First meet with Tensorflow(翻译原文因被作者下架,因此后续章节无法继续完善,而且目前 TF 已经升级,请谨慎参考)
首先申明,这是从一个老前辈那里翻译过来的,也未经过老前辈的允许,原因之一是因为我英语口语不怎么样,其二是我会尊重前辈的成果将原文链接贴在本文末尾。我认为前辈写这篇文章的目的就是为了让更多想在人工智能,机器学习,深度学习有所希冀的初学者,在 tensorflow 的使用学习上提供更多的帮助。而我也是这股洪流中的一员,我也希望本文能给上叙的那些还在找寻方向,想寻求帮助,认为这可能成一个帮助的人提供一些帮助。如果这篇文章涉及到侵权之类的问题,请尽快联系我,我会尽快删除。
我是重度拖延症者,以前的我都会抱有不完成工作不罢休的精神,但是不知实在高中还是初中被磨灭了,我现在变成了一个慢性子,这样非常不好,因为这样我原来一个月能学完的东西,现在需要两三个月。古人云一鼓作气,再而衰,三而竭尽。我希望看到这篇文章的读者能报有一鼓作气的心态。
原文是基于 tensorflow 0.6 python 2.7,在这篇翻译里,我将会将代码改成 tensorflow 1.1 python 3.2 的代码。
--- 好了不说废话了,以下是原作者译文 ---
我希望这篇文章能给这个世界的教育事业做些许的贡献,而且如果真的做到了,我会很高兴的。我认为,知识应该是自由的共享的,对于每一个人,我都希望他能无障碍的获取到他想要的只是。基于这个信念,这篇文章中的内容将在网页上完全自由免费的供求知者尽情的阅读,如果读者认为这里面的内容很有用,而且考虑到可以为作者辛勤的劳作做出适当的打赏,可以直接去原文链接第一段提供的三种途径给作者以适当的补偿,如果为翻译者打赏,可以跳至文尾扫描二维码即可。 [PROTAL]
在当今信息高速发展的时代,随着计算机,网络技术的飞速发展,以及大规模存储设备的出现,这给机器学的发展提供了巨大的推进作用,而机器学习在这些年也以爆发的姿态出现在了人们的面前,在如今我们日常生活中经历的事,触及的事物,都直接或者间接的受到机器学习的影响。如诸语音识别,图像分类,以及在我们的手机上使用的垃圾邮件分类,这些都在十年前,都只可能存在电影中,而如今真真实实的发生在了我们生变,变成了我们生活中的一部分。一些用于股票市场,医疗辅助中使用到的机器学习,对我们的社会产生了巨大的影响。另外在导弹巡航控制,无人机或者自动驾驶领域,人工智能在逐渐的显漏出锋芒,而且在将来这种影响也持续下去。
2006 年以来,深度学习,作为机器学习的一个子分支,无疑是在机器学习领域取得巨大突破与进步的技术之一。而实际上在硅谷,不仅仅是像 google, macrosoft, IBM 这样的大公司拥有这方面的研究团队,而且也涌现了很多专于一个领域的初创公司。同时机器学习也在学校,研究所之外受到了巨大的关注,很多专业的杂志(如:Wired)和周刊日刊(如:New York Time, Bloomberg)撰写了很多关于机器学习方面的报道。
这些报道,引导了更多的学生,企业家和投资者加入到深度学习的行业中,它之所以能激起从业者如此大的兴趣,当然也离不开几个优秀的开元平台(theano, torch, caffe, tensorflow)。我们作为在 2012 年 Berkeley 开发 caffe 推动者(博士生),我可以说,这个在这本书中被提及的,google 2013 年开源的 Tensorflow 这个工具,将会成为研究人员,中小企业用来开发深度学习和机器学习的主要工具之一。之所以我敢做出这样的断言是因为它是由如此多优秀的工程师和顶尖研究员开发的,而且最终要的是它是开源的。
我希望这篇介绍 Tensorflow 的 book 可以帮助读者有兴趣在这个如此诱人的领域开始他们的冒险。我也想感谢作者为 Tensorflow 这项技术的传播作出的努力。作者以创纪录的速度,在发布了 Tensorflow 的两个月后发布了第一个版本(西班牙语),这一个充满 Barcelona 生命的激情,以及誓与成为推动这一技术其中一员的一腔热血所铸就的这篇文章,毫无疑问将会影响到我们的未来。
--> Oriol Vinyals, Research Scientist at Google Brain
模式识别是深度学习的常见应用之一。因此,和你学习其他程序一开始要实现 'hello world!' 一样,深度学习,我们一开始先学习手写识别(handwrite),在接下来我介绍的第一个神经网络的例子的时候,我将介绍这样 tensorflow 这门技术。
不过,我不打算写一本关于深度学习或者机器学习的书,我只是想介绍这个比较新的深度学习工具—— tensorflow。所以,对那些想从这本书中的到更多更深层次只是的人(数据分析师或研究者)致以我诚挚的歉意。
你在这里,能看到我经常在上课的时候讲的一些常规的学习方法,当你们学习的时候,我肯请你们把你们的手放在键盘上,转动你们的脑子,让你的思维跟代码一起擦出火花。师傅领进门,修行靠个人,我成为一名 UPC 的教授的经历告诉我,如果你想学习一门新的知识,开拓一片新的领域,一边学习,一边将之变成实实在在的东西,这是达到你目标的一个不错的方法。
因此,这本书也会很简单,不会涉及到过多的数学知识,我也尽量多的避免提到比较复杂的东西。然而在代码中不可避免的会涉及到一些浅显的数学知识,这是必要的,不过我相信读者还是能够 hand with that!
我猜测,来看这本书的人应该对机器学习也有一些基本的了解,因此我也会在学习 Tensorflow 的过程中引用一些流行的例子。
在第一章,我们除了介绍 Tensorflow 将会使用的场景外,我将会借此顺便介绍一下 Tensorflow 编程的基本结构,以及简单的介绍一下内部的数据组织方式。
第二章,通过 linear regression,我将实现一些基本代码,同时,也会介绍如何去调用实现一些机器学习中一些重要的组成部分,如 cost function 或者 gradient descent optimization algorithm。
第三章,我们将实现一个聚类(clustering)算法,同时也将详细的介绍 tensorflow 中的一些基本数据结构—— tensor(张量),以及一些不一样的用于创建管理 tensor 的函数,
第四章,我们将详细的实现单层的神经网络去识别手写字母,这里我们将会用到上叙几章中的各种只是,而且我们也会看到 create 一个测试模型需要的整个流程。
在接下来的一章则会详细的介绍在前一章介绍的 neural network 的概念和定义,同时,也会介绍如何组建一个多层神经网络,使得我们能在手写识别的这个案例上获得更好的结果。也会展示更多关于 CNN(卷积神经网络)的更多信息。
在第六章,我们将会看到更特殊的例子,也许这个例子并不会让每一个读者都感兴趣(利用 GPU 的运算能力,加速算法的 trainning 过程)。就想第一章所说的,GPU 在神经网络的训练过程中起了重要的作用。
最后我就是这本书的闭幕词了,我将在这里强调一些结论。
最后本书的示例代码可以从本书的 github 仓库中下载。(作者仓库中的是过去的 tensorflow 版本,可能存在一些问题,如果需要请访问[PORTAL1])
- [PROTAL1]本书参考代码。
在本章,我将简明的介绍如何使用 tensorflow 实现一个简短的程序,以及什么是 tensorflow 的模块。在本章结束,我希望读者们能独立的安装 tensorflow 开发框架到你的个人电脑上。
机器学习已经存在学术机构中有几十年的时间了,但知道最近几年才开始较多的出现在公司中。这得益于大规模存储的实现以及如今史无前例的计算资源的发展。在这种情形下,google ,这个 alphabet 的子公司无疑成为了,将 Machain Learning 应用到虚拟领域,数字产品中的最大玩家,
2015 年十月份,当 alphabet 宣布他们的季度业绩中显示,考虑到销售和利润的增长。CEO Sundar Pichi 说的很清楚:“机器学习是我们的核心,他所带来的变革,让我们重新审视我们所作的任何事情。”
从技术上来说,我们在新的纪元里面对的挑战并不是 google 是最大的玩家,在机器学习领域。另外一些技术公司,诸如 Macrosoft, Facebook, Amazon, Apple,还有更多的其他的科技公司正在这个领域持续的增加投入。在这种形式下,几个月前(其实已经过去一年多了),google release 了 tensorflow 这个工具,他遵循 Apache 2.0 证书协议。TensorFlow 适用于那些想在机器学习领域内工作学习的开发者或者研究者,与此同时,google 也将 ML 用到了他们自家的一些不同的产品上,如:gmail, Google photos, Search, Voice Recognition ...
TensorFlow 原来是由 Google Brain 团队开发出来的,其目的是用之进行如今最流行的技术(DL)的研究,但是这个工具慢慢的变得如此的通用,以至于几乎能用于开发我们能见到的不同的机器学习算法。
既然我是一名工程师,而且我将对同样是工程师的你们介绍 TensorFlow, 我将借助数据流图更加直观的展示算法是如何运行的。TensorFlow 可以被看作是使用数据流图进行运算的库。FlowGraph 中的节点即代表一个数学操作,图形边沿则表示互相连接的多维数据张量(矩阵,多维数组)。
TensorFlow 是围绕这构建和操作计算 FlowGraph 来工作的,以符号的形式表现运算过程中的动作。这也使得 TensorFlow 可以方便的获得各个平台中的 CPU GPU 的资源,如:Mac OS, Linux, 或者某些手机平台 Android,IOS.
另一个强有力的工具是 TensorBoard,它可用于告诉你在运行算法的时候,内部数据是符如何产生作用的。能够测量和现实算法的行为,这在用于创建一个优秀的模型是大有裨益的。我有一种感觉,目前我们通过盲测来提升算法的性能,实际上是在大大浪费我们的时间。
去年 Google 又发布了一款产品 —— Tensorflow Serving, 这可以让开发者将他们的 TensorFlow ML model (或者其他 server 的 model) 更好的服务与他们的产品,TensorFlow Serving 是一个开源的服务系统,可以在 GitHub 上获取到它的源码,它支持 Apache 2.0.
TF 与 TFS 有什么差异的地方勒?我是这么理解的,TF 是一个学习和研究的工具,不太好集成到产品上,可能跟适合用在开发的过程中,而 TFS 恰恰提供了更加方便的借口可继承到产品中,开发者可以在 TF 上进行学习研究,训练模型,待到模型成熟之后可以移植到 TFS 上,TFS 提供了 API 来获取客户端的输入数据,和输出运算的结果给客户端。这也可以让开发人员根据现实生活中的数据,大规模的尝试随时间变化的不同模型,并且还可以保持稳定的架构和 API。
一个常见的流程是,训练数据不被送至 learner,然后输出一个模型,被验证可用之后,即可把训练好的模型部署到 TFS 上,当新的数据可用是,或者当你需要更新模型时,这是一个相当通用,持续的迭代的方法。事实上,在 google 内部的帖子里提到,随着新的数据变得可用,许多流程会持续的生成适应新环境的模型。许多开发人员通常会利用 gRPC(这是一个来自 Google 的高性能开源 RPC 框架)与 TFS 通信。
如果你有兴趣去学习 TFS,我建议你阅读 TFS 的官方文档,开始搭建你的 TFS 环境,和开始一些简单的入门训练。
是时候动一下手了,下面我们将介绍 Tensorflow 的安装,我希望你能跟着这个教程一步一步的在你自己的 PC 上完成。
首先我们将要安装的是 python 版本,而不是 C++ 版本,而且,这篇翻译的也和原文的有所出入,原作者介绍安装的是 2.7 的版本,而现在的 tensorflow 已经支持 3.0 了,我们要与时俱进,需要注意的是,按照以下步骤,你可能安装的是 python2.7,因此最好安装 tensorflow 之前先看一下你的 python 版本(运行以下代码可以依次打印 python 和 pip 的版本 python -V; pip -V )。一般地说,当你在 python 上进行开发事,我建议你们用 virtualenv 这个工具,这个工具可以保证 Python 工程的独立性,它可以更具不同的工程配置不同的环境,即使工程之间的依赖可能会有冲突,因为 virtualenv 的机制的原因,各个工程之间也不会受到影响。具体 virtualenv 是怎么实现的,请上网查查,百度也好,Google 也好,这些资料还是很全面的。原书中推荐的只是用 virtualenv,但是我在这里还推荐一个比 virtualenv 更好用的工具(virtualenvwrapper),这个工具是在 virtualenv 的基础上开发来的,但易用性比 virtualenv 更高。具体安装我不会在这里提及,如果想了解的可以参考[PROTAL1].
你在安装 python 的时候,pip 和 virtualenv 是不会自动安装的,因此第一件事你应该先安装这两个工具,具体安装步骤请 Follow next:
# Ubuntu/Linux 64-bit
$ sudo apt-get install python-pip python-dev python-virtualenv
初始化一个 virtualenv 环境在 ~/.tensorflow 目录:
virtualenv --system-site-packages ~/tensorflow
接下来,激活这个环境:
$ source ~/tensorflow/bin/activate # with bash
$ source ~/tensorflow/bin/activate.csh # with csh
(tensorflow)$
初始化一个 virtualenv 环境在 ~/.tensorflow 目录:
virtualenv --system-site-packages ~/tensorflow
接下来,激活这个环境:
$ source ~/tensorflow/bin/activate # with bash
$ source ~/tensorflow/bin/activate.csh # with csh
(tensorflow)$
一旦你想要激活的 virtualenv 环境的名字出现在命令行前,这说明这个环境已经被你激活,接下来你就可以安装 tensorflow 了,你可以参照以下步骤,也可以查看官网的推荐步骤([PROTAL2]):
pip install --upgrade tensorflow
如果你想将你的程序运行在 GPU 上,那么安装的方式可能有些不同。我建议你访问官方文档,去看一下,如果你想安装使用 GPU 版本的 Tensorflow 那么你需要执行那些操作。( 目前似乎不存在版本区分了,但为了尊重作者的成果,还是保留作者本段的翻译 )
退出 virtualenv 的环境:
(tensorflow)$ deactivate
Tensorflow 的更新是很快的,至少在目前看来(2017-5以前),因此,为了获得更新,更加准确的信息,建议访问 TensorFlow 的官网,但似乎 GFW 将该网站屏蔽了,因此你可能需要借助一下 VPN,或者代理之类的。(如果不知道如何FQ,或者想和我合租代理服务的话可以联系我)。
就像我一开始就提到的,我们将会一边介绍 TensorFlow 的使用,一边真正的上机操练。让我们开始吧!
从现在开始,无论你用什么编辑器(vim, atom ...),最好把代码所在的文件名的后缀设置成 .py (如:filename.py),这被默认是 python 的脚本文件,也能让别人一看就懂。如果你想运行这个脚本,执行 python filename.py 就可以了。
让我们看一下,TensorFlow 的代码长什么样子。我建议你实际操作一下下面这段代码:
import tensorflow as tf
a = tf.placeholder('float')
b = tf.placeholder('float')
y = tf.multiply( a, b )
sess = tf.Session()
print( sess.run(y, feed_dict={a:3,b:3}) )
在这代码中,我们首先将 tensorflow 的库倒入进来,然后我们定义了两个 placeholder (符号变量,Tensorflow 中特有的变量类型),一边后面执行程序的时候调用他们。然后我们将这两个 placeholder 用 Tensorflow 提供的乘法函数 tf.mutiply (TensorFlow 提供的众多运算工具之一,具体 TensorFlow 还提供什么其他的数学运算工具,请参考本章后的参考资料 [PROTAL3] [PROTAL4])来构建运算单元。接下来这一步比较重要,所以我必须换一行来说。
在 TensorFlow 中,运算必须跑在 Session 中,因此我们需要用 tf.Session() 来创建一个 Session,需要注意的是,至此,我们还没有执行任何数值上的运算。让我载重新申明 TensorFlow 中组建机器学习算法和执行它被分成两个部分,而上面是一个能简单但又直观体现这一理念的一个例子。
TensorFlow 的程序通过 Session 与库进行交互,直到 tf.Session 我们仅仅只是申明它,到我们调用 sess.run() 的时候才会创建这个 Session 对象,并执行传递进去的算法及参数。当我们调用 run 开始执行程序,计算 a b 的积时,变量值被通过一个 feed_dict 的参数被引入 run() 中。
在我们开始解决一个完整的机器学习代码之前,我是希望能借这个小的示例程序,来介绍通常用在 Tensorflow 解决问题时的常用过程,最终创建一个 session 去运行关联各个参数,以及运算。
有时候,我们希望能有一个更加灵活的方法来构建我们的代码,使用一些方法来图形化各个运算节点。例如,当我们使用 python 编译环境的时候(像 IPython),为了达到我们的目的,TF 提供了一个叫的 tf.InteractiveSession() 类。这个程序模型的内部运行机制已经超出了本书的范畴。然而,为了我们能顺利的进行下面的学习,我们需要知道的是,TF 将所有的信息保存在了能包含所有信息的图形结构中。该图描述了数学计算的过程。图中的节点代表数学的运算,或者数据的读,写,输入,输出。而节点与节点之间的边则代表了 tensor(TF 的基本数据结构) 与 tensor 之间的关系,以图的方式,可以方便的展示信息之间的业务逻辑,和让我们理解在当各个 operation 在 Tensor 上并行可分时,TF 是如何异步的将 operation 分配给分布式单元的。
因此,并行性,是一个能够加快执行昂贵的计算算法的一个因素。而且 TF 也实现(优化)了一些复杂的操作,大多数的这些操作都实现了内核层面优化(比如利用 GPU 或者 TPU 来加速运算)。下面介绍一些提供内核加速的接口 。
| Operations groups | Operations |
|---|---|
| Maths | Add, Sub, Mul, Div, Exp, Log, Greater, Less, Equal |
| Array | Concat, Slice, Split, Constant, Rank, Shape, Shuffle |
| Matrix | Matmul, MatrixInverse, MatrixDeterminant |
| Neuronal Network | SoftMax, Sigmoid, ReLU, Convolution 2D, Maxpool |
| Checkpoint | Save, Restore |
| Queus and syncronizations | Enqueue, Dequeue, MutexAcquire, MutexRelease |
| Flow Control | Merge, Switch, Enter, Leave, NextIteration |
为了了解更多更全面的了解 TF,TF 提供了一个可以图形化算法的工具,用来调试优化你的算法程序 —— TensorBoard。TB 可以查看不同类型的统计数据,包括参数,和图形化计算过程中任何部分的细节。
TB 用于展示的数据,是在算法的执行过程中将需要跟踪的数据记录下来,并存储到跟踪的 log 文件中。参考 [PROTAL5] 你将发现 TB Python API 的更多信息。。
如果你现在马上想看看如何调用 TB,非常简单,TF 在命令行提供了一个名为 tensorboard 的工具,你输入以下命令,即可打开 TB Server.
(tensorflow)$ tensorboard --logdir=<trace file>
不出意外的话,你仅仅需要在浏览器中访问:http://127.0.0.1:6006 就可查看到 TB 的展示界面。
TB 这个工具其实已经超出了本书的讨论范围,关于使用 TB 的更多的信息,请参考 TF 的官方 tutorial。
在这章,我将会用 LR(Linear Regression), 一个简单的例子带大家探索 TF 是如何编程的。基于这个例子,我们将介绍 TF 中的一些简单的代码,同时,也会选择实现机器学习中常见的一些重要组成部分。如:cost function( 损失函数 ), gradient descent( 梯度下降 )。
LR 是一种用数理统计的方法去计算数值之间关系的一种技术,比较让人感到意外的是,这种算法并不难实现,但是它却可以解决各种各样的情况。因为这些原因,我选择用 LR 来开始入手 TF。注意,在两个自变量或者多个变量的情况下,LR 的模型是描述独立变量(Xi)和偏执项(b)与因变量(Y)之间的关系。
在这里,我们创建一个示例来解释 TF 是如何工作的。假设我们的数据模型对应于一个一元一次方程(Y = W*X + b)。为此我将使用几行简单的 python 程序,在二维空间中随机生成分布在上叙一元一次方程附近的点,然后用 TF 去拟合这些点所对应的线性模型。
第一件我们要做的事是导入 Numpy 库到当前的代码空间中,我们将用这个库来生成那些随机点。代码长的像下面这样:
import numpy as np
num_point = 1000
vectors_set = []
for i in range( num_points ):
x1 = np.random.normal( 0.0, 0.55 )
y1= x1 * 0.1 + 0.3 + np.random.normal( 0.0, 0.03 )
vectors_set.append( [x1, y1] )
x_data = [v[0] for v in vectors_set]
y_data = [v[1] for v in vectors_set]
如你所看到的,我们生成了 1000 个遵从公式 Y = 0.1 * x + 0.3 的 sample,尽管我们用引入了一些服从正态分布的一些噪声,有一些点可能并不在公式所对应的那条线上,但这样却更合乎我们在实际环境中遇到的情况。
接下来为了更加直观的观察到 sample 在二维空间的分布情况,我们可以用 matploylib 这个 python 的图形工具库来绘制 sample 的分布图。用法有点类似 matlab 和 ocatve 里面的 plot,有兴趣的同学可以看一下参考文档。绘制坐标图的代码长的像下面这样:
import matplotlib.pyplot as plt
plt.plot( x_data, y_data, 'ro', lable='Original data' )
plt.legend()
plt.show()
你生成的图片长得应该像下面这样,这些 sample point 将会是我们用于训练 LR 模型的数据:(可能会不一样,毕竟引入的随机噪声将会不一样)
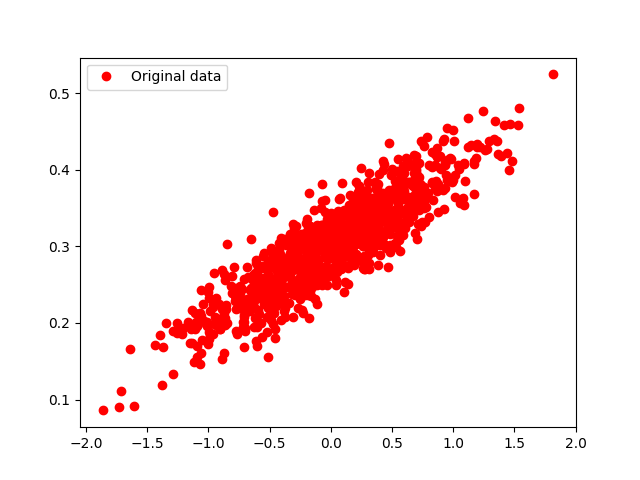
下一步,我们将训练一个 LR 的学习算法,可以更具 x 得到一个服从 y 分布的结果,根据我们前面的介绍,我们已经知道这是一个线性模型,我们可以用两个参数 W 和 b 来表示这个模型。
我们的目的是需要 TF 的代码能自动的发现 W 和 b 最好的参数,虽然我们你知道 W 是 0.1 而 b 是 0.3,但是 TF 是并不知道的,它必须自己意识 W, b 应该接近与这两个值。(经过 Train 学习到)
一个解决这个问题的通用的做法就是,循环改变 W 和 b 的值,然后得到一个比较精准的值,但是我们怎么知道我们已经得到了最好的 W 和 b 了勒?此时我们就需要顶个以一个 cost function 也叫损失函数,有叫代价函数,这个函数会将模型的预测结果和实际 sample 的结果相比较,然后计算出两个结果的差异程度,看当前的模型有多好(实际上是多差)。在这个例子中,我们可以计算预测值和实际值之间的均方差来作为 RL 的 cost function。比较每一次迭代后总的样本点的均方差,我们也可以得到我们训练的模型是在变好,还是在变坏。于是我们便可以做出相应的对策来改进 W 和 b 的值。
<接下来,我将会看一些具体的例子,了解更多关于 cost function,以及其变体的知识。下面我们申明三个变量:
W = tf.Variable( tf.random_uniform([1],-1.0,1.0) )
b = tf.Variable( tf.zeros([1]) )
y = W * x_data + b
回顾之前的内容,调用 tf.Variable 函数可以定义 TF 内部表示图形化的数据结构变量(internal graph data struct)。接下来几章我将会讨论更多的关于这个函数的内容,但现在我认为最好先完成我们的第一个任务。
接下来,我们计算实际点到 W 和 b 参数组成的模型所预测的点的平均距离平方,代码如下:
loss = tf.reduce_mean( tf.square( y - y_data ) )
如我们所见,y_data 是我们在前一小节中创造出来的实际数据,而 y 是我们由 x_data 经过 W 和 b 两个参数所组成的线性方程计算出来的。到这时我想读者以及可以猜出来了,为了获得最好的模型,我们需要吧 loss 这个数值变得尽可能的小。
关于我们的 grandient descent 算法,目前没有什么可以详细说明的,我可以告诉大家的是,它可以帮住我们对 W, b 调优,以使得 loss 尽可能的小(如果迭代次数够的话)。如果从理论层面分析,大概用的就是利用函数的一阶导数,和而阶导数求函数的最值,我相信大家也能在网上找到一大堆关于这方面知识的资料。我们之所以要对误差求平方正是因为这样能保证数值都为正,而且可导。换而言之就是我们能方便的利用 gradient descent 找到最小值。
在 TF 中,我们可以用下面的例子来对我们上叙的参数进行优化:
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize( loss )
至此,这样足可以让 TF 在内部创建 train 所需的参数了,而且也实现了 gradient descent 针对 loss 的迭代优化的过程。至于创建的这些内部结构和过程是 TF 内部的工作,这可以通过 TensorBoard 看到,如果想更加细致的了解,恐怕我只能推荐你看源码了。接下来我们将讨论成为 gredient descent 学习速率的参数。(我们代码里是 0.5)
如我们前面所看到的,我们目前调用 TF 的库所实现的代码只是加载相应的信息到 TF 的 internal graph 中,而且程序执行到此处也没有运行优化算法。因此,我们需要像我们前一章做的一样,需要创建一个 Session,然后运行 Session.run 来训练我们的参数。而且因为我们的代码带有 TF 库中的变量,因此我们需要先初始化这些特殊的变量。
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
现在,我们可以开始迭代,执行这个过程,我们将会找到一个两个(b,W)比较合适的值,这两个参数所组成的模型预测出值将会在我们期望的精度之内。在我们的例子中,如果我们想迭代 8 次,那么这可以写成:
for step in range(8):
print( step, sess.run(loss), sess.run(W), sess.run(b) )
sess.run( train )
// 运行后终端的输出
1 0.0325059 [-0.21684313] [ 0.29495162]
2 0.0160418 [-0.11820275] [ 0.29633981]
3 0.00816312 [-0.04996698] [ 0.2973296]
4 0.00439282 [-0.00276373] [ 0.29801431]
5 0.00258858 [ 0.02988992] [ 0.29848796]
6 0.00172517 [ 0.05247864] [ 0.29881561]
7 0.001312 [ 0.06810477] [ 0.29904228]
8 0.00111427 [ 0.07891442] [ 0.29919907]
9 0.00101966 [ 0.08639217] [ 0.29930755]
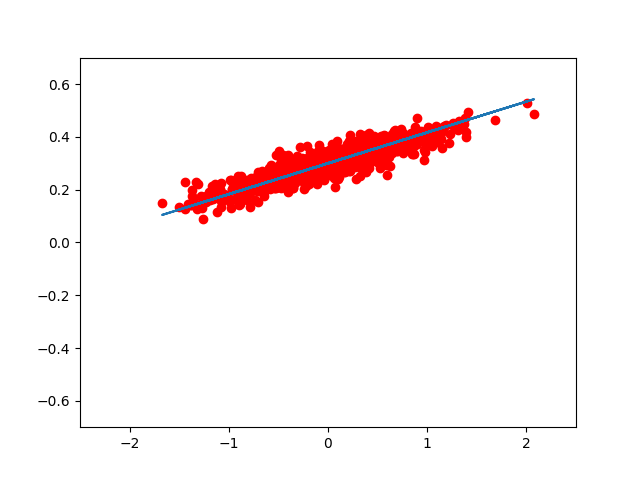
在运行完这几行代码之后,我们将得到近似于我们之前预设的一对值,需要注意的是,因为 train 的数据和 W,b 初始化时候的值在每个人的电脑上都是不一样的,你们的值与我的值之间可能有细微的差别,但总的来,W 不会和 0.01 差太远,而 b 不会和 0,3 差太远。而在这里代码运行了 8 次之后 W 的值为 0.08639217, b 的值为 0.29930755, 已经很接近目标值了。而且可以观察到,每一次迭代,算法都已一种方式在修改 W, b 的值,使总的 loss 最小。
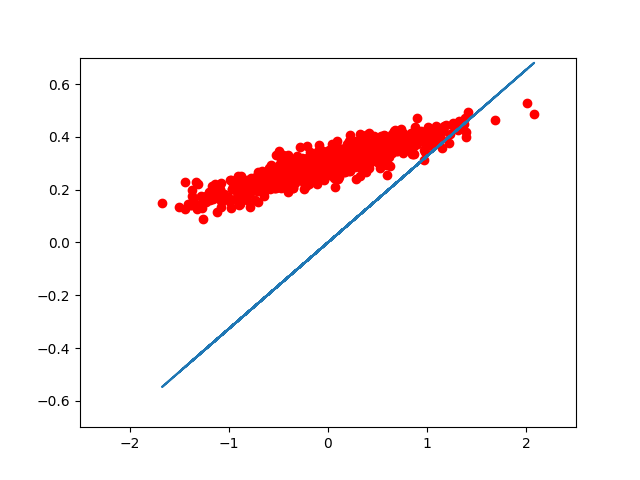
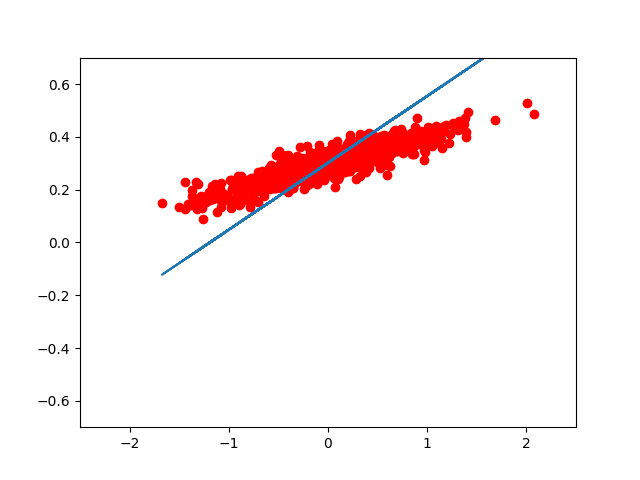
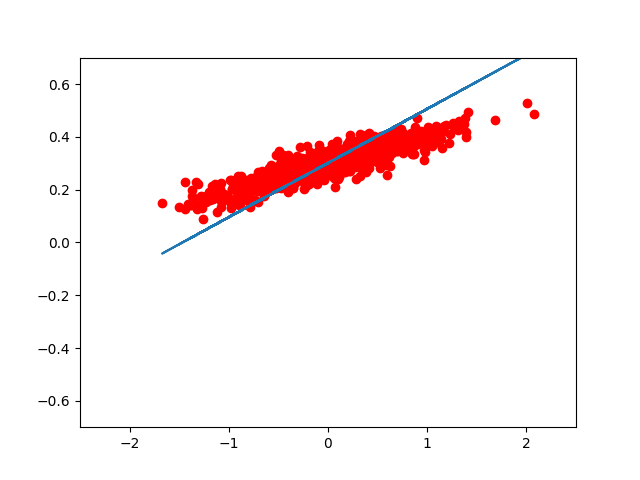
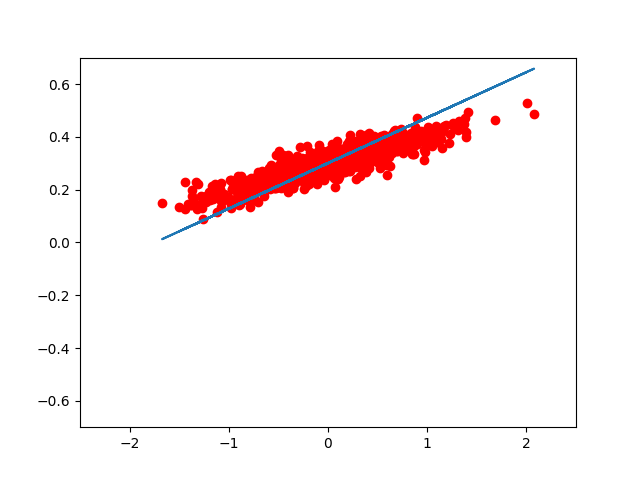
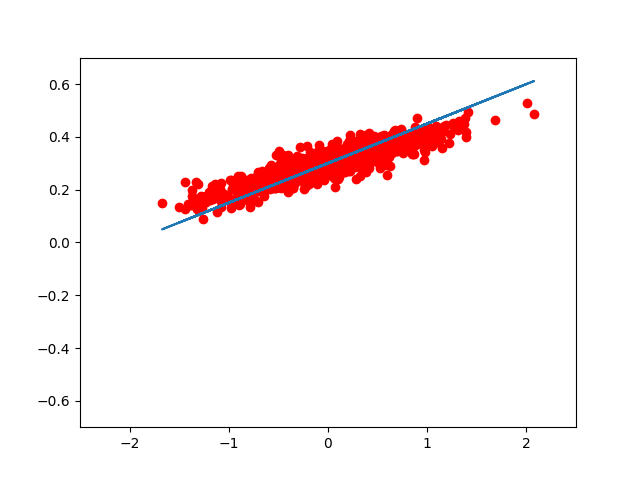
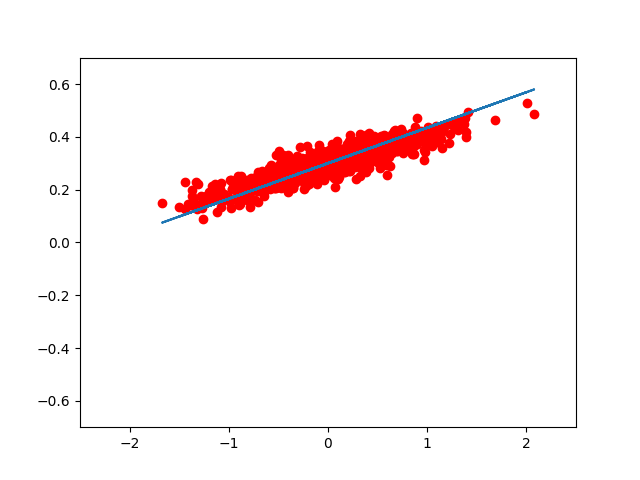
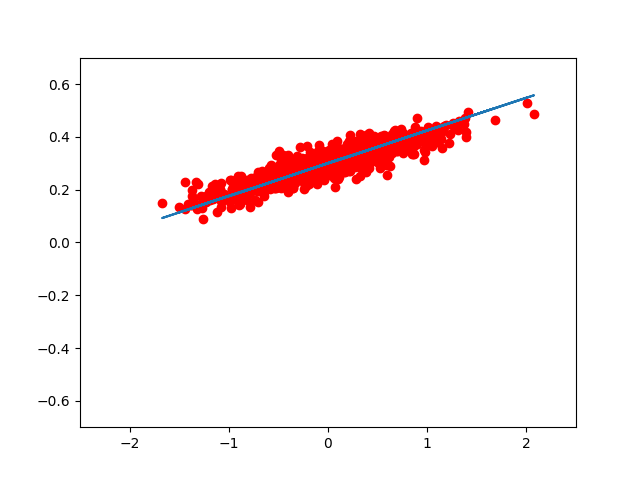
如果我们想用 matplotlib 把每一步优化后的结果显示出来,我们可以这样写:
for step in range(8):
print( step, sess.run(loss), sess.run(W), sess.run(b) )
plt.plot( x_data, y_data, 'ro' )
plt.plot( x_data, sess.run(W) * x_data + sess.run(b) )
plt.xlim( -2.5, 2.5 )
plt.ylim( -0.7, 0.7 )
plt.legend()
plt.show()
sess.run( train )
的到的图像大致如此:(我们可以看到,仅仅用了 8 次迭代, W, b 组成的模型,已经能很好的拟合 train 数据了。)
 |
 |
 |
 |
 |
 |
 |
 |
从输出的数据中我们可以看到,开始的时候我们的 W, b 分别初始化成了 。经过每一次迭代模型都越来越吻合原始数据。那么 GradientDescent 到底是如何做到的?
解释 GradientDescent(梯度下降) 算法是比较麻烦的,如果之间按照原文的翻译过来,我相信只有事先了解的人才会理解什么意思,因此,在理解这个算法前,我觉得至少要对下面借个概念有所了解,我在后面的参考文档中也提供了相关解释的资料,可以先看看,因为我说的,或许并不是那么清晰明了。首先得知道导数是什么?然后梯度是什么?梯度代表的意义是什么?当梯度 >0, ==0, <0 的时候代表参数的模型处于什么状态?如果你把这些能理解清楚,估计对提督下降的概念就自然而然的理解了。作者的结束如下:根据 loss function 所组成的两个参数(这里只考虑一元一次线性方程的情况)可以画出一个二维平面,然后这个二维平面的每个点(Wi,bj)就可以表示一个模型,然后我们再增加一个维度即 loss function 的值。这样我们就可以得到一个三维的图形。它的 x 轴是参数 W 的可能,它的 y 轴是参数 b 的可能,它的 z 轴是参数 W, b 构成模型与实际数据计算出来的 loss value。由此我们可以看到一个类似于下面的这种图形,然后我们对该图形函数(也就是 loss function)求点 (Wi, bj) 在 W, b 方向上的偏导数,及得到了该点在各个方向上的梯度,如果梯度大于 0 则说明现在的 loss function 的值的趋势是增长的,反之则说明值是减小的,而对于一元一次线性模型,我们只要找出 loss function 这个凹函数的最小值点(也就是趋势由减小变为增长的点)。也就是梯度为 0 的点,即找到最拟合我们 samples 的模型(最优解)。而在我们随机从这个三维空间中选择一个 W, b 开始优化时,我们只需要遵从公式(参数 = 参数 - lamda * 梯度),经过一次又一次的迭代 W, b 就会逐渐移动到(一元一次线性模型) loss function 的全局最低点。
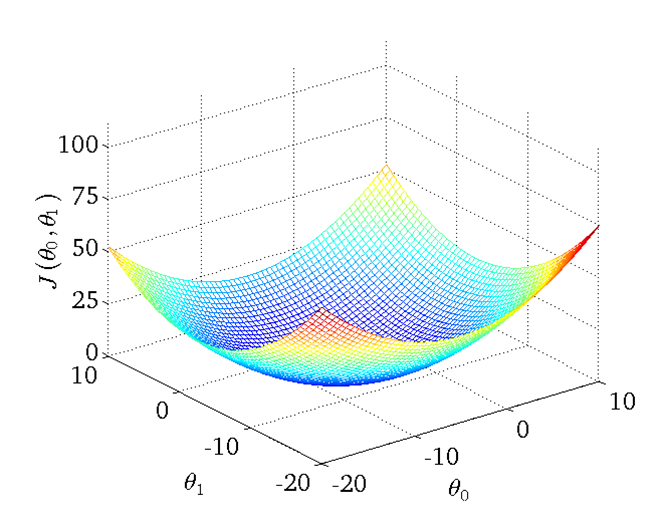
使用 TF 的时候,它会自动的计算我们传进去的 loss function 的 Gradient,而且每一次迭代都会自动的优化 W, b。在上面提到的优化公式(参数 = 参数 - lamda * 梯度)中有一个 lamda 的参数,这个参数决定了优化的速率,可以很自然的看出,当 lamda 越大的时候证明我们将梯度纳入本次优化的量也会越大
但是也并不是意味着 lamda 越大越好,如果值太高,则会导致每一步都可能错过最优的点,则会导致算法不能收敛,再也找不到最优点。而值太小的话,就会导致收敛过慢,可能能得到更加精确的解,但是会花费难以接受的时间来优化,在本章的例子中我们可以改变 optimizer = tf.train.GradientDescentOptimizer( 0.5 ) 这一行代码中传进去的参数从而改变算法的优化速率。
记住,为了更好的理解本章的知识,最好亲自将下面的程序实际实验一下,如果想 get 原作者的精髓最好阅读一下原文。
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
num_points = 1000
vectors_set = []
for i in range( num_points ):
x1 = np.random.normal( 0.0, 0.55 )
y1= x1 * 0.1 + 0.3 + np.random.normal( 0.0, 0.03 )
vectors_set.append( [x1, y1] )
x_data = [v[0] for v in vectors_set]
y_data = [v[1] for v in vectors_set]
# plt.plot( x_data, y_data, 'ro', label='Original data' )
# plt.legend()
# plt.show()
W = tf.Variable( tf.random_uniform( [1], -1.0, 1.0 ) )
b = tf.Variable( tf.zeros([1]) )
y = W * x_data + b
loss = tf.reduce_mean( tf.square( y - y_data ) )
optimizer = tf.train.GradientDescentOptimizer( 0.5 )
train = optimizer.minimize( loss )
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run( init )
for step in range(10):
print( step, sess.run(loss), sess.run(W), sess.run(b) )
plt.plot( x_data, y_data, 'ro' )
plt.plot( x_data, sess.run(W) * x_data + sess.run(b) )
plt.xlim( -2.5, 2.5 )
plt.ylim( -0.7, 0.7 )
plt.legend()
plt.show()
sess.run( train )
线性回归(Linear Regession)我们已经在上一章介绍了,他是监督学习的一种(supervised learning),我们用一组标记好的数据来训练算法模型,然后使模型预测的值能与标记数据相合。但有时候我们想分析一组数据,但是这组数据并没有被标记好,在这种情况下,我们就要用到非监督学习(unsupervised learning),非监督学习是一种被广泛应用的学习算法,因为它通常能很好的对数据进行筛选,分类。
在这章中,我们将介绍一种非监督学习的算法 —— K近邻法(k-means)。可以说它是一个将未分类的集合筛选分类为若干相干性很高子集的算法,也是应用得最流行和最广泛的一种,在子集中,数据的相似度很高。而在这个算法中,我们没有可以用来标定输出类型的值。(也就是说,我们只有一数据在某些特征上的值。比如说我们想要将一堆描述人的数据分为三类,然后我们有一个人头发长短,带没带 bra,有没有小 JJ ,会不会化妆的值,但是没有这个人是男是女或 RY 值)
同时,我也将在此章更加深入的介绍 TF 的基本数据类型 tensor,tensor 这种数据类型与何种类型相似,以及实现 tensor 与该类型之间的转换。然后,我将 tensor 的思想运用到 K-means 中。
TF 语言使用一种叫 tensor 的数据类型来表示所有的基本数据,Tensor 可以看作是拥有静态类型描述的动态分配的多维的数组,它可以表示 boolean, string 类型,也可以表示数值类型,下面的列表向你们展示 tensor 与 python 中等价的类型:
| Type in TF | Type in python | Description |
|---|---|---|
| DT_FLOAT | tf.float32 | Float porint of 32 bits |
| DT_INT16 | tf.int16 | Integer of 16 bits |
| DT_INT32 | tf.int32 | Integer of 32 bits |
| DT_INT64 | tf.int64 | Integer of 64 bits |
| DT_STRING | tf.string | String |
| DT_BOOL | tf.bool | Boolean |
另外,每一个 tensor 都有一个描述它维度(rank,学过线性代数的同学应该很熟悉这个名词的意思)的参数。比如下面的 tensor 维度就是 2。
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
Tensor 可以被设置成任意的 rank (维度),比如 rank == 0 代表 scalar value,rank == 1 代表一个向量(vector),rank == 2 代表一个矩阵(matrix).TF 有三种描述维度的约定(shape, rank, Dimension Number),为了更加方便的阅读 TF 的文档,下表展示了这三种约定之间的关系。
| Shape | Rank | Dimension Number |
|---|---|---|
| [] | 0 | 0-D |
| [D0] | 1 | 1-D |
| [D0,D1] | 2 | 2-D |
| ... | ... | ... |
| [D0,D1 ... Dn] | n | n-D |
Tensor 的这些维度可以利用 TF 提供的函数来进行相互之间的转换。我们将在下一个列表中展示如何去操作。(通过这章,我希望能完整的了解与这方面的相关的操作,更加详细的解释请访问本章后的参考资料 [PTOTAL1])
| Operation | Description |
|---|---|
| tf.shape | To find a shape of a tensor |
| tf.size | To find the size of tensor |
| tf.rank | To find a Rank of tensor |
| tf.reshape | To change the shape of a tensor keep the same elements contined |
| tf.squeeze | To delete in a tensor dimensions of size 1 |
| tf.expend_dims | To inser a dimension to a tensor |
| tf.slice | To remove a portions of a tensor |
| tf.split | To divide a tensor into several tensors along one dimension |
| tf.tile | To create a new tensor replicating a tensor multiple times |
| tf.concat | To concatence tensors in one dimension |
| tf.reverse | To reverse a specific dimension of a tensor |
