
C++基础总结
1程序内存模型
1.1 内存分区模型
C++程序在执行时,将内存大方向划分为4个区域
- 代码区:存放函数体的二进制代码,由操作系统进行管理的
- 全局区:存放全局变量和静态变量以及常量
- 栈区:由编译器自动分配释放, 存放函数的参数值,局部变量等
- 堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区意义:
不同区域存放的数据,赋予不同的生命周期, 给我们更大的灵活编程
1.2 程序运行前
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
- 代码区:
- 存放 CPU 执行的机器指令
- 代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
- 代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
- 全局区:
- 全局变量和静态变量存放在此
- 全局区还包含了常量区, 字符串常量和其他常量也存放在此
- 该区域的数据在程序结束后由操作系统释放
总结:
- C++中在程序运行前分为全局区和代码区
- 代码区特点是共享和只读
- 全局区中存放全局变量、静态变量、常量
- 常量区中存放 const修饰的全局常量 和 字符串常量
1.3 程序运行后
-
栈区:
由编译器自动分配释放, 存放函数的参数值,局部变量等
注意事项:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放 -
堆区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
总结:
- 堆区数据由程序员管理开辟和释放
- 堆区数据利用new关键字进行开辟内存
1.4 new操作符
- C++中利用
new操作符在堆区开辟数据 - 堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符
delete - 语法:
new 数据类型 - 利用new创建的数据,会返回该数据对应的类型的指针
2 类和对象
C++面向对象的三大特性为:封装、继承、多态
2.1 封装
2.1.1 封装的意义
封装是C++面向对象三大特性之一
封装的意义:
-
将属性和行为作为一个整体,表现需要处理的的事物
class 类名{ 访问权限: 属性 / 行为 };
-
将属性和行为加以权限控制
| 权限名 | 类内 | 类外 |
|---|---|---|
| public | 可访问 | 可访问 |
| protected | 可访问 | 不可访问 |
| private | 可访问 | 不可访问 |
2.1.2 struct和class区别
在C++中 struct和class唯一的区别就在于 默认的访问权限不同
区别:
- struct 默认权限为公共
- class 默认权限为私有
2.1.3 成员属性设置为私有
- 优点1:将所有成员属性设置为私有,可以自己控制读写权限
- 优点2:对于写权限,我们可以检测数据的有效性
2.1.4 构造函数和析构函数
- 构造函数:主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
- 析构函数:主要作用在于对象销毁前系统自动调用,执行一些清理工作。
构造函数语法:类名(){}
- 构造函数,没有返回值也不写void
- 函数名称与类名相同
- 构造函数可以有参数,因此可以发生重载
- 程序在调用对象时候会自动调用构造,无须手动调用,而且只会调用一次
析构函数语法: ~类名(){}
- 析构函数,没有返回值也不写void
- 函数名称与类名相同,在名称前加上符号 ~
- 析构函数不可以有参数,因此不可以发生重载
- 程序在对象销毁前会自动调用析构,无须手动调用,而且只会调用一次
2.1.5 构造函数
- 分类
按参数分为: 有参构造和无参构造
按类型分为: 普通构造和拷贝构造
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int a) {
age = a;
cout << "有参构造函数!" << endl;
}
//拷贝构造函数
Person(const Person& p) {
age = p.age;
cout << "拷贝构造函数!" << endl;
}
//析构函数
~Person() {
cout << "析构函数!" << endl;
}
public:
int age;
};
//2、构造函数的调用
//调用无参构造函数
void test01() {
Person p; //调用无参构造函数
}
//调用有参的构造函数
void test02() {
//2.1 括号法,常用
