

iceberg数据存储格式
Apache Iceberg作为一款新兴的数据湖解决方案在实现上高度抽象,在存储上能够对接当前主流的HDFS,S3文件系统并且支持多种文件存储格式,例如Parquet、ORC、AVRO。相较于Hudi、Delta与Spark的强耦合,Iceberg可以与多种计算引擎对接,目前社区已经支持Spark读写Iceberg、Impala/Hive查询Iceberg。本文基于Apache Iceberg 0.10.0,介绍Iceberg文件的组织方式以及不同文件的存储格式。
Iceberg Table Format
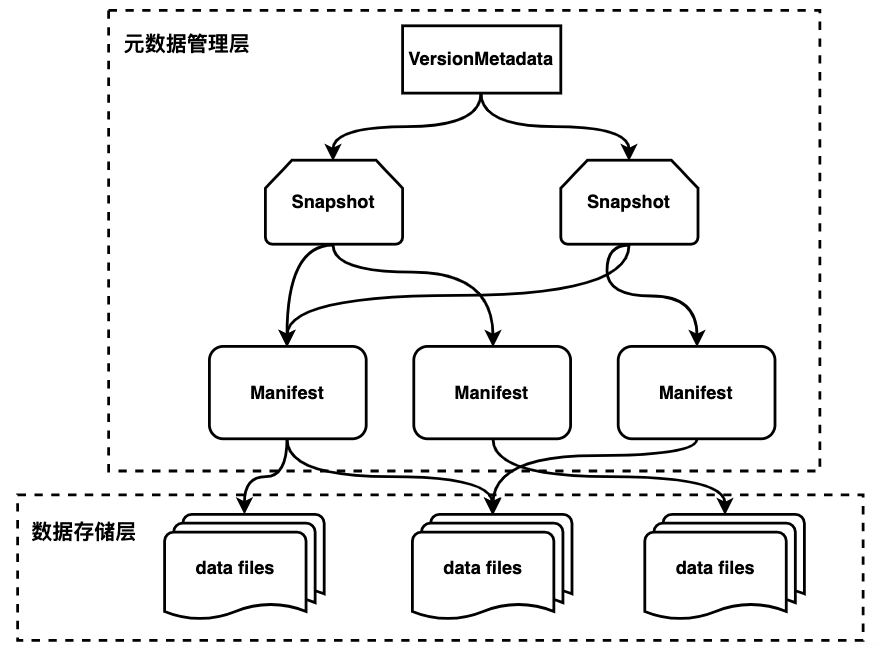
从图中可以看到iceberg将数据进行分层管理,主要分为元数据管理层和数据存储层。元数据管理层又可以细分为三层:
- VersionMetadata
- Snapshot
- Manifest
VersionMetadata存储当前版本的元数据信息(所有snapshot信息);Snapshot表示当前操作的一个快照,每次commit都会生成一个快照,一个快照中包含多个Manifest,每个Manifest中记录了当前操作生成数据所对应的文件地址,也就是data files的地址。基于snapshot的管理方式,iceberg能够进行time travel(历史版本读取以及增量读取),并且提供了serializable isolation。
数据存储层支持不同的文件格式,目前支持Parquet、ORC、AVRO。
下面以HadoopTableOperation commit生成的数据为例介绍各层的数据格式。iceberg生成的数据目录结构如下所示:
├── data
│ ├── id=1
│ │ ├── 00000-0-04ae60eb-657d-45cb-bb99-d1cb7fe0ad5a-00001.parquet
│ │ └── 00000-4-487b841b-13b4-4ae8-9238-f70674d5102e-00001.parquet
│ ├── id=2
│ │ ├── 00001-1-e85b018b-e43a-44d7-9904-09c80a9b9c24-00001.parquet
│ │ └── 00001-5-0e2be766-c921-4269-8e1e-c3cff4b98a5a-00001.parquet
│ ├── id=3
│ │ ├── 00002-2-097171c5-d810-4de9-aa07-58f3f8a3f52e-00001.parquet
│ │ └── 00002-6-9d738169-1dbe-4cc5-9a87-f79457a9ec0b-00001.parquet
│ └── id=4
│ ├── 00003-3-b0c91d66-9e4e-4b7a-bcd5-db3dc1b847f2-00001.parquet
│ └── 00003-7-68c45a24-21a2-41e8-90f1-ef4be42f3002-00001.parquet
└── metadata
├── 1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m0.avro
├── 1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m1.avro
├── f475511f-877e-4da5-90aa-efa5928a7759-m0.avro
├── snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro
├── snap-5178718682852547007-1-f475511f-877e-4da5-90aa-efa5928a7759.avro
├── v1.metadata.json
├── v2.metadata.json
├── v3.metadata.json
└── version-hint.text
其中metadata目录存放元数据管理层的数据:
- version-hint.text:存储version.metadata.json的版本号,即下文的number
- version[number].metadata.json
- snap-[snapshotID]-[attemptID]-[commitUUID].avro(snapshot文件)
- [commitUUID]-m-[manifestCount].avro(manifest文件)
data目录组织形式类似于hive,都是以分区进行目录组织(上图中id为分区列),最终数据可以使用不同文件格式进行存储:
- [sparkPartitionID]-[sparkTaskID]-[UUID]-[fileCount].[parquet | avro | orc]
VersionMetadata
//
{
// 当前文件格式版本信息
// 目前为version 1
// 支持row-level delete等功能的version 2还在开发中
"format-version" : 1,
"table-uuid" : "a9114f94-911e-4acf-94cc-6d000b321812",
// hadoopTable location
"location" : "hdfs://10.242.199.202:9000/hive/empty_order_item",
// 最新snapshot的创建时间
"last-updated-ms" : 1608810968725,
"last-column-id" : 6,
// iceberg schema
"schema" : {
"type" : "struct",
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false, // 类似probuf中的required
"type" : "long"
}, {
"id" : 2,
"name" : "order_id",
"required" : false,
"type" : "long"
}, {
"id" : 3,
"name" : "product_id",
"required" : false,
"type" : "long"
}, {
"id" : 4,
"name" : "product_price",
"required" : false,
"type" : "decimal(7, 2)"
}, {
"id" : 5,
"name" : "product_quantity",
"required" : false,
"type" : "int"
}, {
"id" : 6,
"name" : "product_name",
"required" : false,
"type" : "string"
} ]
},
"partition-spec" : [ {
"name" : "id",
"transform" : "identity", // transform类型
"source-id" : 1,
"field-id" : 1000
} ],
"default-spec-id" : 0,
// 分区信息
