【2022.06.04】huginn对动态网页进行爬取
前言
下载了别人的scenarios,Huginn.io (huginnio.herokuapp.com),想看看数据是怎么进行传输的,最后怎样生成RSS
结果发现该链接已经变成了动态网页,不能使用静态获取
那么就顺便学习一下怎么爬取动态网页吧
Phantom Js agent
注册
进入网站进行注册,只要邮箱就行,每日有500次的爬取次数,这个网站是可以正常访问的
PhantomJsCloud API Service - It just works!
注册好了就可以得到apikey
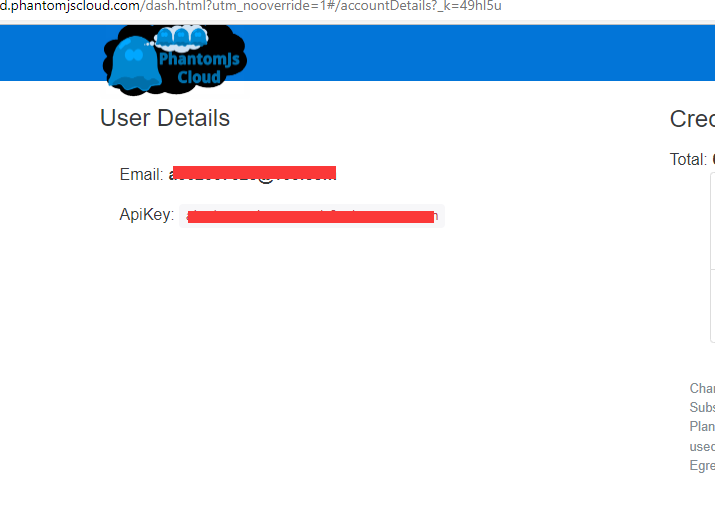
接下来就是增加一个全局变量
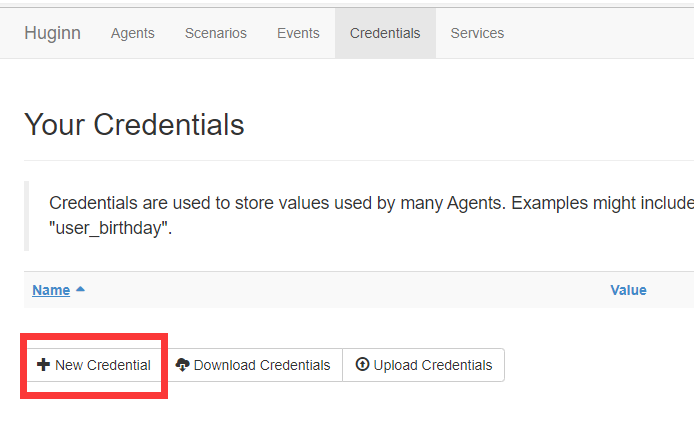
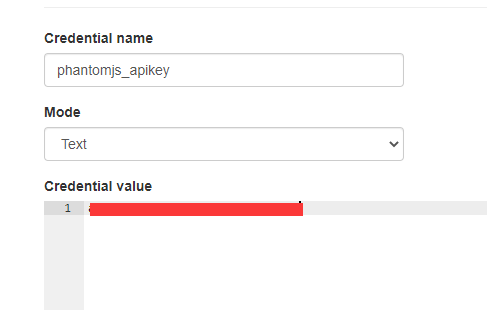
创建好了并保存
创建agent
在type中找到phantomjs
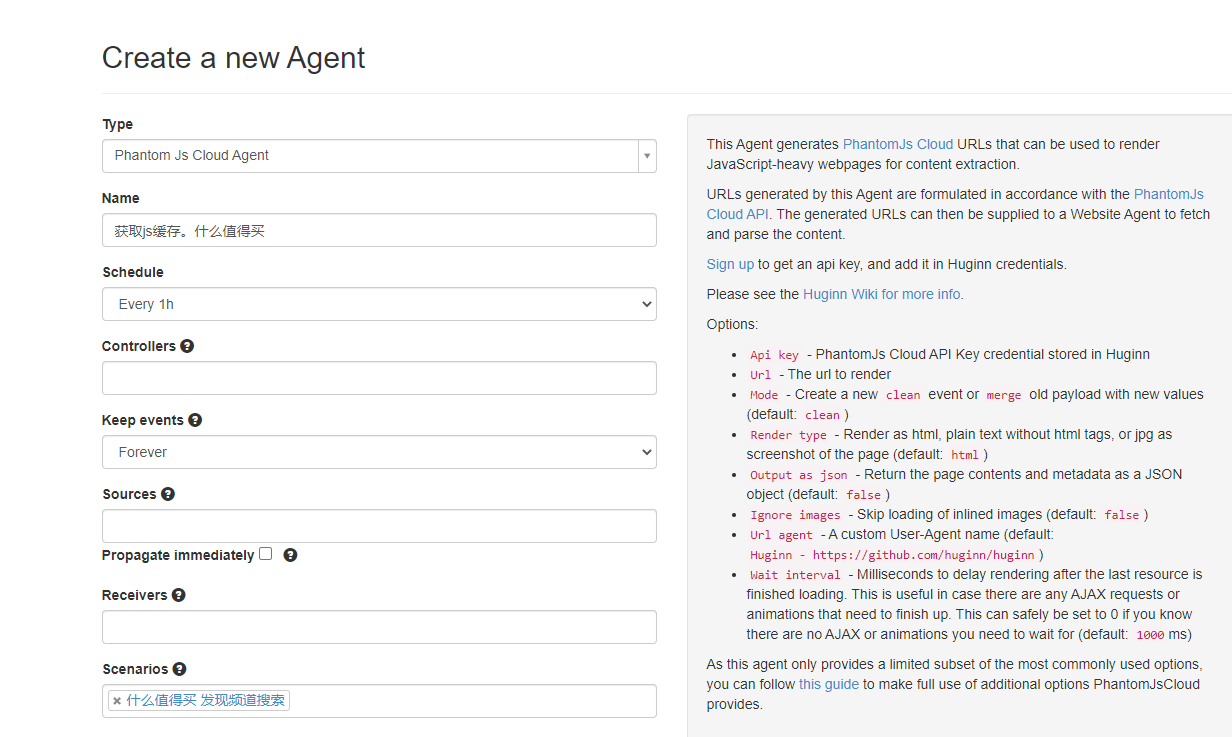
进入要爬取的网页,复制自己的UA
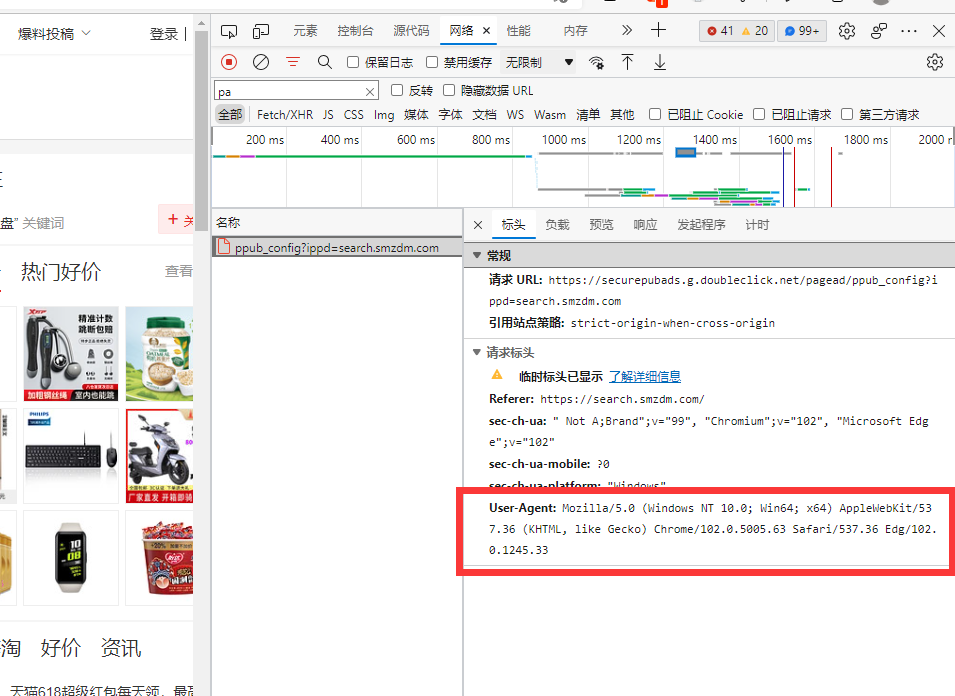
在选项中填入以下内容
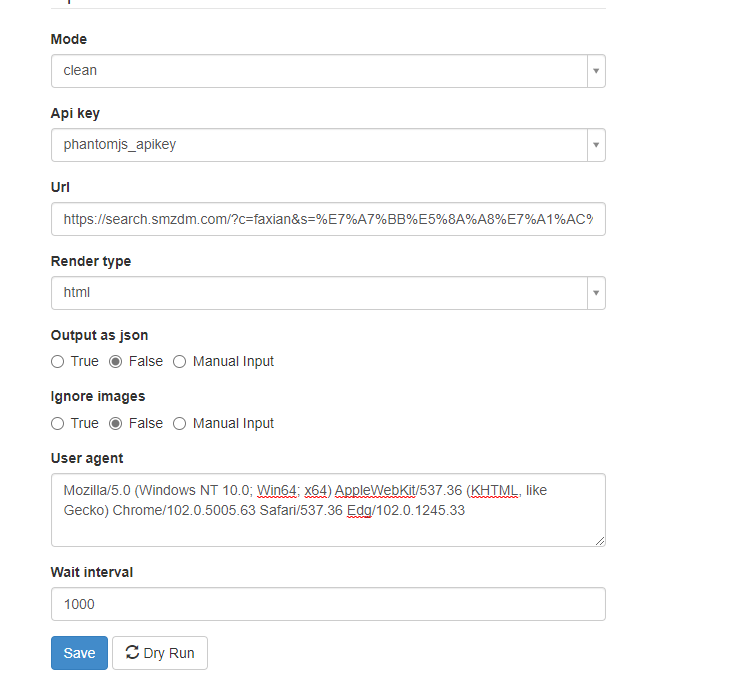
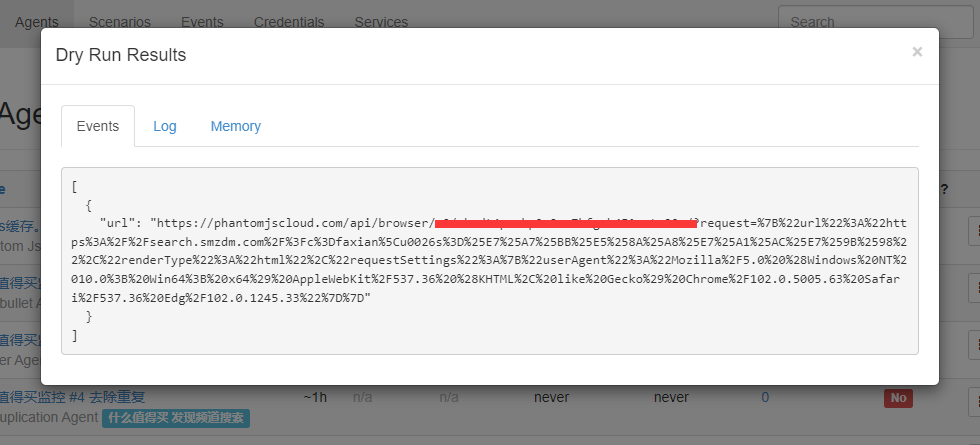
试运行一下,是可以获取到内容的
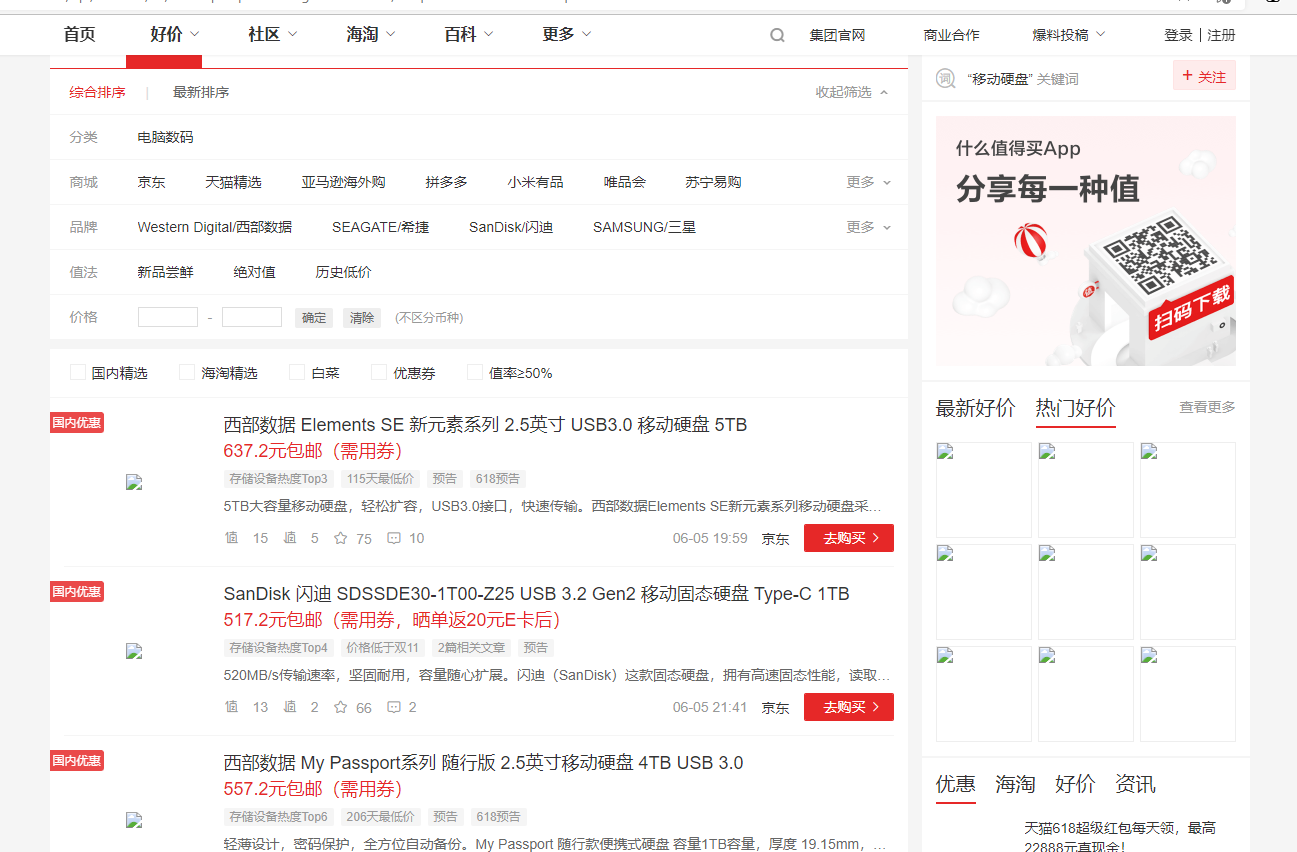
也可以进入该网页查看内容
网页agent
这个是最常用的agent
Propagate immediately 要勾上,意思是说,如果上一个source产生event后,立即运行该agent