Person p1(10);
//注意1:调用无参构造函数不能加括号,如果加了编译器认为这是一个函数声明
//Person p2();
//2.2 显式法
Person p2 = Person(10);
Person p3 = Person(p2);
//Person(10)单独写就是匿名对象 当前行结束之后,马上析构
//2.3 隐式转换法
Person p4 = 10; // Person p4 = Person(10);
Person p5 = p4; // Person p5 = Person(p4);
//注意2:不能利用 拷贝构造函数 初始化匿名对象 编译器认为是对象声明
//Person p5(p4);
}
-
构造函数调用规则
默认情况下,c++编译器至少给一个类添加3个函数
- 默认构造函数(无参,函数体为空)
- 默认析构函数(无参,函数体为空)
- 默认拷贝构造函数,对属性进行值拷贝
构造函数调用规则如下:
- 如果用户定义有参构造函数,c++不在提供默认无参构造,但是会提供默认拷贝构造
- 如果用户定义拷贝构造函数,c++不会再提供其他构造函数(此时需要用户自己定义构造函数,否则会报错)
-
拷贝构造函数调用时机
C++中拷贝构造函数调用时机通常有三种情况
- 使用一个已经创建完毕的对象来初始化一个新对象
- 值传递的方式给函数参数传值
- 以值方式返回局部对象
-
深拷贝与浅拷贝
-
浅拷贝:简单的赋值拷贝操作
-
深拷贝:在堆区重新申请空间,进行拷贝操作
总结:如果属性有在堆区开辟的,一定要自己提供拷贝构造函数,防止浅拷贝带来的问题
-
-
初始化列表
C++提供了初始化列表语法,用来初始化属性
语法:
构造函数():属性1(值1),属性2(值2)... {}例子:
class Person { public: //传统方式初始化 //Person(int a, int b, int c) { // m_A = a; // m_B = b; // m_C = c; //} //初始化列表方式初始化 Person(int a, int b, int c) :m_A(a), m_B(b), m_C(c) {} void PrintPerson() { cout << "mA:" << m_A << endl; cout << "mB:" << m_B << endl; cout << "mC:" << m_C << endl; } private: int m_A; int m_B; int m_C; };调用:
Person p(1, 2, 3); -
类对象作为类成员
-
C++类中的成员可以是另一个类的对象,我们称该成员为 对象成员
-
构造和析构的顺序:
当类中成员是其他类对象时,我们称该成员为 对象成员
构造的顺序是 :先调用对象成员的构造,再调用本类构造
析构顺序与构造相反
-
-
静态成员
静态成员就是在成员变量和成员函数前加上关键字static,称为静态成员
- 静态成员变量
- 所有对象共享同一份数据
- 在编译阶段分配内存
- 类内声明,类外初始化
- 静态成员函数
- 所有对象共享同一个函数
- 静态成员函数只能访问静态成员变量
静态成员变量两种访问方式
- 通过对象,如
Person p1;p1.func(); - 通过类名,如
Person::func();
- 静态成员变量
-
C++对象模型和this指针
-
在C++中,类内的成员变量和成员函数分开存储,只有非静态成员变量才属于类的对象上。函数不占对象空间,所有函数共享一个函数实例
-
this指针概念
- c++通过提供特殊的对象指针,this指针。解决代码是如何区分那个对象调用自己的问题。this指针指向被调用的成员函数所属的对象,this指向的是对象。
-
this指针的用途
- 当形参和成员变量同名时,可用this指针来区分
- 在类的非静态成员函数中返回对象本身,可使用return *this
-
-
空指针访问成员函数
C++中空指针也是可以调用成员函数的,但是也要注意有没有用到this指针,如果用到this指针,需要加以判断保证代码的健壮性。
- 空指针,可以调用成员函数
- 如果成员函数中用到了this指针,不能调用成员函数
//ShowClassName()无this,ShowPerson()有this指针 Person * p = NULL; p->ShowClassName(); //对 p->ShowPerson(); //错 -
const修饰成员函数
常函数:
- 成员函数后加const后我们称为这个函数为常函数
- 常函数内不可以修改成员属性
- 成员属性声明时加关键字mutable后,在常函数中依然可以修改
常对象:
- 声明对象前加const称该对象为常对象
- 常对象只能调用常函数
-
友元
友元的目的就是让一个函数或者类 访问另一个类中私有成员