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "id",
// transform类型:目前支持identity,year,bucket等
"transform" : "identity",
// 对应schema.fields中相应field的ID
"source-id" : 1,
"field-id" : 1000
} ]
} ],
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
// hive创建该表存储的一些hive property信息
"properties" : {
"totalSize" : "0",
"rawDataSize" : "0",
"numRows" : "0",
"COLUMN_STATS_ACCURATE" : "{\"BASIC_STATS\":\"true\"}",
"numFiles" : "0"
},
// 当前snapshot id
"current-snapshot-id" : 2080639593951710914,
// snapshot信息
"snapshots" : [ {
"snapshot-id" : 5178718682852547007,
// 创建snapshot时间
"timestamp-ms" : 1608809818168,
"summary" : {
// spark写入方式,目前支持overwrite以及append
"operation" : "overwrite",
"spark.app.id" : "local-1608809790982",
"replace-partitions" : "true",
// 本次snapshot添加的文件数量
"added-data-files" : "4",
// 本次snapshot添加的record数量
"added-records" : "4",
// 本次snapshot添加的文件大小
"added-files-size" : "7217",
// 本次snapshot修改的分区数量
"changed-partition-count" : "4",
// 本次snapshot中record总数 = lastSnapshotTotalRecord - currentSnapshotDeleteRecord + currentSnapshotAddRecord
"total-records" : "4",
"total-data-files" : "4",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-5178718682852547007-1-f475511f-877e-4da5-90aa-efa5928a7759.avro"
}, {
"snapshot-id" : 2080639593951710914,
// 上次snapshotID
"parent-snapshot-id" : 5178718682852547007,
"timestamp-ms" : 1608810968725,
"summary" : {
"operation" : "overwrite",
"spark.app.id" : "local-1608809790982",
"replace-partitions" : "true",
"added-data-files" : "4",
"deleted-data-files" : "4",
"added-records" : "4",
"deleted-records" : "4",
"added-files-size" : "7217",
"removed-files-size" : "7217",
"changed-partition-count" : "4",
"total-records" : "4",
"total-data-files" : "4",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
// snapshot文件路径
"manifest-list" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro"
} ],
// snapshot记录
"snapshot-log" : [ {
"timestamp-ms" : 1608809818168,
"snapshot-id" : 5178718682852547007
}, {
"timestamp-ms" : 1608810968725,
"snapshot-id" : 2080639593951710914
} ],
// metada记录
"metadata-log" : [ {
"timestamp-ms" : 1608809758229,
"metadata-file" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1608809818168,
"metadata-file" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/v2.metadata.json"
} ]
}
上例展示的是v3.metadata.json中的数据,该文件保存了iceberg table schema、partition、snapshot信息,partition中的transform信息使得iceberg能够根据字段进行hidden partition,而无需像hive一样显示的指定分区字段。由于VersionMetadata中记录了每次snapshot的id以及create_time,我们可以通过时间或snapshotId查询相应snapshot的数据,实现Time Travel。
Snapshot
// Snapshot: 2080639593951710914
// Location: hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro
// manifest entry
{
"manifest_path" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m1.avro",
"manifest_length" : 5291,
"partition_spec_id" : 0,
// 该manifest entry所属的snapshot
"added_snapshot_id" : {
"long" : 2080639593951710914
},
// 该manifest中添加的文件数量
"added_data_files_count" : {
"int" : 4
},
// 创建该manifest时已经存在且
// 没有被这次创建操作删除的文件数量
"existing_data_files_count" : {
"int" : 0
},
// 创建manifest删除的文件
"deleted_data_files_count" : {
"int" : 0
},
// 该manifest中partition字段的范围
"partitions" : {
"array" : [ {
"contains_null" : false,
"lower_bound" : {
"bytes" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
"upper_bound" : {
"bytes" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}
} ]
},
"added_rows_count" : {
"long" : 4
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
// manifest entry
{
"manifest_path" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m0.avro",
"manifest_length" : 5289,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 2080639593951710914
},
"added_data_files_count" : {
"int" : 0
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 4
},
"partitions" : {
"array" : [ {
"contains_null" : false,
"lower_bound" : {
"bytes" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
"upper_bound" : {
"bytes" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}
} ]
},
"added_rows_count" : {
"long" : 0
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 4
}
}
一个snapshot中可以包含多个manifest entry,一个manifest entry表示一个manifest,其中重点需要关注的是每个manifest中的partitions字段,在根据filter进行过滤时可以首先通过该字段表示的分区范围对manifest进行过滤,避免无效的查询。
Manifest
// DataFileEntry
{
// 表示对应数据文件status
// 0: EXISTING, 1: ADDED,2: DELETED
"status" : 1,
"snapshot_id" : {
"long" : 2080639593951710914
},
"data_file" : {
"file_path" : "hdfs://10.242.199.202:9000/hive/empty_order_item/data/id=1/00000-4-487b841b-13b4-4ae8-9238-f70674d5102e-00001.parquet",
"file_format" : "PARQUET",
// 对应的分区值
"partition" : {
"id" : {
"long" : 1
}
},
// 文件中record数量
"record_count" : 1,
// 文件大小
"file_size_in_bytes" : 1823,
"block_size_in_bytes" : 67108864,
// 不同column存储大小
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 52
}, {
"key" : 2,
"value" : 52
}, {
"key" : 3,
"value" : 52
}, {
"key" : 4,
"value" : 53
}, {
"key" : 5,
"value" : 51
}, {
"key" : 6,
"value" : 61
} ]
},
// 不同列对应的value数量
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
}, {
"key" : 3,
"value" : 1
}, {
"key" : 4,
"value" : 1
}, {
"key" : 5,
"value" : 1
}, {
"key" : 6,
"value" : 1
} ]
},
// 列值为null的数量
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
}, {
"key" : 3,
"value" : 0
}, {
"key" : 4,
"value" : 0
}, {
"key" : 5,
"value" : 0
}, {
"key" : 6,
"value" : 0
} ]
},
// 不同列的范围
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 3,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 4,
"value" : "\u0013ˆ"
}, {
"key" : 5,
"value" : "\u0002\u0000\u0000\u0000"
}, {
"key" : 6,
"value" : "table lamp"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 3,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 4,
"value" : "\u0013ˆ"
}, {
"key" : 5,
"value" : "\u0002\u0000\u0000\u0000"
}, {
"key" : 6,
"value" : "table lamp"
} ]
},
"key_metadata" : null,
// parquet block offset/ orc stripe offset
"split_offsets" : {
"array" : [ 4 ]
}
}
}
{
...
}
Manifest管理多个data文件,一条DataFileEntry对应一个data文件,DataFileEntry中记录了所属partition,value bounds等信息,value_counts和null_value_counts可以用于过滤null列,例:column a所对应的value_count为3,且对应的null_value_count也为3,此时如果select a,则可以根据value_count-null_value_count=0判断a全为null直接返回而无需再进行parquet文件的查询;除此之外,可以根据value bounds进行过滤,加速查询。
总结
本文主要介绍了Iceberg不同文件的存储格式,讲解了不同字段中的作用,正是这些元数据管理保证了iceberg能够进行高效快速的查询,后续会根据这些文件进一步分析iceberg写入和查询过程。
原文链接:https://blog.csdn.net/u012794915/article/details/111831471

