

1 前向最大匹配算法
实例: 以“我们经常有意见分歧”这一句为例,进行分词,流程如下:
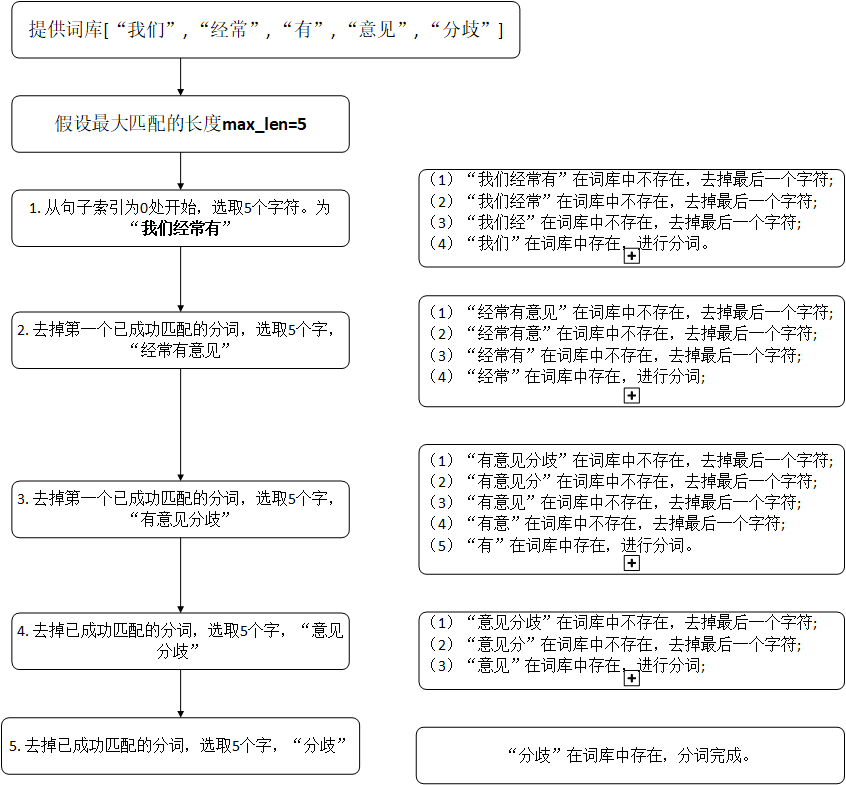
2 前向匹配算法的步骤
- 设定最大匹配的字符串长度N;
-
从index = word_len开始,选取N个字(符);
-
判断选取的字符串在语料库中是否存在,如果是,选中的字符分词成功,转到步骤(4),否则删除当前字符串中最后一个字符,循环步骤(3)直到分词成功。
-
指针移动sentence_length-word_len位,重复步骤(3);
注:其中,sentence_length表示整个待分词的句子长度,word_len位表示所有已经成功分词的字符串长度。
3 算法实现——c#
public static List<string> SplitSeq1(string senquence, List<string> corpus, int maxLength) { var result = new List<string>(); var alreadySplitWord = string.Empty; while (senquence.Length > 0) { var tempStr = senquence.Length >= maxLength ? senquence.Substring(0, maxLength) : senquence; // 逐个移除字符并匹配 while (tempStr.Length > 0) { if (corpus.Contains(tempStr)) { result.Add(tempStr); alreadySplitWord += tempStr; senquence = senquence.Remove(0, tempStr.Length); break; } tempStr = tempStr.Remove(tempStr.Length - 1, 1); } } return result; } public static string Print(List<string> words) { var result = string.Empty; foreach (var item in words) { result += $"{item}|"; } return result; }
业务调用:
static void Main(string[] args) { var corpus = new List<string>(){"我们", "经常", "有", "意见", "分歧"}; var splitResult = SplitSeq1("我们经常有意见分歧", corpus, 5); var result = Print(splitResult); Console.WriteLine(result); }
运行结果为:

4 后向匹配算法
以“我们经常有意见分歧”为例,对句子进行分词。

图2 后向匹配算法流程
3 后向匹配算法实现(c#)
public static List<string> PostMatch(string sequence, List<string> corpus, int maxLength) { var result = new List<string>(); var handledWord = string.Empty; while (sequence.Length > 0) { int startIndex = sequence.Length - maxLength; var tempStr = sequence.Length >= maxLength ? sequence.Substring(startIndex, maxLength) : sequence; while (tempStr.Length > 0) { if (corpus.Contains(tempStr)) { result.Add(tempStr); handledWord += tempStr; sequence = sequence.Remove(sequence.Length-tempStr.Length, tempStr.Length); break; } tempStr = tempStr.Remove(0, 1); } } return result; } public static string PostPrint(List<string> words) { var result = string.Empty; for (int i = words.Count-1; i >=0; i--) { result += $"{words[i]}|"; } return result; }
运行结果为:

注: 由于词库中词语字的重叠,有可能前向和后向匹配算法得到的结果不一样,但是一般而言,相似度比较大。
如, 假设上例中,给定的词库为:["我们", "经常", "意见", "分歧","常有","我","们","经","常", "有"]
前向匹配结果为: 我们| 经常| 有| 意见| 分歧
后向匹配结果为:我们| 经| 常有| 意见| 分歧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号