

HBase的java客户端测试(二)---DML操作
测试准备
【首先同步时间:】
for node in CloudDeskTop master01 master02 slave01 slave02 slave03;do ssh $node "date -s '2017-12-30 21:32:30'";done
【slave各节点启动zookeeper集群:】
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh start && cd - && jps
【master01启动HDFS集群:】
cd /software/ && start-dfs.sh && jps
【master01启动HBase:】
cd /software/hbase-1.2.6/bin && start-hbase.sh && jps
【master02上启动HBase:】
cd /software/hbase-1.2.6/bin && hbase-daemon.sh start master && jps
如有节点启动出现故障:
单独启动master:
cd /software/hbase-1.2.6/bin && hbase-daemon.sh start master && jps
单独启动regionserver:
cd /software/hbase-1.2.6/bin && hbase-daemon.sh start regionserver && jps
通过命令终端查看:
hbase(main):009:0> status
通过web终端查看:
http://master01的IP地址:16010/
【在主机CloudDeskTop导入java客户端开发所需jar包:】HBase1.2.6-All.zip
测试目标:
运用java代码编写程序操作HBase数据库,本次测试致力于对DML语法的java客户端操作;


1 package com.mmzs.bigdata.hbase.dml; 2 3 import java.io.ByteArrayInputStream; 4 import java.io.ByteArrayOutputStream; 5 import java.io.IOException; 6 import java.io.ObjectInputStream; 7 import java.io.ObjectOutputStream; 8 import java.util.ArrayList; 9 import java.util.Date; 10 import java.util.HashMap; 11 import java.util.List; 12 import java.util.Map; 13 import java.util.Map.Entry; 14 import java.util.Set; 15 16 import org.apache.hadoop.conf.Configuration; 17 import org.apache.hadoop.hbase.Cell; 18 import org.apache.hadoop.hbase.CellUtil; 19 import org.apache.hadoop.hbase.HBaseConfiguration; 20 import org.apache.hadoop.hbase.TableName; 21 import org.apache.hadoop.hbase.client.Admin; 22 import org.apache.hadoop.hbase.client.Connection; 23 import org.apache.hadoop.hbase.client.ConnectionFactory; 24 import org.apache.hadoop.hbase.client.Delete; 25 import org.apache.hadoop.hbase.client.Get; 26 import org.apache.hadoop.hbase.client.Put; 27 import org.apache.hadoop.hbase.client.Result; 28 import org.apache.hadoop.hbase.client.ResultScanner; 29 import org.apache.hadoop.hbase.client.Scan; 30 import org.apache.hadoop.hbase.client.Table; 31 import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp; 32 import org.apache.hadoop.hbase.filter.FilterList; 33 import org.apache.hadoop.hbase.filter.PrefixFilter; 34 import org.apache.hadoop.hbase.filter.RowFilter; 35 import org.apache.hadoop.hbase.filter.SingleColumnValueFilter; 36 import org.apache.hadoop.hbase.filter.SubstringComparator; 37 38 /** 39 * @author hadoop 40 * 41 * [HTable].put|delete|get|getScanner([Scan].addColumn|setStartRow|setStopRow|setFilter([FilterList].addFilter)) 42 * 43 */ 44 public class DMLMain { 45 /** 46 * 操作HBase集群的客户端 47 */ 48 private static Admin admin; 49 50 private static Connection conn; 51 52 static{ 53 //创建HBase配置 54 Configuration conf=HBaseConfiguration.create(); 55 conf.set("hbase.zookeeper.quorum", "slave01:2181,slave02:2181,slave03:2181"); 56 try { 57 //根据HBase配置获取HBase集群连接 58 conn=ConnectionFactory.createConnection(conf); 59 admin=conn.getAdmin(); 60 } catch (IOException e) { 61 e.printStackTrace(); 62 } 63 } 64 65 public static void main(String[] args) { 