关键词提取之TextRank
1、背景
关键词提取我们前面介绍了TF-IDF和他的改进版TF_IWF,关于关键词提取简介和应用可以参考以上前篇文章。
在前面我们讲过网页排序算法PageRank的原理,将PageRank用到文本的关键词提取就是TextRank了。
2、原理
相比于PageRank,如下图所示在TextRank中,无非是将单词作为节点,每个单词的外链来源于该单词前后固定大小窗口的所有单词。
类似于RageRank的思想,TextRank也可以这么解释:
- 如果一个词出现在很多词后面,说明这个词比较重要。
- 一个TextRank值很高的词链接到另一个词,那么另一个词的TextRank值也会相应的较高。
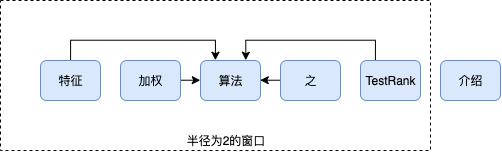
比如对于“算法”一词,前后各两个词链接到它,并使用这四个词来解释中心词,相当于给中间词各投投票,投票的权重等于窗口内的投票词的权重除以投出所有票数的平均,中心词两边的词越多,所得到的票数越多,可见高频词得到的投票机会越大,但是并不意味着权重越高,因为其受限于投票词的权重。
通过改写 PageRank 公式得到 TextRank 的公式为:
\[
WS(V_{i})=(1-d)+d\times\sum_{V_{j}\in{In{(V_{i})}}}\frac{w_{i,j}}{\sum_{V_{k}\in{Out(V_{j})}}w_{j,k}}WS({V_{j})}
\]
其中,\(In{(V_{i})}\) 是指向节点 \(V_{i}\) 的的所有单词集合,\(\frac{w_{i,j}}{\sum_{V_{k}\in{Out(V_{j})}}w_{j,k}}\) 的分子表示词 \(V_{j}\) 链接到 \(V_{i}\) 的权重,分母表示节点 \(V_{j}\) 指向的所有链接的权重和。
3、编程实现
在调研TextRank的时候,发现已经有很多优秀的开源实现,Python语言里有结巴分词、TextRank4zh、Java工具Hanlp等,我们就不必自己造轮子,简单介绍一下。
import jieba.analyse
str = "特征加权算法之TextRank介绍"
result = jieba.analyse.extract_tags(str,withWeight=True)
print(result)
""" Output:
[('TextRank', 2.39095350058),
('算法', 1.738238299826),
('加权', 1.6091211459539998),
('特征', 1.141123992216),
('介绍', 1.106907987096)]
"""
from textrank4zh import TextRank4Keyword
tr4w = TextRank4Keyword()
str = "特征加权算法之TextRank介绍"
tr4w.analyze(text=str, lower=True, window=2, pagerank_config={'alpha':0.85})
for item in tr4w.get_keywords(6, word_min_len=2):
print(item.word, item.weight, type(item.word))
""" Output
加权 0.2459454192354203 <class 'str'>
textrank 0.2459454192354203 <class 'str'>
算法 0.23905458076457978 <class 'str'>
特征 0.1345272903822899 <class 'str'>
介绍 0.1345272903822899 <class 'str'>
"""
对比发现TextRank提供的参数选择比结巴分词更加丰富,更贴切我们上述的公式原理分析。
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.summary.TextRankKeyword;
import java.util.List;
/**
* 关键词提取
* @author hankcs
*/
public class DemoKeyword
{
public static void main(String[] args)
{
String content = "特征加权算法之TextRank介绍";
List<String> keywordList = HanLP.extractKeyword(content, 5);
System.out.println(keywordList);
}
}
/**
* [特征, 介绍, 加权, TextRank, 算法]
*/
Hanlp输出没有封装分数,通过debug后发现分数都一致,这点应该和语句词频和指向相关,增加语句长度效果立显,读者可以尝试。

4、总结
TextRank提取关键词的效果其实并不会优于TF-IDF,因为都倾向于将频繁词作为关键词。此外,TextRank涉及到构建图及迭代计算,所以计算速度应该较TF-IDF慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号