友元关键字
friend- 全局函数做友元
class buliding { friend void goodGay(Building * building); private: string m_BedRoom; //卧室 }; void goodGay(Building * building){ cout << building->m_BedRoom << endl; }- 类做友元
class Building{ friend class goodGay; }- 成员函数做友元
class Building{ friend class goodGay::visit(); } -
运算符重载
运算符重载概念:对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型
-
加号运算符重载
作用:实现两个自定义数据类型相加的运算
总结1:对于内置的数据类型的表达式的的运算符是不可能改变的
总结2:不要滥用运算符重载 -
左移运算符重载
作用:可以输出自定义数据类型
通过全局函数实现左移重载,ostream对象只能有一个
总结:重载左移运算符配合友元可以实现输出自定义数据类型
-
递增运算符重载
作用: 通过重载递增运算符,实现自己的整型数据
总结: 前置递增返回引用,后置递增返回值
-
赋值运算符重载
c++编译器至少给一个类添加4个函数
- 默认构造函数(无参,函数体为空)
- 默认析构函数(无参,函数体为空)
- 默认拷贝构造函数,对属性进行值拷贝
- 赋值运算符 operator=, 对属性进行值拷贝
eg : 可以利用重定义赋值
=号来进行深拷贝Person& operator=(Person &p) { if (m_Age != NULL) { delete m_Age; m_Age = NULL; } //编译器提供的代码是浅拷贝 //m_Age = p.m_Age; //提供深拷贝 解决浅拷贝的问题 m_Age = new int(*p.m_Age); //返回自身 return *this; }如果类中有属性指向堆区,做赋值操作时也会出现深浅拷贝问题
-
关系运算符重载
eg :
bool operator==(Person & p)作用:重载关系运算符,可以让两个自定义类型对象进行对比操作
-
函数调用运算符重载
eg :
void operator()(string text)- 函数调用运算符 () 也可以重载
- 由于重载后使用的方式非常像函数的调用,因此称为仿函数
- 仿函数没有固定写法,非常灵活
-
2.2 继承
有些类与类之间存在特殊的关系,比如动物下面有狗类和猪类,狗类下面有哈士奇,京巴类等。定义这些类时,下级别的成员除了拥有上一级的共性,还有自己的特性,此时考虑利用继承的技术,减少重复代码。
2.2.1 基础基本语法
总结:
继承的好处:可以减少重复的代码
class A : public B;
A 类称为子类 或 派生类
B 类称为父类 或 基类
派生类中的成员,包含两大部分:
一类是从基类继承过来的,一类是自己增加的成员。
从基类继承过过来的表现其共性,而新增的成员体现了其个性。
2.2.2 基础方式
继承的语法:class 子类 : 继承方式 父类
继承方式一共有三种:
| 继承方式 | 基础语法 | 父类public权限 | 父类protected权限 | 父类privite权限 |
|---|---|---|---|---|
| 公共继承 | class Son1:public Base1 |
可访问 public权限 | 可访问 protected权限 | 不可访问 |
| 保护继承 | class Son2:protected Base2 |
可访问 protected权限 | 可访问 protected权限 | 不可访问 |
| 私有继承 | class Son3:private Base3 |
可访问 private权限 | 可访问 private权限 | 不可访问 |
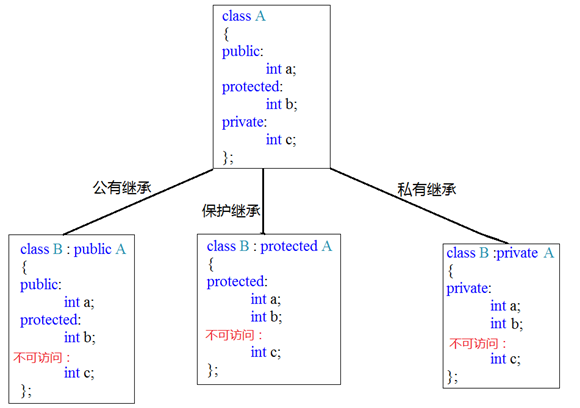
2.2.3 继承中的对象模型
父类中除了共有和保护成员外,私有成员也是被子类继承下去了,只是由编译器给隐藏后访问不到
2.2.4 继承中构造和析构顺序
子类继承父类后,当创建子类对象,也会调用父类的构造函数
继承中 先调用父类构造函数,再调用子类构造函数,析构顺序与构造相反
即 父构造 -> 子构造-> 子析构 -> 父析构
2.2.5 继承同名成员处理方式
- 子类对象可以直接访问到子类中同名成员
- 子类对象加作用域可以访问到父类同名成员
- 当子类与父类拥有同名的成员函数,子类会隐藏父类中同名成员函数,加作用域可以访问到父类中同名函数
2.2.6 继承同名静态成员处理方式
问题:继承中同名的静态成员在子类对象上如何进行访问?