| tf.transpose | To transpose dimensions in a tensor |
| tf.gather | To collect portions according to an index |
例如,如果我们想将二维的数组 A 扩展为三维的数组,我们可以用 tf.Expend_dims 这个函数将会让我们插入一个维度到 tensor A 中。
A = tf.constant( 1.0, shape=[2,2000] )
print( tf.Shape(A) )
A_expand = tf.expand_dims( A, 0 )
print( tf.Shape(A_expand) )
在本章的后面,我们将看到更多关于 tensor 的数学操作,比如:我们会利用 TF 中的函数自动推导一个未被指定大小的维度,并设置一个我们推到的值。
在介绍完 TF 之后,我们来介绍 TF 中获得数据的方式,宽泛的讲有三种:
- 从外部文件导入
通常,我们会从文件中导入初始化数据,这个过程并不复杂,但鉴于这本书的意图,在这里并不会详细的介绍如何导入数据。我推荐读者到 TF 的官网上详细的研究一下如何从不同的文件中导入数据(PROTAL2),你还可以看一下 PROTAL3 中的内容,因为我们之后会用这个方法导入 MINIST 数据。
- 预加载的常量或者变量
如果数据集比较小,也可以实现将数据加载到内存中,我们有两种方法来实现这个过程:1.用
constant(...)当成一个常量导入;2. 用variable(..)当成一个变量导入。TF 提供了一些不同的方法来生成常量,如下表中,你可以发现一些更加详细的描述:
Operation Description tf.zeros_like Create a tensor with all elements initialized to 0 tf.ones_like Creates a tensor with all elements initialized to 1 tf.fill Creates a tensor with all elements initialized to a scalar value given as argument tf.constant Creates a tensor of constants with the elements listed as an arguments 在 TF train 数据的时候,参数主要是作为变量保存在内存中。当一个变量被创建的时候,可以使用 TF 内建的函数初始化成一个常量,也可以初始化成一个随机数。下表提供了初始化成不同分布模型的随机数函数。
Operation Description tf.random_normal Random values with a normal distribution tf.truncated_normal Random values with a normal distribution but eliminating those values whose magnitude is more than 2 times the standard deviation tf.random_uniform Random values with a uniform distribution tf.random_shuffle Randomly mixed tensor elements in the first dimension tf.random_seed Sets the random seed 需要注意的是,TF 所提供的上叙函数都需要指定 tensor 的大小,维度。然后这些函数就会生成对应的 tensor,通常的来说,生成的 Tensor 都有一个固定的 size,但是如果想重新定义 tensor 代写大小,TF 也支持,这个在之前讲过。
在 TF 图构建好之后,在调用 session.run 之前爱你,必须将所有的变量都初始化,这个可以由
tf.initialize_all_variable()完成,在 train 完模型之后,变量也可由tf.train_Save()这个类来完成。但是这部分已经超出本书的知识点,在这里就不再介绍了,如需详细了解的,可以访问官方文档,也可查看 TF 的源码。 - Python 提供的方法生成
最后,我们可以用符号变量( placeholder )来描述数据之间的操作,这叫
tf.placeholder()。他可以是代指参数的类型,tensor 的 size, 或者操作的名字。当陈旭在调用 session.run 或者 tf.eval 时,程序会自动的从 dict 中取出值填入到 placeholder,如:import tensorflow as tf a = tf.placehodler('float') b = tf.placehodler('float') y = tf.mul( a, b ) sess = tf.Session() print( sess.run( y, feed_dict={ a:2, b:3 } ) )在最后有一行,当我们调用 tf.run 时 tf 会自动将 feed_dict 中的数值填入 a, b 中。
至此为止 tensor 的介绍就基本差不多了,希望接下来的代码,读者能毫无压力的理解清楚。
K-means 算法是一种解决聚类问题(clustering problem)的非监督学习(unsupervised algorithm)方法。这个算法是一种简单的方法将给定的数据分成指定的几类(K)。分类后的同一集合中的数据同质化和相似度都很高,而在不同的集合之间的数据差异度则会比较高。这也就意味着在一个子集中的数据将会比其他子集中的数据具有更高的相似度。
这个算法将会生成 k 个聚合点(centroids),这是各个子集的中心点,也就是说子集中的数据距离本子集 centroids 的距离都小于到其他子集 centroids 的距离。
直接求出数据中的 centroids ,最小化误差,这是一个非常消耗计算资源的问题(我们所知道的是这是一个 NP 难题),通常,我们会用反复迭代的方式步步逼近理想中的 centroids(即梯度下降算法),因为这个算法属于启发式算法,最后的结果会受到初始条件的影响,因此有些时候,运算出来的结果并不会在全局最优解附近。通常情况下我们会在不同的启发条件下计算出几组不同的 centroids ,然后选择其中最优的解。
通常情况下 K-means 算法会有以下三个步骤:
Initial step(step0):决定将数据分为 k 类;(结果生成 k 个 centroids)Allocation step(step1):计算每一个数据,并将只分给最近的组;Update step(step2):为每一个 group 计算新的 centroids ;
有几种方法可以初始化 centroids ,方法之一是随即的在数据集中选择 k 数据,让他们呢作为初始的 centroids。在我们的这个示例程序中我们用到的就是这种方法。
step1 和 step2 会交替进行运算,直到 step2 的结果已经收敛,换句话说也就是 step2 的结果将不再出现比较大的浮动。
在开始编写 k-means 算法之前我们首先得准备好数据,如下,我们准备了 2000 个随机的,分布在二维平面的,服从两种线性分布的数据。
import numpy as np
num_points = 2000
conjunto_points = []
for i in range( num_points ):
if np.random.random() < 0.5:
conjunto_points.append( [ np.random.normal( 0.0, 0.9 ), np.random.normal( 0.0, 0.9 ) ] )
else:
conjunto_points.append( [ np.random.normal( 3.0, 0.5 ), np.random.normal( 1.0, 0.5 ) ] )
像我们前一章所作的,我们可以用 python 的绘图库将这些数据绘制出来,如果没有用过的同学,我推荐先用熟悉使用 matplotlib 来绘图,但在这里我们将会用基于 matplotlib 的 Seaborn 库和描述复杂数据结构的 pandas 库开展示我们的数据。如果你之前没有安装过这些依赖库,那么在运行下面的代码前你需要先用 pip 安装这些库。展示上叙数据结构的代码如下:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.DataFrame( { "x": [v[0] for v in conjunto_points],
"y": [ v[1] for v in conjunto_points ]} )
sns.lmplot( "x", "y", data=df, fit_reg=False, size=6 )
plt.show()
你生成的图像长的应该和下面这副图类似:
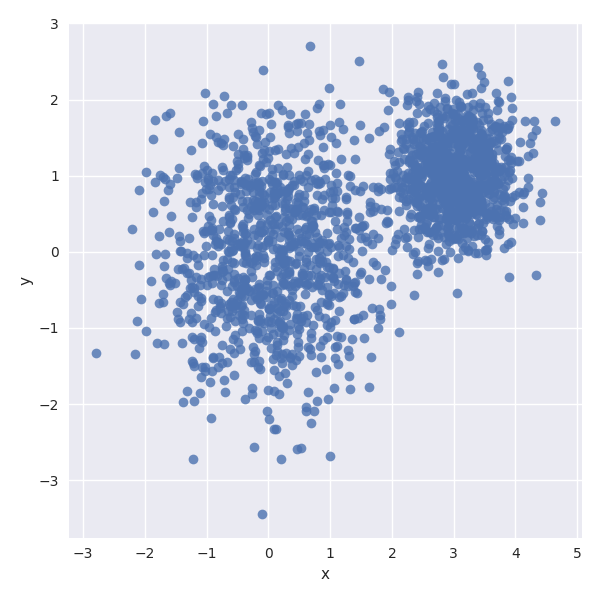
以下是一种基于 K-means 算法将上叙数据分为四类的 TF 代码实现:(基于 Shawn Simister 在他的 blog 中提出的模型)
import tensorflow as tf
print( tf.__version__ )
sess = tf.Session()
sess = tf.Session()
np.set_printoptions( threshold = 5 )
vectors = tf.constant( conjunto_points )
k = 4
centroides = tf.Variable( tf.slice( tf.random_shuffle( vectors ), [ 0, 0 ], [ k, -1 ] ) )
# print( "centroides = ", tf.slice( tf.random_shuffle( vectors ), [ 0, 0 ], [ k, 2 ] ).eval( session=sess ) )
expended_vector = tf.expand_dims( vectors, 0 )
# print( "expended_vector", expended_vector.eval( session=sess ) )
expended_centroides = tf.expand_dims( centroides, 1 )
# print( "expended_centroides", expended_centroides.eval( session=sess ) )
reduce_sum = tf.reduce_sum( tf.square( tf.subtract( expended_vector, expended_centroides ) ), 2 )
assignments = tf.argmin( reduce_sum , 0 )
means = tf.concat( [ tf.reduce_mean( tf.gather( vectors, tf.reshape( tf.where( tf.equal( assignments, c ) ), [1, -1] ) ), reduction_indices = [1] ) for c in range(k) ], 0 )
update_centroides = tf.assign( centroides, means )
init_op = tf.global_variables_initializer()
sess.run( init_op )
for step in range( 100 ):
pcentroides = sess.run( update_centroides )
print( sess.run( centroides ) )
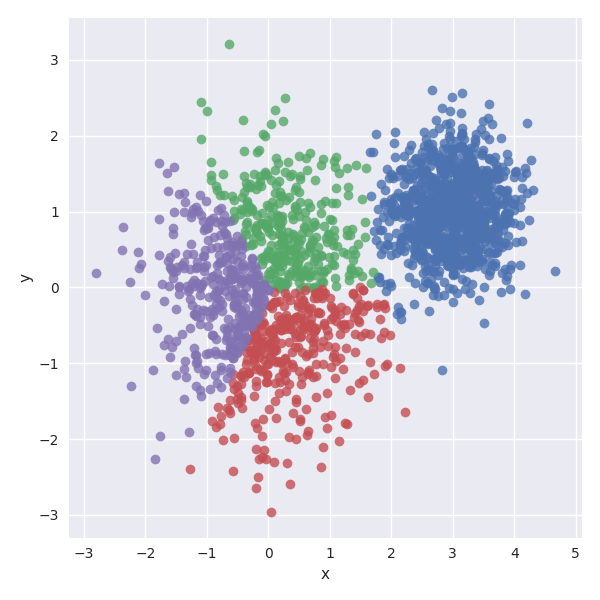
我推荐读着使用以下代码检查一下 assignments tensor 中的分布情况:(以下代码将会生成数据在二维空间中的分布情况)
assignment_values = sess.run( assignments )
data = { "x":[], "y":[], "cluster":[] }
for i in range( len(assignment_values) ):
data[ 'x' ].append( conjunto_points[i][0] )
data[ 'y' ].append( conjunto_points[i][1] )
data[ 'cluster' ].append( assignment_values[i] )
df = pd.DataFrame( data )
sns.lmplot( "x", "y", data=df, fit_reg = False, size=6, hue='cluster', legend = False )
plt.show()
你将会得到一副类似于下面这样的图片。
写到这里我想说一句就是,本文翻译的博客还是基于两年前的 TF,而到现今,TF 提供了很强大的调试接口,以及非常方便,直观分析工具来分析你的算法,所以我还是建议学习好 TensorBoard 这真的是非常不错的一个分析工具。
我猜想,读者读到这里已经头大了,不要急,接下来我们将会一步一步的分析上叙关键代码,尤其是涉及到 TF 中 tensor 是如何被引用和转化的部分。
首先我们需要导入我们的随即生成的数据,因为一般是不变的,因此我们将之转换成 constant tensor:
vectors = tf.constant( conjunto_points )
想之前我们提到过的,在这里我们应该初始化我们的 centroids,而且因为算法本身的需求,初始的 centroids 必须不一样。在这里我们先将数据洗牌,然后在打乱后的数据中选择前 4 个来当作 centroids 的初始值。
k = 4
centroides = tf.Variable( tf.slice( tf.random_shuffle( vectors ), [ 0, 0 ], [ k, -1 ] ) )
# print( "centroides = ", tf.slice( tf.random_shuffle( vectors ), [ 0, 0 ], [ k, 2 ] ).eval( session=sess ) )
k 个 centroids 被保存到二维的 tensor 中,如果我们想知道这些 tensor 内部的结构,我们可以用 tf.get_shape() 来获取。
print(vectors.get_shape())
print(centroides.get_shape())
现在可以直接用下面的代码,而且输出信息比上面的信息更全面
print(vectors)
print(centroides)
我们可以看到 vectors 是一个 (2000 row, 2 column) 的矩阵,总记录着 2000 个采样点。centroids 是一个(4 row, 2 column)的矩阵,k = 4 个质心的在二维空间中的位置。
之后算法将进入一个循环迭代的过程。首先,得求出每一个点到每一个 centroids 的距离,在这里我们使用的是欧式距离(当然在不同的情况下我们还会选择其他计算距离的方式,具体请参考[PROTAL4]),两个矩阵的相减会用到 tf.subtract(a,b),至于 tensor a 减去 tensor b 到底是一个什么结果,我认为读者应该自己手动实验一下,当然你也可以去查阅官方文档,或者查看源码。但我觉的自己动手做过的事,会让自己记得更深刻,而且关键的是要学会找到解决问题的方法,因为照搬的化,过去的知识在在看来可能就不适用了,比如两年前 tensor 的相减实际上用的是 tf.sub(a,b) 这个函数。
在学 matlab 的时候我们知道,当 a = [ [ 1, 1], [ 2, 2 ] ] 去减 b = [ [ 1, 1], [ 2, 2 ] ] 时,结果会是 [ [ 0, 0 ], [ 0 ,0 ] ]。而如果拿 a 去减 c = [ 1, 1 ] 的时候结果会是 [ [ 0, 0 ], [ 1, 1 ] ]。
从二维的 matrix 扩展到多维的 tensor 也一样,如果我们用 2000 * 2 的 vectors 减去 4*2 的 centroids 的时候,只会是因为两个的大小不一样导致运算出错,但是如果我们用 [[2000*2]] 的数组减去 [[1*2],[1*2],[1*2]] 的时候, 结果就会变成 [[2000*2],[2000*2],[2000*2]]。因此运用这个性质,恰好可以一次性将 2000 个点到 4 个 centroids 之间的各个特征的曼哈顿距离算出来。而将 vector 的 [2000*2] 扩展成 [[2000*2]] 则用 tf.expand_dims( vectors, 0 ), 而将 centroids 的 [3*2] 扩展成 [[1*2],[1*2],[1*2]] 的 tensor 则用 tf.expand_dims( centroids, 1 )。
tf.square(a) 将会对 a 中的所有数据求平方, tf.reduce_sum( a, 2 ) 则是对从高维向低维看的 -2 维进行求和(降维打击 :))。所引用的远离与 tf.expand_dims 类似。如 a = [ [ [ 1, 1 ], [ 2, 2 ] ], [ [ 3, 3 ], [ 4, 4 ] ], [ [ 5, 5 ], [ 6, 6 ] ] ], tf.reduce_sum( a, 2 ) 的结果是 [ [ [ 2 ], [ 4 ] ], [ [ 6 ], [ 8 ] ], [ [ 10 ], [ 12 ] ] ] , tf.reduce_sum( a, 1 ) 的结果是 [ [ [ 3, 3 ] ], [ [ 7, 7 ] ], [ [ 11, 11 ] ] ] ,tf.reduce_sum( a, 2 ) 的结果是 [ [ [ 9, 9 ], [ 12, 12 ] ] ]。 而在本章介绍的例子中即是求各个 sample 特征的曼哈顿距离的平方和,结果就是各个 sample 距离 centroids 的欧式距离。这里我们注意一下 tf.reduce(), TF 提供了几个数学方法(接口,函数),这些函数会使处理过 tensor 维度减小.下表列举了几个其他的类似于拥有这样功能的函数:
| Operations groups | Operations |
|---|---|
| tf.reduce_sum | Computes the sum of the elements along one dimension |
| tf.reduce_prod | Computes the product of the elements along one dimension |
| tf.reduce_min | Computes the minumum of the elements along one dimension |
| tf.reduce_max | Computes the maximum of the elements along one dimension |
| tf.reduce_mean | Computes the mean of the elements along one dimension |
如果你想对比同维度各个子 tensor 同一位置的数据哪个比较大(或者那个比较小),你可以用 tf.argmax( a, dim ), tf.argmin( a, dim )。比如就不在举例了,根据以上的例子,再利用简单的联想能力应该很容易知道 tf.argmax 的作用,在后面部分我也将给出测试这些接口的例子,亲自动手实验一下就当课堂作业吧。而在本章介绍的算法中则是求出每一个 sample 到底与哪一个 centroids 的距离最小。同样的,有最小就有最大,如下所示:
| Operations groups | Operations |
|---|---|
| tf.argmin | Return the index of the element with the minimum value of the tensor dimension |
| tf.argmax | Return the index of the element with the maximim value of the tensor dimension |
在每次迭代之后,我们有了新的集合,但是我们还是得记住,我们的目的是找出 centroids 来.下面这一行代码就是做这事的:
means = tf.concat( [ tf.reduce_mean( tf.gather( vectors, tf.reshape( tf.where( tf.equal( assignments, c ) ), [1, -1] ) ), reduction_indices = [1] ) for c in range(k) ], 0 )
上面这行代码所做的处理就是对属于每个集合(簇,group)的数据求平均值,接下来,我将详细的分析上面这行代码中包含的 TF 接口到底是对数据进行了怎样的操作.
我们的目的是将同一集合的数据从原来的数据集中找出来,然后聚合(gather)到一起,然后对每一个集合求中值,并把这些中值组合成一个新的 centroids.
首先是 tf.equal( a, b ), 这个函数的作用是判断 a 中的值是否等于 b 中的值,如果相等,则在 a 的相应位置的数据设置 True, 否则 Flase.最后生成一个 True 和 Flase 组成的 tensor, 而经过 tf.equal( assignments, c ) 我们就能找出 assignments 中同一组的数据在哪些位置.但是 True 和 Flase 并不能帮助我们从 assignments 中取出数据,此时我们就用上了 tf.where, 这个函数将一个 bool 集合中的 True 的下表(索引)找出来,比如说 a = [ True True False False True False False True True False],那么 tf.where(a) 的结果就是 [[0] [1] [4] [7] [8]] , 但我们从 assignments 中完整的取出数据的时候需要的数组格式是 [ 0, 1, 4, 7, 0 ] ,因此我们需要对 tf.where 的结果做 reshape,因此我们用到了 tf.reshapre().之后就是 tf.gather 这个函数会负责将 assignments 中 第二个参数指定位置的数据取出并返回.
最后需要提到的一个函数就是 tf.concat, 这个函数的功能字面意思就是合并两个同维度的集合,举个例子: a = [ [ 1, 2 ], [ 3, 4 ]], b = [ [ 5, 6 ], [ 7, 8 ]], 如果我们直接 [ a, b ] 那么结果就是 [ [ [ 1, 2 ], [ 3, 4 ] ], [ [ 5, 6 ], [ 7, 8 ] ] ],而将这个 tensor 用 tf.concat( tensor, 0 ) 处理,结果就变成了, [ [ 1, 2 ], [ 3, 4 ], [ 5, 6 ], [ 7, 8 ] ].
ps: 下面是测试这些程序的代码,建议大家还是实际操作一下.
import numpy as np
import tensorflow as tf
a = [ [ 1, 1 ], [ 2, 2 ], [ 3, 3 ], [ 4, 4 ], [ 5, 5 ], [ 6, 6 ] ]
a = tf.expand_dims( a, 0 )
b = [ [ 1, 1 ], [2, 2] , [3, 3] ]
b = tf.expand_dims( b, 1 )
c = tf.subtract( a, b )
d = tf.reduce_sum( c, 0 )
e = tf.argmin( c, 0 )
sess = tf.Session()
print( "a---->\n", a.eval( session=sess ) )
print( "b---->\n", b.eval( session=sess ) )
print( "c---->\n", c.eval( session=sess ) )
print( "d---->\n", d.eval( session=sess ) )
print( "e---->\n", e.eval( session=sess ) )
# print( "---->", tf.reduce_sum( a, 1 ).eval( session=sess ) )
# print( "---->", tf.argmin( a, 0).eval( session=sess ) )
# stand = np.random.randn( 10, 2 )
stand = [[ 1.1393722 , 1.33728204],
[-0.71773923, 0.00654658],
[ 0.86429579, -1.47813939],
[ 0.95321839, -0.47760367],
[-0.18936852, 0.09168004],
[ 0.99312509, -0.54670781],
[ 0.94027451, 0.40104494],
[-1.07108197, 1.95100451],
[-1.13885187, 0.14394257],
[ 1.75545762, -0.19064573]]
stand_tf = tf.constant( stand )
f = tf.argmin( stand, 1 )
g = tf.equal( f, 0 )
h = tf.equal( f, 1 )
i = tf.where( g )
j = tf.reshape( i, [ 1, -1 ] )
k = tf.gather( stand_tf, j )
l = tf.reduce_mean( k, 1 )
m = [ tf.reduce_mean( tf.gather( stand_tf, tf.reshape( tf.where( tf.equal( f, index ) ) ,[1,-1] ) ), 1 ) for index in range(2) ]
n = tf.concat( l, 0 )
print( "f---->\n", f.eval( session=sess ) )
print( "g---->\n", g.eval( session=sess ) )
print( "h---->\n", h.eval( session=sess ) )
print( "i---->\n", i.eval( session=sess ) )
print( "j---->\n", j.eval( session=sess ) )
print( "k---->\n", k.eval( session=sess ) )
print( "l---->\n", l.eval( session=sess ) )
print( "m---->\n", sess.run( m ) )
print( "o---->\n", n.eval( session=sess ) )
最后我们得讲一下循环迭代部分的代码,还有更新 centroids 部分的代码.首先为了更新 centroids 需要创建一个操作符(运算流程),当执行到 sess.run() 的时候,这个操作符会将计算出来的中值赋值给 centroids,已被后续的迭代使用.
update_centroides = tf.assign( centroides, means )
接下来我们要初始化 TF 中的所有变量.
init_op = tf.global_variables_initializer()
sess.run( init_op )
到这一步,基本上所有前期工作都准备好了,接下来就可以训练这个模型(graph, TF 操作流图),
for step in range( 100 ):
pcentroides = sess.run( update_centroides )
# print( sess.run( centroides ) )
在这里需要注意的一点是,你定义的 update_centroids 并不是一个变量,而是一个运算符,这个运算符的目的就是更新 centroids, 而执行的流程就是我们上面所提到的那些.只有当 sess.run 这个运算符的时候上面这个流程才会执行一遍,同时 sess.run() 也会返回运算符运算之后的值(numpy 格式).当我们迭代过 100 次后便可用 Seaborn 将结果显示出来,(Seaborn 如何操作的知识超出了本书的介绍范围,希望大家自己到 Seaborn 的官网上了解详细的使用方法啊)
强烈建议读者可以手动将代码中的参数值,运行一下看看结果是怎样的,这样能让你更加深入的理解本章中提到的知识.
本章到这里也就结束了,主要介绍了 Kmeans 在 TF 上的实现,以及提到了与之相关的某些函数的具体操作方法.下一章我们将会接触到单层的神经网络,以来可以接触到更多 TF 提供的接口,而来为理解,学好 DNN 这是必不可少的.
在这一部分,我将介绍一种用于模式识别深度学习方法,和变成语言的初学者学的第一行代码是将 "hello world" 打印到屏幕上一样,在 Deep learning 中我们首要做的事是进行手写数字识别,在这一章中,我将一步一步的介绍如何用 TF 实习单层的神经网络,这也是众多的 TF 入门教程之一,所以读者们好好笑话吧!
鉴于本书的对象人群,因此在这里关于某些算法细节的推导会做相应的简化,更多的将会是使用实例来引导读者去理解.在阅读本书后如果读者想要了解更多关于算法的理论推导,我建议读者阅读本章参考资料 [PROTAL1] ,当然在本书后还有更多的学习资料,大家可以自己选择.[PROTAL1] 讲的同样是这个例子,但是会在理论层面做更加详细的讲解.
MNIST 是一个手写数字图片的开元数据库,这些数据由白底黑子的数字图片组成,这个数据库包含了 60000 用于训练的数据和 10000 用于测试的数据(当然这个比率是可以调的,只是可能自己要费一些功夫),这些数据可以在本章后的 [PROTAL2] 中被找到.
这个数据集非常适合开始学习模式识别,但是没有时间去准备数据(收集数据,筛选数据,格式化数据,对数据做标记)的初学者.这几步也是机器学习中非常重要的几步,但是也是非常花时间的几步.(当然现在开始流行 GAN 了,不过某些前期工作还是比较麻烦的)
本数据集中的图形数据都已经归一化成了 20*20 的像素,在这个案例中,我们可以看到图像使用了平滑处理(在黑白相間的地方使用了灰色的像素点),在这之后将格式化的图片平移到以 28*28 像素为中心位置.如下琐事:
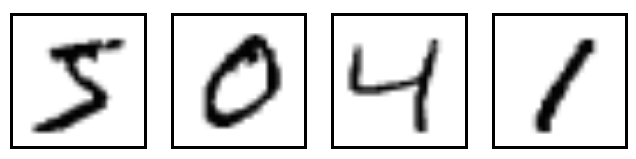
而且我们本章中所介绍的是监督学习,因此这些图片也相应的被标记成你所看到的数字.这也是现今机器学习最常见的形式.
首先,在开始的时候我们收集了一大堆标记好的数据,这些数据被输入模型后,模型会根据输入计算出一个对应正确输出值的得分,我们当然希望每一个图像,模型都给该图像的对应值的得分越高.但这在模型训练初期基本上是不可能的.
在一次预测之后,我们设计了一个 error function,这个函数会针对预测结果计算与真实结果之间的偏差.为了缩小预测值与真实值质检的偏差,我们会根据计算出来的值对模型中的参数(神经元的权重,weight)做调整,在典型的 DNN 中,这些参数常常是成百上千万的,但是在这里,我们简化了模型,一遍我们更好的理解算法是如何运行的.
我们这里使用简单的方法将之前 MNIST 库中的数据导入,如下:
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
其中代码所用到的库文件你可以在本章后 [PROTAL3] 下载得到.这份代码是 google 开源的,还是不由得赞叹:"还是 google 大法好啊!"
