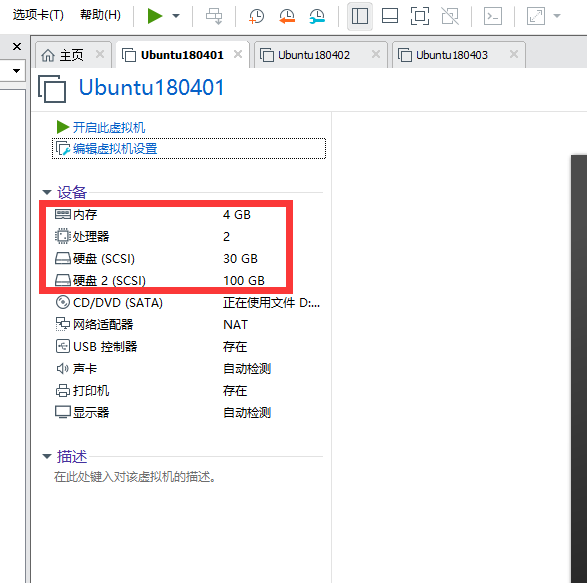
有三台服务器同时安装elasticsearch服务并搭建集群,三台服务器的IP分别为:192.168.37.16/192.168.37.17/192.168.37.18
1.1.1:主机名和磁盘挂载,
三台主机的主机名分别设置为
192.168.37.16 linux-fairies1
192.168.37.17 linux-fairies2
192.168.37.18 linux-fairies3
在三台主机上分别设置主机名并重启,见下图

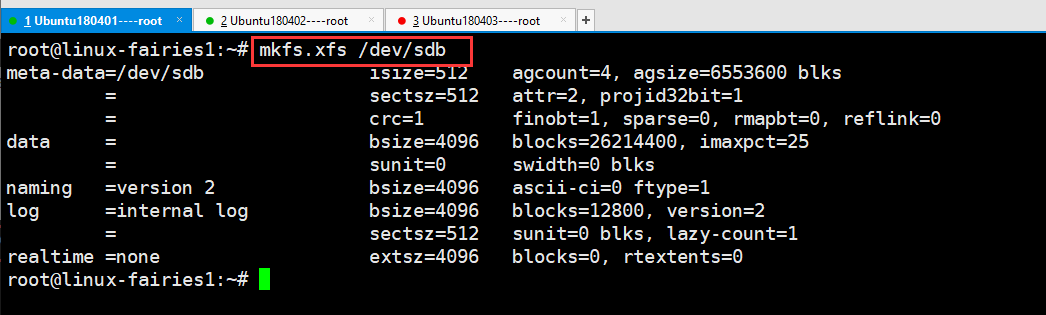
在三台机器上分别格式化硬盘,具体做法见下图
查看硬盘的ID信息,使用命令blkid ,具体见下图

其中上图/dev/sdb是我们自己手动添加的硬盘
打开文件,挂载,
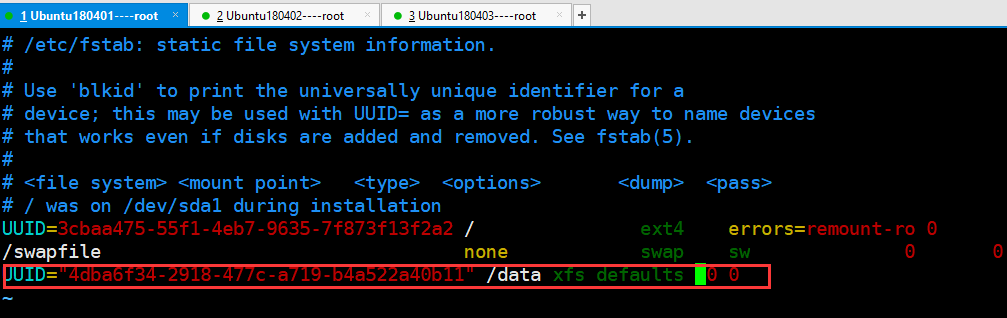
vim /etc/fstab
