Java-Map集合
一、Map集合体系
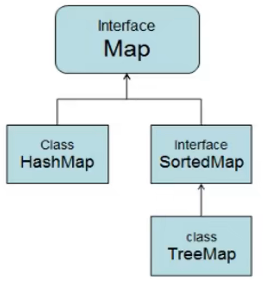

二、Map父接口
- 特点:存储一对数据(Key-Value),无序、无下标,键不可重复,值可重复
- 常用方法:
- V put(K key,V value)// 将对象存入到集合中,关联键值。key值重复则覆盖原值
- Object get(Object key)//根据键获取对应的值
- Set<K> keySet()//返回所有key的Set集合
- Collection<V> values()//返回包含所有值得Collection集合
- Set<Map.Entry<K,V>> entrySet() //键值匹配的Set集合
三、Map接口的使用
使用Map接口创建集合,循环的时候要使用keySet() 或者 entrySet()。
keySet():返回的是Key的一个Set集合。Set集合循环的时候可以用增强For循环(foreach)
EntrySet():把Key和Value封装成Entry,一个Entry就是一个映射对(键值对),返回的类型也是Set集合。循环的时候用增强For
EntrySet()的效率要高于KeySet()。EntrySet里包含了Key和Value,KeySet只包含Key,如果要取Value的值,则还需要循环,所以效率比较低。
package com.monv.map; import java.util.HashMap; import java.util.Map; import java.util.Set; /** * Map接口的使用 * 特点:(1)存储键值对(2)键不能重复,值可以重复(3)无序的 */ public class Demo1 { public static void main(String[] args) { //创建Map集合 因为map是一个接口 所以只能用它的实现类 Map<String,String> map = new HashMap<>(); //1.添加元素 map.put("cn", "中国"); map.put("uk", "英国"); map.put("usa", "美国"); map.put("cn", "zhongguo");//这条会更新第一条记录 System.out.println("元素个数:"+map.size()); System.out.println(map.toString()); //2.删除元素 // map.remove("uk");//使用Key删除 // System.out.println("删除后元素个数:"+map.size()); // System.out.println(map.toString()); //3.遍历【重点】 //3.1使用keySet(); System.out.println("---------keySet()----------"); // Set<String> keyset = map.keySet();//返回的是所有key的Set集合 集合的循环用增强For // for (String key : keyset) { // System.out.println(key+"----"+map.get(key)); // } for (String key : map.keySet()) { System.out.println(key+"----"+map.get(key)); } //3.2使用entrySet() 把每一个key和value封装成entry 一个entry就是一个映射对(键值对) 效率要高些 System.out.println("---------entrySet()----------"); // Set<Map.Entry<String , String>> entrys = map.entrySet(); // for (Map.Entry<String, String> entry : entrys) { // System.out.println(entry.getKey()+"----"+entry.getValue()); // } for (Map.Entry<String, String> entry : map.entrySet()) { System.out.println(entry.getKey()+"----"+entry.getValue()); } //4.判断 System.out.println("-------判断------------"); System.out.println(map.containsKey("cn"));//判断有没有键 System.out.println(map.containsValue("美国"));//判读有没有值 } }
四、Map集合的实现类
1、HashMap【重点】:JDK1.2版本,线程不安全,运行效率快;允许用Null作为Key或是Value
默认构造方法HashMap():构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap
默认加载因子(0.75) :比如现在的容量是100,当存储的数据到达75%的时候,会自动扩容(32 :初始容量的2倍)
源码分析:
存储结构:哈希表(数组+链表+红黑树)
重复依据:键的hashcode()和equals方法
1 static final int DEFAULT_INITIAL_CAPACITY = 16;//默认的初始容量大小 2 static final int MAXIMUM_CAPACITY = 1 << 30;//hashmap数组的最大容量(1左移30位 2的30次方) 3 static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认加载因子 4 static final int TREEIFY_THRESHOLD = 8;//jdk1.8 链表的长度大于8并且数组的长度大于64 则会把链表调整为红黑树(查找效率比较高) 5 static final int UNTREEIFY_THRESHOLS = 6;//jkd1.8 当链表长度小于6时,调整成链表 6 static final int MIN_TREEIFY_CAPACITY = 64;// 数组的最小容量 7 transient Node<K,V>[] table;//哈希表中的数组 8 size;//元素个数
总结:
(1)hashmap刚创建没有添加元素时,table 为NULL、size为0 。目的是为了节省空间,当添加第一个元素时,table的容量为16
(2)当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后大小为原来的2倍。目的是减少调整元素的个数
(3)jdk1.8 当每个链表长度大于8,并且数组元素个数大于等于64时,会调整为红黑树,目的是提高执行效率
(4)jdk 1.8 当链表长度小于6时,调整成链表
(5)jkd 1.8以前,链表是头插入,jdk 1.8以后是尾插入
package com.monv.map; public class Student { private String name; private int stuNO; public Student() { // TODO Auto-generated constructor stub } public Student(String name, int stuNO) { super(); this.name = name; this.stuNO = stuNO; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getStuNO() { return stuNO; } public void setStuNO(int stuNO) { this.stuNO = stuNO; } @Override public String toString() { return "Student [name=" + name + ", stuNO=" + stuNO + "]"; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((name == null) ? 0 : name.hashCode()); result = prime * result + stuNO; return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Student other = (Student) obj; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; if (stuNO != other.stuNO) return false; return true; } } -------------------------------------------- package com.monv.map; import java.util.HashMap; import java.util.Map; /** * HashMap集合的使用 * 存储结构:哈希表(数组+链表+红黑树) * 哈希表使用Key的HashCode和equals来作为判断重复的依据 * @author Administrator * */ public class Demo2 { public static void main(String[] args) { //创建集合 HashMap<Student,String> students = new HashMap<Student,String>(); //1、添加元素 Student s1 = new Student("小明", 2001); Student s2 = new Student("小花", 2002); Student s3 = new Student("小芳", 2003); students.put(s1, "北京"); students.put(s2, "上海"); students.put(s3, "广州"); //这个是可以添加进去的 new Student("小芳", 2003) 是一个新的对象 跟 s3的地址不一样 所以是不同的 可以添加进去 //如果不想添加进去 判断名字和学号相等就认为是相同的元素,则需要重写Student中的方法 HashCode() 和 equals() 方法 students.put(new Student("小芳", 2003), "南京"); System.out.println("元素个数:"+students.size()); System.out.println(students.toString()); //2、删除元素 // students.remove(s1); // System.out.println("删除后元素个数:"+students.size()); //3.循环 //3.1使用keySet() System.out.println("------KeySet-------"); for (Student Key : students.keySet()) { System.out.println(Key.toString()+"--"+students.get(Key)); } //3.2使用entrySet() System.out.println("------entrySet-----"); for (Map.Entry<Student, String> entry : students.entrySet()) { System.out.println(entry.getKey()+"--"+entry.getValue()); } //4.判断 System.out.println("-----判断-----"); System.out.println(students.containsKey(s1)); System.out.println(students.containsKey(new Student("小芳", 2003)));//因为重写了hashcode和equals 所以返回true System.out.println(students.containsValue("上海")); } }
