

BeautifulSoup库(1)
信息组织与提取
信息标记:
- 标记后的信息可以形成信息组织结构,增加了信息维度
- 标记后的信息可用于通信、存储或展示的形式
- 标记的结构与信息一样具有重要价值
- 标记后的信息更有利于程序理解和运用
信息标记的三种形式
XML(扩展标记语言)

空元素的缩写形式:
![]()
注释书写形式:
![]()
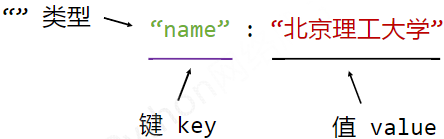
JSON
有类型的键值对key:value


YAML
无类型键值对 Key:value
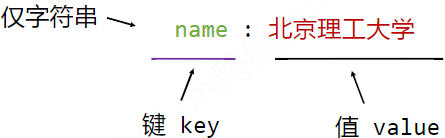
缩进表达所属关系

-表达并列关系

| 表达整块数据 #表示注释

三种信息标记形式的比较
XML:
-
- 最早的通用信息标记语言,可扩展性好,但繁琐
- Internet上的信息交互与传递
JSON:
-
- 信息有类型,适合程序处理(js),较XML简洁
- 移动应用云端和节点的信息通信,无注释
YAML:
-
- 信息无类型,文本信息比例最高,可读性好
- 各类系统的配置文件,有注释易读
信息提取的一般方法
方法一:完整解析信息的标记形式,再提取关键信息
- XML JSON YAML
- 需要标记解析器,例如:bs4库的标签树遍历
- 优点:信息解析准确
- 缺点:提取过程繁琐,速度慢
方法二:无视标记形式,直接搜索关键信息
- 搜索
- 对信息的文本查找函数即可
- 优点:提取过程简洁,速度较快
- 缺点:提取结果准确性与信息内容相关
融合方法:结合形式解析与搜索方法,提取关键信息
- XML JSON YAML 搜索
- 需要标记解析器及文本查找函数
实列
提取HTML中所有URL链接
思路:
- 搜索到所有<a>标签
- 解析<a>标签格式,提取href后的链接内容

1 import requests
2 from bs4 import BeautifulSoup
3 r = requests.get("http://python123.io/ws/demo.html")
4 demo = r.text
5 soup = BeautifulSoup(demo, "html.parser")
6 for link in soup.find_all('a'):
7 print(link.get('href'))
基于bs4库的HTML内容查找方法
<>.find_all(name, attrs, recursive, string, **kwargs)
返回一个列表类型,存储查找的结果
- name:对标签名称的检索字符串
1 import requests,re
2 from bs4 import BeautifulSoup
3 r = requests.get("http://python123.io/ws/demo.html")
4 demo = r.text
5 soup = BeautifulSoup(demo, "html.parser")
6 print(soup.find_all('a'))
7 print(soup.find_all(['a','b']))
8 print("=======================")
9 for tag in soup.find_all(True):
10 print(tag.name)
11 for tag in soup.find_all(re.compile('b')):
12 print(tag.name)
- attrs:对标签属性值的检索字符串,可标注属性检索\
1 import requests,re
2 from bs4 import BeautifulSoup
3 r = requests.get("http://python123.io/ws/demo.html")
4 demo = r.text
5 soup = BeautifulSoup(demo, "html.parser")
6 print(soup.find_all('p','course'))
7 print(soup.find_all(id = 'link1'))
8 print("==========================")
9 print(soup.find_all(id = 'link'))
10 print(soup.find_all(id = re.compile('link')))
- recursive:是否对子孙全部检索,默认True
1 import requests
2 from bs4 import BeautifulSoup
3 r = requests.get("http://python123.io/ws/demo.html")
4 demo = r.text
5 soup = BeautifulSoup(demo, "html.parser")
6 print(soup.find_all('a'))
7 print(soup.find_all('a', recursive = False))
- string:<>...</>中字符串区域的检索字符串
1 import requests,re
2 from bs4 import BeautifulSoup
3 r = requests.get("http://python123.io/ws/demo.html")
4 demo = r.text
5 soup = BeautifulSoup(demo, "html.parser")
6 print(soup.find_all(string = 'Basic Python'))
7 print(soup.find_all(string = re.compile('Python')))
| 方法 | 说明 |
| <>.find() | 搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.fing_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() | 在前面平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,同.find()参数 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通