【2022.01.06】使用树莓派安装huginn监控网页变换
【2022.01.06】使用树莓派安装huginn监控网页变换
前言
最近在使用树莓派折腾docker,想找个监控网页变化的软件,这种软件在我去年考研的时候给了我很大的帮助
例如distill,(每十分钟检测特定学校的调剂信息,发生变化的时候及时邮件告诉我,不过distill的免费版功能受限太多,而且需要电脑持续开机和浏览器得在前台,太过耗电,所以我要使用树莓派来解决这个问题)
如果windows想要类似功能,也可以使用Quicker的监控器功能,但是同样需要保持电脑开机,所以并不是很方便(我用这个软件去订阅番剧更新)
但是很多的WebMonitor是使用不了的,因为树莓派是arm32v7架构的,不能使用原版的部署,终于找到一个能用的
安装
huginn这部分中文网上教程不多,折腾了我好久,这里记录一下
找了好多的docker,只有这个成功部署了,如果失败了的话多重试几次,我用的是树莓派3B
sudo docker run -d --name huginn --restart=on-failure:5 -p 3000:3000 -v huginn-data:/var/lib/mysql docker.mirror.aliyuncs.com/mjysci/huginn:arm32v7
安装好后进入网页
http://树莓派地址:3000
点击Login,初始账号:admin,密码:password
主要功能
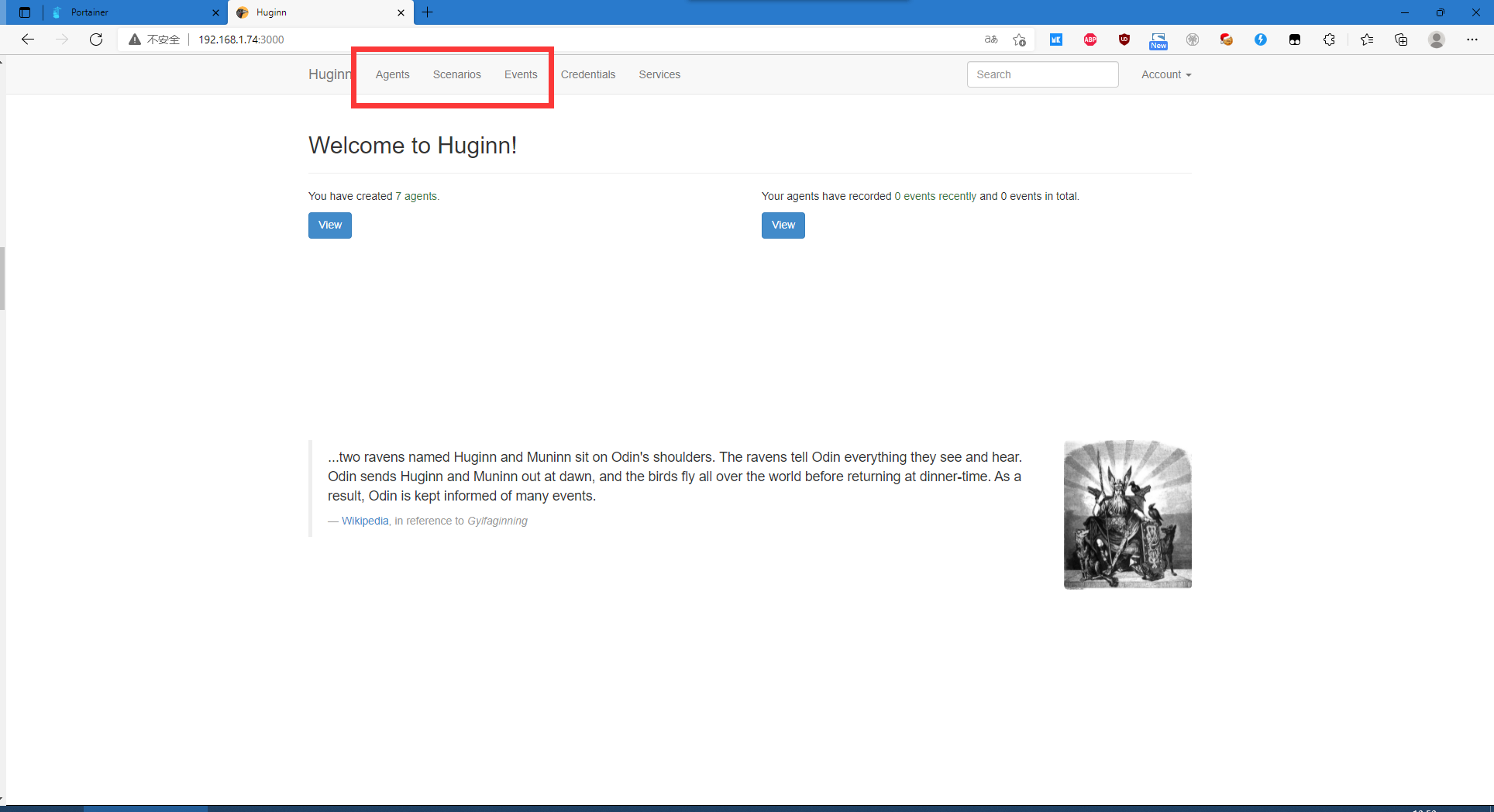
进入后可以看到上方的三个主要功能
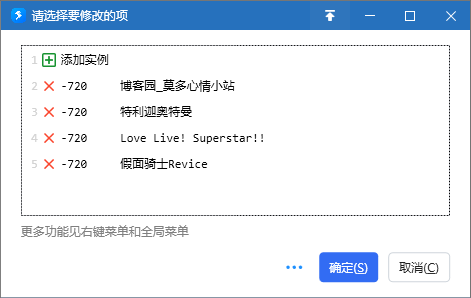
Agents,一个监控的实例
Scenarios,监控实例的集合(比如有的实例是看博客的,有的看价格变化的)
Events,监控的事件记录查看
添加实例
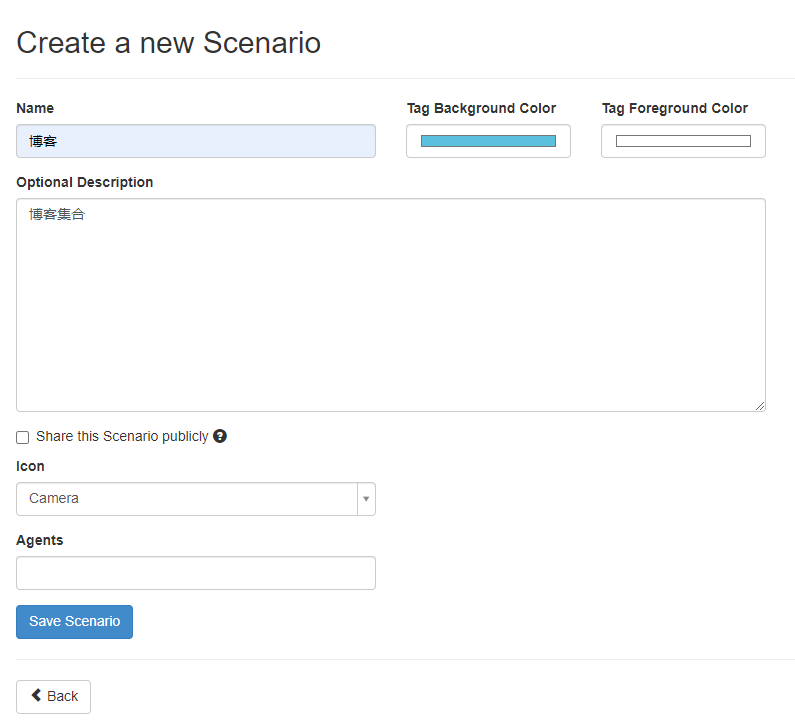
先进入Scenarios,创建一个分类“博客”,先以我的博客变化作为第一个实例
在该分类下新增一个实例,选择Website Agent
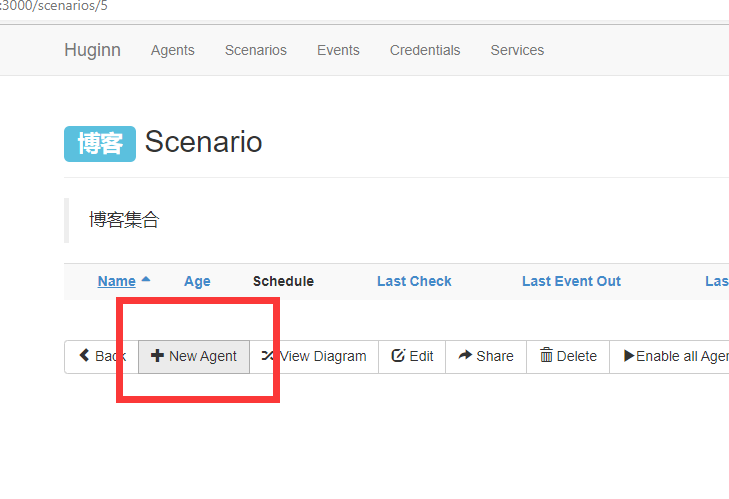
只要更改名字和检测周期就行,其他可以不用修改
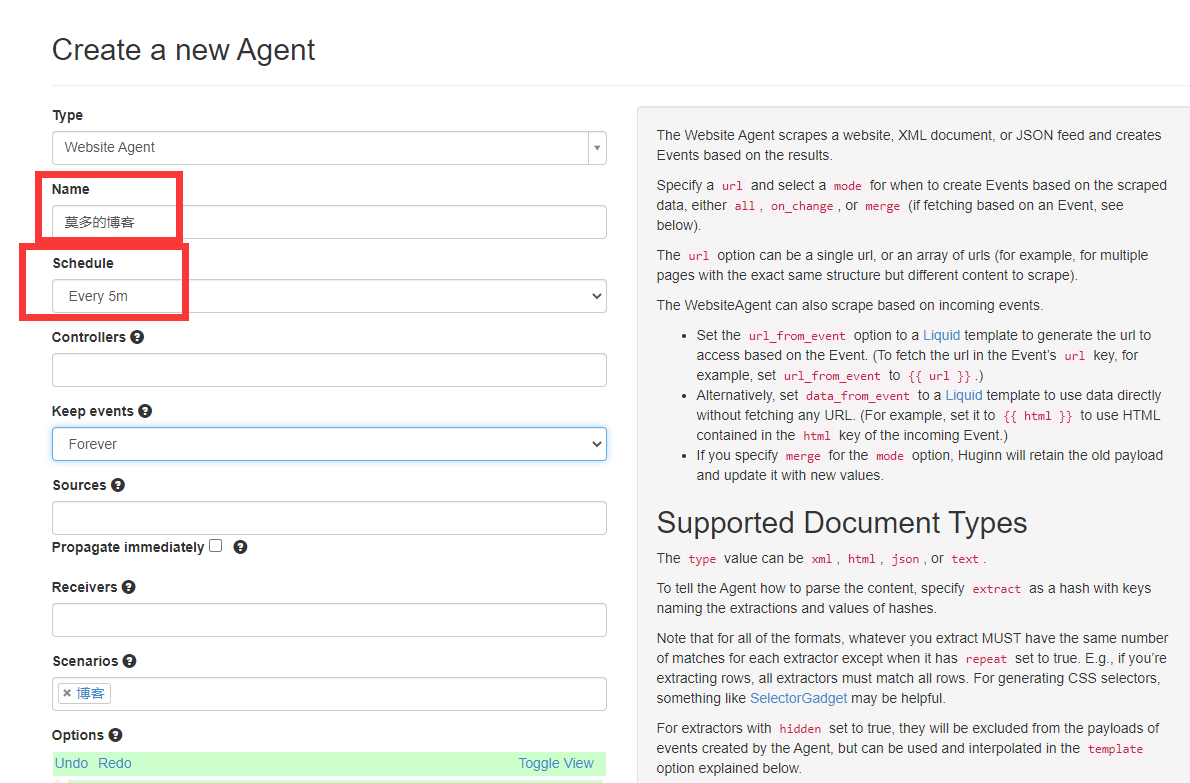
接下来就是最关键的Options的填写,右边的所有英文都是在解释如何填写这部分内容的
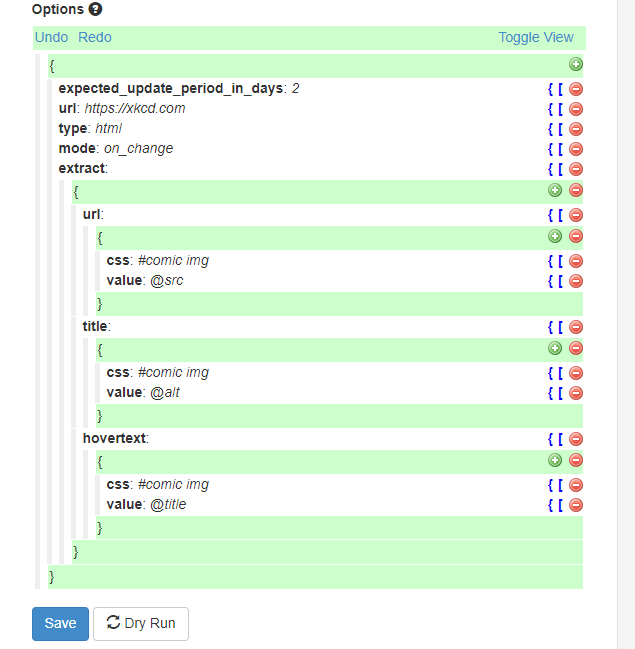
URL:监控链接
TYPE:返回的数据类型
支持文档类型
类型值可以是xml、html、json和text。
一般是html,如果你要检测的是RSS的变化的话,那就用XML
MODE:记录模式
如果是每次都要推送,all
如果是变化时再推送,on_change
extra:抓取规则
url和title表示抓取字段的名称,可随意命名;(后面用得着,作为参数传给其他Agent)
css表示抓取内容的css路径,value表示抓取的值,@href表示抓取对应css标签的href属性值,还有@src,@title等等;