2.TreeMap 存储结构:红黑树
package com.monv.map; public class Student { private String name; private int stNO; public Student() { // TODO Auto-generated constructor stub } public Student(String name, int stNO) { super(); this.name = name; this.stNO = stNO; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getStNO() { return stNO; } public void setStNO(int stNO) { this.stNO = stNO; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((name == null) ? 0 : name.hashCode()); result = prime * result + stNO; return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Student other = (Student) obj; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; if (stNO != other.stNO) return false; return true; } @Override public String toString() { return "Student [name=" + name + ", stNO=" + stNO + "]"; } } ------------------------------------------- package com.monv.map; import java.util.Comparator; import java.util.Map; import java.util.TreeMap; public class Demo3 { public static void main(String[] args) { //创建集合 (定制比较) TreeMap<Student, String> students = new TreeMap<Student, String>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { int n1 = o1.getStNO()-o2.getStNO(); int n2 = o1.getName().compareTo(o2.getName()); return n1==0?n2:n1; } }); Student s1 = new Student("小明", 101); Student s2 = new Student("小红", 102); Student s3 = new Student("小白", 103); //1.添加元素 students.put(s1, "北京"); students.put(s2, "上海"); students.put(s3, "深圳"); System.out.println("元素个数:"+students.size()); //TreeMap的存储结构是红黑树 所以Student类要实现Comparable接口 或者 在定义集合的时候 定制好比较规则 System.out.println(students.toString());// java.lang.ClassCastException: com.monv.map.Student cannot be cast to java.lang.Comparable //2.删除元素 // students.remove(s2); // System.out.println("删除后元素个数:"+students.size()); // System.out.println(students.toString()); //3.遍历 //3.1使用keySet()遍历 System.out.println("----3.1使用keySet()--------"); for (Student key : students.keySet()) { System.out.println(key +"-----"+students.get(key)); } //3.2 使用EntrySet()遍历 System.out.println("----3.2使用EntrySet()--------"); for (Map.Entry<Student, String> entry : students.entrySet()) { System.out.println(entry.getKey()+"----"+entry.getValue()); } //4.判断 System.out.println("--------判断---------------"); System.out.println(students.containsKey(s2)); System.out.println(students.containsValue("北京")); } }
方法:
1、public static void reverse(List<?> list) //反转集合中元素的顺序
2、public static void shuffle(List<?> list) //随机重置集合元素的顺序
package com.monv.map; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.List; /** * Collections工具类使用 * @author Administrator * */ public class Demo4 { public static void main(String[] args) { List<Integer> list = new ArrayList<Integer>(); list.add(10); list.add(2); list.add(25); list.add(13); list.add(22); //1.Sort排序 System.out.println("----Sort排序----"); System.out.println("排序前:"+list.toString()); Collections.sort(list); System.out.println("排序后:"+list.toString()); //2.binarySearch二分查找(查找元素的位置) System.out.println("----binarySearch----"); int i = Collections.binarySearch(list, 13); System.out.println(i); //3.Copy复制 System.out.println("----Copy----"); List<Integer> dest = new ArrayList<Integer>(); //List是有长度的 dest为新建的 长度为0 复制的时候会报错 所以要开辟空间 for (int j = 0; j < list.size(); j++) { dest.add(0); } Collections.copy(dest, list);//注意:复制的时候要求 目标List和源List的大小一致 否则会报错 System.out.println(dest.toString()); //4.reverse 反转 System.out.println("----reverse----"); Collections.reverse(list); System.out.println(list.toString()); //5.shuffle 打乱 每次运行都不一样 System.out.println("----shuffle----"); Collections.shuffle(list); System.out.println(list.toString()); //补充:List转换为数组 System.out.println("----List转换为数字----"); Integer[] intArr = list.toArray(new Integer[0]); System.out.println(intArr.length); System.out.println(Arrays.toString(intArr)); //数组转换为List集合 System.out.println("----数组转换为List集合"); String[] str = {"aaa","bbb","ccc"}; //数组转换后的集合是受限集合 长度是固定的 不能添加和删除 List<String> list2 = Arrays.asList(str); System.out.println(list2); //把基本类型数字转换成集合时,需要修改为包装类型 // int[] nums = {100,200,13,25,12}; Integer[] nums = {100,200,13,25,12}; List<Integer> list3=Arrays.asList(nums); System.out.println(list3); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号