在文件中添加挂载内容,见下图,
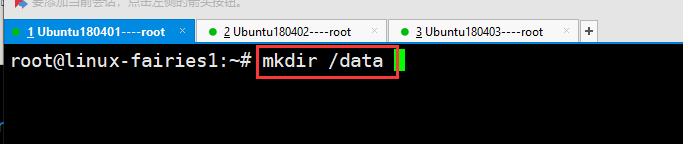
假如你挂载的文件不存在,就要先创建文件,如下图创建文件夹
执行命令,使挂载生效,见下图
root@linux-fairies1:~# mount -a
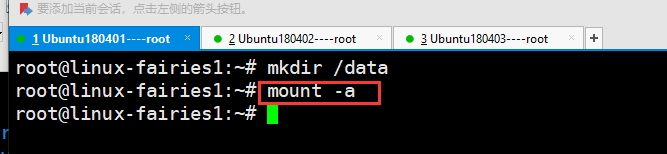
验证挂载信息,见下图
root@linux-fairies1:~# df -h Filesystem Size Used Avail Use% Mounted on udev 1.9G 0 1.9G 0% /dev tmpfs 392M 13M 380M 4% /run /dev/sda1 30G 3.3G 25G 12% / tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup tmpfs 392M 0 392M 0% /run/user/0 /dev/sdb 100G 135M 100G 1% /data
