
机器学习编译MLC
陈天奇 - 《机器学习编译》
课程主页: https://mlc.ai/summer22-zh
课程笔记:https://mlc.ai/zh/
机器学习编译概述
1.1 什么是机器学习编译
机器学习编译 (machine learning compilation, MLC) 是指,将机器学习算法从开发阶段,通过变换和优化算法,使其变成部署状态。
开发形式 是指我们在开发机器学习模型时使用的形式。典型的开发形式包括用 PyTorch、TensorFlow 或 JAX 等通用框架编写的模型描述,以及与之相关的权重。
部署形式 是指执行机器学习应用程序所需的形式。它通常涉及机器学习模型的每个步骤的支撑代码、管理资源(例如内存)的控制器,以及与应用程序开发环境的接口(例如用于 android 应用程序的 java API)。
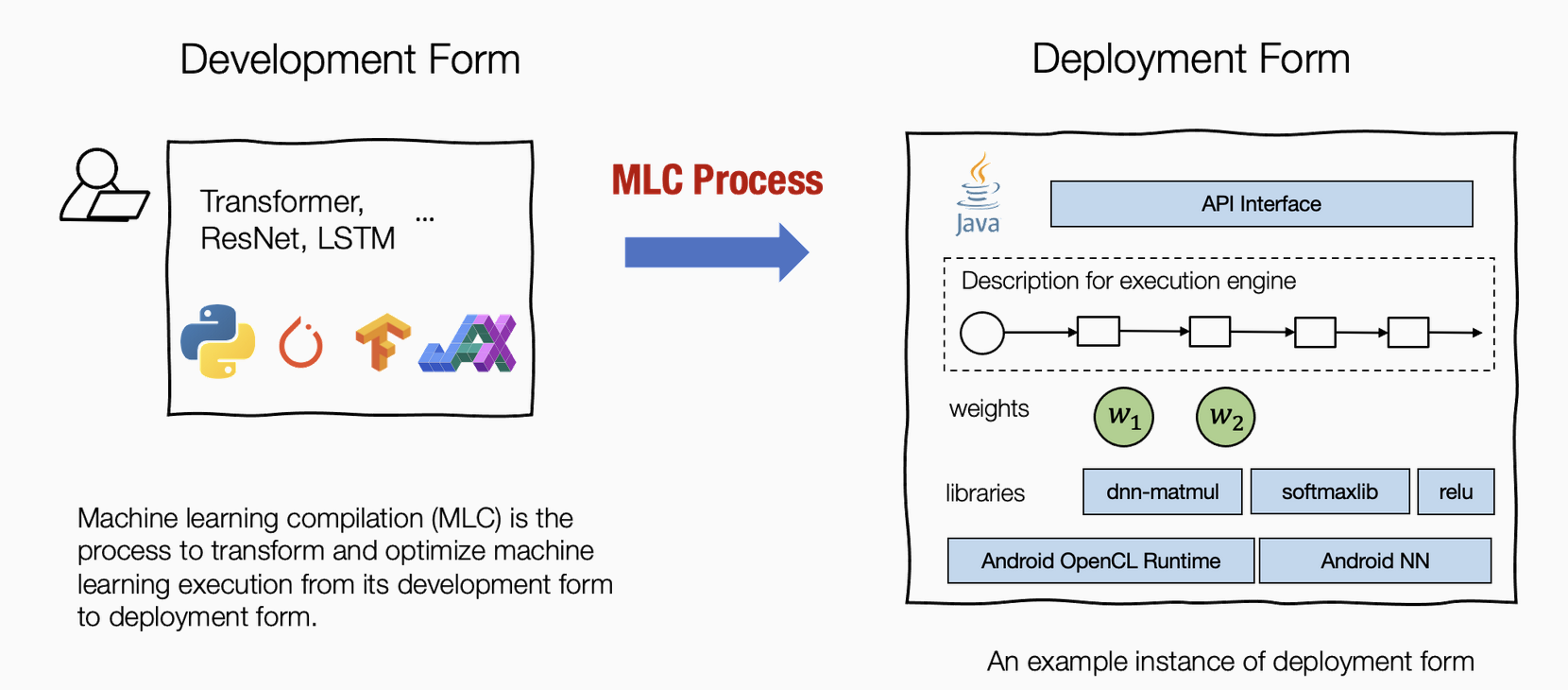
机器学习编译通常有以下几个目标:
- 集成与最小化依赖 部署过程通常涉及集成 (Integration),即将必要的元素组合在一起以用于部署应用程序。 例如,如果我们想启用一个安卓相机应用程序来检测猫,我们将需要图像分类模型的必要代码,但不需要模型无关的其他部分(例如,我们不需要包括用于 NLP 应用程序的embedding table)。代码集成、最小化依赖项的能力能够减小应用的大小,并且可以使应用程序部署到的更多的环境。
- 利用硬件加速 每个部署环境都有自己的一套原生加速技术,并且其中许多是专门为机器学习开发的。机器学习编译的一个目标就是是利用硬件本身的特性进行加速。 我们可以通过构建调用原生加速库的部署代码或生成利用原生指令(如 TensorCore)的代码来做到这一点。
- 通用优化 有许多等效的方法可以运行相同的模型执行。 MLC 的通用优化形式是不同形式的优化,以最小化内存使用或提高执行效率的方式转换模型执行。
1.2 为什么学习机器学习编译
