【2022.05.24】对无验证码的整个网页公告的内容进行自适应爬取(3)
前言
今天发现昨天的想法有误了,动态获取到的html文件,后面如果使用requests去获取的话就是静态html文件,那么就有可能得不到真实的html文件,大部分网站是不会变的,但是像大连交易所的网站就会动态加载,需要使用selenium来获取html文件
经过反复排查比对,发现是html的注释部分出了问题,只要注释里面也含有标签,就会影响到判断,因此在获取xpath前,需要对得到的html文件进行删除注释处理,因此加入以下代码
# 去除掉注释,防止getroottree获取到不正确的xpath
soup = BeautifulSoup(page.text,'html.parser')
for element in soup(text=lambda text: isinstance(text, Comment)):
element.extract()
print(str(soup))
获取通告标题很简单,只要获取得到的链接的标题就行
具体的路径是
/html/head/title
学习内容
最折磨的莫过于找出公告的具体位置xpath
我的想法是,找出最多字数的div,然后返回其xpath,但是有的div太大了,把其他位置div的文字算进去了
和朋友讨论了一下,最后用了一个取巧的办法,就是找出最多字数的p,然后将其xpath删减到最近的div
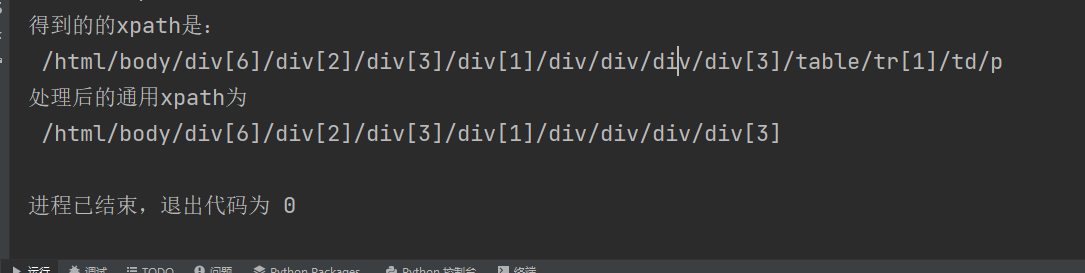
未解决问题
selenium因为没法子返回xpath路径,所以被这个问题折磨,还有的网站完全不按规范来,就很难做到自适应
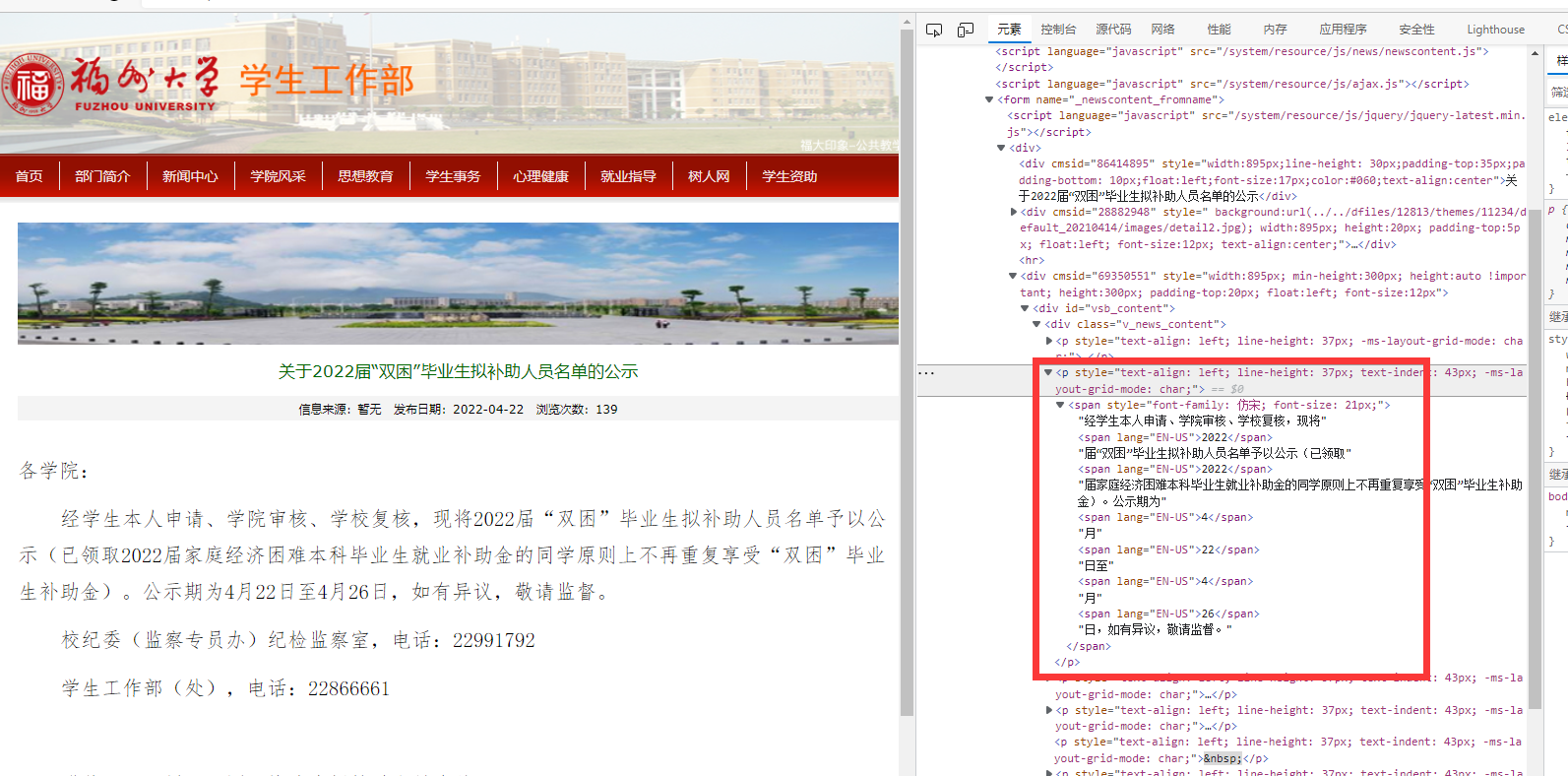
还有的网站,比如福师大的,它的标题不是放在ul中的,而是放在tbody,这让我非常痛苦
代码
from bs4 import BeautifulSoup, Comment
import requests
from lxml import etree
from lxml import html
import json
import time
from urllib.parse import urljoin
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# 全局变量
with open('config.json', 'r', encoding='utf-8') as f:
JsonFile = json.load(f)
base_url = JsonFile['url']
notice_title_href_xpath = JsonFile['notice_title_href_xpath']
notice_title_xpath = JsonFile['notice_title_xpath']
notice_content_xpath = JsonFile['notice_content_xpath']
notice_pages = JsonFile['notice_pages']
search = JsonFile['search']
notice_content_xpath = notice_content_xpath.replace("替换", search)
# 全局变量不修改,调试用的
chrome_driver = r'.\chromedriver.exe' # chromedriver的文件位置
next_page_keywords = JsonFile['next_page_keywords']
delay = JsonFile['delay']
notice_list_number = JsonFile['notice_list_number']
open_xpath_search_mode = JsonFile['open_xpath_search_mode']
content_page_number = JsonFile['content_page_number']
# 返回下一页的链接,因为是动态js加载的,所以我要使用selenium
def get_next_page_url(current_url, notice_pages):
s = Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=s)
driver.get(current_url)
time.sleep(5)
result = []
result.append(driver.current_url)
i = 1
print(driver.current_url)
print("开始寻找所有的公告页面")
while True:
try:
pre_url = driver.current_url
driver.find_element(by=By.XPATH, value=next_page_keywords).click()
if driver.current_url == pre_url:
break
i = i + 1
result.append(driver.current_url)
if i >= notice_pages:
break
time.sleep(delay)
except:
print("到达页数上限")
break