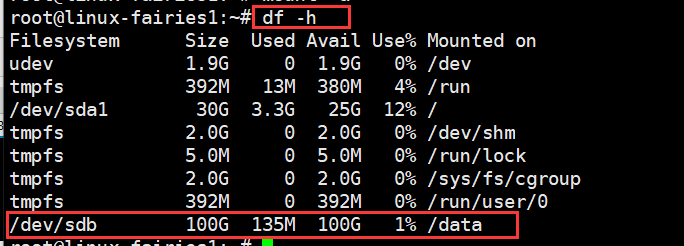
看到上图,说明挂载成功,同时在另外两台电脑上执行相同的命令完成挂载
1.2:安装elasticsearch,我这次系统使用的是Ubuntu1804,elasticsearch为带JDK的7.6.1版本
上传deb包,包名如下图
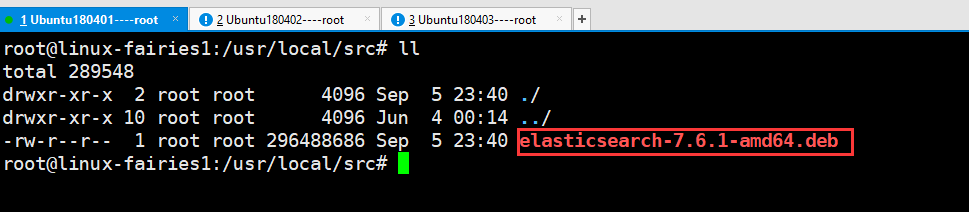
1.3:开始安装:具体见下图
root@linux-fairies1:/usr/local/src# dpkg -i elasticsearch-7.6.1-amd64.deb
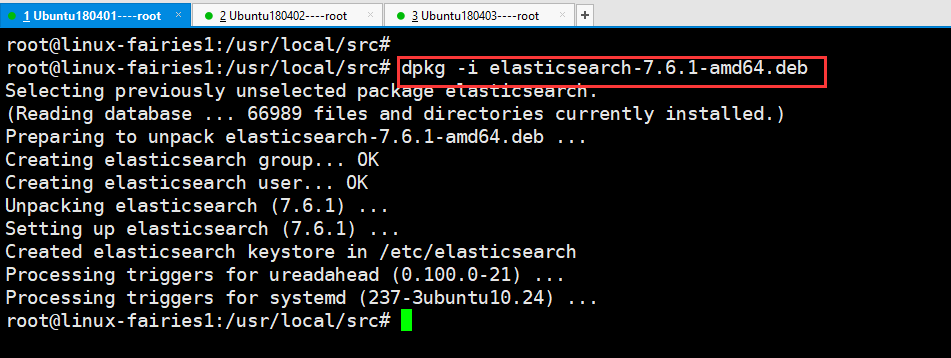
通过上图可知,软件安装完成
1.4:修改配置文件,具体修改的内容如下图
root@linux-fairies1:/usr/local/src# cat /etc/elasticsearch/elasticsearch.yml
