

spark之java程序开发
spark之java程序开发
1、Spark中的Java开发的缘由:
Spark自身是使用Scala程序开发的,Scala语言是同时具备函数式编程和指令式编程的一种混血语言,而Spark源码是基于Scala函数式编程来给予设计的,Spark官方推荐Spark的开发人员基于Scala的函数式编程来实现Spark的Job开发,但是目前Spark在生产上的主流开发语言仍然是Java,造成这一事实的原因主要有以下几点:
A、Java目前已经成为行业内的主流语言,社区相当活跃,相比于Scala而言,Java可以有相当多的资料和文档供与项目开发上参考
B、Spark项目会与其它已有的Java项目进行集成,这意味着使用Java来开发Spark项目可以更好的实现与已有的各个基于Java的平台进行对接和整合
C、目前行业内的Scala程序员相当匮乏、Spark提供了基于Scala与Java的两套API实现,同时在Scala的学习成本较之于Java更高的情况下很多公司和企业有放弃使用Scala来开发的倾向
2、Spark中的Java-API的特征:
Java的API是根据Scala的API来进行对应设计的,由于Scala的API是基于函数式的,函数式编程的一个重要特征就是函数本身可以作为函数的参数进行传递(即实现高阶函数调用),而Java的编程方式是指令式的,指令式编程中函数的参数类型不能直接是函数类型,只能是基本类型和对象类型,Spark为了做到与Scala一致的API设计采用了函数参数为对象类型的传递方式;
由于受SparkAPI的限定,Spark提供的各个函数的参数类型都是固定的,在Scala语法实现的API中其函数的参数类型是函数类型,参数函数的类型依赖于取决于参数函数的名称、参数函数的参数列表、参数函数的返回类型;而在java语法实现的Spark-API中,其函数的参数类型是对象类型,由于参数对象类型是受Spark-API限定的,所以Spark提供了一套专门针对函数参数对象类型的接口,在调用方法时通过传递这些接口类型的实例即可回调与函数式编程中相似的参数函数对象,也就是说函数式编程中的参数函数相当于参数接口中定义的方法,参数接口的具体实现可以单独实现也可以使用局部内部类来给予实现,由于大多数的参数接口回调都是临时的,而不是通用的,所以在生产上采用局部内部类来实现参数接口的情况更普遍;
另一个需要值得注意的是使用Java来开发Spark项目时,其参数接口通常都是被Spark官方做了泛型定义的,Spark定义泛型化的参数接口是为在编译期检查接口中回调函数的参数列表和返回类型
3、使用Ecipse的mars版本(JavaEE版本)开发Spark应用程序
整体工程结构:

3.1、使用Java开发的本地Spark应用
说明:
Scala-Eclipse的工作空间一般是/project/scala目录下,而JavaEE-Eclipse的mars版本工作空间一般是/project目录下,此处有一定区别,注意区分
A、使用Eclipse4.5(mars版本)创建一个Java工程SparkRDD,并在此工程下创建一个用于本地输入的目录input
[hadoop@CloudDeskTop software]$ mkdir -p /project/SparkRDD/input
B、然后在Eclipse4.5中创建一个Spark2.1.1-All的用户库,将~/Spark2.1.1-All目录中的所有jar包导入Spark2.1.1-All用户库中,并将此用户库添加到当前的Java工程中:Window==>Preferences==>Java==>Build Path==>User Libraries==>New

说明:由于现在换了Eclipse的JavaEE版本,之前的Scala-eclipse中的用户库无法使用,所以针对Eclipse4.5版本的Spark用户库需要重新创建
C、将输入文件拷贝到创建的input目录下
[hadoop@CloudDeskTop project]$ cp -a /project/scala/SparkRDD/input/{first.txt,second.txt} /project/SparkRDD/input/


[hadoop@CloudDeskTop input]$ cat first.txt jin tian shi ge hao tian qi jin tian tian qi bu cuo welcome to mmzs blog [hadoop@CloudDeskTop input]$ cat second.txt jin tian shi ge hao tian qi jin tian tian qi bu cuo welcome to mmzs blog welcome to mmzs blog
D、将Scala代码翻译成Java代码如下:
1 package com.mmzs.bigdata.spark.core.local; 2 3 import java.io.File; 4 import java.util.Arrays; 5 import java.util.Iterator; 6 import java.util.List; 7 8 import org.apache.spark.SparkConf; 9 import org.apache.spark.api.java.JavaPairRDD; 10 import org.apache.spark.api.java.JavaRDD; 11 import org.apache.spark.api.java.JavaSparkContext; 12 import org.apache.spark.api.java.function.FlatMapFunction; 13 import org.apache.spark.api.java.function.Function2; 14 import org.apache.spark.api.java.function.PairFunction; 15 16 import scala.Tuple2; 17 18 public class TestMain00 { 19 20 private static final File OUT_PATH=new File("/home/hadoop/test/usergroup/output"); 21 22 static{ 23 deleteDir(OUT_PATH); 24 } 25 /** 26 * 递归删除任何目录或文件 27 * @param f 28 */ 29 private static void deleteDir(File f){ 30 if(!f.exists())return; 31 if(f.isFile()||(f.isDirectory()&&f.listFiles().length==0)){ 32 f.delete(); 33 return; 34 } 35 File[] files=f.listFiles(); 36 for(File fp:files)deleteDir(fp); 37 f.delete(); 38 } 39 40 /** 41 * 主方法 42 * @param args 43 */ 44 public static void main(String[] args) { 45 SparkConf conf=new SparkConf(); 46 conf.setAppName("Java Spark local"); 47 conf.setMaster("local"); 48 49 //根据Spark配置生成Spark上下文 50 JavaSparkContext jsc=new JavaSparkContext(conf); 51 52 //读取本地的文本文件成内存中的RDD集合对象 53 JavaRDD<String> lineRdd=jsc.textFile("/project/SparkRDD/input"); 54 55 //切分每一行的字串为单词数组,并将字串数组中的单词字串释放到外层的JavaRDD集合中 56 JavaRDD<String> flatMapRdd=lineRdd.flatMap(new FlatMapFunction<String,String>(){ 57 @Override 58 public Iterator<String> call(String line) throws Exception { 59 String[] words=line.split(" "); 60 List<String> list=Arrays.asList(words); 61 Iterator<String> its=list.iterator(); 62 return its; 63 } 64 }); 65 66 //为JavaRDD集合中的每一个单词进行计数,将其转换为元组 67 ////注意下面一定是调用的mapToPair函数,而不是map函数,否则返回的类型无法续调reduceByKey方法,因为只有元组列表才能实现分组统计 68 JavaPairRDD<String, Integer> mapRdd=flatMapRdd.mapToPair(new PairFunction<String, String,Integer>(){ 69 @Override 70 public Tuple2<String,Integer> call(String word) throws Exception { 71 return new Tuple2<String,Integer>(word,1); 72 } 73 }); 74 75 //根据元组中的第一个元素(Key)进行分组并统计单词出现的次数 76 JavaPairRDD<String, Integer> reduceRdd=mapRdd.reduceByKey(new Function2<Integer,Integer,Integer>(){ 77 @Override 78 public Integer call(Integer pre, Integer next) throws Exception { 79 return pre+next; 80 } 81 }); 82 83 //将单词元组中的元素反序以方便后续排序 84 JavaPairRDD<Integer, String> mapRdd02=reduceRdd.mapToPair(new PairFunction<Tuple2<String, Integer>,Integer,String>(){ 85 @Override 86 public Tuple2<Integer, String> call(Tuple2<String, Integer> wordTuple) throws Exception { 87 return new Tuple2<Integer,String>(wordTuple._2,wordTuple._1); 88 } 89 }); 90 91 //将JavaRDD集合中的单词按出现次数进行将序排列 92 JavaPairRDD<Integer, String> sortRdd=mapRdd02.sortByKey(false, 1); 93 94 //排序之后将元组中的顺序换回来 95 JavaPairRDD<String, Integer> mapRdd03=sortRdd.mapToPair(new PairFunction<Tuple2<Integer, String>,String,Integer>(){ 96 @Override 97 public Tuple2<String, Integer> call(Tuple2<Integer, String> wordTuple) throws Exception { 98 return new Tuple2<String, Integer>(wordTuple._2,wordTuple._1); 99 } 100 }); 101 102 //存储统计之后的结果到磁盘文件中去 103 File fp=new File("/project/SparkRDD/output"); 104 if(fp.exists())deleteDir(fp); 105 mapRdd03.saveAsTextFile("/project/SparkRDD/output"); 106 107 //关闭Spark上下文 108 jsc.close(); 109 } 110 }
E、本地测试:
基于本地(local)模式的Spark应用可以直接在Eclipse里面测试
1 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 2 18/02/08 16:47:58 INFO SparkContext: Running Spark version 2.1.1 3 18/02/08 16:47:58 WARN SparkContext: Support for Java 7 is deprecated as of Spark 2.0.0 4 18/02/08 16:47:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 5 18/02/08 16:47:59 INFO SecurityManager: Changing view acls to: hadoop 6 18/02/08 16:47:59 INFO SecurityManager: Changing modify acls to: hadoop 7 18/02/08 16:47:59 INFO SecurityManager: Changing view acls groups to: 8 18/02/08 16:47:59 INFO SecurityManager: Changing modify acls groups to: 9 18/02/08 16:47:59 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set() 10 18/02/08 16:48:00 INFO Utils: Successfully started service 'sparkDriver' on port 59107. 11 18/02/08 16:48:00 INFO SparkEnv: Registering MapOutputTracker 12 18/02/08 16:48:00 INFO SparkEnv: Registering BlockManagerMaster 13 18/02/08 16:48:00 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 14 18/02/08 16:48:00 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 15 18/02/08 16:48:00 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-c7ad47e1-cd0d-43f7-90e2-307e08da20c0 16 18/02/08 16:48:00 INFO MemoryStore: MemoryStore started with capacity 348.0 MB 17 18/02/08 16:48:00 INFO SparkEnv: Registering OutputCommitCoordinator 18 18/02/08 16:48:01 INFO Utils: Successfully started service 'SparkUI' on port 4040. 19 18/02/08 16:48:01 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.154.134:4040 20 18/02/08 16:48:01 INFO Executor: Starting executor ID driver on host localhost 21 18/02/08 16:48:01 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 49148. 22 18/02/08 16:48:01 INFO NettyBlockTransferService: Server created on 192.168.154.134:49148 23 18/02/08 16:48:01 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 24 18/02/08 16:48:01 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.154.134, 49148, None) 25 18/02/08 16:48:01 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.154.134:49148 with 348.0 MB RAM, BlockManagerId(driver, 192.168.154.134, 49148, None) 26 18/02/08 16:48:01 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.154.134, 49148, None) 27 18/02/08 16:48:01 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.154.134, 49148, None) 28 18/02/08 16:48:03 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 193.9 KB, free 347.8 MB) 29 18/02/08 16:48:03 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 22.9 KB, free 347.8 MB) 30 18/02/08 16:48:03 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.134:49148 (size: 22.9 KB, free: 348.0 MB) 31 18/02/08 16:48:03 INFO SparkContext: Created broadcast 0 from textFile at TestMain00.java:53 32 18/02/08 16:48:03 INFO FileInputFormat: Total input paths to process : 2 33 18/02/08 16:48:03 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 34 18/02/08 16:48:03 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 35 18/02/08 16:48:03 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 36 18/02/08 16:48:03 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 37 18/02/08 16:48:03 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 38 18/02/08 16:48:03 INFO FileOutputCommitter: File Output Committer Algorithm version is 1 39 18/02/08 16:48:04 INFO SparkContext: Starting job: saveAsTextFile at TestMain00.java:105 40 18/02/08 16:48:04 INFO DAGScheduler: Registering RDD 3 (mapToPair at TestMain00.java:68) 41 18/02/08 16:48:04 INFO DAGScheduler: Registering RDD 5 (mapToPair at TestMain00.java:84) 42 18/02/08 16:48:04 INFO DAGScheduler: Got job 0 (saveAsTextFile at TestMain00.java:105) with 1 output partitions 43 18/02/08 16:48:04 INFO DAGScheduler: Final stage: ResultStage 2 (saveAsTextFile at TestMain00.java:105) 44 18/02/08 16:48:04 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 1) 45 18/02/08 16:48:04 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 1) 46 18/02/08 16:48:04 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at TestMain00.java:68), which has no missing parents 47 18/02/08 16:48:04 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.1 KB, free 347.8 MB) 48 18/02/08 16:48:04 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.8 KB, free 347.8 MB) 49 18/02/08 16:48:04 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.154.134:49148 (size: 2.8 KB, free: 348.0 MB) 50 18/02/08 16:48:04 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:996 51 18/02/08 16:48:04 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at TestMain00.java:68) 52 18/02/08 16:48:04 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks 53 18/02/08 16:48:04 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 5982 bytes) 54 18/02/08 16:48:04 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 55 18/02/08 16:48:04 INFO HadoopRDD: Input split: file:/project/SparkRDD/input/first.txt:0+75 56 18/02/08 16:48:04 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1748 bytes result sent to driver 57 18/02/08 16:48:04 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 5983 bytes) 58 18/02/08 16:48:04 INFO Executor: Running task 1.0 in stage 0.0 (TID 1) 59 18/02/08 16:48:04 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 424 ms on localhost (executor driver) (1/2) 60 18/02/08 16:48:04 INFO HadoopRDD: Input split: file:/project/SparkRDD/input/second.txt:0+94 61 18/02/08 16:48:04 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1661 bytes result sent to driver 62 18/02/08 16:48:04 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 107 ms on localhost (executor driver) (2/2) 63 18/02/08 16:48:04 INFO DAGScheduler: ShuffleMapStage 0 (mapToPair at TestMain00.java:68) finished in 0.556 s 64 18/02/08 16:48:04 INFO DAGScheduler: looking for newly runnable stages 65 18/02/08 16:48:04 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 66 18/02/08 16:48:04 INFO DAGScheduler: running: Set() 67 18/02/08 16:48:04 INFO DAGScheduler: waiting: Set(ShuffleMapStage 1, ResultStage 2) 68 18/02/08 16:48:04 INFO DAGScheduler: failed: Set() 69 18/02/08 16:48:04 INFO DAGScheduler: Submitting ShuffleMapStage 1 (MapPartitionsRDD[5] at mapToPair at TestMain00.java:84), which has no missing parents 70 18/02/08 16:48:04 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 4.3 KB, free 347.8 MB) 71 18/02/08 16:48:04 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.4 KB, free 347.8 MB) 72 18/02/08 16:48:04 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.154.134:49148 (size: 2.4 KB, free: 348.0 MB) 73 18/02/08 16:48:04 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:996 74 18/02/08 16:48:04 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 1 (MapPartitionsRDD[5] at mapToPair at TestMain00.java:84) 75 18/02/08 16:48:04 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks 76 18/02/08 16:48:04 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, localhost, executor driver, partition 0, ANY, 5746 bytes) 77 18/02/08 16:48:04 INFO Executor: Running task 0.0 in stage 1.0 (TID 2) 78 18/02/08 16:48:05 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks out of 2 blocks 79 18/02/08 16:48:05 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 15 ms 80 18/02/08 16:48:05 INFO Executor: Finished task 0.0 in stage 1.0 (TID 2). 2052 bytes result sent to driver 81 18/02/08 16:48:05 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, localhost, executor driver, partition 1, ANY, 5746 bytes) 82 18/02/08 16:48:05 INFO Executor: Running task 1.0 in stage 1.0 (TID 3) 83 18/02/08 16:48:05 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 137 ms on localhost (executor driver) (1/2) 84 18/02/08 16:48:05 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks out of 2 blocks 85 18/02/08 16:48:05 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms 86 18/02/08 16:48:05 INFO Executor: Finished task 1.0 in stage 1.0 (TID 3). 2052 bytes result sent to driver 87 18/02/08 16:48:05 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 60 ms on localhost (executor driver) (2/2) 88 18/02/08 16:48:05 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 89 18/02/08 16:48:05 INFO DAGScheduler: ShuffleMapStage 1 (mapToPair at TestMain00.java:84) finished in 0.178 s 90 18/02/08 16:48:05 INFO DAGScheduler: looking for newly runnable stages 91 18/02/08 16:48:05 INFO DAGScheduler: running: Set() 92 18/02/08 16:48:05 INFO DAGScheduler: waiting: Set(ResultStage 2) 93 18/02/08 16:48:05 INFO DAGScheduler: failed: Set() 94 18/02/08 16:48:05 INFO DAGScheduler: Submitting ResultStage 2 (MapPartitionsRDD[8] at saveAsTextFile at TestMain00.java:105), which has no missing parents 95 18/02/08 16:48:05 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 73.4 KB, free 347.7 MB) 96 18/02/08 16:48:05 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 26.6 KB, free 347.7 MB) 97 18/02/08 16:48:05 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.154.134:49148 (size: 26.6 KB, free: 347.9 MB) 98 18/02/08 16:48:05 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:996 99 18/02/08 16:48:05 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 2 (MapPartitionsRDD[8] at saveAsTextFile at TestMain00.java:105) 100 18/02/08 16:48:05 INFO TaskSchedulerImpl: Adding task set 2.0 with 1 tasks 101 18/02/08 16:48:05 INFO TaskSetManager: Starting task 0.0 in stage 2.0 (TID 4, localhost, executor driver, partition 0, ANY, 5757 bytes) 102 18/02/08 16:48:05 INFO Executor: Running task 0.0 in stage 2.0 (TID 4) 103 18/02/08 16:48:05 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks out of 2 blocks 104 18/02/08 16:48:05 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 1 ms 105 18/02/08 16:48:05 INFO FileOutputCommitter: File Output Committer Algorithm version is 1 106 18/02/08 16:48:05 INFO FileOutputCommitter: Saved output of task 'attempt_20180208164803_0002_m_000000_4' to file:/project/SparkRDD/output/_temporary/0/task_20180208164803_0002_m_000000 107 18/02/08 16:48:05 INFO SparkHadoopMapRedUtil: attempt_20180208164803_0002_m_000000_4: Committed 108 18/02/08 16:48:05 INFO Executor: Finished task 0.0 in stage 2.0 (TID 4). 