执行玩上叙代码之后,你就可以在环境中调用 mnist.train 使用训练的数据, 调用 mnist.test 使用 mnist 测试集数据.如前所述,每个元素由一个被称为“xs”的图像和相应的标签“ys”组成,这样能更方便的表示代码。请记住,所有数据集,培训和测试都包含“xs”和“ys”.同样在本例中,访问训练数据的数据(图像)可访问 mnist.train.images ,访问对应的标记 mnist.train.labels 中。
如前所述,一个 28*28 的图片可以表示成一个矩阵,如下所示:
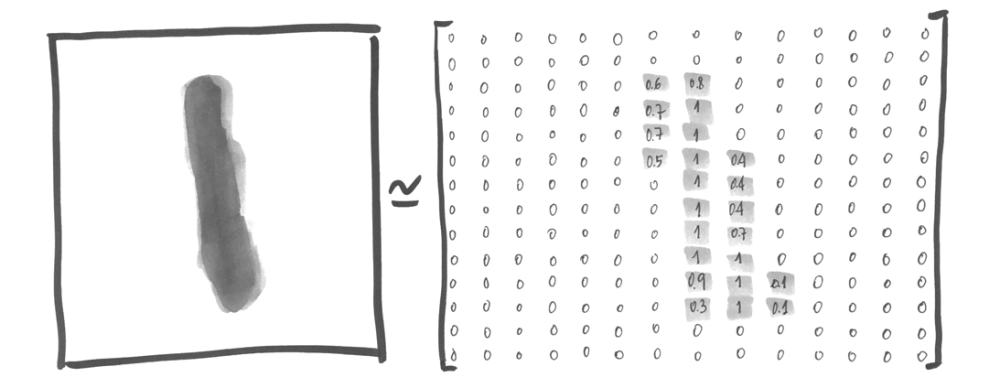
在这里,每一个值表示该点像素的颜色深浅,这个矩阵可以表示 14*14 的图像(为了显示方便我们使图片缩小了一倍), 实际上在代码中,我们把一张图片(28*28)表示成一个 784 维的数组.需要注意的是,某些情况下,为了方便分析算法模型,可能会用到一些图形展示工具来向我们展示某些参数,这就不可避免的需要将高维的数据压缩,降维,但这时候就会造成信息的丢失,但是在我们这个例子中不用担心,因为足够简单.
在本章中我们可以用 tf.get_shape 来获取 mnist.train.imagse 的大小(形状.数据组织方式)(TensorShape([Dimension(60000), Dimension(784)])).第一个维度表示地几张图片,第二个维度则表示组成一副图片的 784 个像素点.每一个值都表示 0 或者 1.同样在我们的标记数据集中存放着图片所对应的数值.一个图片对应的 label 由 0-9 十个 bool 类型的值组成,如果这幅图所对应的数值是 1 那么,在 bool 数组中第二个数据就是 1, 其他的就是 0,(这是因为数据是从 0 开始的).同样 mnist.train.labelses 数据集的大小应该是这样. TensorShape([Dimension(60000), Dimension10)])
尽管本书并不会深入的介绍神经网络(NN)的原理,但是读者了解一些简单直观的东西对后续的学习还是很有帮助的。那些已经知道了 NN 原理的人可以跳过此章节了。
下面我以一个简单的例子来说明 NN 的运作方式,如下图所示,在样本空间中包含着两类数据,一类是四边形,一类是圆形,现在我们有个未知的数据 x 处于图中所示位置,现在我们需要求出 x 属于那一类。
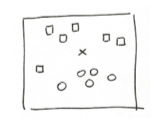
最简单的方法就是画一条直线将两类数据分开,然后看 x 属于哪一边。
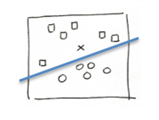
在这个例子中,输入数据是由 (x, y) 所构成的二维空间中的点,而我们的函数的返回值 (0 or 1) 则是这个点是输入那一类数据 ( 在线线的上方--属于平行四边形,还是在线的下方--属于圆形 ) ,在 Linear Regression 那章我们了解到,这条线可以用这个式子( y = W*x + b )来表示。
一般的来说,神经网络需要学习两个参数来对输入数据 -- 权重(Weight 大小和输入的纬度一致)和偏置(bias),然后神经元将计算输入 X 与 权重 (weight) 相乘与偏置(bias)的和,在经过一个非线性的激活函数(activation function)来转换成分类的值(Y | 0 or 1)。
这个个过程可以表示成如下数学形式:
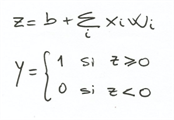
我们已经为神经元定义了它的函数,那么算法是如何从图中方形和圆形的采样点得出 W 和 b 的勒?
第一种方法可能与我们之前用的线性回归的方法类似,向神经网络中喂已经标记好的数据,然后比较算得的结果与真实结果之间的差值,通过这个差值来调整 W 和 b 的值,随后每一次迭代 W 和 b 的值都会朝着错误率最小的方向改变,如第二章看到的。一旦有了 W 和 b,便可计算出输入数据的加权和 z,随后我们需要一个函数将 z 中的结果转化成 '0' 或者 '1'。这里有几个可用的激活函数,在这个例子中,我们可以用最流行的激活函数(sigmoid function)来返回介于 0 和 1 之间的值。
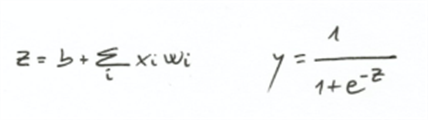
更具上面这个公式,我们可以看到算法在大多情况下会返回趋近与 0 或 1 的值,如果 z 的值过大,那么 e^-z 就会趋近 0,而 sigmoid 函数的输出则会趋近与1,反之则会趋近于 0, 如下图所示:
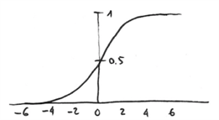
至此,我们学到了如何定义一个神经元,但在实际应用中,神经网络的组织方式和用的 activation function 都是各种各样的(据具体问题而定)。鉴于本书的宗旨是让读者快速的熟悉 tensorflow,因此在这里就不再深入探讨。但我向你保证,了解研究神经网络的过程是一个让人激动人心的过程。
我们需要注意的一点是,一个典型的神经网络会由层来表示,样本数据从输入层(input layers)进入,在隐藏层(hiden layers)进行运算,然后运算结果由输出层(output layers)输出,一个只直观的表示如下所示:
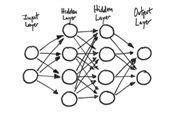
在这个网络中,同以层中的神经元,承接上一层的信息,经过加权,求和,激活函数转化,输出到下一层伸进元。
最后我们在说一下 activation function,如之前提到过,类似于 sigmoid 这种激活函数是有很多的,每一种都会有各自的特性。当我们面对的是多类分类问题(>2)时,我们可能就会用到 softmax 这种 activation function,softmax 会为每一个类计算它的概率密度,这些概率加起来会等于 1,而更具输入算法得出的结果将可能是概率最大的那个结果。具体关于 softmax 以及其他 activation function 的信息注意文后的参考资料,会不定期更新。
2017-5-16: TensorFlow 目前已经支持 C/C++, Python, Java, Go。一下部分是我自己闲时记录在应用中记录的问题以及解决方法。
我这里之介绍 python 的安装办法,一来 python 最容易入门,二来平时调试训练的时候 python 也最容易实现。如果需要看更加详细的安装方法需要你去 tensorflow 的官网上多走走,因为 Tensorflow, Cudnn 之类的发展太快了,可能过来半年这个教程就已经过时了,但是去官网肯定是可以解决的。
大致的安装步骤是:
- 安装 python;(需要注意 python 的版本,因为 python2.7, python3.0 的变动还是比较大的)
- 安装 pip;(这个要是用来安装 Tensorflow 以及相关库)
- 如果是只想用 cpu 那么直接运行
pip install tensorflow即可,如果你有 nvidia 的独显,建议你装 gpu 版本,pip install tensorflow-gpu; - 安装其他调试依赖的库,有些会在安装 tensorflow 的时候顺便安装上。(numpy, scipy, matplotlib, pandas, seaborn ... )
- 如果你安装的是 gpu 版本,那么你需要安装 cuda,cudnn;
以上两个库都是 nvidia 官方提供的,没有源码,如果你的系统是 Archlinux,cuda 直接用 pacman 装就可以了,如果你的是 ubuntu 那就跟容易了,入门级的 linux 系统,相信大家也能搞定。安装 cudnn 的话,首先是要确定你安装的 gpu 版本的 tensorflow 对应那个版本的 cudnn,我所知道的办法是,先不管三七二十一先把 cudnn 装上(随便选择一个版本),然后写个最简单的 tf 程序,运行一次,log 里面自有打印。当然我相信 tensorflow 肯定有更加简单的办法来严格的知道对应的 cudnn 是哪个,我就不再深究了。
现在如果你碰到了版本不兼容,你可能需要到 nvidia 的官网把 cudnn 的库下下来,现在麻烦一点的是需要你注册一个帐号(访问[PROTAL1],然后下载([PROTAL2])对应的版本,我的 TF 的版本是 1.1, cuda 和 cudnn 默认安装到了
/tmp/cuda目录。所以依照你安装的目录,将下载的库解压到相应的目录即可。最后需要注意的就是设置好
LD_LIBRARY_PATH和CUDA_HOME这两个环境变量。如我的安装目录是/opt/cuda,那么将下面两个语句保存到你的启动脚本中,或者你每次激活 virtualenv 的时候应用一下。export CUDA_HOME=/opt/cuda,export LD_LIBRARY_PATH=$LIBRARY_PATH:/opt/cuda/lib64。之后你就可以将你的 tensorflow-gpu 用起来了。我的是笔记本电脑,配了 GeForce 840M,相比与将 cpu 的资源全部用尽,用上 gpu 速度提升了大约 20 几倍。 - 很多人会选择将 tensorflow 以及相关的 ML 开发环境用用 virtalenv 独立出来,因为开发可能还涉及到后台的开发,以及 QT 的开发,因此我也建议你使用这个工具。顺便提一句,在你使用
workon env的时候,此时配置环境的脚本存在/home/user/.virtalenv/env/bin/activate目录中,因此如果你要家上面提到的 CUDA_HOME ... 可以加入到这个文件中。安装 virtualenv 或者 virtalenvwrapp 请参考 [PROTAL3].
- [PROTAL1]First contact with TensorFlow -- Get started with with Deep Learning programming(本文原文)
- [PROTAL2]TF Tutorials
- [PROTAL3]PCA 的数学原理
- [PROTAL4]NMF 的非负矩阵分解



 浙公网安备 33010602011771号
浙公网安备 33010602011771号