静态成员和非静态成员出现同名,处理方式一致
- 访问子类同名成员 直接访问即可
- 访问父类同名成员 需要加作用域
总结:同名静态成员处理方式和非静态处理方式一样,只不过有两种访问的方式(通过对象 和 通过类名)
2.2.7 多继承语法
C++允许一个类继承多个类
语法: class 子类 :继承方式 父类1 , 继承方式 父类2...
多继承可能会引发父类中有同名成员出现,需要加作用域区分
C++实际开发中不建议用多继承
2.2.8 菱形继承
-
菱形继承概念:
当两个派生类继承同一个基类,又有某个类同时继承者两个派生类时这种继承被称为菱形继承,或者钻石继承 -
菱形继承产生问题:是共同的子类继承两份相同的数据,导致资源浪费以及毫无意义
-
解决方法:利用虚继承可以解决菱形继承问题
class Sheep : virtual public Animal {};
class Tuo : virtual public Animal {};
class SheepTuo : public Sheep, public Tuo {};
2.3 多态
多态分为两类
- 静态多态: 函数重载 和 运算符重载属于静态多态,复用函数名
- 动态多态: 派生类和虚函数实现运行时多态
静态多态和动态多态区别:
- 静态多态的函数地址早绑定 - 编译阶段确定函数地址
- 动态多态的函数地址晚绑定 - 运行阶段确定函数地址
总结:
多态满足条件
- 有继承关系
- 子类重写父类中的虚函数
多态使用条件
- 父类指针或引用指向子类对象
重写:函数返回值类型 函数名 参数列表 完全一致称为重写
- 多态的优点:
- 代码组织结构清晰
- 可读性强
- 利于前期和后期的扩展以及维护
2.3.1 纯虚函数和抽象类
在多态中,通常父类中虚函数的实现是毫无意义的,主要都是调用子类重写的内容,因此可以将虚函数改为纯虚函数
纯虚函数语法:virtual 返回值类型 函数名 (参数列表)= 0 ;
比如:
class Base
{
public:
virtual void func() = 0; //纯虚函数
};
当类中有了纯虚函数,这个类也称为抽象类,如上述代码中的Base类
抽象类特点:
- 无法实例化对象
- 子类必须重写抽象类中的纯虚函数,否则也属于抽象类
2.3.2 虚析构和纯虚析构
多态使用时,如果子类中有属性开辟到堆区,那么父类指针在释放时无法调用到子类的析构代码
- 解决方式:将父类中的析构函数改为虚析构或者纯虚析构
虚析构和纯虚析构共性:
- 可以解决父类指针释放子类对象
- 都需要有具体的函数实现
虚析构和纯虚析构区别:
- 如果是纯虚析构,该类属于抽象类,无法实例化对象
总结:
1. 虚析构或纯虚析构就是用来解决通过父类指针释放子类对象
2. 如果子类中没有堆区数据,可以不写为虚析构或纯虚析构
3. 拥有纯虚析构函数的类也属于抽象类
3 模板
3.1 模板概念
模板就是建立通用的模具,大大提高复用性
模板的特点:
- 模板不可以直接使用,它只是一个框架
- 模板的通用并不是万能的
3.2 函数模板
-
C++另一种编程思想称为 泛型编程 ,主要利用的技术就是模板
-
C++提供两种模板机制:函数模板和类模板
3.2.1 函数模板语法
建立一个通用函数,其函数返回值类型和形参类型可以不具体制定,用一个虚拟的类型来代表。