print("已找到所有页面,一共有", i, "页")
time.sleep(3)
driver.quit()
print(result)
return result
# 自适应寻找公告列表的xpath
def get_notice_page_title(base_url):
s = Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=s)
driver.get(base_url)
time.sleep(1)
# dynamic_html = driver.execute_script("return document.documentElement.outerHTML")
# print(dynamic_html)
# print(driver.execute_script("return document.documentElement.innerHTML"))
ul_list = driver.find_elements(By.XPATH, value="//ul")
result = ""
# 找出最长ul
temp = 0
for ul in ul_list:
# 没有字数的列表块跳过不输出
if len(ul.text) == 0:
continue
elif len(ul.text) > temp:
print("————————————————————————————————————————————")
print("【当前最大列表块】\n字数:", len(ul.text), "\n内容:\n", ul.text)
print("————————————————————————————————————————————")
temp = len(ul.text)
print(temp)
# li_list记录的是最长板块的列表集合
li_list = ul.find_elements(By.XPATH, value="li")
try:
result = li_list[notice_list_number].find_element(By.XPATH, value="a").text
except:
continue
# 将列表中的第二个公告赋予xpath,防止置顶贴
print("\n")
print("最后得到的公告标题为:\n", result)
return result
# driver.quit()
# 将标题去获取页面的标题xpath
def get_xpath(title, url, search_element):
page = requests.get(url)
page.encoding = 'utf-8'
# print(page.text)
# 去除掉注释,防止getroottree获取到不正确的xpath
soup = BeautifulSoup(page.text, 'html.parser')
for element in soup(text=lambda text: isinstance(text, Comment)):
element.extract()
# print(str(soup))
root = html.fromstring(str(soup))
tree = root.getroottree()
temp_xpath = "//" + search_element + "[contains(text(),\"" + title + "\")]"
# print(temp_xpath)
result = root.xpath(temp_xpath)
result_xpath = tree.getpath(result[0])
print("得到的的xpath是:\n", result_xpath)
# 如果有多项才使用for循环
# for r in result:
# print(tree.getpath(r))
return result_xpath
# 将取得的单项xpath处理成多项,将最后的li后面中括号去掉
def handle_suffix_of_title_xpath(pre_xpath):
# print(pre_xpath.rfind('[', beg=0, end=len(title_xpath)))
print(str.rfind(pre_xpath, '[', 0, len(pre_xpath)))
x = str.rfind(pre_xpath, '[', 0, len(pre_xpath))
# print(pre_xpath)
string_list = list(pre_xpath)
# print(len(string_list))
# print(string_list)
del string_list[x:x+3]
# print(len(string_list))
# print(string_list)
after_xpath = ''.join(string_list)
# print(len(pre_xpath))
# # print(pre_xpath)
# # print(len(after_xpath))
print("处理后的通用xpath为", after_xpath)
return after_xpath
# 获取所有公告的链接
def get_all_notice_url_list(notice_pages_list):
notice_list = []
for notice_page in notice_pages_list:
# current_url = notice_page
# print(current_url)
# print(notice_page)
current_html = requests.get(notice_page)
current_html.encoding = "utf-8"
selector = etree.HTML(current_html.text)
title_href_xpath = after_title_xpath + "/@href"
notice = selector.xpath(title_href_xpath)
# print(notice) 打印当前页面的所有公告href
# 获取当前页面所有公告
for result in notice:
# 获得所有公告网址
notice_url = urljoin(notice_page, result)
notice_list.append(notice_url)
# print("网址: ", notice_url)
# # 获取文本标题
# notice_html = requests.get(notice_url)
# notice_html.encoding = "utf-8"
# notice_selector = etree.HTML(notice_html.text)
# notice_title_name_xpath = """/html/head/title/text()"""
# notice_title_name = notice_selector.xpath(notice_title_name_xpath)
# print("标题: ", notice_title_name[0])
return notice_list
# 自适应获取公告的内容位置
def get_notice_content_location(all_notice_url_list):
i = 0
for url in all_notice_url_list:
# 自适应加载页数
i = i + 1
if i > content_page_number:
break
# 启用selenium
s = Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=s)
driver.get(url)
time.sleep(1)
p_list = driver.find_elements(By.XPATH, value="//p")
# 找出字最多的p
temp = 0
result = ''
for p in p_list:
# 没有字数跳过不输出
if len(p.text) == 0:
continue
elif len(p.text) > temp:
temp = len(p.text)
print("————————————————————————————————————————————")
print("【当前最大块】\n字数:", len(p.text), "\n内容:\n", p.text)
print("————————————————————————————————————————————")
result = p.text
print("最终获得的p字段内容为:", result)
return result
def handle_suffix_of_content_xpath(pre_xpath):
x = str.rfind(pre_xpath, "div", 0, len(pre_xpath))
string_list = list(pre_xpath)
for i in range(x, len(pre_xpath)):
# print(string_list[i])
if string_list[i] == '/':
del string_list[i:len(pre_xpath)]
break
after_xpath = ''.join(string_list)
print("处理后的通用xpath为\n", after_xpath)
return after_xpath
def get_notice(url_list, notice_content_xpath):
for url in url_list:
print("网址: ", url)
# 获取文本标题
notice_html = requests.get(url)
notice_html.encoding = "utf-8"
notice_selector = etree.HTML(notice_html.text)
notice_title_name_xpath = """/html/head/title/text()"""
notice_title_name = notice_selector.xpath(notice_title_name_xpath)
print("标题: ", notice_title_name[0])
notice_content = notice_selector.xpath(notice_content_xpath)[0].xpath("string(.)")
