GAN实战笔记——第一章GAN简介
GAN简介
一、什么是GAN
GAN是一类由两个同时训练的模型组成的机器学习技术:一个是生成器,训练其生成伪数据:另一个是判别器,训练其从真实数据中识别伪数据。
- 生成(generative)一词预示着模型的总目标——生成新数据。GAN通过学习生成的数据取决于所选择的训练集,例如,如果我们想用GAN合成一幅看起来像达・芬奇作品的画作,就得用达·芬奇的作品作为训练集。
- 对抗(adversarial)一词则是指构成GAN框架的两个动态博弈、竞争的模型:生成器和判别器。生成器的目标是生成与训练集中的真实数据无法区分的伪数据——在刚才的示例中这就意味着能够创作出和达・芬奇画作一样的绘画作品。判别器的目标是能辨别出哪些是来自训练集的真实数据,哪些是来自生成器的伪数据。也就是说,判别器充当着艺术品鉴定专家的角色,评估被认为是达·芬奇画作的作品的真实性。这两个网络不断新地“斗智斗勇”,试图互相欺骗:生成器生成的伪数据越逼真,判别器辨别真伪的能力就要越强。
- 网络(network)一词表示最常用于生成器和判别器的一类机器学习模型:神经网络。依据GAN实现的复杂程度,这些网络包括从最简单的前馈神经网络到卷积神经网络以及更为复杂的变体。
二、GAN是如何工作的
还有一个比喻经常用来形容GAN,假币制造者(生成器)和试图逮捕他的侦探(判别器)——假钞看起来越真实,就需要越好的侦探才能辨别出他们,反之亦然。
用更专业的术语来说,生成器的目标是生成能最大程度有效捕捉训练集特征的样本,以至于生成出的样本与训练数据别无二致。生成器可以看作一个反向的对象识别模型——对象识别算法学习图像中的模式,以期能够识别图像的内容。生成器不是去识别这些模式,而是要学会从头开始学习创建它们,实际上,生成器的输入通常不过是一个随机数向量。
生成器通过从判别器的分类结果中接收反馈来不断学习。判别器的目标是判断一个特定的样本是真的(来自训练集)还是假的(由生成器生成)。因此,每当判别器“上当受骗”将假的图像错判为真实图像时,生成器就会知道自己做得很好:相反,每当判别器正确地将生成器生成的假图像辨别出来时,生成器就会收到需要继续改进的反馈。
判别器也会不断地改善,像其他分类器一样,它会从预测标签与真实标签(真或假)之间的偏差中学习。所以随着生成器能更好地生成更逼真的数据,判别器也能更好地辨别真假数据,两个网络都在同时不断地改进着。
表1.1 生成器和判别器的关键信息
| 生成器 | 判别器 | |
|---|---|---|
| 输入 | 一个随机数向量 | 判别器的输入有两个来源:来自训练集的真实样本和来自生成器的伪样本 |
| 输出 | 尽可能令人信服的伪样本 | 预测输入样本是真实的概率 |
| 目标 | 生成与训练集中数据别无二致的伪数据 | 区分来自生成器的伪样本和来自训练集的真实样本 |
三、GAN的结构
假定我们的目标是教GAN生成逼真的手写数字。GAN的核心结构如下图所示。
让我们看看其中的细节。
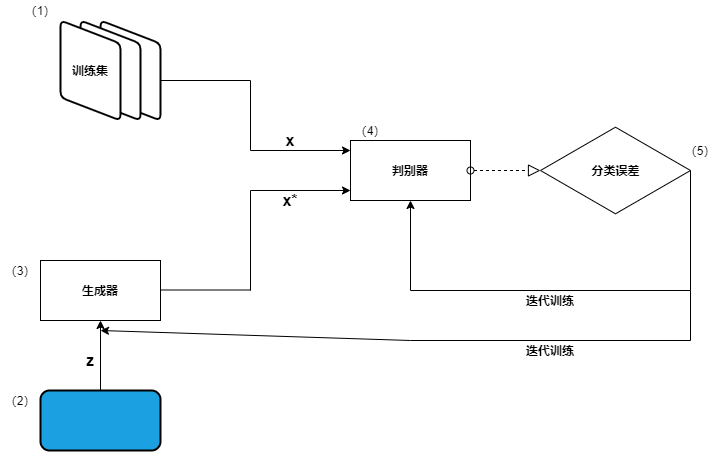
(1) 训练数据集——包含真实样本的数据集,是我们希望生成器能以近乎完美的质量去学习模仿的数据。在这个示例中,数据集由手写数字的图像组成。该数据集用作判别器网络的输入(\(x\))。
(2) 随机噪声向量——生成器网络的初始输入(z)。此输入是一个由随机数组成的向量,生成器将其用作合成伪样本的起点。
(3) 生成器网络——生成器接收随机数向量(z)作为输入并输出伪样本(x*)。它的目标是生成和训练数据集中的真实样本别无二致的伪样本。(卷积神经网络)
(4) 判别器网络——判别器接收来自训练集的真实样本(x)或生成器生成的伪样本(x*)作为输入。对每个样本,判别器会进行判定并输出其为真实的概率。(反卷积神经网络)
(5) 迭代训练/调优——对于每个判别器的预测,我们会衡量它效果有多好——就像对常规的分类器一样——并用结果反向传播去迭代优化判别器网络和生成网络。
- 更新判别器的权重和偏置,以最大化其分类的精确度(最大化正确预测的概率:x为真,x*为假)。
- 更新生成器的权重和偏置,以最大化判别器将x*误判为真的概率。
3.1 GAN的训练
为了了解GAN各组件的用途,我们首先介绍GAN的训练算法,其次演示训练过程,以便我们能够可以清楚的看到实际的框架图。
GAN训练算法
对于每次训练迭代,执行如下操作。
(1)训练判别器
a.从训练集中随机抽取真实样本x。
b.获取一个新的随机噪声向量z,用生成器网络合成一个伪样本x*。
c.用判别器网络对x和x*进行分类。
d.计算分类误差并反向传播总误差以更新判别器的可训练参数,寻求最小化分类误差。
(2)训练生成器
a.获取一个新的随机噪声向量z,用生成器网络合成一个伪样本x*。
b.用判别器网络对x*进行分类。
c.计算分类误差并反向传播以更新生成器的可训练参数,寻求最大化判别器误差。
结束
GAN训练过程可视化
GAN的训练算法如下图所示,其中的字母表示GAN训练算法中的步骤。
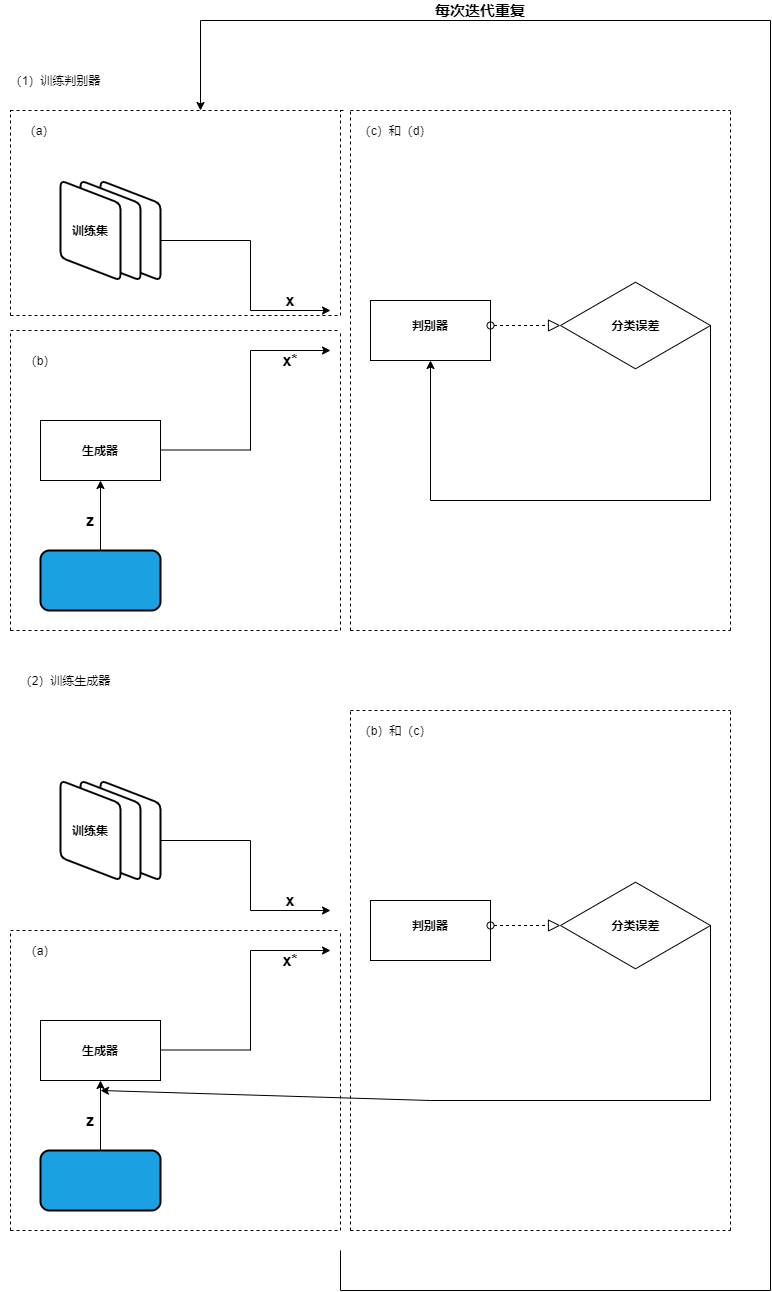
子程序图示说明
