【2022.06.08】为什么选择Huginn
经过一段时间在公司的工作,我深刻意识到信息获取的重要性
已经搭载在宿舍的服务器上了
账号admin,密码password
为什么会选择huginn呢,我想从流程上、技术上、用户体验上给出我的理由
流程上
在信息获取流程分为三个阶段,以研究员举例
传统获取信息方式
研究员需要不定期、定期去某个网站获取数据,手动摘录数据
改进后的获取信息方式
程序员根据研究员的需求,为其定制了一个软件,方便研究员获取数据
或者说,程序员开发程序,让程序定期检查信息是否更新,一旦有信息更新,研究员可以及时接收到信息的变化(通过邮件)
我们现在就处于这个阶段,但是这种方式存在的缺点是
①一个程序对应一个网站进行爬取,适应性很差,但很多研究员的需求却是相似的,需要重复开发
②没有图形界面的话,研究员存在一定的学习成本,程序员就需要考虑开发图形界面,但是这对程序员是没必要的支出
③程序员开发的软件只能在对应的研究员电脑上运行,一旦出现问题,或者说需求出现变更,程序员可能需要回到该研究员电脑上修改,如果开发不够规范的话,读懂过去的代码又要花去大量的时间成本
较好的获取信息方式
有一台服务器,可以满足程序员随时在上面进行修改需求
将处理后的内容发送到微信群聊、QQ群聊
但是我不希望,根据一个网站写一个脚本,而是使用通用协议的方式,获取到相同格式的内容再进行推送,这里我想使用是RSS的方式
我找到了一个名为huginn的开源项目,可以可视化、自动化、模块化、定制自己所需要的数据,再将数据以邮箱或者RSS源的方式进行推送
如果有需要的数据,huginn将其处理后,可以直接调用HTTP将其输入到数据库之中
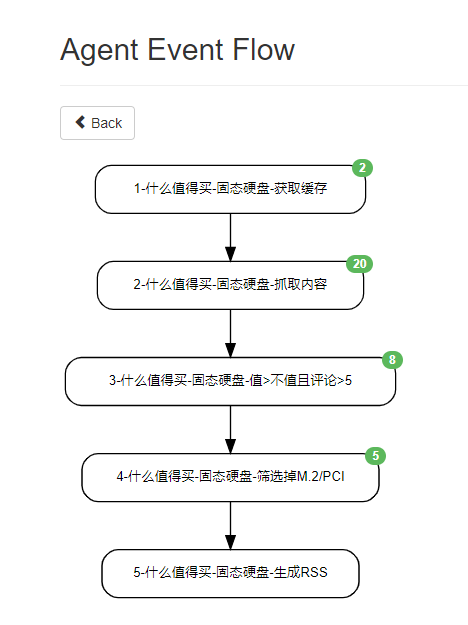
以上是一个爬取动态页面的示例,我最近服务器存储满了想要买个便宜硬盘
最后生成RSS,并且每日9点推送到我的QQ上
运用在工作中
就好比同样是爬取交易所公告,这个huginn就可以模块化筛选出想要的数据(比如玉米、矿物的公告),而不是一有消息更新就推送到所有人的邮箱
我收到以下邮件,就是对我来说完全无用的数据,产生干扰
技术上
当使用python时,会很经常用到request这个包,但是这个包只能跑静态页面,但随着技术更新,比如郑商所,爬虫就难起效果
动态页面就需要使用selenium这个包,这个包很强大,但是有一个很大的缺点,需要在研究员的电脑上安装对应的浏览器+浏览器驱动,不到万不得已一般是不会用selenium的,而且随着反爬机制加强,selenium也很吃力
Huginn的缺点也是有的,这几天体验下来,只有爬取没验证码的页面会好用一些,尽管动态和静态页面的爬取都有解决方案,但是要使用JavaScript进行一些额外的脚本处理,这个语言和Java也没啥关系,我也没接触过,有些学习成本
用户体验上
我是经常使用bot的玩家,我对消息的推送有两种截然不同的态度
①非常重要且有时效性的消息要及时推送给我个人,越快越好
②一般的消息最好是合并后,在固定的时间段(比如上班后9点整,集合推送),我可以一口气浏览完,而不是我在一天分散的时间段,消息一有更新立马推送给我,它们会对我的工作产生不停的打断
而以上的需求,在我仔细琢磨了一下Huginn后,发现它满足了我所有的需求
但Huginn中文的教程很少很少,我需要花费大量时间去查阅英语资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号