如果要抓取对应标签的值,可填.(包括html代码的全部内容),string(.)(只包含对应标签的值),text()等同string(.)
填写方法
这部分如果不理解的话,可以查看它的七个默认实例,DryRun一下(不计入Events)
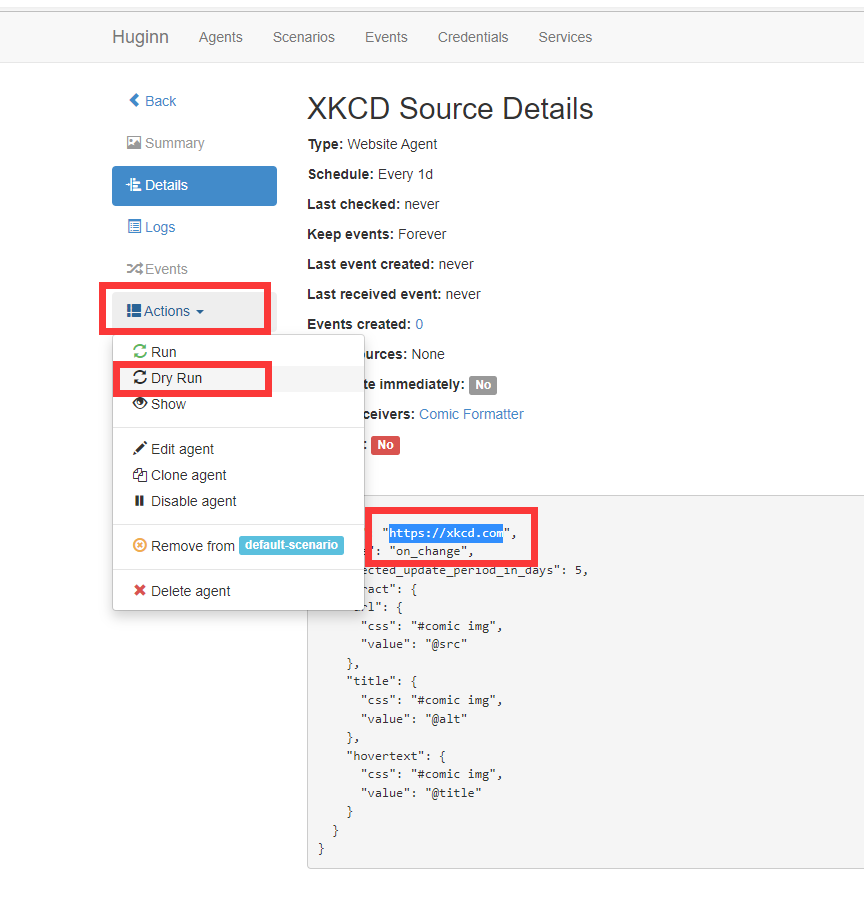
进入它上面的网页,去看看它是怎么运行的到这些数据的
{
"url": "https://xkcd.com",
"mode": "on_change",
"expected_update_period_in_days": 5,
"extract": {
"url": {
"css": "#comic img",
"value": "@src"
},
"title": {
"css": "#comic img",
"value": "@alt"
},
"hovertext": {
"css": "#comic img",
"value": "@title"
}
}
}
[
{
"url": "//imgs.xkcd.com/comics/sunshield.png",