(1)训练判别器
a. 从训练集中随机抽取真实样本x。
b. 获取一个新的随机噪声向量z,用生成器网结合成一个伪样本x*。
c. 用判别器网络对x和x*进行分类。
d. 计算分类误差并反向传播总误差以更新判别器的权重和偏置,寻求最小化分类误差。
(2)训练生成器
a. 获取一个新的随机噪声向量z,用生成器网络合成一个伪样本x*。
b.用判别器网络对x*进行分类。
c.计算分类误差并反向传播以更新生成器的可训练参数,寻求最大化判别器误差。
3.2 达到平衡
对于一般的神经网络,我们通常有一个明确的目标去实现以及用来衡量效果。例如,当训练一个分类器时,我们度量在训练集和验证集上的分类误差,一旦发现验证集开始变坏,就停止进程(为了避免过拟合)。在GAN结构中,判别器网络和生成器网络有两个互为竞争对手的目标:一个网络越好,另一个就越差。那么我们如何决定何时停止进程呢?
这其实是一个零和博弈问题,即一方的收益等于另一方的损失。当一方提高一定程度时,另一方会恶化同样的程度。零和博弈都有一个纳什均衡点,那就是任何一方无论怎么努力都不能改善他们的处境或结果。
当满足以下条件时,GAN达到纳什均衡点。
(1)生成器生成的伪样本与训练集中的真实数据别无二致。
(2)判别器所能做的只是随机猜测一个特定的样本是真的还是假的(也就是说,猜测一个示例为真的概率是50%)。
让我们来解释为何会出现这种情况。当每一个伪样本(x*)与来自训练集的真实样本无法区分时,判别器用任何手段都无法区分它们。因为判别器接收到的样本有一半是真的,半是假的,所以它所能做的最有用的事情就是抛硬币,以50%的概率把每个样本分为真和假。
同样,生成器也处于这样一个点上,它不能从进一步的调优中获得任何提高了。因为生成器生成的样本早已和真实样本无法区分了,以至于对随机噪声向量(z)转换为伪样本(x)的过程做出哪怕一丁点儿改变,也可能给判别器提供从真实样本中辨别出伪样本的机会,从而使生成器变得更糟。
当达到纳什均衡时,GAN就被认为是收敛的。这是一个棘手的问题,在实践中,由于在非凸博弈中实现收敛所涉及的巨大复杂性,几乎不可能达到GAN的纳什均衡。实际上,GAN的收敛仍是GAN研究中最重要的开放性问题之一。
四、小结
- GAN是一种利用两个神经网络之间的动态竞争来合成真实数据样本的深度学习技术,例如能合成具有照片级真实感的虚假图像。构成一个完整GAN的两个网络如下:
- 生成器,其目标是通过生成与训练数据集别无二致的数据来欺骗判别器;
- 判别器,其目标是正确区分来自训练数据集的真实数据和由生成器生成的伪数据。

