【2021.02.24】加载数据集、多分类问题
本期的学习来源是:https://www.bilibili.com/video/BV1Y7411d7Ys?p=8
代码来源:https://blog.csdn.net/bit452/article/details/109680909
全部的数据都使用被称为batch,最大化利用向量计算的优势,以提升计算的速度
随机梯度下降只使用一个样本,可以帮我们克服鞍点,但训练时间较长
因此中和一下,综合两者的概念便被称为mini-batch
嵌套循环

外层表示训练次数,内层表示batch迭代
epoch:将样本进行一次正向传播和反向传播
batch-size:每次训练时候的样本数量
iteration:batch被分为多少个(内层循环次数
样本数量=batch-size * iteration
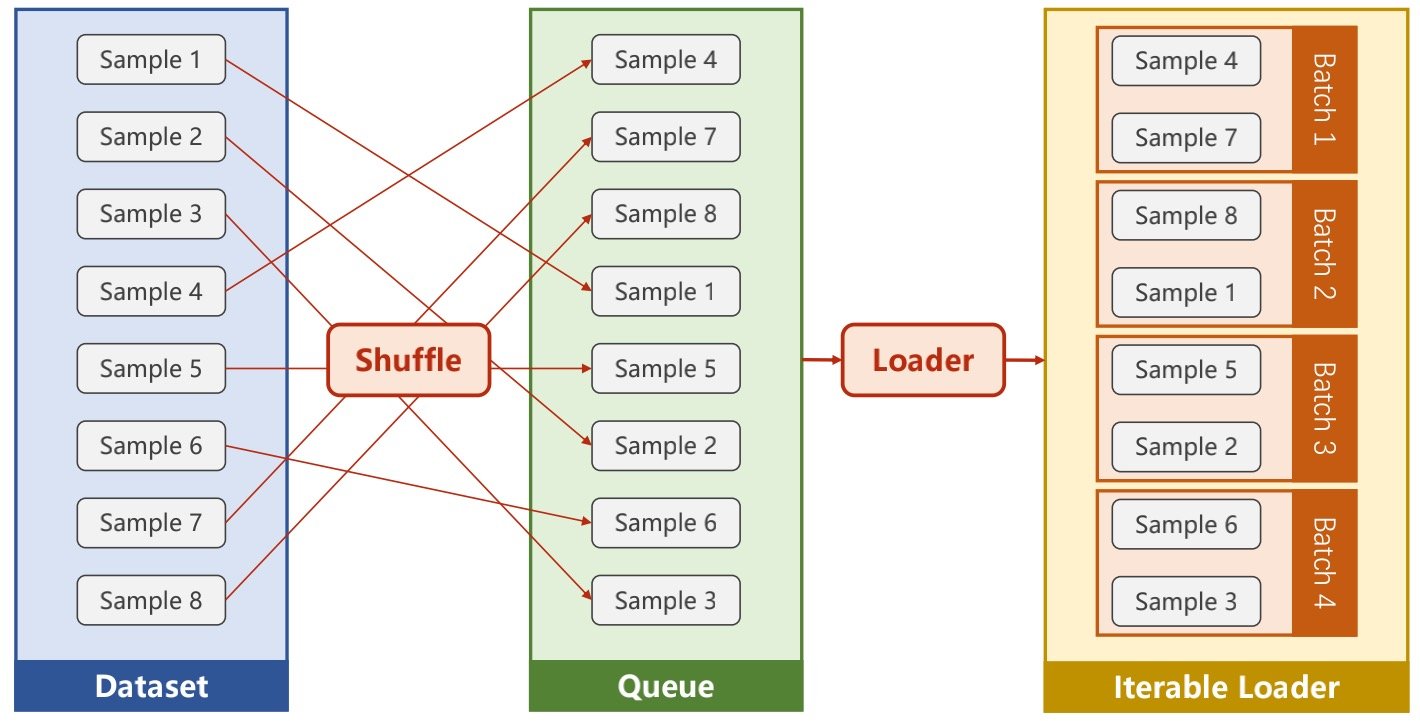
加载数据集
Shuffle:作用是打乱顺序
图中的batch-size=2,因此在最后打包的时候,两个分为一组
dataset是抽象类, 无法被实例化,只能被子类去继承
dataloader可以被实例化

Dataset的功能
在我们输入图像时,输出的结果如果也是图像,就很消耗内存
Dataset可以帮助我们节省内存
一、直接加载全部数据(适合小型,结构化的数据表
二、分步加载数据(适合无结构数据、图像、语音
Dataloader的功能
加载数据
传入参数有实例、batch-size、是否打乱、多线程参数
(在使用多线程的时候,Windows上使用spawn替代掉fork函数