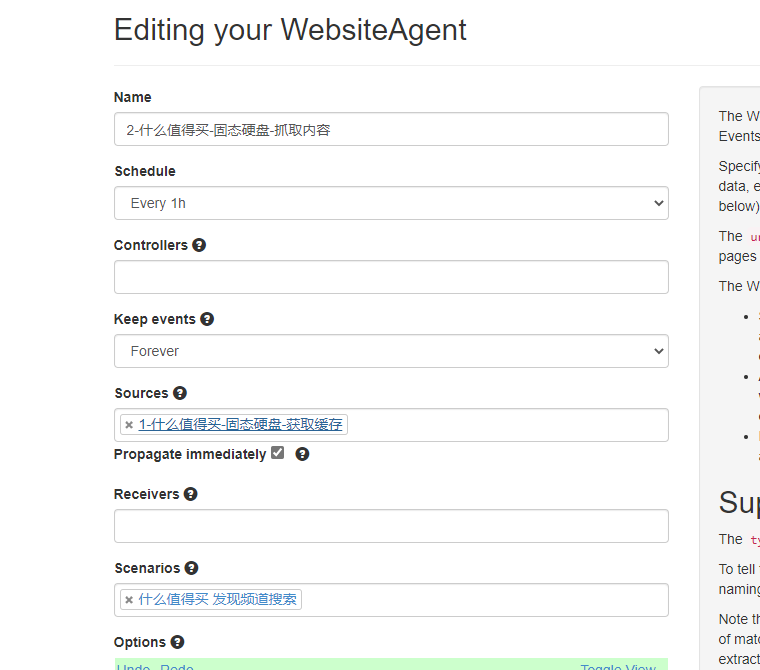
sources填写上个agent
进入上一步获取的event的url之中,开始修改
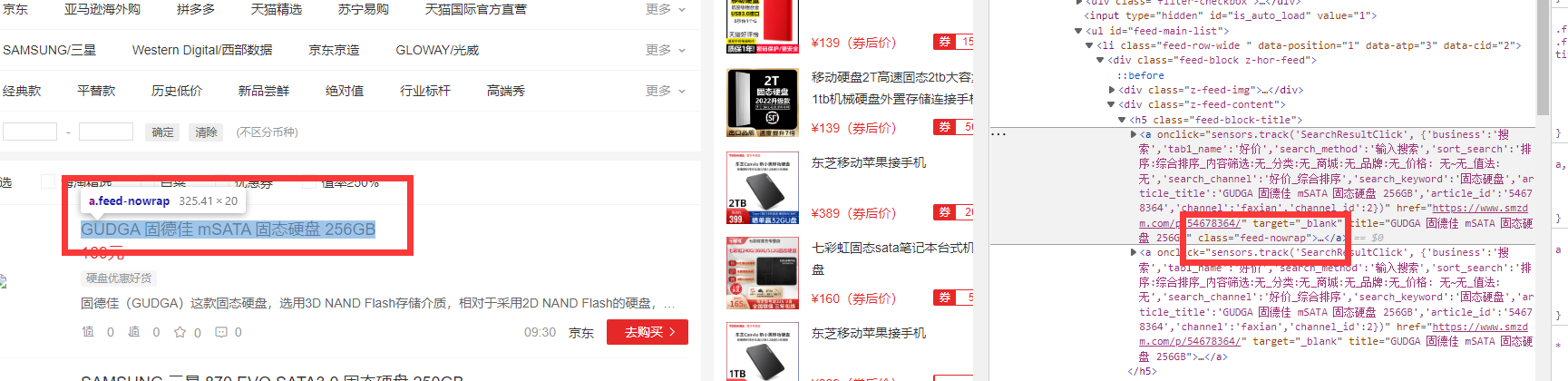
由这里可以得到我们要的标题和链接位置均为
//*[@class='feed-nowrap']
在元素控制台使用ctrl+f验证一下位置对不对
在options里面填入以下内容
{
"expected_update_period_in_days": "2",
"url_from_event": "{{url}}",
"type": "html",
"mode": "on_change",
"extract": {
"title": {
"xpath": "//*[@class='feed-nowrap']",
"value": "@title"
},
"url": {
"xpath": "//*[@class='feed-nowrap']",
"value": "@href"
},
"price": {
"xpath": "//*[@class='z-highlight']",
"value": "text()"
}
}
}
记得要选一个最近的event再进行试运行
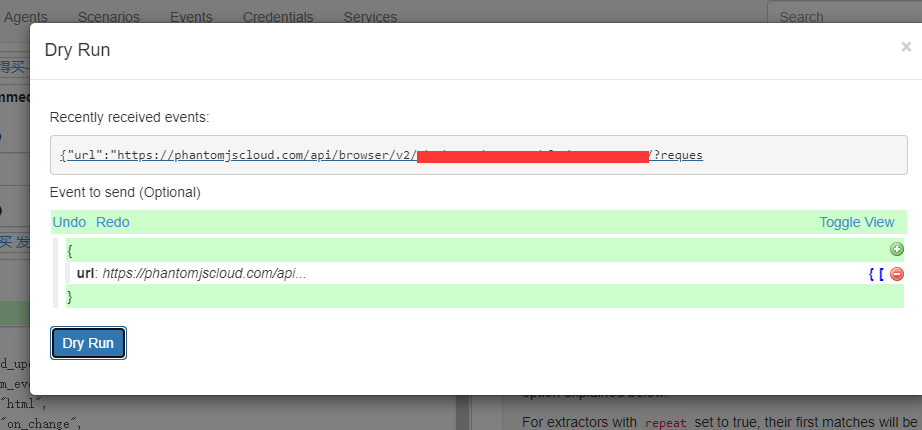
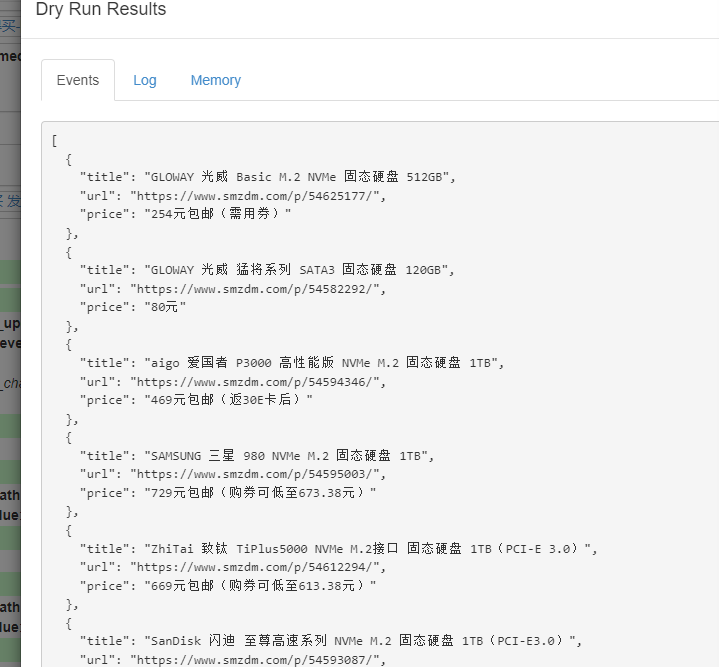
试运行一下,可以得到以下数据
RSS agent
到了最后一步生成数据,先使用DataOutputAgent吧
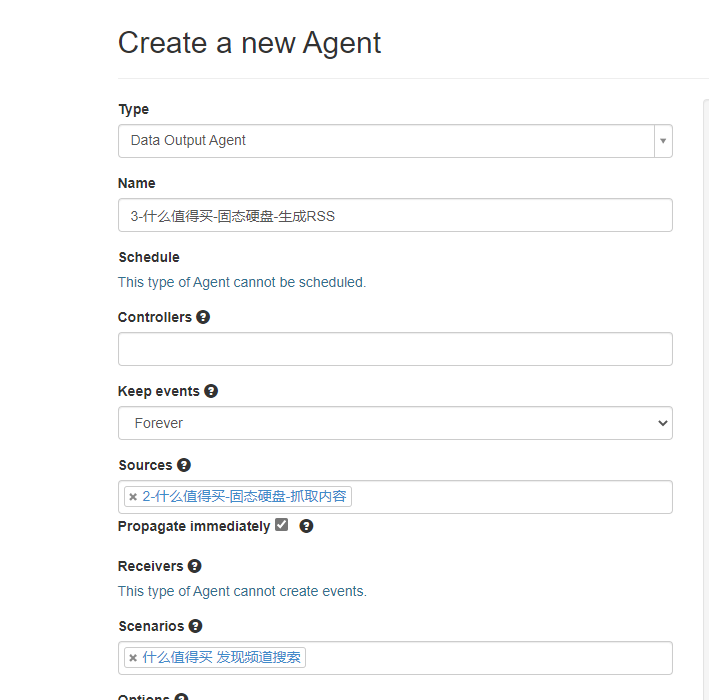
导入RSS阅读器
在最后的event中,点击show,得到xml链接
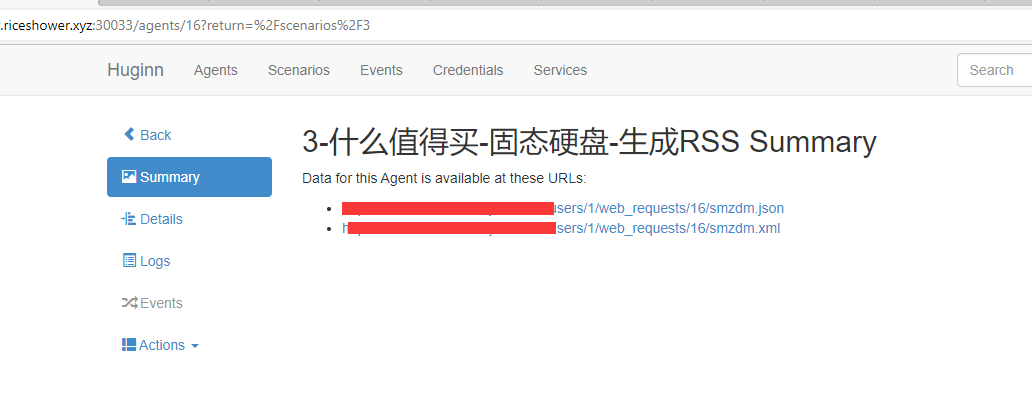
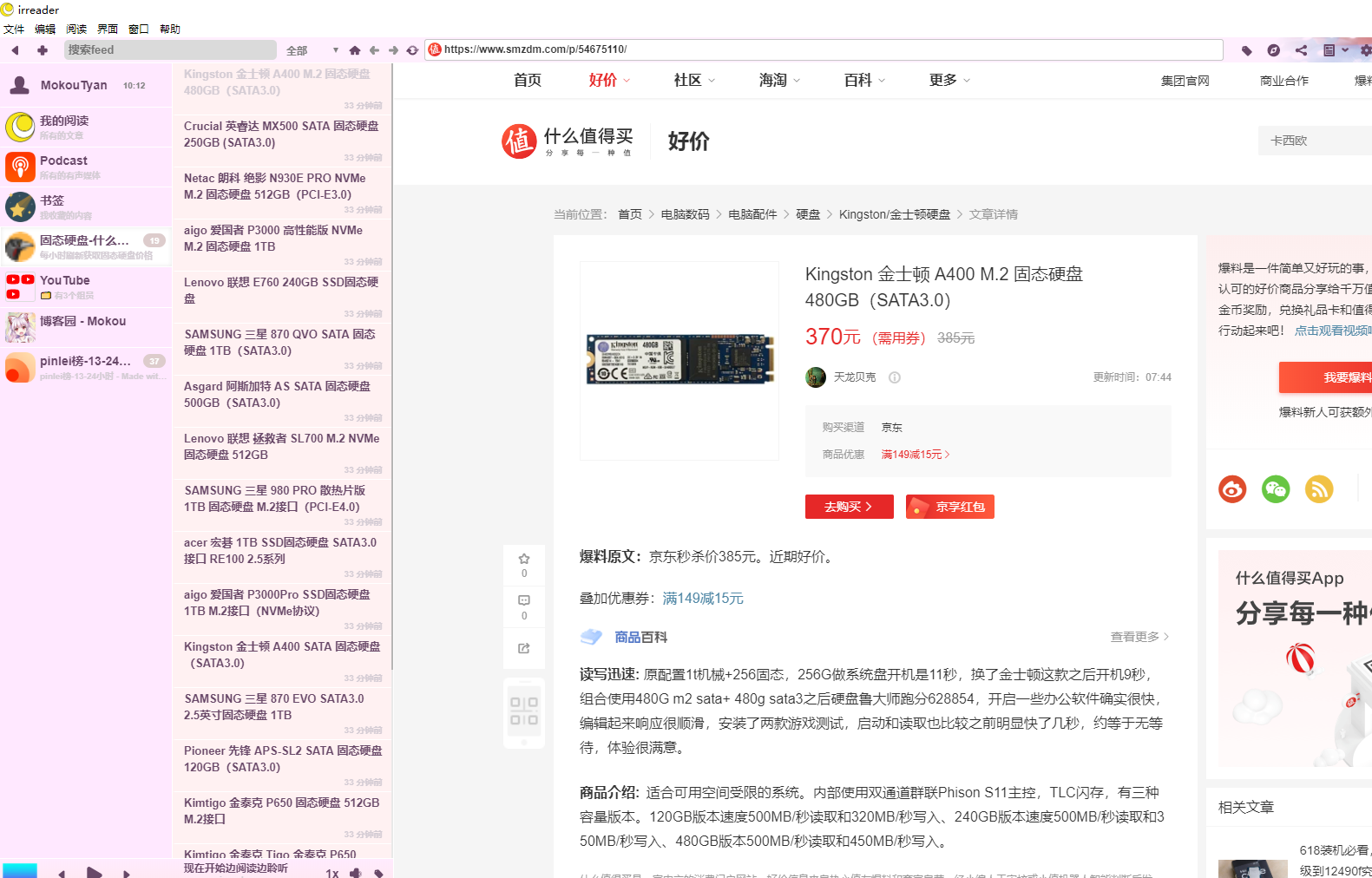
xml链接,导入阅读器则可以得到如下内容
参考链接
RSS 进阶篇:Huginn - 真·为任意网页定制 RSS 源(PhantomJs 抓取) - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号