
spark学习之Lambda架构日志分析流水线
单机运行
一、环境准备
Flume 1.6.0
Hadoop 2.6.0
Spark 1.6.0
Java version 1.8.0_73
Kafka 2.11-0.9.0.1
zookeeper 3.4.6
二、配置
spark和hadoop配置见()
kafka和zookeeper使用默认配置
1、kafka配置
启动
bin/kafka-server-start.sh config/server.properties
创建一个test的topic
bin/kafka-topics.sh --create --zookeeper vm: 2181 --replication-factor 1 --partitions 1 --topic test
2、flume配置文件,新建一个dh.conf文件,配置如下
其中发送的内容为apache-tomcat-8.0.32的访问日志
#define c1 agent1.channels.c1.type = memory agent1.channels.c1.capacity = 2000000 agent1.channels.c1.transactionCapacity = 100 #define c1 end #define c2 agent1.channels.c2.type = memory agent1.channels.c2.capacity = 2000000 agent1.channels.c2.transactionCapacity = 100 #define c2 end #define source monitor a file agent1.sources.avro-s.type = exec agent1.sources.avro-s.command = tail -f -n+1 /usr/local/hong/apache-tomcat-8.0.32/logs/localhost_access_log.2016-02-19.txt agent1.sources.avro-s.channels = c1 c2 agent1.sources.avro-s.threads = 5 # send to hadoop agent1.sinks.log-hdfs.channel = c1 agent1.sinks.log-hdfs.type = hdfs agent1.sinks.log-hdfs.hdfs.path = hdfs://vm:9000/flume agent1.sinks.log-hdfs.hdfs.writeFormat = Text agent1.sinks.log-hdfs.hdfs.fileType = DataStream agent1.sinks.log-hdfs.hdfs.rollInterval = 0 agent1.sinks.log-hdfs.hdfs.rollSize = 1000000 agent1.sinks.log-hdfs.hdfs.rollCount = 0 agent1.sinks.log-hdfs.hdfs.batchSize = 1000 agent1.sinks.log-hdfs.hdfs.txnEventMax = 1000 agent1.sinks.log-hdfs.hdfs.callTimeout = 60000 agent1.sinks.log-hdfs.hdfs.appendTimeout = 60000 #send to kafaka agent1.sinks.log-sink2.type = org.apache.flume.sink.kafka.KafkaSink agent1.sinks.log-sink2.topic = test agent1.sinks.log-sink2.brokerList = vm:9092 agent1.sinks.log-sink2.requiredAcks = 1 agent1.sinks.log-sink2.batchSize = 20 agent1.sinks.log-sink2.channel = c2 # Finally, now that we've defined all of our components, tell # agent1 which ones we want to activate. agent1.channels = c1 c2 agent1.sources = avro-s agent1.sinks = log-hdfs log-sink2
三、测试flume发送
1、启动hdfs
./start-dfs.sh
2、启动zookeeper
./zkServer.sh start
3、kafka的见上面
4、启动flume
flume-ng agent -c conf -f dh.conf -n agent1 -Dflume.root.logger=INFO,console
四、测试效果
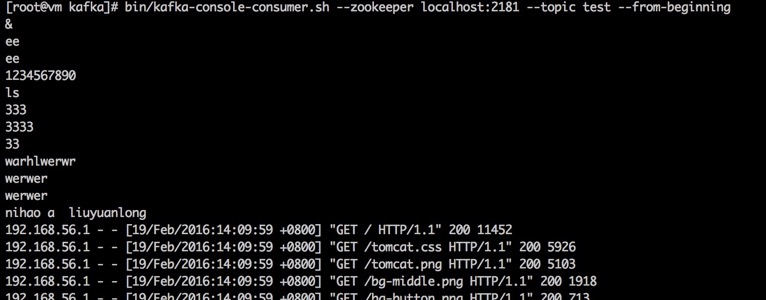
运行kafka的consumer查看
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
可以看到如下内容说明kafka和flume的配置成功
访问hdfs查看如果/flume可以下载文件进行查看验证hdfs发送是否成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号