1890 bytes result sent to driver 109 18/02/08 16:48:05 INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID 4) in 218 ms on localhost (executor driver) (1/1) 110 18/02/08 16:48:05 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool 111 18/02/08 16:48:05 INFO DAGScheduler: ResultStage 2 (saveAsTextFile at TestMain00.java:105) finished in 0.218 s 112 18/02/08 16:48:05 INFO DAGScheduler: Job 0 finished: saveAsTextFile at TestMain00.java:105, took 1.457949 s 113 18/02/08 16:48:05 INFO SparkUI: Stopped Spark web UI at http://192.168.154.134:4040 114 18/02/08 16:48:05 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 115 18/02/08 16:48:05 INFO MemoryStore: MemoryStore cleared 116 18/02/08 16:48:05 INFO BlockManager: BlockManager stopped 117 18/02/08 16:48:05 INFO BlockManagerMaster: BlockManagerMaster stopped 118 18/02/08 16:48:05 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 119 18/02/08 16:48:05 INFO SparkContext: Successfully stopped SparkContext 120 18/02/08 16:48:05 INFO ShutdownHookManager: Shutdown hook called 121 18/02/08 16:48:05 INFO ShutdownHookManager: Deleting directory /tmp/spark-0dba6634-7bc4-49f1-93b7-97f6623dbf08
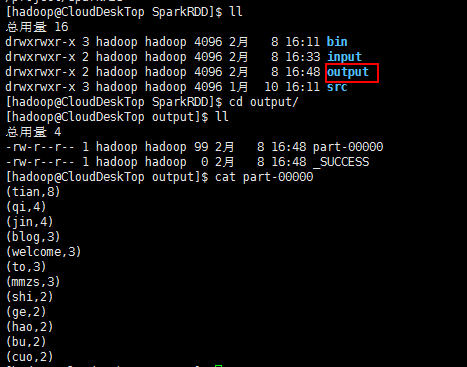
查看输出目录下是否有数据生成如下图:
3.2、使用Java开发的集群Spark应用
A、在工程目录SparkRDD下创建一个用于存储打包文件的目录jarTest
[hadoop@CloudDeskTop software]$ mkdir -p /project/SparkRDD/jarTest
//集群上输入目录下的数据文件 [hadoop@master02 install]$ hdfs dfs -ls /spark Found 1 items drwxr-xr-x - hadoop supergroup 0 2018-01-05 15:14 /spark/input [hadoop@master02 install]$ hdfs dfs -ls /spark/input Found 1 items -rw-r--r-- 3 hadoop supergroup 66 2018-01-05 15:14 /spark/input/wordcount [hadoop@master02 install]$ hdfs dfs -cat /spark/input/wordcount my name is ligang my age is 35 my height is 1.67 my weight is 118
B、开发源代码如下:
package com.mmzs.bigdata.spark.core.cluster; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.util.Arrays; import java.util.Iterator; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; public class TestMain01 { /** * 数据输入路径 */ private static final String IN_PATH="hdfs://ns1/spark/input"; /** * 数据输出路径 */ private static final String OUT_PATH="hdfs://ns1/spark/output"; static{ Configuration conf=new Configuration(); Path outPath=new Path(OUT_PATH); try { FileSystem dfs=FileSystem.get(new URI("hdfs://ns1/"), conf, "hadoop"); if(dfs.exists(outPath))dfs.delete(outPath, true); } catch (IOException | InterruptedException | URISyntaxException e) { e.printStackTrace(); } } public static void main(String[] args) { SparkConf conf=new SparkConf(); conf.setAppName("Java Spark Cluster"); //conf.setMaster("local");//本地运行模式 //根据Spark配置生成Spark上下文 JavaSparkContext jsc=new JavaSparkContext(conf); //读取本地的文本文件成内存中的RDD集合对象 JavaRDD<String> lineRdd=jsc.textFile(IN_PATH); //切分每一行的字串为单词数组,并将字串数组中的单词字串释放到外层的JavaRDD集合中 JavaRDD<String> flatMapRdd=lineRdd.flatMap(new FlatMapFunction<String,String>(){ @Override public Iterator<String> call(String line) throws Exception { String[] words=line.split(" "); List<String> list=Arrays.asList(words); Iterator<String> its=list.iterator(); return its; } }); //为JavaRDD集合中的每一个单词进行计数,将其转换为元组 JavaPairRDD<String, Integer> mapRdd=flatMapRdd.mapToPair(new PairFunction<String, String,Integer>(){ @Override public Tuple2<String,Integer> call(String word) throws Exception { return new Tuple2<String,Integer>(word,1); } }); //根据元组中的第一个元素(Key)进行分组并统计单词出现的次数 JavaPairRDD<String, Integer> reduceRdd=mapRdd.reduceByKey(new Function2<Integer,Integer,Integer>(){ @Override public Integer call(Integer pre, Integer next) throws Exception { return pre+next; } }); //将单词元组中的元素反序以方便后续排序 JavaPairRDD<Integer, String> mapRdd02=reduceRdd.mapToPair(new PairFunction<Tuple2<String, Integer>,Integer,String>(){ @Override public Tuple2<Integer, String> call(Tuple2<String, Integer> wordTuple) throws Exception { return new Tuple2<Integer,String>(wordTuple._2,wordTuple._1); } }); //将JavaRDD集合中的单词按出现次数进行将序排列 JavaPairRDD<Integer, String> sortRdd=mapRdd02.sortByKey(false, 1); //排序之后将元组中的顺序换回来 JavaPairRDD<String, Integer> mapRdd03=sortRdd.mapToPair(new PairFunction<Tuple2<Integer, String>,String,Integer>(){ @Override public Tuple2<String, Integer> call(Tuple2<Integer, String> wordTuple) throws Exception { return new Tuple2<String, Integer>(wordTuple._2,wordTuple._1); } }); //存储统计之后的结果到磁盘文件中去 mapRdd03.saveAsTextFile(OUT_PATH); //关闭Spark上下文 jsc.close(); } }
C、打包Spark应用到jarTest目录下
#删除之前的输出目录
[hadoop@CloudDeskTop bin]$ hdfs dfs -rm -r /spark/output
#切换到Spark工程目录下的bin目录下将com文件夹打包至工程目录下的clusterdist目录下
[hadoop@CloudDeskTop software]$ cd /project/SparkRDD/bin/
[hadoop@CloudDeskTop bin]$ jar -cvf /project/SparkRDD/jarTest/wordcount01.jar com/
D、提交Job到Spark集群
#提交Job
[hadoop@CloudDeskTop software]$ cd /software/spark-2.1.1/bin/
[hadoop@CloudDeskTop bin]$ ./spark-submit --master spark://master01:7077 --class com.mmzs.bigdata.spark.core.cluster.TestMain01 /project/SparkRDD/jarTest/wordcount01.jar 1
1 [hadoop@CloudDeskTop src]$ cd /software/spark-2.1.1/bin/ 2 [hadoop@CloudDeskTop bin]$ ./spark-submit --master spark://master01:7077 --class com.mmzs.bigdata.spark.core.cluster.TestMain01 /project/SparkRDD/jarTest/wordcount01.jar 1 3 18/02/08 17:10:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 4 18/02/08 17:10:08 INFO spark.SparkContext: Running Spark version 2.1.1 5 18/02/08 17:10:08 WARN spark.SparkContext: Support for Java 7 is deprecated as of Spark 2.0.0 6 18/02/08 17:10:08 INFO spark.SecurityManager: Changing view acls to: hadoop 7 18/02/08 17:10:08 INFO spark.SecurityManager: Changing modify acls to: hadoop 8 18/02/08 17:10:08 INFO spark.SecurityManager: Changing view acls groups to: 9 18/02/08 17:10:08 INFO spark.SecurityManager: Changing modify acls groups to: 10 18/02/08 17:10:08 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set() 11 18/02/08 17:10:09 INFO util.Utils: Successfully started service 'sparkDriver' on port 34342. 12 18/02/08 17:10:10 INFO spark.SparkEnv: Registering MapOutputTracker 13 18/02/08 17:10:10 INFO spark.SparkEnv: Registering BlockManagerMaster 14 18/02/08 17:10:10 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 15 18/02/08 17:10:10 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 16 18/02/08 17:10:10 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-a153fe5d-a20a-4b99-adbe-cd63c15eb585 17 18/02/08 17:10:10 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB 18 18/02/08 17:10:10 INFO spark.SparkEnv: Registering OutputCommitCoordinator 19 18/02/08 17:10:10 INFO util.log: Logging initialized @10611ms 20 18/02/08 17:10:11 INFO server.Server: jetty-9.2.z-SNAPSHOT 21 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1b780c4a{/jobs,null,AVAILABLE,@Spark} 22 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@666edc5c{/jobs/json,null,AVAILABLE,@Spark} 23 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7845508d{/jobs/job,null,AVAILABLE,@Spark} 24 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@eab96ab{/jobs/job/json,null,AVAILABLE,@Spark} 25 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2330bc13{/stages,null,AVAILABLE,@Spark} 26 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@548b9571{/stages/json,null,AVAILABLE,@Spark} 27 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@18005914{/stages/stage,null,AVAILABLE,@Spark} 28 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3ed83c5b{/stages/stage/json,null,AVAILABLE,@Spark} 29 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@66629a98{/stages/pool,null,AVAILABLE,@Spark} 30 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5393a5ab{/stages/pool/json,null,AVAILABLE,@Spark} 31 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@261a86b{/storage,null,AVAILABLE,@Spark} 32 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@59780a05{/storage/json,null,AVAILABLE,@Spark} 33 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@57d9fc26{/storage/rdd,null,AVAILABLE,@Spark} 34 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@28394fd9{/storage/rdd/json,null,AVAILABLE,@Spark} 35 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4aa94430{/environment,null,AVAILABLE,@Spark} 36 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2ebbd19b{/environment/json,null,AVAILABLE,@Spark} 37 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2cbe2f15{/executors,null,AVAILABLE,@Spark} 38 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7a0522a5{/executors/json,null,AVAILABLE,@Spark} 39 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6725bd38{/executors/threadDump,null,AVAILABLE,@Spark} 40 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5ea9dc6f{/executors/threadDump/json,null,AVAILABLE,@Spark} 41 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@61c72bf6{/static,null,AVAILABLE,@Spark} 42 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5b1755a0{/,null,AVAILABLE,@Spark} 43 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@58f6aa18{/api,null,AVAILABLE,@Spark} 44 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2a193b49{/jobs/job/kill,null,AVAILABLE,@Spark} 45 18/02/08 17:10:11 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5e834b36{/stages/stage/kill,null,AVAILABLE,@Spark} 46 18/02/08 17:10:11 INFO server.ServerConnector: Started Spark@51f709d6{HTTP/1.1}{0.0.0.0:4040} 47 18/02/08 17:10:11 INFO server.Server: Started @11305ms 48 18/02/08 17:10:11 INFO util.Utils: Successfully started service 'SparkUI' on port 4040. 49 18/02/08 17:10:11 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.154.134:4040 50 18/02/08 17:10:11 INFO spark.SparkContext: Added JAR file:/project/SparkRDD/jarTest/wordcount01.jar at spark://192.168.154.134:34342/jars/wordcount01.jar with timestamp 1518081011640 51 18/02/08 17:10:11 INFO client.StandaloneAppClient$ClientEndpoint: Connecting to master spark://master01:7077... 52 18/02/08 17:10:12 INFO client.TransportClientFactory: Successfully created connection to master01/192.168.154.130:7077 after 137 ms (0 ms spent in bootstraps) 53 18/02/08 17:10:12 INFO cluster.StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20180208171013-0012 54 18/02/08 17:10:12 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 42259. 55 18/02/08 17:10:12 INFO netty.NettyBlockTransferService: Server created on 192.168.154.134:42259 56 18/02/08 17:10:12 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 57 18/02/08 17:10:12 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.154.134, 42259, None) 58 18/02/08 17:10:12 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20180208171013-0012/0 on worker-20180208121809-192.168.154.133-49922 (192.168.154.133:49922) with 4 cores 59 18/02/08 17:10:12 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20180208171013-0012/0 on hostPort 192.168.154.133:49922 with 4 cores, 1024.0 MB RAM 60 18/02/08 17:10:12 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20180208171013-0012/1 on worker-20180208121818-192.168.154.132-43679 (192.168.154.132:43679) with 4 cores 61 18/02/08 17:10:12 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20180208171013-0012/1 on hostPort 192.168.154.132:43679 with 4 cores, 1024.0 MB RAM 62 18/02/08 17:10:12 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20180208171013-0012/2 on worker-20180208121826-192.168.154.131-56071 (192.168.154.131:56071) with 4 cores 63 18/02/08 17:10:12 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20180208171013-0012/2 on hostPort 192.168.154.131:56071 with 4 cores, 1024.0 MB RAM 64 18/02/08 17:10:12 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.134:42259 with 366.3 MB RAM, BlockManagerId(driver, 192.168.154.134, 42259, None) 65 18/02/08 17:10:12 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.154.134, 42259, None) 66 18/02/08 17:10:12 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.154.134, 42259, None) 67 18/02/08 17:10:12 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20180208171013-0012/2 is now RUNNING 68 18/02/08 17:10:12 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20180208171013-0012/0 is now RUNNING 69 18/02/08 17:10:12 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20180208171013-0012/1 is now RUNNING 70 18/02/08 17:10:13 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7b33f19f{/metrics/json,null,AVAILABLE,@Spark} 71 18/02/08 17:10:14 INFO scheduler.EventLoggingListener: Logging events to hdfs://ns1/sparkLog/app-20180208171013-0012 72 18/02/08 17:10:14 INFO cluster.StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0 73 18/02/08 17:10:16 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 202.4 KB, free 366.1 MB) 74 18/02/08 17:10:17 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 23.8 KB, free 366.1 MB) 75 18/02/08 17:10:17 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.134:42259 (size: 23.8 KB, free: 366.3 MB) 76 18/02/08 17:10:17 INFO spark.SparkContext: Created broadcast 0 from textFile at TestMain01.java:54 77 18/02/08 17:10:17 INFO mapred.FileInputFormat: Total input paths to process : 1 78 18/02/08 17:10:18 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 79 18/02/08 17:10:18 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 80 18/02/08 17:10:18 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 81 18/02/08 17:10:18 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 82 18/02/08 17:10:18 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 83 18/02/08 17:10:18 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 84 18/02/08 17:10:18 INFO spark.SparkContext: Starting job: saveAsTextFile at TestMain01.java:103 85 18/02/08 17:10:18 INFO scheduler.DAGScheduler: Registering RDD 3 (mapToPair at TestMain01.java:68) 86 18/02/08 17:10:18 INFO scheduler.DAGScheduler: Registering RDD 5 (mapToPair at TestMain01.java:84) 87 18/02/08 17:10:18 INFO scheduler.DAGScheduler: Got job 0 (saveAsTextFile at TestMain01.java:103) with 1 output partitions 88 18/02/08 17:10:18 INFO scheduler.DAGScheduler: Final stage: ResultStage 2 (saveAsTextFile at TestMain01.java:103) 89 18/02/08 17:10:18 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 1) 90 18/02/08 17:10:18 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 1) 91 18/02/08 17:10:18 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at TestMain01.java:68), which has no missing parents 92 18/02/08 17:10:19 INFO memory.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.1 KB, free 366.1 MB) 93 18/02/08 17:10:19 INFO memory.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.8 KB, free 366.1 MB) 94 18/02/08 17:10:19 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.154.134:42259 (size: 2.8 KB, free: 366.3 MB) 95 18/02/08 17:10:19 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:996 96 18/02/08 17:10:19 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at TestMain01.java:68) 97 18/02/08 17:10:19 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 2 tasks 98 18/02/08 17:10:26 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.131:53934) with ID 2 99 18/02/08 17:10:26 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 192.168.154.131, executor 2, partition 0, ANY, 6040 bytes) 100 18/02/08 17:10:26 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 192.168.154.131, executor 2, partition 1, ANY, 6040 bytes) 101 18/02/08 17:10:26 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.131:42223 with 413.9 MB RAM, BlockManagerId(2, 192.168.154.131, 42223, None) 102 18/02/08 17:10:27 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.132:37901) with ID 1 103 18/02/08 17:10:29 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.132:53222 with 413.9 MB RAM, BlockManagerId(1, 192.168.154.132, 53222, None) 104 18/02/08 17:10:29 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.154.131:42223 (size: 2.8 KB, free: 413.9 MB) 105 18/02/08 17:10:30 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.131:42223 (size: 23.8 KB, free: 413.9 MB) 106 18/02/08 17:10:31 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.133:42166) with ID 0 107 18/02/08 17:10:31 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.133:49446 with 413.9 MB RAM, BlockManagerId(0, 192.168.154.133, 49446, None) 108 18/02/08 17:10:37 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 11480 ms on 192.168.154.131 (executor 2) (1/2) 109 18/02/08 17:10:37 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 11264 ms on 192.168.154.131 (executor 2) (2/2) 110 18/02/08 17:10:37 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 111 18/02/08 17:10:37 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (mapToPair at TestMain01.java:68) finished in 18.407 s 112 18/02/08 17:10:37 INFO scheduler.DAGScheduler: looking for newly runnable stages 113 18/02/08 17:10:37 INFO scheduler.DAGScheduler: running: Set() 114 18/02/08 17:10:37 INFO scheduler.DAGScheduler: waiting: Set(ShuffleMapStage 1, ResultStage 2) 115 18/02/08 17:10:37 INFO scheduler.DAGScheduler: failed: Set() 116 18/02/08 17:10:37 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 1 (MapPartitionsRDD[5] at mapToPair at TestMain01.java:84), which has no missing parents 117 18/02/08 17:10:37 INFO memory.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 4.3 KB, free 366.1 MB) 118 18/02/08 17:10:37 INFO memory.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.4 KB, free 366.1 MB) 119 18/02/08 17:10:37 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.154.134:42259 (size: 2.4 KB, free: 366.3 MB) 120 18/02/08 17:10:37 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:996 121 18/02/08 17:10:37 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 1 (MapPartitionsRDD[5] at mapToPair at TestMain01.java:84) 122 18/02/08 17:10:37 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 2 tasks 123 18/02/08 17:10:37 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, 192.168.154.131, executor 2, partition 0, NODE_LOCAL, 5810 bytes) 124 18/02/08 17:10:37 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, 192.168.154.131, executor 2, partition 1, NODE_LOCAL, 5810 bytes) 125 18/02/08 17:10:37 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.154.131:42223 (size: 2.4 KB, free: 413.9 MB) 126 18/02/08 17:10:38 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to 192.168.154.131:53934 127 18/02/08 17:10:38 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 1 is 158 bytes 128 18/02/08 17:10:38 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 725 ms on 192.168.154.131 (executor 2) (1/2) 129 18/02/08 17:10:38 INFO scheduler.DAGScheduler: ShuffleMapStage 1 (mapToPair at TestMain01.java:84) finished in 0.743 s 130 18/02/08 17:10:38 INFO scheduler.DAGScheduler: looking for newly runnable stages 131 18/02/08 17:10:38 INFO scheduler.DAGScheduler: running: Set() 132 18/02/08 17:10:38 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 2) 133 18/02/08 17:10:38 INFO scheduler.DAGScheduler: failed: Set() 134 18/02/08 17:10:38 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 710 ms on 192.168.154.131 (executor 2) (2/2) 135 18/02/08 17:10:38 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 136 18/02/08 17:10:38 INFO scheduler.DAGScheduler: Submitting ResultStage 2 (MapPartitionsRDD[8] at saveAsTextFile at TestMain01.java:103), which has no missing parents 137 18/02/08 17:10:38 INFO memory.MemoryStore: Block broadcast_3 stored as values in memory (estimated size 75.1 KB, free 366.0 MB) 138 18/02/08 17:10:38 INFO memory.MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 27.6 KB, free 366.0 MB) 139 18/02/08 17:10:38 INFO storage.BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.154.134:42259 (size: 27.6 KB, free: 366.2 MB) 140 18/02/08 17:10:38 INFO spark.SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:996 141 18/02/08 17:10:38 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 2 (MapPartitionsRDD[8] at saveAsTextFile at TestMain01.java:103) 142 18/02/08 17:10:38 INFO scheduler.TaskSchedulerImpl: Adding task set 2.0 with 1 tasks 143 18/02/08 17:10:38 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 2.0 (TID 4, 192.168.154.131, executor 2, partition 0, NODE_LOCAL, 5821 bytes) 144 18/02/08 17:10:38 INFO storage.BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.154.131:42223 (size: 27.6 KB, free: 413.9 MB) 145 18/02/08 17:10:38 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to 192.168.154.131:53934 146 18/02/08 17:10:38 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 157 bytes 147 18/02/08 17:10:40 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 2.0 (TID 4) in 1605 ms on 192.168.154.131 (executor 2) (1/1) 148 18/02/08 17:10:40 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool 149 18/02/08 17:10:40 INFO scheduler.DAGScheduler: ResultStage 2 (saveAsTextFile at TestMain01.java:103) finished in 1.610 s 150 18/02/08 17:10:40 INFO scheduler.DAGScheduler: Job 0 finished: saveAsTextFile at TestMain01.java:103, took 21.646030 s 151 18/02/08 17:10:40 INFO server.ServerConnector: Stopped Spark@51f709d6{HTTP/1.1}{0.0.0.0:4040} 152 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5e834b36{/stages/stage/kill,null,UNAVAILABLE,@Spark} 153 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2a193b49{/jobs/job/kill,null,UNAVAILABLE,@Spark} 154 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@58f6aa18{/api,null,UNAVAILABLE,@Spark} 155 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5b1755a0{/,null,UNAVAILABLE,@Spark} 156 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@61c72bf6{/static,null,UNAVAILABLE,@Spark} 157 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5ea9dc6f{/executors/threadDump/json,null,UNAVAILABLE,@Spark} 158 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6725bd38{/executors/threadDump,null,UNAVAILABLE,@Spark} 159 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7a0522a5{/executors/json,null,UNAVAILABLE,@Spark} 160 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2cbe2f15{/executors,null,UNAVAILABLE,@Spark} 161 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2ebbd19b{/environment/json,null,UNAVAILABLE,@Spark} 162 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@4aa94430{/environment,null,UNAVAILABLE,@Spark} 163 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@28394fd9{/storage/rdd/json,null,UNAVAILABLE,@Spark} 164 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@57d9fc26{/storage/rdd,null,UNAVAILABLE,@Spark} 165 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@59780a05{/storage/json,null,UNAVAILABLE,@Spark} 166 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@261a86b{/storage,null,UNAVAILABLE,@Spark} 167 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5393a5ab{/stages/pool/json,null,UNAVAILABLE,@Spark} 168 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@66629a98{/stages/pool,null,UNAVAILABLE,@Spark} 169 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@3ed83c5b{/stages/stage/json,null,UNAVAILABLE,@Spark} 170 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@18005914{/stages/stage,null,UNAVAILABLE,@Spark} 171 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@548b9571{/stages/json,null,UNAVAILABLE,@Spark} 172 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@2330bc13{/stages,null,UNAVAILABLE,@Spark} 173 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@eab96ab{/jobs/job/json,null,UNAVAILABLE,@Spark} 174 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7845508d{/jobs/job,null,UNAVAILABLE,@Spark} 175 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@666edc5c{/jobs/json,null,UNAVAILABLE,@Spark} 176 18/02/08 17:10:40 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1b780c4a{/jobs,null,UNAVAILABLE,@Spark} 177 18/02/08 17:10:40 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.154.134:4040 178 18/02/08 17:10:40 INFO cluster.StandaloneSchedulerBackend: Shutting down all executors 179 18/02/08 17:10:40 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down 180 18/02/08 17:10:41 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 181 18/02/08 17:10:41 INFO memory.MemoryStore: MemoryStore cleared 182 18/02/08 17:10:41 INFO storage.BlockManager: BlockManager stopped 183 18/02/08 17:10:41 INFO storage.BlockManagerMaster: BlockManagerMaster stopped 184 18/02/08 17:10:41 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 185 18/02/08 17:10:41 INFO spark.SparkContext: Successfully stopped SparkContext 186 18/02/08 17:10:41 INFO util.ShutdownHookManager: Shutdown hook called 187 18/02/08 17:10:41 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-876de51d-03a6-4d59-add0-ff90ad1e1287
E、查看输出目录下是否有数据生成
[hadoop@master02 install]$ hdfs dfs -ls /spark Found 2 items drwxr-xr-x - hadoop supergroup 0 2018-01-05 15:14 /spark/input drwxr-xr-x - hadoop supergroup 0 2018-02-08 17:10 /spark/output [hadoop@master02 install]$ hdfs dfs -ls /spark/output Found 2 items -rw-r--r-- 3 hadoop supergroup 0 2018-02-08 17:10 /spark/output/_SUCCESS -rw-r--r-- 3 hadoop supergroup 88 2018-02-08 17:10 /spark/output/part-00000 [hadoop@master02 install]$ hdfs dfs -cat /spark/output/part-00000 (is,4) (my,4) (118,1) (1.67,1) (35,1) (ligang,1) (weight,1) (name,1) (height,1) (age,1)
4、说明:
对于将Job提交到集群的情况,最好不要直接在Eclipse工程中测试,这种不可预测性太大,容易出现异常,如果需要直接在Eclipse中测试可以设置一下提交的master节点:
SparkConf conf=new SparkConf(); conf.setAppName("Java Spark Cluster"); //conf.setMaster("local");//本地运行模式 conf.setMaster("spark://master01:7077"); //根据Spark配置生成Spark上下文 JavaSparkContext jsc=new JavaSparkContext(conf);
同时因为Job中涉及到HDFS的文件操作,这需要连接到HDFS来完成,所以需要将Hadoop的配置文件拷贝到工程的根目录下
[hadoop@CloudDeskTop software]$ cd /software/hadoop-2.7.3/etc/hadoop/
[hadoop@CloudDeskTop hadoop]$ cp -a core-site.xml hdfs-site.xml /project/SparkRDD/src/
完成上述的操作之后就可以在Eclipse中直接测试了,但是经过实践操作发现这种在IDE环境中提交Job到集群的测试会抛出很多异常(比如mutable.List类型转换异常等)
1 log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory). 2 log4j:WARN Please initialize the log4j system properly. 3 log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. 4 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 5 18/02/08 17:20:16 INFO SparkContext: Running Spark version 2.1.1 6 18/02/08 17:20:16 WARN SparkContext: Support for Java 7 is deprecated as of Spark 2.0.0 7 18/02/08 17:20:16 INFO SecurityManager: Changing view acls to: hadoop 8 18/02/08 17:20:16 INFO SecurityManager: Changing modify acls to: hadoop 9 18/02/08 17:20:16 INFO SecurityManager: Changing view acls groups to: 10 18/02/08 17:20:16 INFO SecurityManager: Changing modify acls groups to: 11 18/02/08 17:20:16 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set() 12 18/02/08 17:20:17 INFO Utils: Successfully started service 'sparkDriver' on port 50465. 13 18/02/08 17:20:17 INFO SparkEnv: Registering MapOutputTracker 14 18/02/08 17:20:17 INFO SparkEnv: Registering BlockManagerMaster 15 18/02/08 17:20:17 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 16 18/02/08 17:20:17 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 17 18/02/08 17:20:17 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-dd6a1243-0a7c-49df-91ad-c0c70d0695a7 18 18/02/08 17:20:17 INFO MemoryStore: MemoryStore started with capacity 348.0 MB 19 18/02/08 17:20:17 INFO SparkEnv: Registering OutputCommitCoordinator 20 18/02/08 17:20:18 INFO Utils: Successfully started service 'SparkUI' on port 4040. 21 18/02/08 17:20:18 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.154.134:4040 22 18/02/08 17:20:18 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://master01:7077... 23 18/02/08 17:20:18 INFO TransportClientFactory: Successfully created connection to master01/192.168.154.130:7077 after 67 ms (0 ms spent in bootstraps) 24 18/02/08 17:20:18 INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20180208172019-0013 25 18/02/08 17:20:18 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20180208172019-0013/0 on worker-20180208121809-192.168.154.133-49922 (192.168.154.133:49922) with 4 cores 26 18/02/08 17:20:18 INFO StandaloneSchedulerBackend: Granted executor ID app-20180208172019-0013/0 on hostPort 192.168.154.133:49922 with 4 cores, 1024.0 MB RAM 27 18/02/08 17:20:18 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20180208172019-0013/1 on worker-20180208121818-192.168.154.132-43679 (192.168.154.132:43679) with 4 cores 28 18/02/08 17:20:18 INFO StandaloneSchedulerBackend: Granted executor ID app-20180208172019-0013/1 on hostPort 192.168.154.132:43679 with 4 cores, 1024.0 MB RAM 29 18/02/08 17:20:18 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20180208172019-0013/2 on worker-20180208121826-192.168.154.131-56071 (192.168.154.131:56071) with 4 cores 30 18/02/08 17:20:18 INFO StandaloneSchedulerBackend: Granted executor ID app-20180208172019-0013/2 on hostPort 192.168.154.131:56071 with 4 cores, 1024.0 MB RAM 31 18/02/08 17:20:18 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 56980. 32 18/02/08 17:20:18 INFO NettyBlockTransferService: Server created on 192.168.154.134:56980 33 18/02/08 17:20:18 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 34 18/02/08 17:20:18 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.154.134, 56980, None) 35 18/02/08 17:20:18 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180208172019-0013/1 is now RUNNING 36 18/02/08 17:20:18 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180208172019-0013/0 is now RUNNING 37 18/02/08 17:20:18 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.154.134:56980 with 348.0 MB RAM, BlockManagerId(driver, 192.168.154.134, 56980, None) 38 18/02/08 17:20:18 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.154.134, 56980, None) 39 18/02/08 17:20:18 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.154.134, 56980, None) 40 18/02/08 17:20:19 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20180208172019-0013/2 is now RUNNING 41 18/02/08 17:20:19 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0 42 18/02/08 17:20:21 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 199.5 KB, free 347.8 MB) 43 18/02/08 17:20:21 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 23.5 KB, free 347.8 MB) 44 18/02/08 17:20:21 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.134:56980 (size: 23.5 KB, free: 348.0 MB) 45 18/02/08 17:20:21 INFO SparkContext: Created broadcast 0 from textFile at TestMain01.java:55 46 18/02/08 17:20:22 INFO FileInputFormat: Total input paths to process : 1 47 18/02/08 17:20:22 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 48 18/02/08 17:20:22 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 49 18/02/08 17:20:22 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 50 18/02/08 17:20:22 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 51 18/02/08 17:20:22 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 52 18/02/08 17:20:22 INFO FileOutputCommitter: File Output Committer Algorithm version is 1 53 18/02/08 17:20:23 INFO SparkContext: Starting job: saveAsTextFile at TestMain01.java:104 54 18/02/08 17:20:23 INFO DAGScheduler: Registering RDD 3 (mapToPair at TestMain01.java:69) 55 18/02/08 17:20:23 INFO DAGScheduler: Registering RDD 5 (mapToPair at TestMain01.java:85) 56 18/02/08 17:20:23 INFO DAGScheduler: Got job 0 (saveAsTextFile at TestMain01.java:104) with 1 output partitions 57 18/02/08 17:20:23 INFO DAGScheduler: Final stage: ResultStage 2 (saveAsTextFile at TestMain01.java:104) 58 18/02/08 17:20:23 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 1) 59 18/02/08 17:20:23 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 1) 60 18/02/08 17:20:23 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at TestMain01.java:69), which has no missing parents 61 18/02/08 17:20:23 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.1 KB, free 347.8 MB) 62 18/02/08 17:20:23 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.8 KB, free 347.8 MB) 63 18/02/08 17:20:23 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.154.134:56980 (size: 2.8 KB, free: 348.0 MB) 64 18/02/08 17:20:23 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:996 65 18/02/08 17:20:23 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at mapToPair at TestMain01.java:69) 66 18/02/08 17:20:23 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks 67 18/02/08 17:20:29 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.133:44738) with ID 0 68 18/02/08 17:20:29 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 192.168.154.133, executor 0, partition 0, ANY, 5980 bytes) 69 18/02/08 17:20:29 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 192.168.154.133, executor 0, partition 1, ANY, 5980 bytes) 70 18/02/08 17:20:30 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.154.133:60954 with 413.9 MB RAM, BlockManagerId(0, 192.168.154.133, 60954, None) 71 18/02/08 17:20:32 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.154.133:60954 (size: 2.8 KB, free: 413.9 MB) 72 18/02/08 17:20:33 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.132:51240) with ID 1 73 18/02/08 17:20:33 WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, 192.168.154.133, executor 0): java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD 74 at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2083) 75 at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1261) 76 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1996) 77 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 78 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 79 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 80 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990) 81 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 82 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 83 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 84 at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370) 85 at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75) 86 at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114) 87 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85) 88 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53) 89 at org.apache.spark.scheduler.Task.run(Task.scala:99) 90 at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322) 91 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 92 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 93 at java.lang.Thread.run(Thread.java:745) 94 95 18/02/08 17:20:33 INFO TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0) on 192.168.154.133, executor 0: java.lang.ClassCastException (cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD) [duplicate 1] 96 18/02/08 17:20:33 INFO TaskSetManager: Starting task 0.1 in stage 0.0 (TID 2, 192.168.154.132, executor 1, partition 0, ANY, 5980 bytes) 97 18/02/08 17:20:33 INFO TaskSetManager: Starting task 1.1 in stage 0.0 (TID 3, 192.168.154.133, executor 0, partition 1, ANY, 5980 bytes) 98 18/02/08 17:20:33 INFO TaskSetManager: Lost task 1.1 in stage 0.0 (TID 3) on 192.168.154.133, executor 0: java.lang.ClassCastException (cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD) [duplicate 2] 99 18/02/08 17:20:33 INFO TaskSetManager: Starting task 1.2 in stage 0.0 (TID 4, 192.168.154.132, executor 1, partition 1, ANY, 5980 bytes) 100 18/02/08 17:20:33 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.154.132:36228 with 413.9 MB RAM, BlockManagerId(1, 192.168.154.132, 36228, None) 101 18/02/08 17:20:35 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.154.132:36228 (size: 2.8 KB, free: 413.9 MB) 102 18/02/08 17:20:35 INFO TaskSetManager: Lost task 0.1 in stage 0.0 (TID 2) on 192.168.154.132, executor 1: java.lang.ClassCastException (cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD) [duplicate 3] 103 18/02/08 17:20:35 INFO TaskSetManager: Starting task 0.2 in stage 0.0 (TID 5, 192.168.154.132, executor 1, partition 0, ANY, 5980 bytes) 104 18/02/08 17:20:35 INFO TaskSetManager: Lost task 1.2 in stage 0.0 (TID 4) on 192.168.154.132, executor 1: java.lang.ClassCastException (cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD) [duplicate 4] 105 18/02/08 17:20:35 INFO TaskSetManager: Starting task 1.3 in stage 0.0 (TID 6, 192.168.154.132, executor 1, partition 1, ANY, 5980 bytes) 106 18/02/08 17:20:36 INFO TaskSetManager: Lost task 0.2 in stage 0.0 (TID 5) on 192.168.154.132, executor 1: java.lang.ClassCastException (cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD) [duplicate 5] 107 18/02/08 17:20:36 INFO TaskSetManager: Starting task 0.3 in stage 0.0 (TID 7, 192.168.154.133, executor 0, partition 0, ANY, 5980 bytes) 108 18/02/08 17:20:36 INFO TaskSetManager: Lost task 1.3 in stage 0.0 (TID 6) on 192.168.154.132, executor 1: java.lang.ClassCastException (cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD) [duplicate 6] 109 18/02/08 17:20:36 ERROR TaskSetManager: Task 1 in stage 0.0 failed 4 times; aborting job 110 18/02/08 17:20:36 INFO TaskSchedulerImpl: Cancelling stage 0 111 18/02/08 17:20:36 INFO TaskSchedulerImpl: Stage 0 was cancelled 112 18/02/08 17:20:36 INFO TaskSetManager: Lost task 0.3 in stage 0.0 (TID 7) on 192.168.154.133, executor 0: java.lang.ClassCastException (cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD) [duplicate 7] 113 18/02/08 17:20:36 INFO DAGScheduler: ShuffleMapStage 0 (mapToPair at TestMain01.java:69) failed in 12.402 s due to Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 6, 192.168.154.132, executor 1): java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD 114 at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2083) 115 at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1261) 116 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1996) 117 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 118 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 119 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 120 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990) 121 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 122 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 123 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 124 at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370) 125 at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75) 126 at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114) 127 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85) 128 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53) 129 at org.apache.spark.scheduler.Task.run(Task.scala:99) 130 at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322) 131 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 132 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 133 at java.lang.Thread.run(Thread.java:745) 134 135 Driver stacktrace: 136 18/02/08 17:20:36 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 137 18/02/08 17:20:36 INFO DAGScheduler: Job 0 failed: saveAsTextFile at TestMain01.java:104, took 13.081248 s 138 Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 6, 192.168.154.132, executor 1): java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD 139 at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2083) 140 at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1261) 141 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1996) 142 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 143 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 144 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 145 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990) 146 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 147 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 148 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 149 at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370) 150 at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75) 151 at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114) 152 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85) 153 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53) 154 at org.apache.spark.scheduler.Task.run(Task.scala:99) 155 at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322) 156 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 157 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 158 at java.lang.Thread.run(Thread.java:745) 159 160 Driver stacktrace: 161 at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1435) 162 at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1423) 163 at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1422) 164 at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) 165 at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) 166 at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1422) 167 at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:802) 168 at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:802) 169 at scala.Option.foreach(Option.scala:257) 170 at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:802) 171 at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1650) 172 at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1605) 173 at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1594) 174 at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48) 175 at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:628) 176 at org.apache.spark.SparkContext.runJob(SparkContext.scala:1925) 177 at org.apache.spark.SparkContext.runJob(SparkContext.scala:1938) 178 at org.apache.spark.SparkContext.runJob(SparkContext.scala:1958) 179 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply$mcV$sp(PairRDDFunctions.scala:1226) 180 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1168) 181 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$1.apply(PairRDDFunctions.scala:1168) 182 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) 183 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) 184 at org.apache.spark.rdd.RDD.withScope(RDD.scala:362) 185 at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopDataset(PairRDDFunctions.scala:1168) 186 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply$mcV$sp(PairRDDFunctions.scala:1071) 187 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1037) 188 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$4.apply(PairRDDFunctions.scala:1037) 189 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) 190 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) 191 at org.apache.spark.rdd.RDD.withScope(RDD.scala:362) 192 at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1037) 193 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply$mcV$sp(PairRDDFunctions.scala:963) 194 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:963) 195 at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopFile$1.apply(PairRDDFunctions.scala:963) 196 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) 197 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) 198 at org.apache.spark.rdd.RDD.withScope(RDD.scala:362) 199 at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:962) 200 at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply$mcV$sp(RDD.scala:1489) 201 at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1468) 202 at org.apache.spark.rdd.RDD$$anonfun$saveAsTextFile$1.apply(RDD.scala:1468) 203 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) 204 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) 205 at org.apache.spark.rdd.RDD.withScope(RDD.scala:362) 206 at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1468) 207 at org.apache.spark.api.java.JavaRDDLike$class.saveAsTextFile(JavaRDDLike.scala:550) 208 at org.apache.spark.api.java.AbstractJavaRDDLike.saveAsTextFile(JavaRDDLike.scala:45) 209 at com.mmzs.bigdata.spark.core.cluster.TestMain01.main(TestMain01.java:104) 210 Caused by: java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD 211 at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2083) 212 at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1261) 213 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1996) 214 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 215 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 216 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 217 at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990) 218 at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915) 219 at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798) 220 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350) 221 at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370) 222 at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75) 223 at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114) 224 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:85) 225 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53) 226 at org.apache.spark.scheduler.Task.run(Task.scala:99) 227 at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322) 228 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) 229 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) 230 at java.lang.Thread.run(Thread.java:745) 231 18/02/08 17:20:36 INFO SparkContext: Invoking stop() from shutdown hook 232 18/02/08 17:20:36 INFO SparkUI: Stopped Spark web UI at http://192.168.154.134:4040 233 18/02/08 17:20:36 INFO StandaloneSchedulerBackend: Shutting down all executors 234 18/02/08 17:20:36 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down 235 18/02/08 17:20:36 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 236 18/02/08 17:20:36 INFO MemoryStore: MemoryStore cleared 237 18/02/08 17:20:36 INFO BlockManager: BlockManager stopped 238 18/02/08 17:20:36 INFO BlockManagerMaster: BlockManagerMaster stopped 239 18/02/08 17:20:36 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 240 18/02/08 17:20:36 INFO SparkContext: Successfully stopped SparkContext 241 18/02/08 17:20:36 INFO ShutdownHookManager: Shutdown hook called 242 18/02/08 17:20:36 INFO ShutdownHookManager: Deleting directory /tmp/spark-3d8e7ee4-202e-48e8-aed3-48df843fbf19
解决办法:
由网络或者gc引起,worker或executor没有接收到executor或task的心跳反馈。
提高 spark.network.timeout 的值,根据情况改成300(5min)或更高。
默认为 120(120s),配置所有网络传输的延时,如果没有主动在(spark-2.1.1/conf/spark-defaults.conf)配置文件中设置以下参数,默认覆盖其属性
- spark.core.connection.ack.wait.timeout
- spark.akka.timeout
- spark.storage.blockManagerSlaveTimeoutMs
- spark.shuffle.io.connectionTimeout
- spark.rpc.askTimeout or spark.rpc.lookupTimeout

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}