print("正文:\n", "".join([s for s in notice_content.splitlines(True) if s.strip()]))
if __name__ == '__main__':
# 【动态】自适应获取通知列表的标题,思路是根据ul的字数最多数量判断
title = get_notice_page_title(base_url)
# 【静态】将上面函数获取的标题去获取页面的标题xpath
title_xpath = get_xpath(title, base_url, "a")
# 将取得的单项xpath处理成多项
after_title_xpath = handle_suffix_of_title_xpath(title_xpath)
# 【动态】自适应获取当前后续的所有页面List,防止页面使用js生成下一页链接
notice_pages_list = get_next_page_url(base_url, notice_pages)
# 【静态】将取得的通用xpath去获取所有的链接
all_notice_list = get_all_notice_url_list(notice_pages_list)
# 【动态】自适应获取公告的内容位置,思路是找到字数最多的p
notice_content_location = get_notice_content_location(all_notice_list)
# 【静态】将上面函数获取的内容去获取页面的内容xpath
notice_content_location_xpath = get_xpath(notice_content_location, all_notice_list[0], "p")
# 将取得的单项xpath处理成上级div目录
after_content_xpath = handle_suffix_of_content_xpath(notice_content_location_xpath)
# 【静态】将取得的通用xpath转化为内容
get_notice(all_notice_list, after_content_xpath)
# current_html = requests.get(current_url)
# current_html.encoding = "utf-8"
# selector = etree.HTML(current_html.text)
# notice = selector.xpath(notice_title_href_xpath)
# print(notice)
# 获取当前页面的所有公告
# for result in notice:
# # 获得网址
# result_url = urljoin(current_url, result)
# print("网址: ", result_url)
# result_html = requests.get(result_url)
# result_html.encoding = "utf-8"
# result_detail = etree.HTML(result_html.text)
# result_title = result_detail.xpath(notice_title_xpath)
# print("标题: ", result_title)
#
# result_content = result_detail.xpath(notice_content_xpath)
# print("内容: ")
# for result_print in result_content:
# print(result_print)
# print("\n")
# time.sleep(delay)
配置
{
"?url": "【可修改】用于查找的网页",
"url": "http://www.dce.com.cn/dalianshangpin/ywfw/jystz/ywtz/13305-2.html",
"?search": "【可修改】要查找的公告内容",
"search": "玉米",
"?notice_pages": "【可修改】爬取公告的页数的上限,默认100页",
"notice_pages": 10,
"?1": "——————【分割线,以下请在了解Xpath后修改】——————",
"?open_xpath_search_mode": "是否开启xpath搜索模式,默认关闭0,开启是1",
"open_xpath_search_mode": 0,
"?notice_title_href_xpath": "获取每个公告href的Xpath位置",
"notice_title_href_xpath": "//*[@class='lists diylist']/li/a/@href",
"?notice_title_xpath": "获取每个公告title的Xpath位置",
"notice_title_xpath": "//div[@class='pub-det-title']/text()",
"?notice_content_xpath": "获取每个公告content的Xpath位置",
"notice_content_xpath": "//*[contains(text(),'替换') and @style]/text()",
"?2": "——————【分割线,以下只允许程序员调试】——————",
"?next_page_keywords": "调用selenium时候获取下一页href的关键词",
"next_page_keywords": "//*[contains(text(),'下一页') or contains(text(),'下页')]",
"?delay": "延迟,防止反爬虫",
"delay": 1,
"?notice_list_number": "防止置顶帖子引起公告列表xpath混乱,默认采用第二个公告作为采集xpath链接",
"notice_list_number": 1,
"?content_page_number": "公告内容位置监测自适应页面数量,越多越慢",
"content_page_number": 1
}
参考链接
innerhtml与outerhtml的区别_高明懿大可爱的博客-CSDN博客_innerhtml和outerhtml的区别
Python BeautifulSoup 实战: 去除 HTML 中的注释 - 乐天笔记 (letianbiji.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号