【2022.11.04】pytorch的使用相关(二)
【2022.11.04】pytorch的初始化
前言
参考代码来自于:Fafa-DL/Lhy_Machine_Learning: 李宏毅2021春季机器学习课程课件及作业 (github.com)
数据集来自于:https://github.com/ga642381/ML2021-Spring/blob/main/HW01/HW01.pdf
设置固定种子
设置种子的用意是:一旦固定种子,后面依次生成的随机数其实都是固定的。
同样的道理,也可以手动设置GPU的随机数生成种子:
torch.cuda.manual_seed(seed) – 设置当前GPU的随机数生成种子
torch.cuda.manual_seed_all(seed) – 设置所有GPU的随机数生成种子
set a random seed for reproducibility
在每次重新运行程序时,同样的随机数生成代码得到的是同样的结果。
打个比方:设置好种子后,第一次运行程序时,第一个生成的随机数是A,第二个生成的随机数是B, 第三个生成的随机数是C,第四个生成的随机数是D。那么,不管第二次,第三次,还是第n次运行程序时,第一个生成的随机数仍然是A,第二个生成的随机数仍然是B, 第三个生成的随机数仍然是C,第四个生成的随机数仍然是D。
ps:手动设置种子一般可用于固定随机初始化的权重值,这样就可以让每次重新从头训练网络时的权重的初始值虽然是随机生成的但却是固定的。
myseed = 42069 # set a random seed for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed)
torch.backends.cudnn.deterministic
将这个 flag 置为True的话,每次返回的卷积算法将是确定的,即默认算法。如果配合上设置 Torch 的随机种子为固定值的话,应该可以保证每次运行网络的时候相同输入的输出是固定的
torch.backends.cudnn.deterministic 将这个 flag 置为 True 的话,每次返回的卷积算法将是确定的,即默认算法。如果配合上设置 Torch 的随机种子为固定值的话,应该可以保证每次运行网络的时候相同输入的输出是固定的。
torch.backends.cudnn.benchmark
在使用GPU的时候,PyTorch会默认使用cuDNN加速,但是,在使用 cuDNN 的时候,torch.backends.cudnn.benchmark模式是为False。
设置这个 flag 为True,我们就可以在 PyTorch 中对模型里的卷积层进行预先的优化,也就是在每一个卷积层中测试 cuDNN 提供的所有卷积实现算法,然后选择最快的那个。这样在模型启动的时候,只要额外多花一点点预处理时间,就可以较大幅度地减少训练时间。
如果我们的网络模型一直变的话,不能设置cudnn.benchmark=True。因为寻找最优卷积算法需要花费时间。
这段代码一般放在训练代码的开头,比如再设置使用GPU的同时,加在后面
如果在 PyTorch 程序中设置了 torch.backends.cudnn.deterministic=True,并且 cudnn.benchmark == False的话,那么就选那个默认的卷积算法
训练集(train)验证集(validation)测试集(test)与交叉验证法
机器学习中这三种数据集合非常容易弄混,特别是验证集和测试集,这篇笔记写下我对它们三个的理解以及在实践中是如何进行划分的。