"title": "Sunshield",
"hovertext": "RIP the surface of Mars"//这里是鼠标悬浮会看到的东西
}
]
打开浏览器的F12工具,查看你要爬取的数据位置的id或者是class
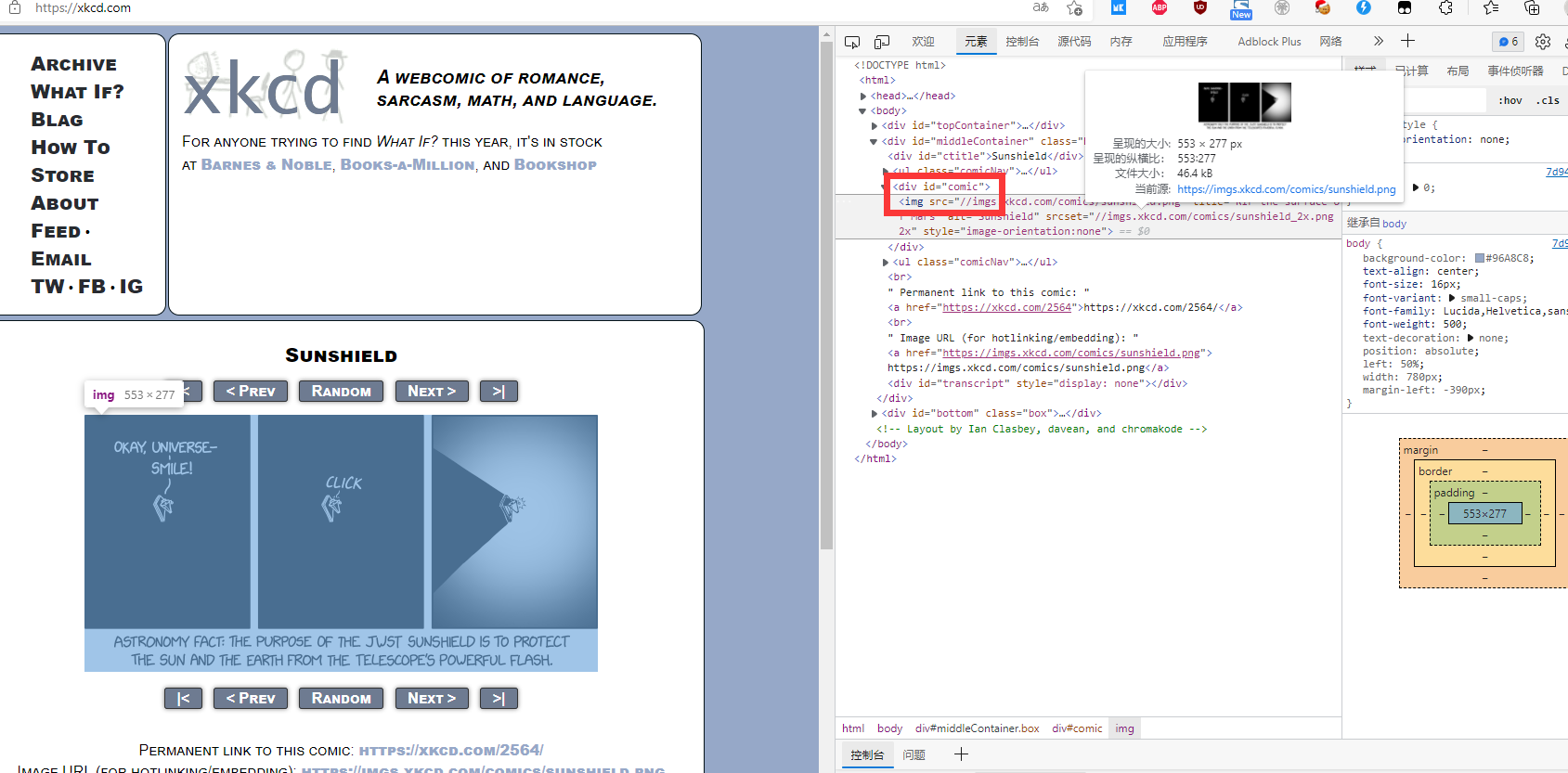
但是这种方法其实很麻烦,要自己寻找、自己填写,下面讲一种比较便捷的方法Xpath
提取Xpath
这里以我的博客为例
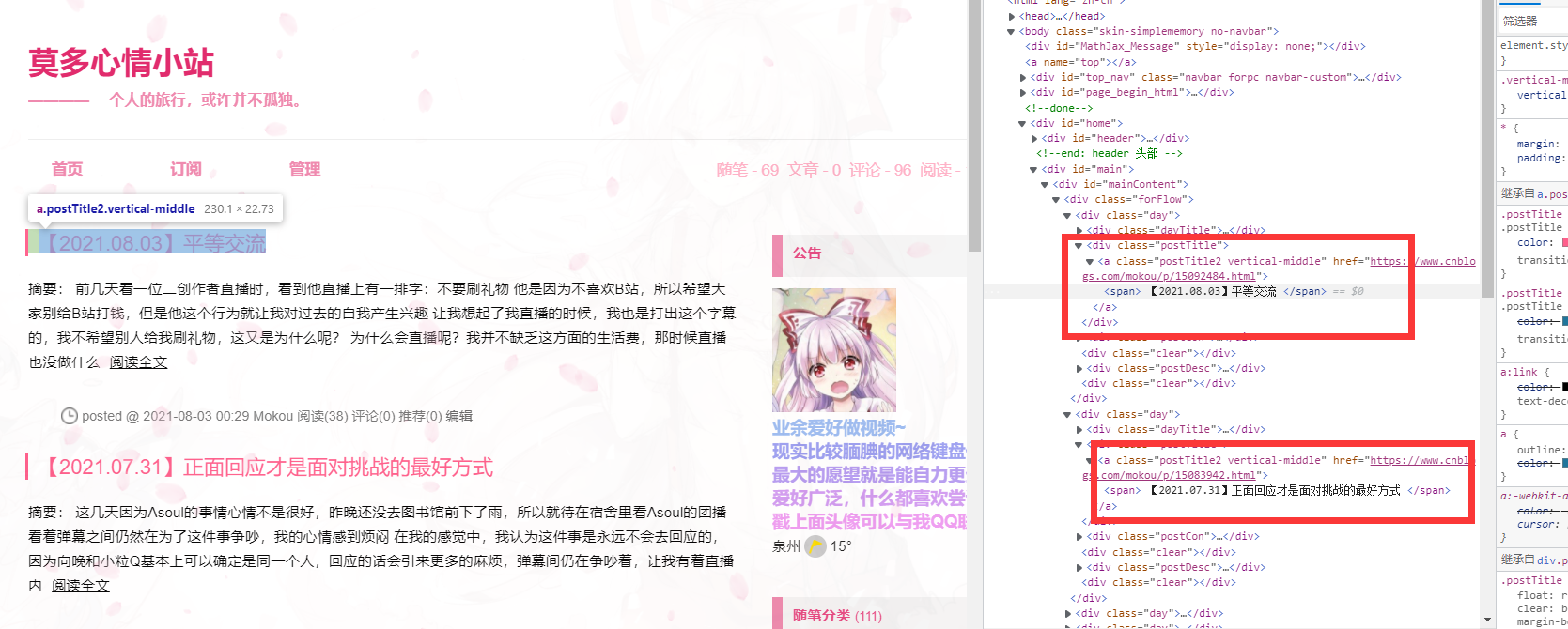
在这两个位置分别右键复制xpath得到两个不一样的xpath
//*[@id="mainContent"]/div/div[1]/div[2]/a
//*[@id="mainContent"]/div/div[2]/div[2]/a
所以想要得到页面中的所有标题,就要把两个合并为
//*[@id="mainContent"]/div/div/div[2]/a
因为url要返回的是链接,所以要在这个基础上加入<a>标签中的href
最终的xpath值为
//*[@id="mainContent"]/div/div/div[2]/a/@href
url的value中填入一个.就可以
title的xpath同理如上
//*[@id="mainContent"]/div/div/div[2]/a/span
title的值不在<>之中,所以value使用
string(.) 获得标签<>的文本
normalize-space(.) 这个在string(.)的基础上可以去掉空格
编辑好的Options如下
{
"expected_update_period_in_days": "2",
"url": "https://www.cnblogs.com/mokou/",
"type": "html",
"mode": "on_change",
"extract": {
"url": {
"xpath": "//*[@id=\"mainContent\"]/div/div/div[2]/a/@href",
"value": "."