例子

以上图为例
其中在__init__中的134条是加载数据相关,数据集是N行9列的数据,其中9列里8列是特征值。1列是标签
而第二行的.shape[0]的作用是提取出N来
因此我们在__len__中只需要返回len就可以得到样本数量了
__getitem__则是返回内存中的元组

多分类问题
结果只判断为“是/否”的为二分类问题
而多输出可以实现多分类问题,
将每个分类作为二分类,每个分类的概率是多少
(例如:y_hat1=0.9,y_hat2=0.8
这样的输出是不好的
最好的输出为所有分类的概率大于等于0,且所有的分类概率和为1
因此我们要加个softmax layer层
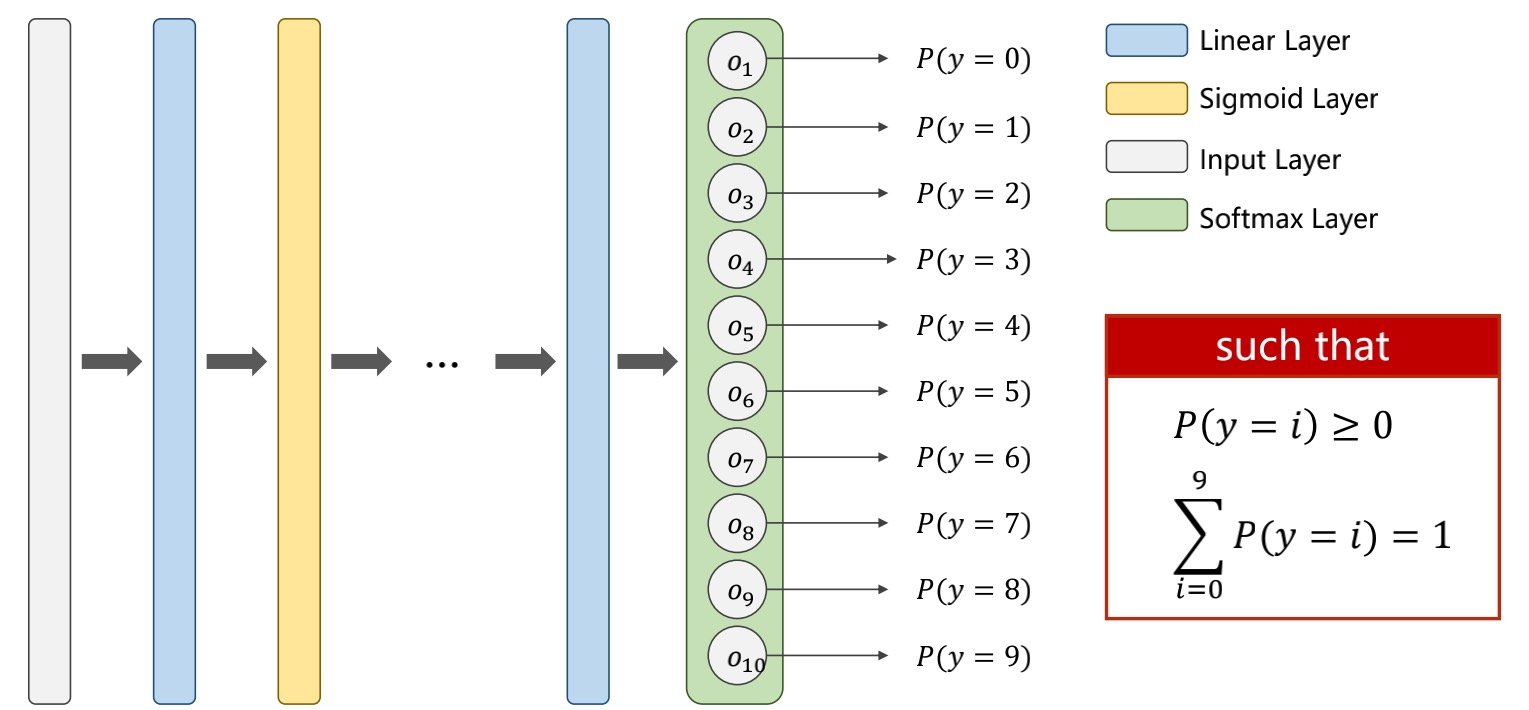
softmax layer层公式为
其中的
是为了保证概率大于等于0,当计算出来的z<0时候,带入上式子可>0

而在计算损失函数的时候,将结果导入
如果多分类问题有唯一解,则导入的结果中只有一个1(被称为one-hot
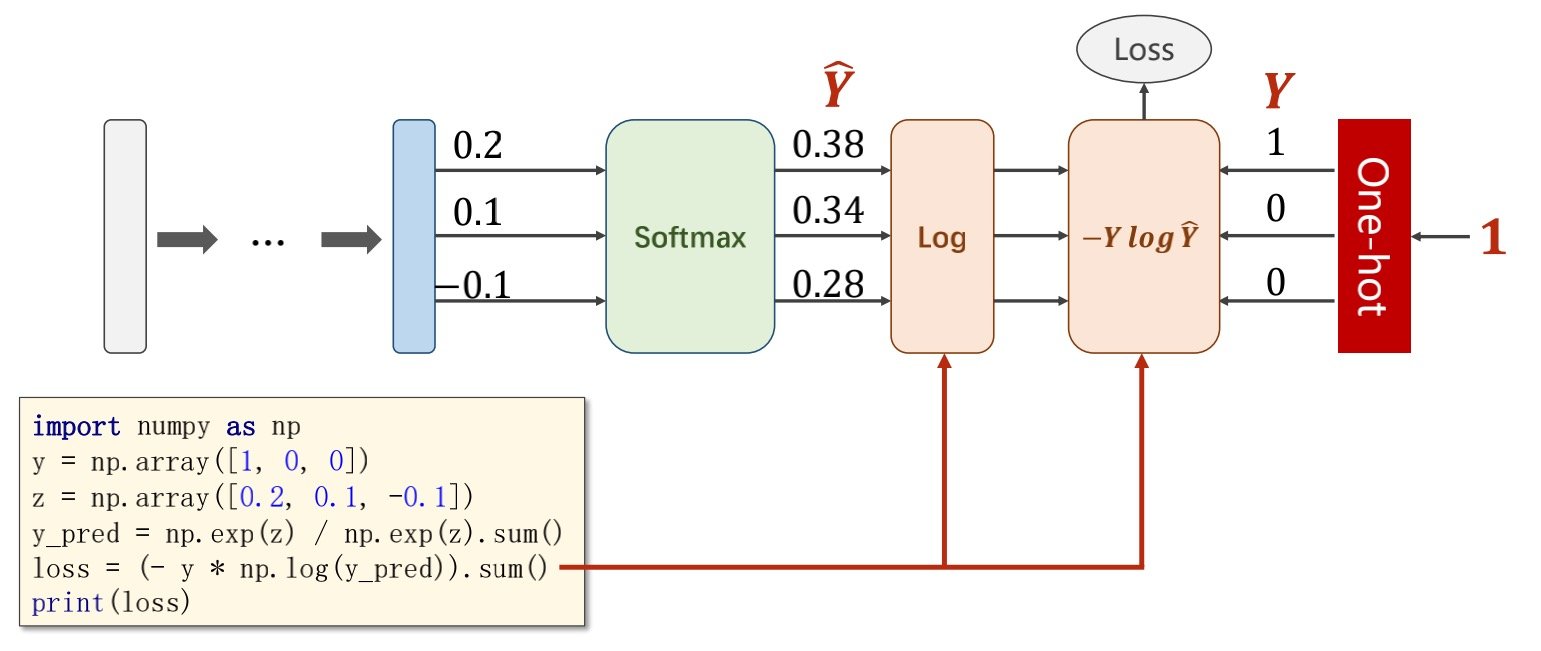
通过softmax layer的运算得到的结果与one-hot的值可以算出损失函数
相对吻合的结果,得到的交叉熵损失会较小,如下图

minist数据集
在做的时候可以将图像映射到[0,1]上

from torchvision import transforms
transform主要是进行图像的转换与映射
minist数据集这种单色图,我们称作为单通道图,而对RGB图像我们称为多通道图
读取图片时要使用W*H*C,宽x高x通道,或者如下图C*H*C
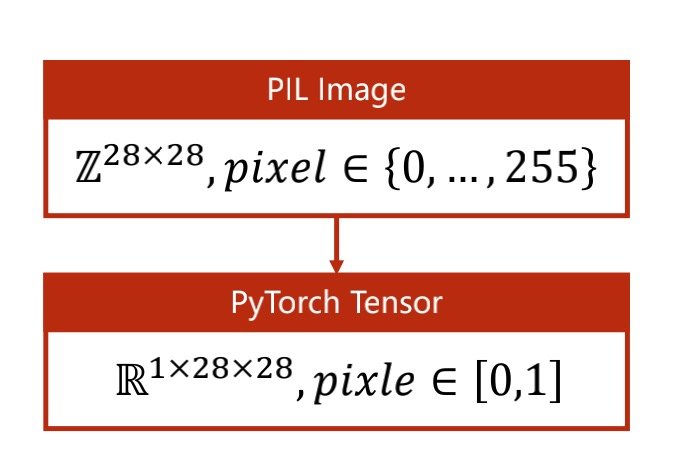
转换成[0,1]分布,最适合神经网络的学习
minist处理过程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号