语法:
template<typename T>
函数声明或定义
解释:
template --- 声明创建模板
typename --- 表面其后面的符号是一种数据类型,可以用class代替
T --- 通用的数据类型,名称可以替换,通常为大写字母
例子:
//实现交换两个元素
template<typename T>
void mySwap(T& a, T& b)
{
T temp = a;
a = b;
b = temp;
}
使用:
//1、自动类型推导
mySwap(a, b);
//2、显示指定类型
mySwap<int>(a, b);
总结:
- 函数模板利用关键字 template
- 使用函数模板有两种方式:自动类型推导、显示指定类型
- 模板的目的是为了提高复用性,将类型参数化
3.2.2 函数模板注意事项
-
自动类型推导,必须推导出一致的数据类型T,才可以使用
-
模板必须要确定出T的数据类型,才可以使用
3.2.3 普通函数与函数模板的区别
- 普通函数调用时可以发生自动类型转换(隐式类型转换)
- 函数模板调用时,如果利用自动类型推导,不会发生隐式类型转换
- 如果利用显示指定类型的方式,可以发生隐式类型转换
3.2.4 普通函数与函数模板的调用规则
- 如果函数模板和普通函数都可以实现,优先调用普通函数
- 可以通过空模板参数列表来强制调用函数模板
- 函数模板也可以发生重载
- 如果函数模板可以产生更好的匹配,优先调用函数模板
3.2.5 模板的局限性
- 利用具体化的模板,可以解决自定义类型的通用化
- 学习模板并不是为了写模板,而是在STL能够运用系统提供的模板
如:
class Person{...};
template<class T>
bool myCompare(T& a, T& b){...}
template<> bool myCompare(Person &p1, Person &p2){...}
3.3 类模板
3.3.1 类模板语法
- 建立一个通用类,类中的成员 数据类型可以不具体制定,用一个虚拟的类型来代表。
语法:
template<typename T>
类
解释:
template --- 声明创建模板
typename --- 表面其后面的符号是一种数据类型,可以用class代替
T --- 通用的数据类型,名称可以替换,通常为大写字母
3.3.2 类模板与函数模板区别
类模板与函数模板区别主要有两点:
- 类模板没有自动类型推导的使用方式
- 类模板在模板参数列表中可以有默认参数
3.3.3 类模板中成员函数创建时机
- 普通类中的成员函数一开始就可以创建
- 类模板中的成员函数在调用时才创建
3.3.4 类模板对象做函数参数
- 指定传入的类型 --- 直接显示对象的数据类型
- 参数模板化 --- 将对象中的参数变为模板进行传递
- 整个类模板化 --- 将这个对象类型 模板化进行传递
3.3.5 类模板与继承
- 当子类继承的父类是一个类模板时,子类在声明的时候,要指定出父类中T的类型
- 如果不指定,编译器无法给子类分配内存
- 如果想灵活指定出父类中T的类型,子类也需变为类模板
4 STL
4.1 STL基本概念
4.1.1 简介
- STL(Standard Template Library,标准模板库)