训练集
这个是最好理解的,用来训练模型内参数的数据集,Classfier直接根据训练集来调整自身获得更好的分类效果
验证集
用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。
同时验证集在训练过程中还可以用来监控模型是否发生过拟合,一般来说验证集表现稳定后,若继续训练,训练集表现还会继续上升,但是验证集会出现不升反降的情况,这样一般就发生了过拟合。所以验证集也用来判断何时停止训练
测试集
测试集用来评价模型泛化能力,即之前模型使用验证集确定了超参数,使用训练集调整了参数,最后使用一个从没有见过的数据集来判断这个模型是否Work。
三者区别
形象上来说训练集就像是学生的课本,学生 根据课本里的内容来掌握知识,验证集就像是作业,通过作业可以知道 不同学生学习情况、进步的速度快慢,而最终的测试集就像是考试,考的题是平常都没有见过,考察学生举一反三的能力。
为什么要测试集
训练集直接参与了模型调参的过程,显然不能用来反映模型真实的能力,这样一些 对课本死记硬背的学生(过拟合)将会拥有最好的成绩,显然不对。同理,由于验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型,就像刷题库的学生也不能算是学习好的学生是吧。所以要通过最终的考试(测试集)来考察一个学(模)生(型)真正的能力。
但是仅凭一次考试就对模型的好坏进行评判显然是不合理的,所以接下来就要介绍交叉验证法
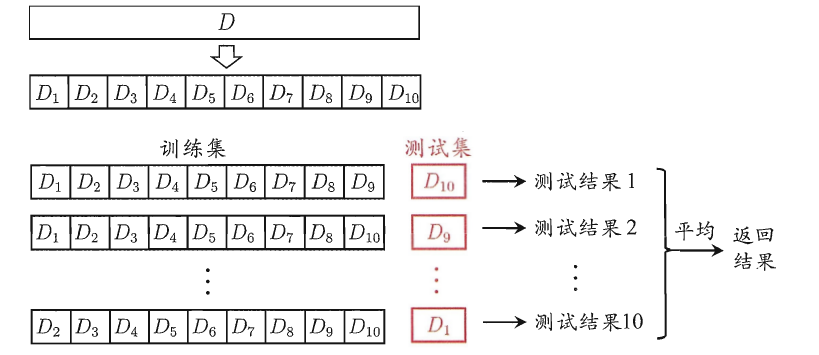
交叉验证法
交叉验证法的作用就是尝试利用不同的训练集/测试集划分来对模型做多组不同的训练/测试,来应对单词测试结果过于片面以及训练数据不足的问题。
交叉验证的做法就是将数据集粗略地分为比较均等不相交的k份,然后取其中的一份进行测试,另外的k-1份进行训练,然后求得error的平均值作为最终的评价
Dataset和Dataloader
Dataset用于分类,而Dataloader用于调整成合适的规格塞入网络
梯度下降

学习率LR的设置
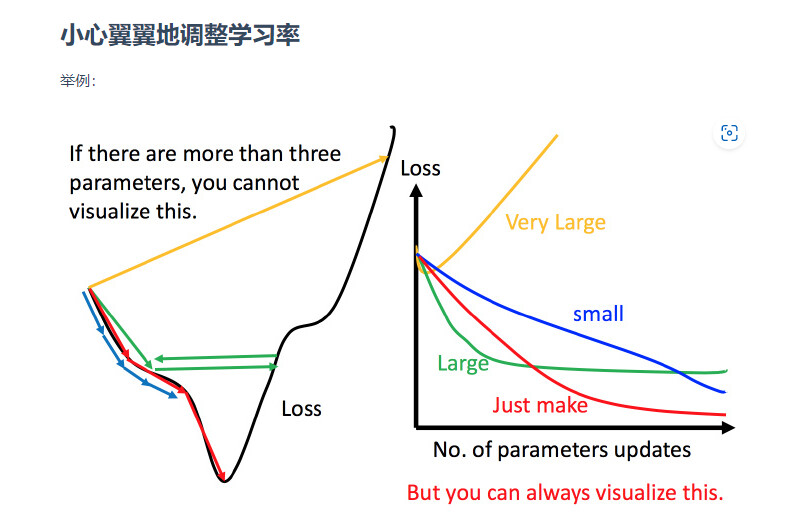
上图左边黑色为损失函数的曲线,假设从左边最高点开始,如果学习率调整的刚刚好,比如红色的线,就能顺利找到最低点。如果学习率调整的太小,比如蓝色的线,就会走的太慢,虽然这种情况给足够多的时间也可以找到最低点,实际情况可能会等不及出结果。如果 学习率调整的有点大,比如绿色的线,就会在上面震荡,走不下去,永远无法到达最低点。还有可能非常大,比如黄色的线,直接就飞出去了,更新参数的时候只会发现损失函数越更新越大。
虽然这样的可视化可以很直观观察,但可视化也只是能在参数是一维或者二维的时候进行,更高维的情况已经无法可视化了。
解决方法就是上图右边的方案,将参数改变对损失函数的影响进行可视化。比如学习率太小(蓝色的线),损失函数下降的非常慢;学习率太大(绿色的线),损失函数下降很快,但马上就卡住不下降了;学习率特别大(黄色的线),损失函数就飞出去了;红色的就是差不多刚好,可以得到一个好的结果。
参考链接
https://blog.csdn.net/weixin_43002433/article/details/104706950
(3条消息) 为什么要设置torch.backends.cudnn.deterministic=True_月亮在偷看吖的博客-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号