【2021.03.04】使用卷积神经网络实现MNIST(下)
书接上文:【2021.03.03】使用卷积神经网络实现MNIST(上)
本次的学习来源:https://www.bilibili.com/video/BV1HK4y1s7j3
定义优化器
# 定义优化器
model = Digit().to(DEVICE)
optimizer = optim.Adam(model.parameters())
这里使用的是Adam优化器,用于更新模型的参数,使得训练测试得到的数值优化
定义训练函数
# 定义训练函数
def train_model(model,device,train_loader,optimizer,epoch):
# 模型训练
model.train() # 调用方法开始训练
for batch_index, (data,target) in enumerate(train_loader): # data是数据,target是标签,enumerate用于遍历
# 部署到DEVICE上去
data, target = data.to(device),target.to(device)
# 训练开始前,梯度初始化为0,准备开始预测
optimizer.zero_grad()
# 训练后的结果
output = model(data)
# 计算损失,这里使用的是交叉熵损失
loss = F.cross_entropy(output, target) # 传入交叉熵的是输出值和便签值
# 找到最大的概率值
pred = output.max(1,keepdim=True)
# 反向传播,拿预测值和标签值进行比较,目的是为了找到更好的权重值,使得损失函数的值得到尽量小
loss.backward()
# 参数优化更新
optimizer.step()
if batch_index % 3000 == 0: # 每三千个循环打印一个结果
print("Train Epoch :{} \t Loss :{:.6f}".format(epoch,loss.item())) # .item()是必须的,用于取出标量数值,
梯度下降:
梯度下降指的是损失函数的值下降,具体可以看:【2021.02.17】线性模型、梯度下降算法
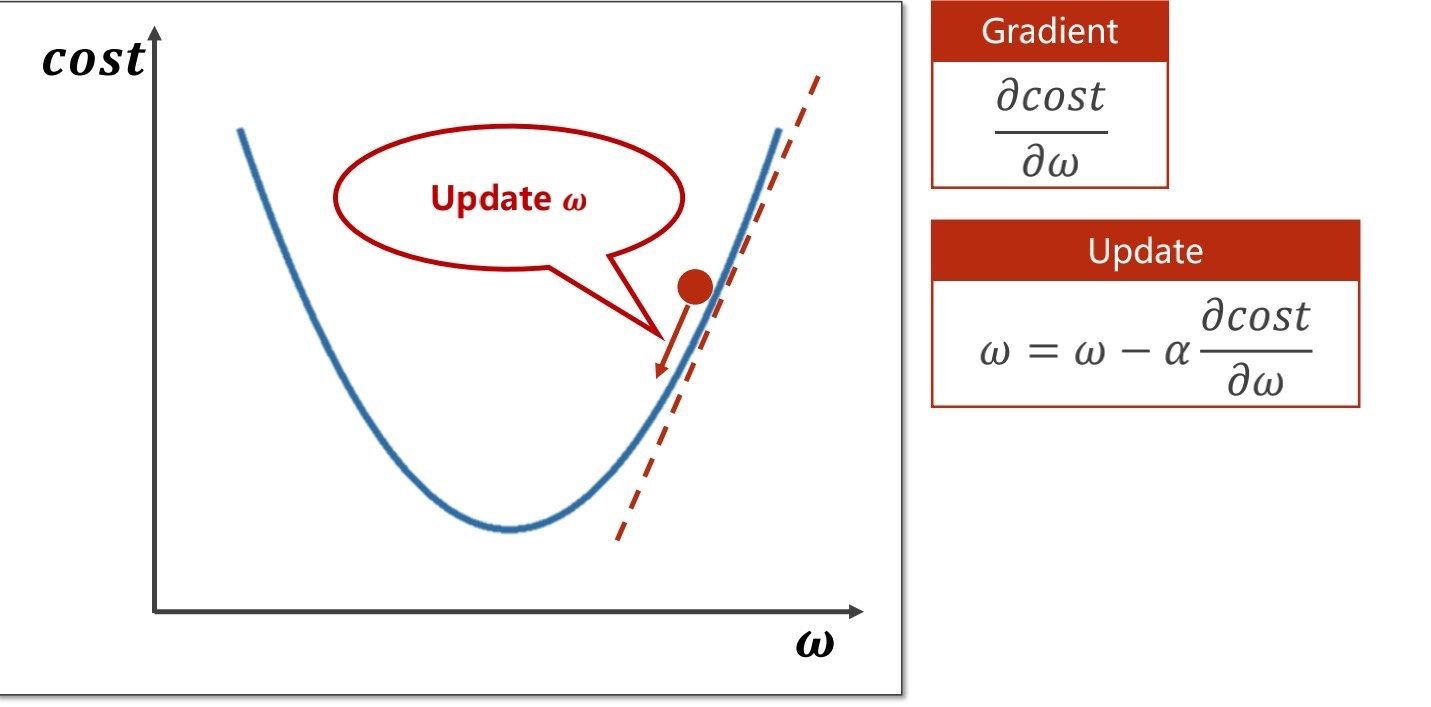
因此在每一次的训练开始前,梯度要初始化为0
enumerate()函数
函数语法:https://www.runoob.com/python/python-func-enumerate.html
enumerate(sequence, [start=0])
start默认为0,可以不传参
.item()
用于将张量Tensor提取出标量来,
计算损失的部分
loss = F.cross_entropy(output, target)
因为在这里不用打印/进行计算,所以这里可以不用使用.item()
(也可以在计算损失的时候使用该函数,这样子loss的定义就是一个标量而不是张量,在下面打印的时候就不用用到该函数
但是特别要注意的是,loss.backward()这里用到的loss是张量,标量是无法用来计算的反向传播的
因此在训练函数中,要输出时再使用.item()吧
定义测试方法
同理训练方法,不用考虑优化方法,要算出正确率值,损失值
# 定义测试方法
def test_model(model, device, test_loader):
# 模型验证
model.eval()
# 正确率
correct = 0.0
# 测试损失
test_loss = 0.0
with torch.no_grad():#已经拥有模型,不用计算梯度、反向传播,而是进行测试
for data, target in test_loader:
# 部署到device上
data, target = data.to(device),target.to(device)
# 测试数据
output = model(data)
# 计算测试损失
test_loss += F.cross_entropy(output, target).item() #得到的数据是张量,需要用item()提取出标量
# 找到概率值最大的下标
pred = output.max(1,keepdim=True)[1] #数据结构为值、索引,我们要获取的是下标,因此是[1]
# 其他写法
# pred=torch.max(output, dim=1)
# pred=output.argmax(dim=1)
#累计正确率,官方写法
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test -- Average loss :{:4f}, Accuracy : {:.3f}\n".format(test_loss,100.0 * correct/ len(test_loader.dataset)))
torch.no_grad()
这里是测试集,不用计算梯度,已经拥有模型,
不用考虑计算梯度、反向传播(这两个在训练集中的作用都是优化)
调用测试方法
每一次训练完后都进行一次测试
# 调用方法,输出结果
for epoch in range(1, EPOCHS + 1):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)
输出结果
随着轮数的增加,训练集的正确率在曲线上升,损失函数的值在不断趋近于0
测试集也没有出现过拟合的现象,损失函数值也在不断趋近于0


 浙公网安备 33010602011771号
浙公网安备 33010602011771号