词法分析程序的设计与实现
词法分析程序(Lexical Analyzer)要求:
- 从左至右扫描构成源程序的字符流
- 识别出有词法意义的单词(Lexemes)
- 返回单词记录(单词类别,单词本身)
- 滤掉空格
- 跳过注释
- 发现词法错误
程序结构:
输入:字符流(什么输入方式,什么数据结构保存)
处理:
–遍历(什么遍历方式)
–词法规则
输出:单词流(什么输出形式)
–二元组
单词类别:
1.标识符(10)
2.无符号数(11)
3.保留字(一词一码)
4.运算符(一词一码)
5.界符(一词一码)
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<= |
21 |
|
do |
5 |
<> |
22 |
|
end |
6 |
> |
23 |
|
l(l|d)* |
10 |
>= |
24 |
|
dd* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
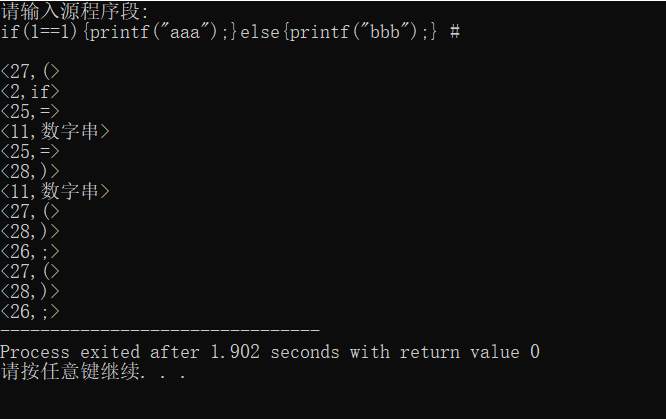
以下是我用c语言写的词法分析程序:
#include<stdio.h> #include<stdlib.h> #include<string.h> typedef struct { int key; char *value; }HASH; HASH hash[100]; char str[1000];//存储输入语句数组 char ch;//存储源程序段 int j=0;// hash[100] 的下标 int Long=0;//str[]的下标 char word[10];//存储单词的容器 char num[10];//存储数字的容器 void danzifu(char Str[]){ int i,p;//循环用的下标 int k=0;// word[10] 的下标 int h=0;// num[10] 的下标 bool flag=false; for(i=0;i<Long;i++){ if(Str[i]>='a'&&Str[i]<='z'){ word[k]=Str[i];//if(1==1){printf("aaa");}else{printf("bbb");} # k++; }else{ if(strcmp(word,"begin")==0){ hash[j].key=1; hash[j].value="begin";j++; }else if(strcmp(word,"if")==0){ hash[j].key=2; hash[j].value="if";j++; }else if(strcmp(word,"then")==0){ hash[j].key=3; hash[j].value="then";j++; }else if(strcmp(word,"while")==0){ hash[j].key=4; hash[j].value="while";j++; }else if(strcmp(word,"do")==0){ hash[j].key=5; hash[j].value="do";j++; }else if(strcmp(word,"end")==0){ hash[j].key=6; hash[j].value="end";j++; }else if(word[0]>='a'&&Str[i]<=word[0]){ hash[j].key=10; hash[j].value="字母串";j++; } k=0; for(p=0;p<10;p++){ word[p]='\0'; } } if(Str[i]>='0'&&Str[i]<='9'){ num[h]=Str[i]; h++; flag=true; }else{ if(flag){ // hash[j].key=11; hash[j].value=num;j++; hash[j].key=11; hash[j].value="数字串";j++; h=0; num[10]=NULL; flag=false; } } switch(Str[i]){ case '+': hash[j].key=13; hash[j].value="+";j++;break; case '-': hash[j].key=14; hash[j].value="-";j++;break; case '*': hash[j].key=15; hash[j].value="*";j++;break; case '/': hash[j].key=16; hash[j].value="/";j++;break; case ':': if(Str[++i]=='='){ hash[j].key=18; hash[j].value=":=";j++; }else{ hash[j].key=17; hash[j].value=":";j++; i--; } break; case '<': if(Str[++i]=='='){ hash[j].key=21; hash[j].value="<=";j++; }else if(Str[i]=='>'){ hash[j].key=22; hash[j].value="<>";j++; }else{ hash[j].key=20; hash[j].value="<";j++; i--; } break; case '>': if(Str[++i]=='='){ hash[j].key=24; hash[j].value=">=";j++; }else{ hash[j].key=23; hash[j].value=">";j++; i--; } break; case '=': hash[j].key=25; hash[j].value="=";j++;break; case ';': hash[j].key=26; hash[j].value=";";j++;break; case '(': hash[j].key=27; hash[j].value="(";j++;break; case ')': hash[j].key=28; hash[j].value=")";j++;break; case '#': hash[j].key=0; hash[j].value="#";j++;break; } } } main(){ printf("请输入源程序段:\n"); do{ ch=getchar(); str[Long++]=ch; } while(ch!='#'); // printf("\n%s",str); danzifu(str); int k=0; while(hash[k].key!=0){ printf("\n<%d,%s>",hash[k].key,hash[k].value); k++; } }
运行结果如图: