字符串、文件操作,英文词频统计预处理
该作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2646
1.字符串操作:
解析身份证号:生日、性别、出生地
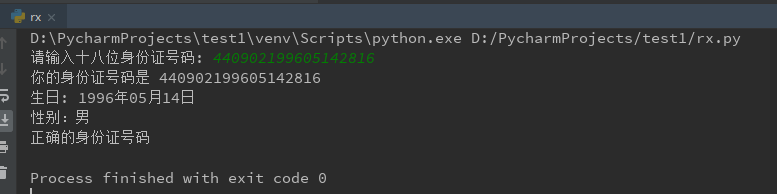
ID=input('请输入十八位身份证号码: ')
if len(ID)==18:
print("你的身份证号码是 "+ID)
else:
print("错误的身份证号码")
ID_add=ID[0:6]
ID_birth=ID[6:14]
ID_sex=ID[14:17]
ID_check=ID[17]
#ID_add是身份证中的区域代码,如果有一个行政区划代码字典,就可以用获取大致地址#
year=ID_birth[0:4]
moon=ID_birth[4:6]
day=ID_birth[6:8]
print("生日: "+year+'年'+moon+'月'+day+'日')
if int(ID_sex)%2==0:
print('性别:女')
else:
print('性别:男')
#此部分应为错误判断,如果错误就不应有上面的输出,如何实现?#
W=[7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2]
ID_num=[18,17,16,15,14,13,12,11,10,9,8,7,6,5,4,3,2]
ID_CHECK=['1','0','X','9','8','7','6','5','4','3','2']
ID_aXw=0
for i in range(len(W)):
ID_aXw=ID_aXw+int(ID[i])*W[i]
ID_Check=ID_aXw%11
if ID_check==ID_CHECK[ID_Check]:
print('正确的身份证号码')
else:
print('错误的身份证号码')
运行效果
凯撒密码编码与解码
在密码学中,我们把想要加密的消息叫做明文(plain text)。把明文转换成加密后的消息叫做对明文加密(encrypting),明文加密后变成(cipher text)。
凯撒密码的密钥是1到26之间的一个数字。除非知道这个键(即用于加密消息的数字),否则无法对这个保密的代码进行解密。凯撒密码是人类最早发明的密码之一,原理是获取消息中的每个字母,并用一个“移位后的”字母来代替它,如果把字母A移动1格,就会得到字母B,移动两格,就会得到字母C。
MAX_KEY_SIZE = 26 def getMode(): while True: print('请选择加密或解密模式,或者选择暴力破解:') print('加密:encrypt(e)') print('解密:decrypt(d)') print('暴力破解:brute(b)') mode = input().lower() if mode in 'encrypt e decrypt d brute b'.split(): return mode else: print('请输入"encrypt"或"e"或"decrypt"或"d"或"brute"或"b"!') def getMessage(): print('请输入你的信息:') return input() def getKey(): key = 0 while True: print('请输入密钥数字(1-%s)' % (MAX_KEY_SIZE)) key = int(input()) if (key >=1 and key <= MAX_KEY_SIZE): return key def getTranslatedMessage(mode, message, key): if mode[0] == 'd': key = -key translated = '' for symbol in message: if symbol.isalpha(): num = ord(symbol) num += key if symbol.isupper(): if num > ord('Z'): num -= 26 elif num < ord('A'): num += 26 elif symbol.islower(): if num > ord('z'): num -= 26 elif num < ord('a'): num += 26 translated += chr(num) else: translated += symbol return translated mode = getMode() message = getMessage() if mode[0] != 'b': key = getKey() print('你要翻译的信息是:') if mode[0] != 'b': print(getTranslatedMessage(mode, message, key)) else: for key in range(1, MAX_KEY_SIZE + 1): print(key, getTranslatedMessage('decrypt', message, key))
运行效果:


网址观察与批量生成
print(r"搜索结果如下"); url="https://list.jd.com/list.html?tid=1006238" s="&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=" print("第1页网址为{}".format(url)); for i in range(5): arg=url+s+str(i*44); print("第{}页网址为{}".format(i+2,url));
2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说,保存为utf8文件。
- 从文件读出字符串。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
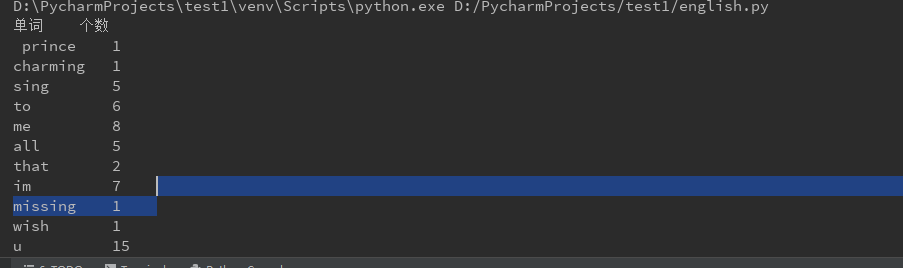
fo = open(r'D:\PycharmProjects\test1\music.txt', encoding='utf-8') text = fo.read() fo.close() text = text.lower() # 转换成小写 sep = ",.?!:''\n'" result = {} for s in sep: # 去除各种符号,用空格代替 text = text.replace(s, ' ') a = text.split(' ') # 分隔出单词 print("单词 个数") for w in a: if w != '': print("{:<10} {:<5}".format(w, text.count(w))) # 格式化输出
运行结果: