

shell编程基础(五): 正则表达式及其使用
正则表达式
1、前情提要
以前我们用grep在一个文件中找出包含某些字符串的行,比如在头文件中找出一个宏定义。其实grep还可以找出符合某个模式(Pattern)的一类字符串。例如找出所有符合xxxxx@xxxx.xxx模式的字符串(也就是email地址),要求x字符可以是字母、数字、下划线、小数点或减号,email地址的每一部分可以有一个或多个x字符,例如abc.d@ef.com、1_2@987-6.54,当然符合这个模式的不全是合法的email地址,但至少可以做一次初步筛选,筛掉a.b、c@d等肯定不是email地址的字符串。再比如,找出所有符合yyy.yyy.yyy.yyy模式的字符串(也就是IP地址),要求y是0-9的数字,IP地址的每一部分可以有1-3个y字符。
如果要用grep查找一个模式,如何表示这个模式,这一类字符串,而不是一个特定的字符串呢?从这两个简单的例子可以看出,要表示一个模式至少应该包含以下信息:
字符类(Character Class):如上例的x和y,它们在模式中表示一个字符,但是取值范围是一类字符中的任意一个。
数量限定符(Quantifier): 邮件地址的每一部分可以有一个或多个x字符,IP地址的每一部分可以有1-3个y字符
各种字符类以及普通字符之间的位置关系:例如邮件地址分三部分,用普通字符@和.隔开,IP地址分四部分,用.隔开,每一部分都可以用字符类和数量限定符描述。
为了表示位置关系,还有位置限定符(Anchor)的概念,将在下面介绍。
规定一些特殊语法表示字符类、数量限定符和位置关系,然后用这些特殊语法和普通字符一起表示一个模式,这就是正则表达式(Regular Expression)。
例如email地址的正则表达式可以写成[a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+.[a-zA-Z0-9_.-]+,IP地址的正则表达式可以写成[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}。
等下介绍正则表达式的语法,我们先看看正则表达式在grep中怎么用。例如有这样一个文本文件testgrep:
[root@VM_0_5_centos test]# vi testgrep.file [root@VM_0_5_centos test]# cat testgrep.file 192.168.13.108 123.5254.045.678 abcde52s 198.23.233.342 1233.232.232.4
查找其中包含IP地址的行:

注:1、egrep相当于grep -E,表示采用Extended正则表达式语法。另外还有fgrep命令,相当于grep -F,表示只搜索固定字符串而不搜索正则表达式模式,不会按正则表达式的语法解释后面的参数。
2、正则表达式参数用单引号括起来了,因为正则表达式中用到的很多特殊字符在Shell中也有特殊含义(例如\),只有用单引号括起来才能保证这些字符原封不动地传给grep命令,而不会被Shell解释掉。
grep的正则表达式有Basic和Extended两种规范: 1、grep正则表达式的Extended规范在基本语法中介绍; 2、Basic规范也有Extended规范的这些语法,只是字符?+{}|()应解释为普通字符,要表示上述特殊含义则需要加\转义。如果用grep而不是egrep,并且不加-E参数,则应该遵照Basic规范来写正则表达式。
问:192.168.13.108符合上述模式,由三个.隔开的四段组成,每段都是1到3个数字,所以这一行被找出来了,可为什么1233.232.232.4也被找出来了呢?
答:因为grep找的是包含某一模式的行,这一行包含一个符合模式的字符串233.232.232.4。相反,123.5254.045.678这一行不包含符合模式的字符串,所以不会被找出来。
grep是一种查找过滤工具,正则表达式在grep中用来查找符合模式的字符串。其实正则表达式还有一个重要的应用是验证用户输入是否合法,例如用户通过网页表单提交自己的email地址,就需要用程序验证一下是不是合法的email地址,这个工作可以在网页的Javascript中做,也可以在网站后台的程序中做,例如PHP、Perl、Python、Ruby、Java或C,所有这些语言都支持正则表达式,可以说,目前不支持正则表达式的编程语言实在很少见。除了编程语言之外,很多UNIX命令和工具也都支持正则表达式,例如grep、vi、sed、awk、emacs等等。“正则表达式”就像“变量”一样,它是一个广泛的概念,而不是某一种工具或编程语言的特性。
2、基本语法
我们知道C的变量和Shell脚本变量的定义和使用方法很不相同,表达能力也不相同,C的变量有各种类型,而Shell脚本变量都是字符串。同样道理,各种工具和编程语言所使用的正则表达式规范的语法并不相同,表达能力也各不相同,有的正则表达式规范引入很多扩展,能表达更复杂的模式,但各种正则表达式规范的基本概念都是相通的。本节介绍egrep(1)所使用的正则表达式,它大致上符合POSIX正则表达式规范,详见regex(7)(看这个man page对你的英文绝对是很好的锻炼)。希望读者仿照上一节的例子,一边学习语法,一边用egrep命令做实验。
字符类:
| 字符 | 含义 | 举例 |
| . | 匹配任意一个字符 | abc.可以匹配abcd、abc9等 |
| [] | 匹配括号中的任意一个字符 | [abc]d可以匹配ad、bd或cd |
| - | 在[]括号内表示字符范围 | [0-9a-fA-F]可以匹配一位十六进制数字 |
| ^ | 位于[]括号内的开头,匹配除括号中的字符之外的任意一个字符 | [^xy]匹配除xy之外的任一字符,因此[^xy]1可以匹配a1、b1但不匹配x1、y1 |
| [[:xxx:]] | grep工具预定义的一些命名字符类 | [[:alpha:]]匹配一个字母,[[:digit:]]匹配一个数字 |
数量限定符:
| 字符 | 含义 | 举例 |
| ? |
紧跟在它前面的单元应匹配零次或一次 |
[0-9]?\.[0-9]匹配0.0、2.3、.5等,由于.在正则表达式中是一个特殊字符,所以需要用\转义一下,取字面值 |
| + |
紧跟在它前面的单元应匹配一次或多次 |
[a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.[a-zA-Z0-9_.-]+匹配email地址 |
| * |
紧跟在它前面的单元应匹配零次或多次 |
[0-9][0-9]*匹配至少一位数字,等价于[0-9]+,[a-zA-Z_]+[a-zA-Z_0-9]*匹配C语言的标识符 |
| {N} |
紧跟在它前面的单元应精确匹配N次 |
[1-9][0-9]{2}匹配从100到999的整数
|
| {n,} |
紧跟在它前面的单元应匹配至少N次 |
[1-9][0-9]{2,}匹配三位以上(含三位)的整数
|
| {,M} |
紧跟在它前面的单元应匹配最多M次 |
[0-9]{,1}相当于[0-9]?
|
| {N,M} |
紧跟在它前面的单元应匹配至少N次,最多M次 |
[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}匹配IP地址
|
再次注意grep找的是包含某一模式的行,而不是完全匹配某一模式的行。再举个例子,如果文本文件的内容是:
[root@VM_0_5_centos test]# vi testfile.txt
[root@VM_0_5_centos test]# cat testfile.txt
acaabc
caad
efg
sdcasd
sda
查找a*这个模式的结果是三行都被找出来了:

注:a匹配0个或多个a,而第三行包含0个a,所以也包含了这一模式。单独用a这样的正则表达式做查找没什么意义,一般是把a*作为正则表达式的一部分来用。
位置限定符:
| 字符 | 含义 | 举例 |
| ^ |
匹配行首的位置 |
^Content匹配位于一行开头的Content |
| $ |
匹配行末的位置 |
;$匹配位于一行结尾的;号,^$匹配空行 |
| \< |
匹配单词开头的位置 |
\<th匹配... this,但不匹配ethernet、tenth |
| \> |
匹配单词结尾的位置 |
p\>匹配leap ...,但不匹配parent、sleepy |
| \b |
匹配单词开头或结尾的位置 |
\bat\b匹配... at ...,但不匹配cat、atexit、batch |
| \B |
匹配非单词开头和结尾的位置 |
\Bat\B匹配battery,但不匹配... attend、hat ... |
位置限定符可以帮助grep更准确地查找,例如上一节我们用[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}查找IP地址,找到这两行:
192.168.13.108 198.23.233.342 1233.232.232.4
如果用^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}$查找,就可以把1233.232.232.4这一行过滤掉了。
其它特殊字符:
| 字符 | 含义 | 举例 |
| \ |
转义字符,普通字符转义为特殊字符,特殊字符转义为普通字符 |
普通字符<写成\<表示单词开头的位置,特殊字符.写成\.以及\写成\\就当作普通字符来匹配 |
| () |
将正则表达式的一部分括起来组成一个单元,可以对整个单元使用数量限定符 |
([0-9]{1,3}\.){3}[0-9]{1,3}匹配IP地址
|
| | |
连接两个子表达式,表示或的关系 |
n(o|either)匹配no或neither |
以上介绍的是grep正则表达式的Extended规范,Basic规范也有这些语法,只是字符?+{}|()应解释为普通字符,要表示上述特殊含义则需要加\转义。如果用grep而不是egrep,并且不加-E参数,则应该遵照Basic规范来写正则表达式。
3、grep
1.作用
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
rep家族包括grep、egrep和fgrep: egrep和fgrep的命令只跟grep有很小不同。 egrep是grep的扩展,支持更多的re元字符; fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。 linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
2.格式
grep [options]
3.主要参数
grep --help [options]主要参数: -c:只输出匹配行的计数。 -i:不区分大小写。 -h:查询多文件时不显示文件名。 -l:查询多文件时只输出包含匹配字符的文件名。 -n:显示匹配行及行号。 -s:不显示不存在或无匹配文本的错误信息。 -v:显示不包含匹配文本的所有行。 --color=auto :可以将找到的关键词部分加上颜色的显示。
pattern正则表达式主要参数:(pattern部分最好用双引号)
\ 忽略正则表达式中特殊字符的原有含义。 ^ 匹配正则表达式的开始行。 $ 匹配正则表达式的结束行。 \< 从匹配正则表达 式的行开始。 \> 到匹配正则表达式的行结束。 [ ] 单个字符,如[A]即A符合要求 。 [ - ] 范围,如[A-Z],即A、B、C一直到Z都符合要求 。 . 所有的单个字符。 * 有字符,长度可以为0。
4.grep命令使用简单实例
显示所有以d开头的文件中包含 test的行; [root@VM_0_5_centos test]# grep “test” d* 显示在aa,bb,cc文件中匹配test的行(./*表示当前目录下的所有文件); [root@VM_0_5_centos test]# grep ‘test’ aa bb cc [root@VM_0_5_centos test]# egrep "sda" ./* ./test:sda ./testfile.txt:sda ./testsd:sdadf [root@VM_0_5_centos test]# egrep "sda" ./* -n ./test:2:sda ./testfile.txt:5:sda ./testsd:2:sdadf [root@VM_0_5_centos test]# egrep "sda" ./* -c ./test:1 ./testfile.txt:1 ./testgrep.file:0 ./testsd:1 ./tfun.sh:0 显示所有包含每个字符串至少有5个连续小写字符的字符串的行; [root@VM_0_5_centos test]# grep “[a-z]\{5\}” test
[root@VM_0_5_centos test]# egrep “[a-z]{5}” test
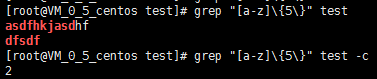
如果asd被匹配,则s就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着另外一个s(\1),找到就显示该行。如果用egrep或grep -E,就不用”\”号进行转义,直接写成’a(s)d.*\1′就可以了;
[root@VM_0_5_centos test]# grep “a\(s\)d.*\1” test
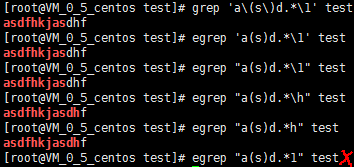
5.grep命令使用复杂实例
明确要求搜索子目录:
grep -r
或忽略子目录:
grep -d skip
如果有很多输出时,您可以通过管道将其转到’less’上阅读:
IP地址的正则表达式可以写成[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}。
grep -E '^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$' testgrep.file | less
这样,您就可以更方便地阅读。
注意:您必需提供一个文件过滤方式(搜索全部文件的话用 *)。如果您忘了,’grep’会一直等着,直到该程序被中断。如果您遇到了这样的情况,按 ,然后再试。
下面还有一些有意思的命令行参数:
grep -i pattern files //不区分大小写地搜索。默认情况区分大小写, grep -l pattern files //只列出匹配的文件名, grep -L pattern files //列出不匹配的文件名, grep -w pattern files //只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’), grep -C number pattern files//匹配的上下文分别显示[number]行, grep pattern1 | pattern2 files //显示匹配 pattern1 或 pattern2 的行, 例如: grep "abc\|xyz" testfile 表示过滤包含abc或xyz的行 grep pattern1 files | grep pattern2 //显示既匹配 pattern1 又匹配 pattern2 的行。 grep -n pattern files //即可显示行号信息 grep -c pattern files //即可查找总行数
这里还有些用于搜索的特殊符号:
\< 和 \> 分别标注单词的开始与结尾 例如: grep man * 会匹配 ‘Batman’、’manic’、’man’等; grep ‘\<man’ * 会匹配’manic’和’man’,但不是’Batman’; grep ‘\<man\>’ 只匹配’man’,而不是’Batman’或’manic’等其他的字符串。 ‘^’ 指匹配的字符串在行首; ‘$’ 指匹配的字符串在行尾; 例如: [root@VM_0_5_centos test]# cat testfile.txt acaabc caad efg sdcasd sda [root@VM_0_5_centos test]# grep '^a' testfile.txt acaabc [root@VM_0_5_centos test]# grep -E '^a' testfile.txt acaabc [root@VM_0_5_centos test]# grep -E 'a$' testfile.txt sda


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}