- STL 从广义上分为: 容器(container) 算法(algorithm) 迭代器(iterator)
- 容器和算法之间通过迭代器进行无缝连接。
- STL 几乎所有的代码都采用了模板类或者模板函数
4.1.2 六大组件
STL大体分为六大组件,分别是:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
- 容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据。
- 算法:各种常用的算法,如sort、find、copy、for_each等
- 迭代器:扮演了容器与算法之间的胶合剂。
- 仿函数:行为类似函数,可作为算法的某种策略。
- 适配器:一种用来修饰容器或者仿函数或迭代器接口的东西。
- 空间配置器:负责空间的配置与管理。
4.1.3 STL中容器、算法、迭代器
容器:置物之所也
STL容器就是将运用最广泛的一些数据结构实现
常用的数据结构:数组, 链表,树, 栈, 队列, 集合, 映射表 等
这些容器分为序列式容器和关联式容器两种:
- 序列式容器 : 强调值的排序,序列式容器中的每个元素均有固定的位置。
- 关联式容器 : 二叉树结构,各元素之间没有严格的物理上的顺序关系
算法:问题之解法也
有限的步骤,解决逻辑或数学上的问题,叫做算法(Algorithms)
算法分为:质变算法和非质变算法。
- 质变算法:是指运算过程中会更改区间内的元素的内容。例如拷贝,替换,删除等等
- 非质变算法:是指运算过程中不会更改区间内的元素内容,例如查找、计数、遍历、寻找极值等等
迭代器:容器和算法之间粘合剂
提供一种方法,使之能够依序寻访某个容器所含的各个元素,而又无需暴露该容器的内部表示方式。
每个容器都有自己专属的迭代器
迭代器使用非常类似于指针,但不完全相同
迭代器种类:
| 种类 | 功能 | 支持运算 |
|---|---|---|
| 输入迭代器 | 对数据的只读访问 | 只读,支持++、==、!= |
| 输出迭代器 | 对数据的只写访问 | 只写,支持++ |
| 前向迭代器 | 读写操作,并能向前推进迭代器 | 读写,支持++、==、!= |
| 双向迭代器 | 读写操作,并能向前和向后操作 | 读写,支持++、--, |
| 随机访问迭代器 | 读写操作,可以以跳跃的方式访问任意数据,功能最强的迭代器 | 读写,支持++、--、[n]、-n、<、<=、>、>= |
常用的容器中迭代器种类为双向迭代器,和随机访问迭代器
4.2 常见容器
4.2.1 string
- 本质是一个系统封装好的类
4.2.2 vector
- vector数据结构和数组非常相似,也称为单端数组
动态扩展:
- 并不是在原空间之后续接新空间,而是找更大的内存空间,然后将原数据拷贝新空间,释放原空间
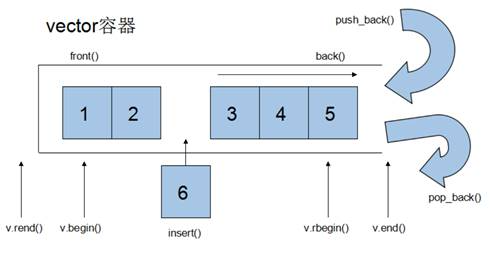
- vector容器的迭代器是支持随机访问的迭代器
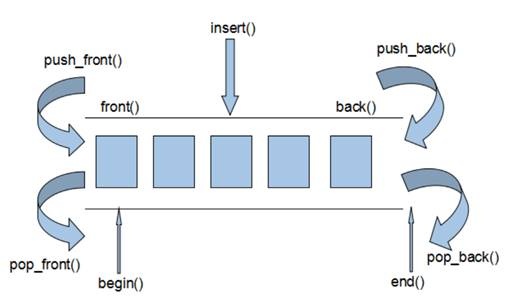
4.2.3 deque
- 双端数组,可以对头端进行插入删除操作
deque与vector区别:
- vector对于头部的插入删除效率低,数据量越大,效率越低