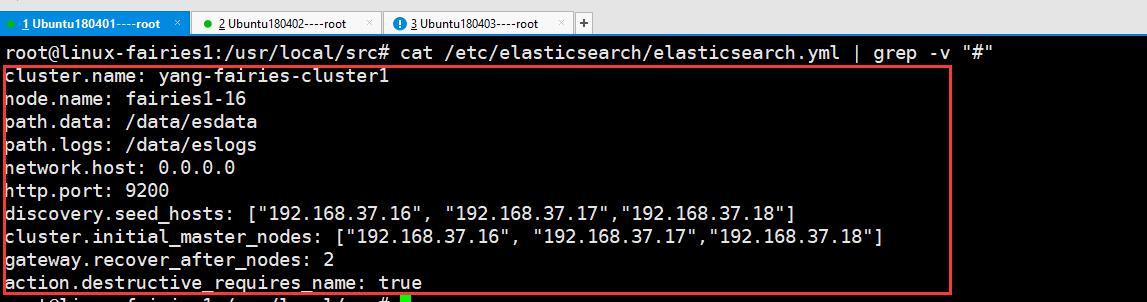
三台机器都需要需改配置文件的,其中节点(node.name)的名称必须唯一
配置文件解析如下:
cluster.name: ELK-Cluster #ELK的集群名称,名称相同即属于是同一个集群 node.name: elk-node1 #当前节点在集群内的节点名称 path.data: /elk/data#ES数据保存目录 path.logs: /elk/logs#ES日志保存目 bootstrap.memory_lock: true#服务启动的时候锁定足够的内存,防止数据写入swapnetwork.host: 0.0.0.0#监听IP http.port: 9200#监听端口 #集群中node节点发现列表 discovery.seed_hosts: ["192.168.37.16","192.168.37.17","192.168.37.18"] #集群初始化那些节点可以被选举为 mastercluster.initial_master_nodes: ["192.168.37.16","192.168.37.17","192.168.37.18"] #2.x 5.x 6.x 配置节点发现列表 discovery.zen.ping.unicast.hosts: ["192.168.15.11", "192.168.15.12"] #一个集群中的N个节点启动后,才允许进行数据恢复处理,默认是1 gateway.recover_after_nodes: 2 #设置是否可以通过正则或者_all删除或者关闭索引库,默认true表示必须需要显式指定索引库名称,生产环境建议设置为true,删除索引库的时候必须指定,否则可能会误删索引库中的索引库。 action.destructive_requires_name: true
1.5:启动程序,可以直接执行 systemctl restart elasticsearch 启动程序的,见下图
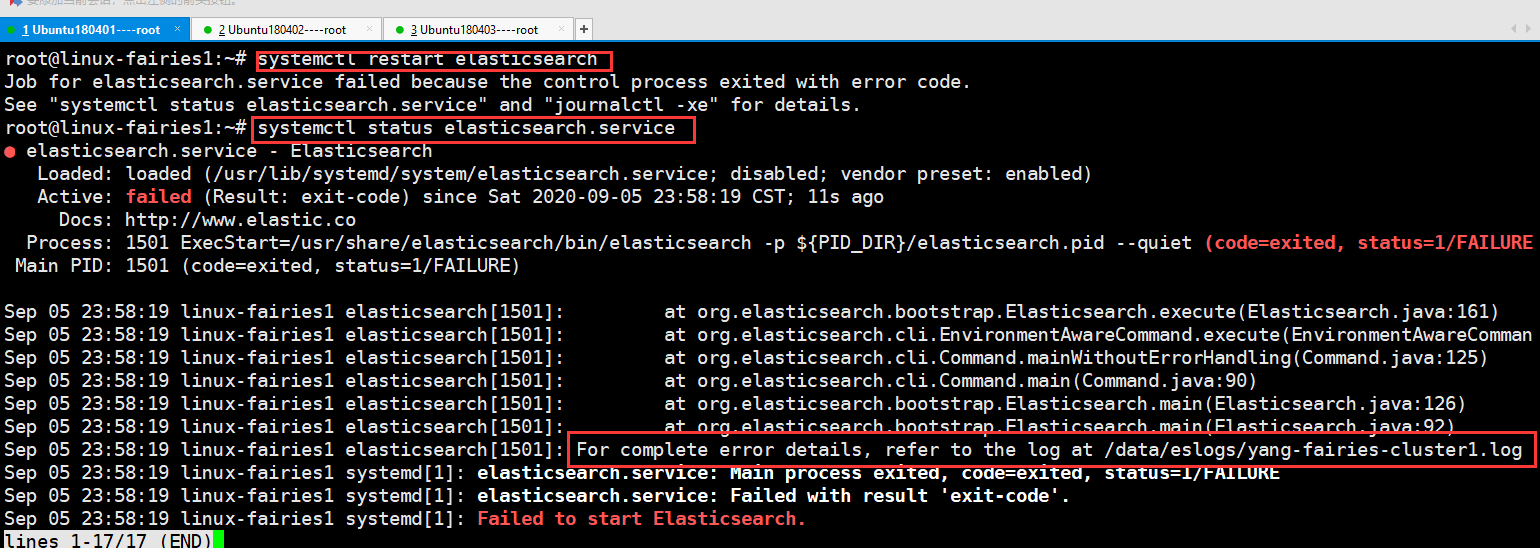
通过上图可知,程序启动失败
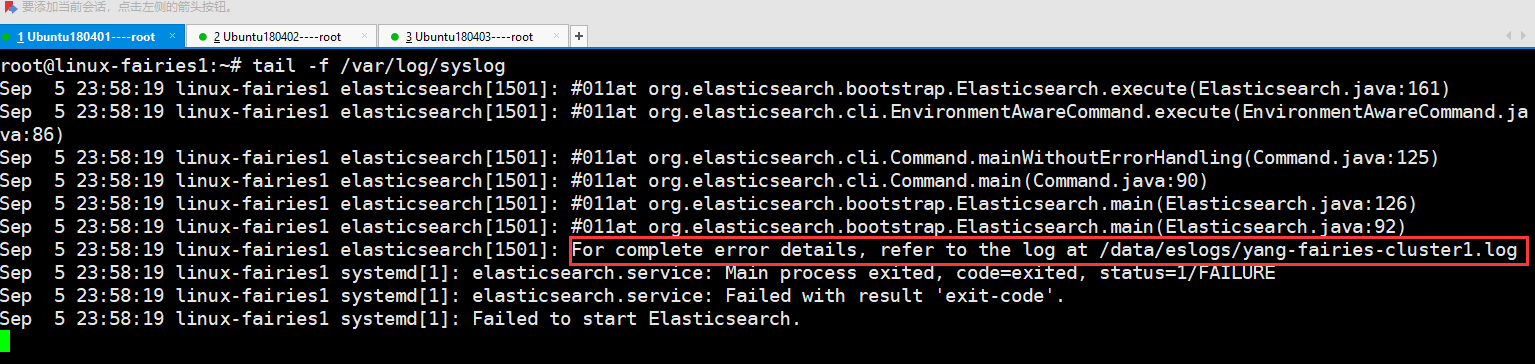
1.6:检查排查,检查排错主要是通过查看日志的,查看日志及相关信息见下图
下图为系统日志
下图为服务启动的脚本
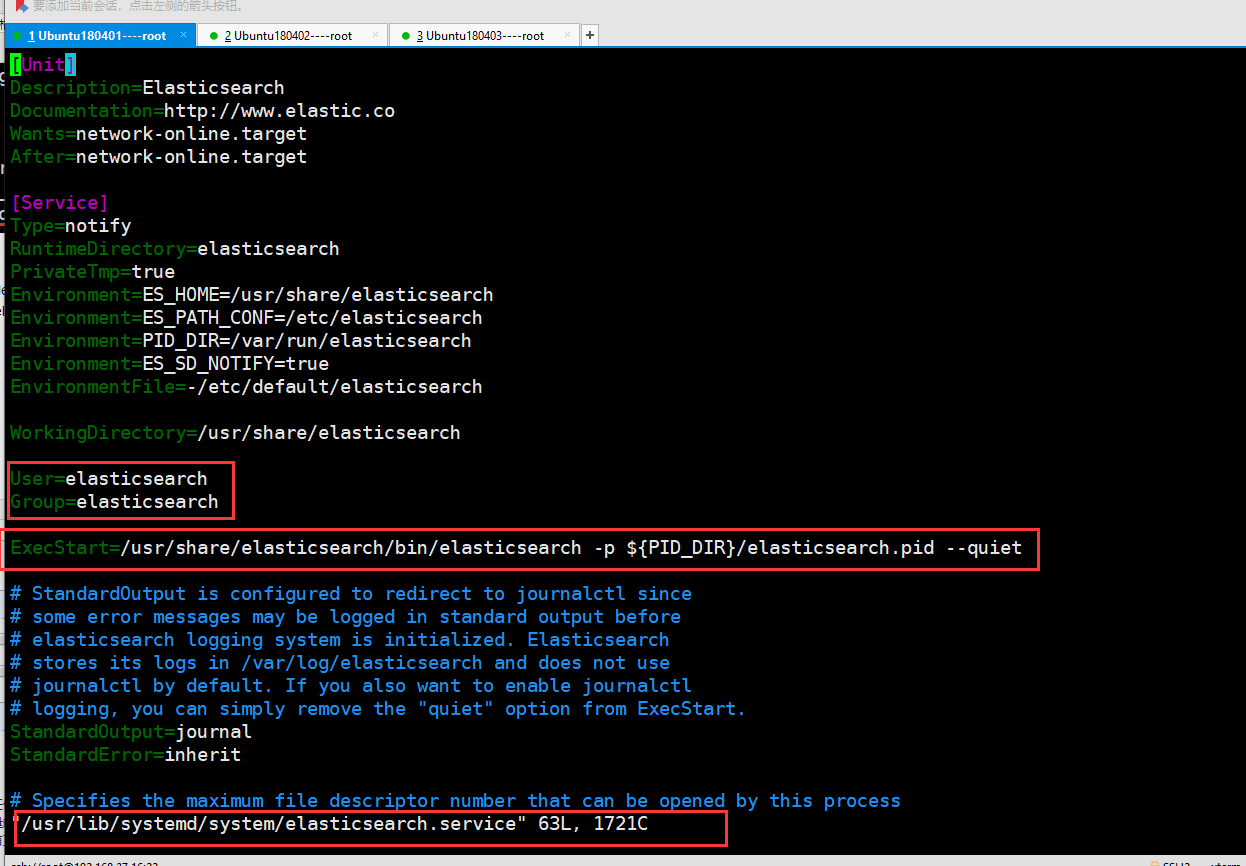
下图为,服务启动的账户信息
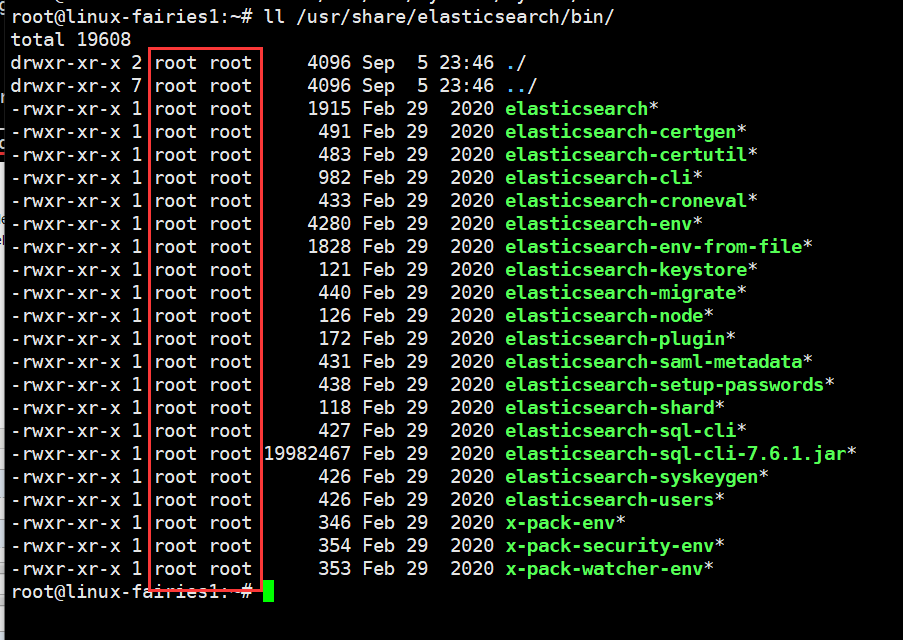
通过以上图片分析可知,主要是/data目录没有权限及服务使用root启动的,
修改权限见如下

1.7:重新启动服务并验证,具体明细见下图
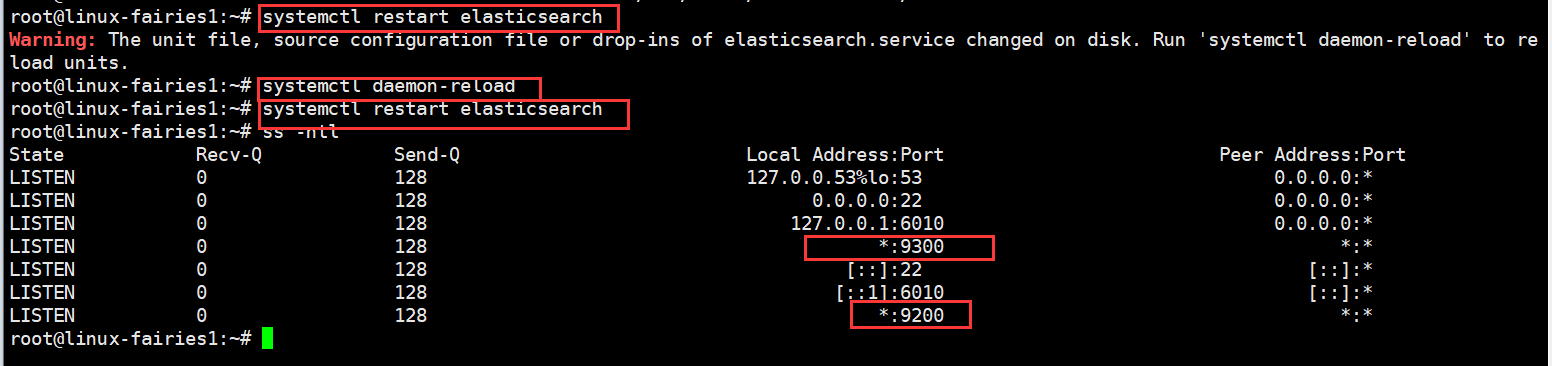
根据上图可知,服务起开了
打开浏览器验证,见下图
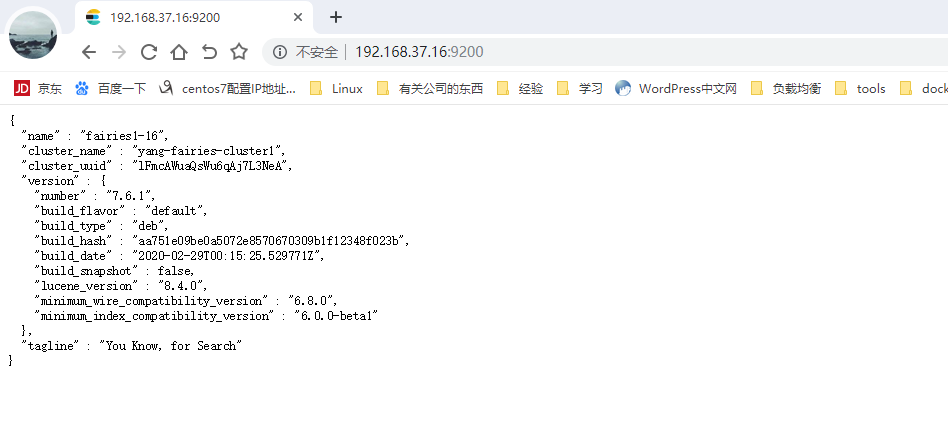
由上图可知,elasticsearch集群服务创建成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号