对于机器学习科学家,学习机器学习编译可以更深入地了解将模型投入生产所需的步骤。机器。机器学习编译使机器学习算法科学家有机会了解背后的基本原理,并且知晓为什么我的模型的运行速度不及预期,以及如何来使部署更有效。对于硬件厂商,机器学习编译提供了一种构建机器学习软件栈的通用方法,能够最好地利用他们构建的硬件。重要的是,机器学习编译技术并不是孤立地使用的。许多 MLC 技术已被应用或正在整合到常见的机器学习框架和机器学习部署流程中。 MLC 在塑造机器学习框架生态系统的 API、架构和连接组件方面发挥着越来越重要的作用。最后,学习 MLC 本身很有趣。
1.3 机器学习编译的关键要素
张量 (Tensor) 是执行中最重要的元素。张量是表示神经网络模型执行的输入、输出和中间结果的多维数组。
张量函数 (Tensor functions) 神经网络的“知识”被编码在权重和接受张量和输出张量的计算序列中。我们将这些计算称为张量函数。值得注意的是,张量函数不需要对应于神经网络计算的单个步骤。部分计算或整个端到端计算也可以看作张量函数。
1.4 抽象和实现
我们使用抽象 (Abstraction)来表示我们用来表示相同张量函数的方式。不同的抽象可能会指定一些细节,而忽略其他实现(Implementations)细节。例如,linear_relu 可以使用另一个不同的 for 循环来实现。
张量程序抽象与实践
2.1 元张量函数
机器学习编译的过程可以被看作张量函数之间的变换

2.2 张量程序抽象
张量程序抽象的一个重要性质是,他们能够被一系列有效的程序变换所改变。
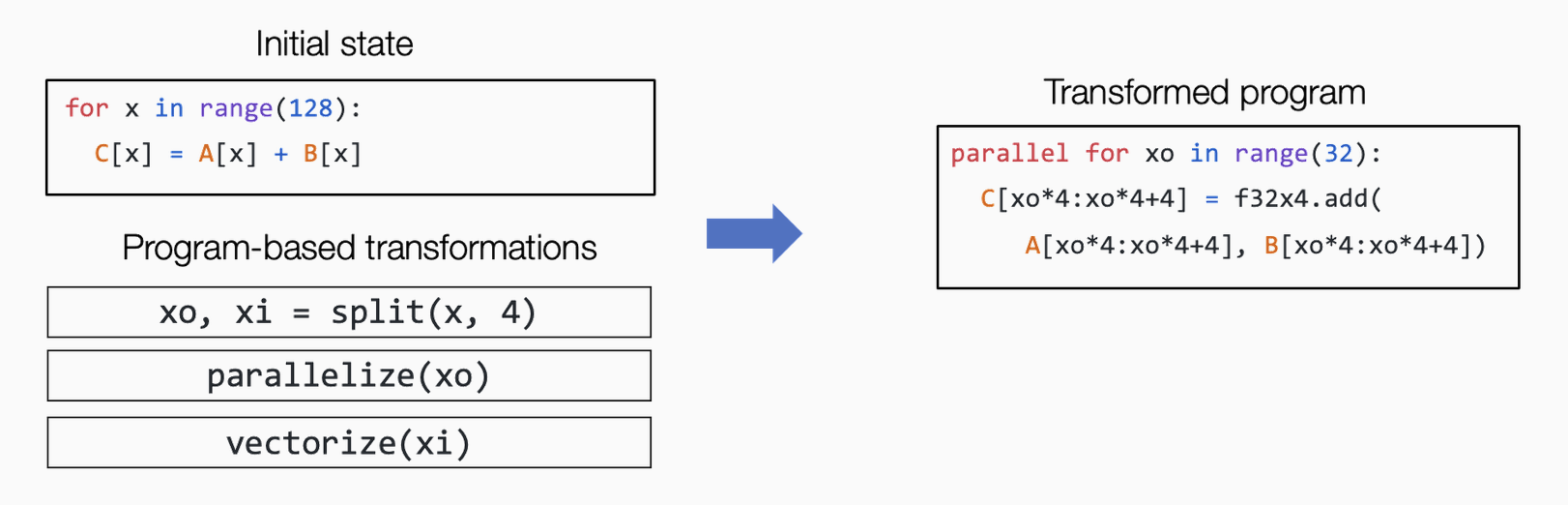
张量程序抽象中的其它结构

举个例子,上面图中的程序包含额外的 T.axis.spatial 标注,表明 vi 这个特定的变量被映射到循环变量 i,并且所有的迭代都是独立的。
- 张量程序是一个表示元张量函数的有效抽象
- 关键成分包括: 多维数组,循环嵌套,计算语句。
- 程序变换可以被用于加速张量程序的执行。
- 张量程序中额外的结构能够为程序变换提供更多的信息。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具