- deque相对而言,对头部的插入删除速度会比vector快
- vector访问元素时的速度会比deque快,这和两者内部实现有关
deque内部工作原理:
deque内部有个中控器,维护每段缓冲区中的内容,缓冲区中存放真实数据
中控器维护的是每个缓冲区的地址,使得使用deque时像一片连续的内存空间
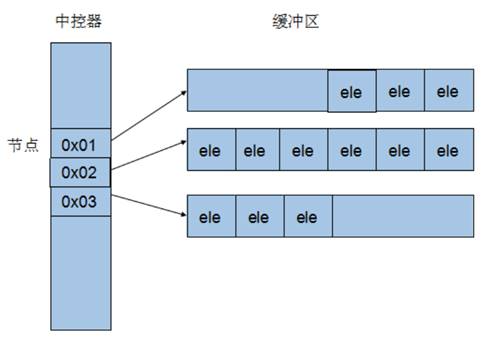
deque容器的迭代器也是支持随机访问的
4.2.4 stack
概念:stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口

栈中只有顶端的元素才可以被外界使用,因此栈不允许有遍历行为
栈中进入数据称为 --- 入栈 push
栈中弹出数据称为 --- 出栈 pop
4.2.5 queue
概念:Queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口
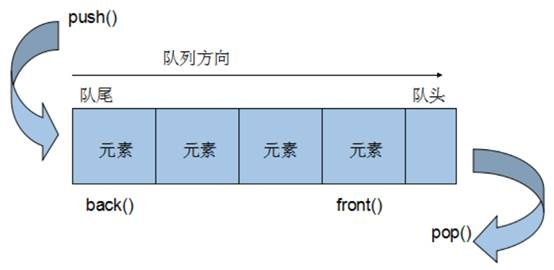
队列容器允许从一端新增元素,从另一端移除元素
队列中只有队头和队尾才可以被外界使用,因此队列不允许有遍历行为
队列中进数据称为 --- 入队 push
队列中出数据称为 --- 出队 pop
4.2.6 list
功能:将数据进行链式存储
链表(list)是一种物理存储单元上非连续的存储结构,数据元素的逻辑顺序是通过链表中的指针链接实现的
链表的组成:链表由一系列结点组成
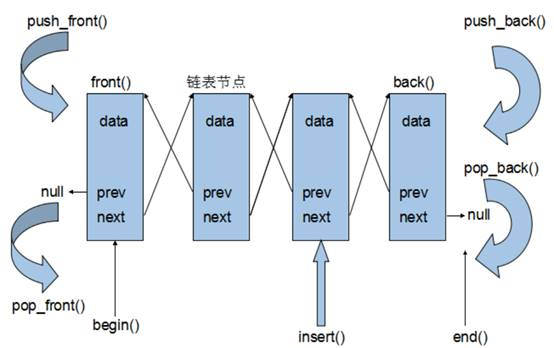
由于链表的存储方式并不是连续的内存空间,因此链表list中的迭代器只支持前移和后移,属于双向迭代器
list的优点:
- 采用动态存储分配,不会造成内存浪费和溢出
- 链表执行插入和删除操作十分方便,修改指针即可,不需要移动大量元素
list的缺点:
- 链表灵活,但是空间(指针域) 和 时间(遍历)额外耗费较大
List有一个重要的性质,插入操作和删除操作都不会造成原有list迭代器的失效,这在vector是不成立的。
总结:STL中List和vector是两个最常被使用的容器,各有优缺点
4.2.7 set/ multiset
-
所有元素都会在插入时自动被排序
-
set/multiset属于关联式容器,底层结构是用二叉树实现。
set和multiset区别:
- set不允许容器中有重复的元素
- multiset允许容器中有重复的元素
4.2.8 map/ multimap
-
map中所有元素都是pair
-
pair中第一个元素为key(键值),起到索引作用,第二个元素为value(实值)
-
所有元素都会根据元素的键值自动排序
-
map/multimap属于关联式容器,底层结构是用二叉树实现。
优点:
- 可以根据key值快速找到value值
map和multimap区别:
- map不允许容器中有重复key值元素
- multimap允许容器中有重复key值元素
本文来自博客园,作者:mobbu,转载请注明原文链接:https://www.cnblogs.com/mobbu/p/17560955.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号