},
"title": {
"xpath": "//*[@id=\"mainContent\"]/div/div/div[2]/a/span",
"value": "normalize-space(.)"
}
}
}
DryRun得到的结果如下
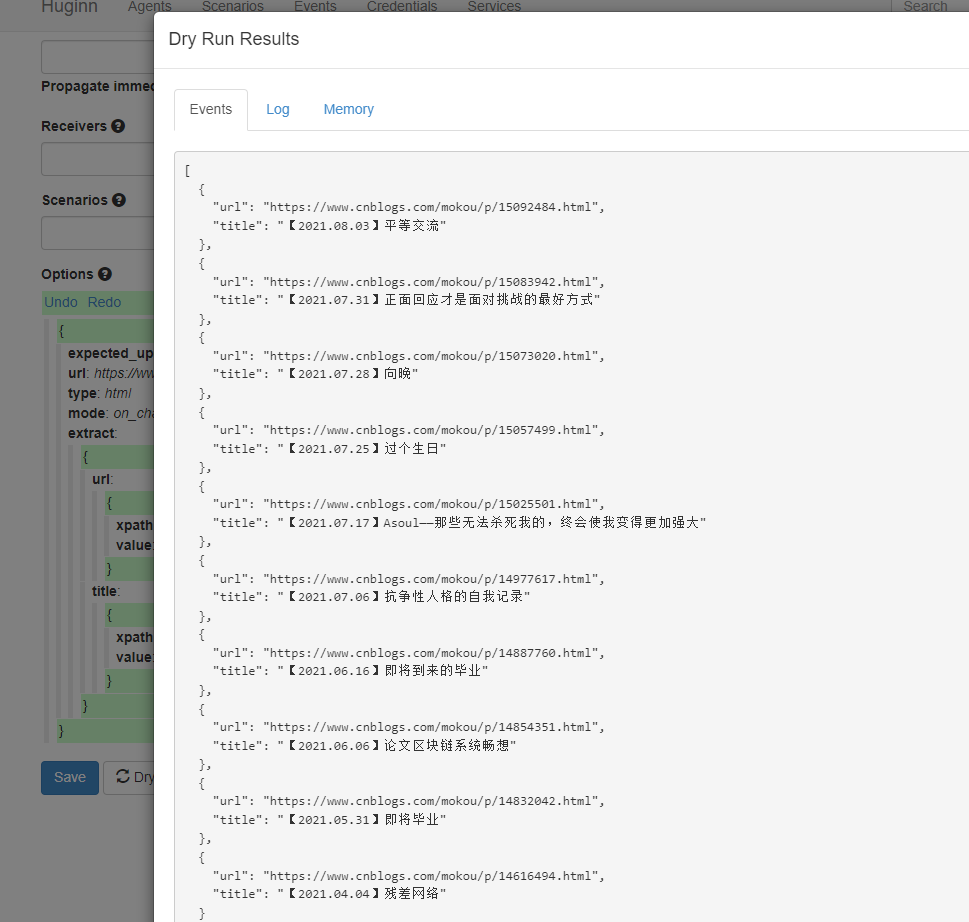
这样就得到我们想要的结果了
下一期做,怎么进行agents之间的传递数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号