66 //这种添加方式的读数据在后面查找时容易出IO异常,因为中间涉及了二进制转换 67 // put("mmzs:myuser","008","base","userName","ligang00"); 68 // put("mmzs:myuser","008","base","userAge","18"); 69 // put("mmzs:myuser","008","base","gender","woman"); 70 71 /* Date d=new Date(); 72 System.out.println(d); 73 byte[] b=getBytes(d); 74 System.out.println(b); 75 Object obj=getObject(b); 76 System.out.println(obj);*/ 77 78 //添加数据 79 /* Map<String,Map<String,Map<String,Object>>> dataMap=new HashMap<String,Map<String,Map<String,Object>>>(); 80 81 Map<String,Map<String,Object>> familyMap=new HashMap<String,Map<String,Object>>(); 82 // dataMap.put("ligang+28+1.67", familyMap); 83 // dataMap.put("zhanghua+28+1.67", familyMap); 84 // dataMap.put("zhanghua+29+1.67", familyMap); 85 // dataMap.put("ligang+28+1.72", familyMap); 86 // dataMap.put("wangwu+29+1.82", familyMap); 87 dataMap.put("001", familyMap); 88 dataMap.put("002", familyMap); 89 dataMap.put("003", familyMap); 90 dataMap.put("004", familyMap); 91 dataMap.put("005", familyMap); 92 dataMap.put("006", familyMap); 93 94 Map<String,Object> keyValMap=new HashMap<String,Object>(); 95 keyValMap.put("height", 1.68); 96 keyValMap.put("weight", 75.5); 97 keyValMap.put("gender", "women"); 98 keyValMap.put("username", "zhangsan"); 99 100 familyMap.put("extra", keyValMap); 101 102 puts("mmzs:myuser",dataMap);*/ 103 104 105 // delete("mmzs:myuser","005"); 106 // delete("mmzs:myuser","002","extra","username"); 107 // deletes("mmzs:myuser","001","002","003","004","005","006","007","008"); 108 109 // get("mmzs:myuser","005"); 110 111 // scan("mmzs:myuser"); 112 113 // scanByCondition("mmzs:myuser"); 114 } 115 116 /** 117 * 将二进制流读到内存通过反序列化重构生成对象 118 * @param object 119 * @return 120 */ 121 private static Object getObject(byte[] b){ 122 ObjectInputStream ois=null; 123 try { 124 ByteArrayInputStream bais=new ByteArrayInputStream(b); 125 ois=new ObjectInputStream(bais); 126 return ois.readObject(); 127 } catch (IOException e) { 128 e.printStackTrace(); 129 } catch (ClassNotFoundException e) { 130 e.printStackTrace(); 131 }finally{ 132 try{ 133 if(null!=ois)ois.close(); 134 }catch(IOException e){ 135 e.printStackTrace(); 136 } 137 } 138 return null; 139 } 140 141 /** 142 * 将对象序列化成二进制数组 143 * @param object 144 * @return 145 */ 146 private static byte[] getBytes(Object object){ 147 ObjectOutputStream oos=null; 148 try { 149 ByteArrayOutputStream baos=new ByteArrayOutputStream(); 150 oos=new ObjectOutputStream(baos); 151 oos.writeObject(object); 152 oos.flush(); 153 return baos.toByteArray(); 154 } catch (IOException e) { 155 e.printStackTrace(); 156 }finally{ 157 try{ 158 if(null!=oos)oos.close(); 159 }catch(IOException e){ 160 e.printStackTrace(); 161 } 162 } 163 return null; 164 } 165 166 /** 167 * 打印结果集 168 * @param ress 169 */ 170 private static void printResult(ResultScanner rss){ 171 //遍历结果集,每一个Result对应一行记录(即对应一个RowKey) 172 for(Result res:rss){ 173 String rowKey=new String(res.getRow()); 174 List<Cell> cellList=res.listCells(); 175 for(Cell cell:cellList){ 176 //获取当前键值对所在的列族名称 177 String familyName=new String(CellUtil.cloneFamily(cell)); 178 //获取当前键值对的键(Key) 179 String key=new String(CellUtil.cloneQualifier(cell)); 180 //获取当前键值对的值(Value) 181 String value=getObject(CellUtil.cloneValue(cell)).toString(); 182 183 System.out.println(rowKey+"\t"+familyName+"\t"+key+":"+value); 184 } 185 } 186 } 187 188 /** 189 * 条件查询 190 * @param tabNameStr 191 * 192 * PrefixFilter和RowFilter都是基于行键(RowKey)的过滤器 193 */ 194 public static void scanByCondition(String tabNameStr){ 195 TableName tabName=TableName.valueOf(tabNameStr); 196 Scan scan=new Scan(); 197 198 //前缀过滤器,行键前缀是ligang的 199 PrefixFilter prefixFilter=new PrefixFilter("ligang".getBytes()); 200 201 //子串过滤,行键中包含1.72的 202 RowFilter rowFilter=new RowFilter(CompareOp.EQUAL,new SubstringComparator("28")); 203 204 //行键过滤器,列族 列名 比较操作 值,显示不包含满足条件的 205 SingleColumnValueFilter scvFilter=new SingleColumnValueFilter("base".getBytes(),"userName".getBytes(),CompareOp.EQUAL,new SubstringComparator("ligang")); 206 207 //FilterList.Operator.MUST_PASS_ALL相当于and,FilterList.Operator.MUST_PASS_ONE相当于or 208 FilterList filterList=new FilterList(FilterList.Operator.MUST_PASS_ALL); 209 //添加使用的过滤器 210 // filterList.addFilter(prefixFilter); 211 // filterList.addFilter(rowFilter); 212 filterList.addFilter(scvFilter); 213 214 // scan.setFilter(prefixFilter); 215 216 scan.setFilter(filterList);//设置过滤 217 try { 218 Table table=conn.getTable(tabName); 219 ResultScanner ress=table.getScanner(scan); 220 printResult(ress); 221 } catch (IOException e) { 222 e.printStackTrace(); 223 } 224 } 225 226 /** 227 * 查询多条记录 228 * @param tabNameStr 229 * @param rowKey 230 */ 231 public static void scan(String tabNameStr){ 232 TableName tabName=TableName.valueOf(tabNameStr); 233 234 Scan scan=new Scan(); 235 236 //过滤查询结果集中的字段 237 scan.addColumn("extra".getBytes(), "height".getBytes()); 238 scan.addColumn("extra".getBytes(), "weight".getBytes()); 239 240 //设置查询的起始和结束行索引(通过行键RowKey指定) 241 scan.setStartRow("002".getBytes()); 242 scan.setStopRow("006".getBytes()); 243 244 try { 245 Table table=conn.getTable(tabName); 246 //查询多行返回一个结果集 247 ResultScanner rss=table.getScanner(scan); 248 //遍历结果集,每一个Result对应一行记录(即对应一个RowKey) 249 printResult(rss); 250 } catch (IOException e) { 251 e.printStackTrace(); 252 } 253 } 254 255 /** 256 * 查询单条记录 257 * @param rowKey 258 * @param tabNameStr 259 */ 260 public static void get(String tabNameStr,String rowKey){ 261 TableName tabName=TableName.valueOf(tabNameStr); 262 263 Get get=new Get(rowKey.getBytes()); 264 //相当于select..字段列表...from...,如果没有下面的addColumn方法调用则相当于select *... 265 get.addColumn("base".getBytes(), "height".getBytes()); 266 get.addColumn("base".getBytes(), "gender".getBytes()); 267 try { 268 Table table=conn.getTable(tabName); 269 Result result=table.get(get); 270 271 //获取行键 272 String rowKeyStr=new String(result.getRow()); 273 System.out.println("行键:"+rowKeyStr); 274 275 //获取键所对应的值 276 byte[] byteName=result.getValue("base".getBytes(), "gender".getBytes()); 277 String gender=getObject(byteName).toString(); 278 System.out.println("gender:"+gender); 279 280 //获取当前行中的所有键值对 281 List<Cell> cellList=result.listCells(); 282 for(Cell cell:cellList){ 283 //获取当前键值对所在的列族名称 284 String familyName=new String(CellUtil.cloneFamily(cell)); 285 //获取当前键值对的键(Key) 286 String key=new String(CellUtil.cloneQualifier(cell)); 287 //获取当前键值对的值(Value) 288 byte[] byteValue=CellUtil.cloneValue(cell); 289 String value=getObject(byteValue).toString(); 290 291 System.out.println(rowKey+"\t"+familyName+"\t"+key+":"+value); 292 } 293 } catch (IOException e) { 294 e.printStackTrace(); 295 } 296 } 297 298 /** 299 * 批量删除多行 300 * @param tabNameStr 301 * @param rowKey 302 */ 303 public static void deletes(String tabNameStr,String... rowKeys){ 304 if(rowKeys.length==0)return; 305 TableName tabName=TableName.valueOf(tabNameStr); 306 307 List<Delete> deleteList=new ArrayList<Delete>(); 308 for(String rowKey:rowKeys)deleteList.add(new Delete(rowKey.getBytes())); 309 310 try { 311 Table table=conn.getTable(tabName); 312 table.delete(deleteList); 313 System.out.println("删除完成!"); 314 } catch (IOException e) { 315 e.printStackTrace(); 316 } 317 } 318 319 /** 320 * 删除行中的键值对 321 * @param tabNameStr 322 * @param rowKey 323 * @param key 324 */ 325 public static void delete(String tabNameStr,String rowKey,String family,String key){ 326 TableName tabName=TableName.valueOf(tabNameStr); 327 try { 328 Table table=conn.getTable(tabName); 329 Delete delete=new Delete(rowKey.getBytes()); 330 delete.addColumn(family.getBytes(), key.getBytes()); 331 table.delete(delete); 332 System.out.println("删除完成!"); 333 } catch (IOException e) { 334 e.printStackTrace(); 335 } 336 } 337 338 /** 339 * 删除整行 340 * @param tabNameStr 341 * @param rowKey 342 */ 343 public static void delete(String tabNameStr,String rowKey){ 344 TableName tabName=TableName.valueOf(tabNameStr); 345 try { 346 Table table=conn.getTable(tabName); 347 Delete delete=new Delete(rowKey.getBytes()); 348 table.delete(delete); 349 System.out.println("删除完成!"); 350 } catch (IOException e) { 351 e.printStackTrace(); 352 } 353 } 354 355 /** 356 * 增加或修改数据(表名、行键、列族、列、值) 357 */ 358 public static void put(String tabNameStr,String rowKey,String family,String key,String value){ 359 TableName tabName=TableName.valueOf(tabNameStr); 360 try { 361 Table table=conn.getTable(tabName); 362 Put put=new Put(rowKey.getBytes()); 363 put.addColumn(family.getBytes(), key.getBytes(), value.getBytes()); 364 table.put(put); 365 System.out.println("操作完成!"); 366 } catch (IOException e) { 367 e.printStackTrace(); 368 } 369 } 370 371 /** 372 * 批量插入或修改数据 373 * @param tabNameStr 374 * @param dataMap 375 */ 376 public static void puts(String tabNameStr,Map<String,Map<String,Map<String,Object>>> dataMap){ 377 List<Put> putList=new ArrayList<Put>(); 378 Set<Entry<String, Map<String, Map<String, Object>>>> entrys=dataMap.entrySet(); 379 for(Entry<String, Map<String, Map<String, Object>>> entry:entrys){ 380 //获取行的rowKey 381 byte[] rowKey=entry.getKey().getBytes(); 382 Put put=new Put(rowKey); 383 putList.add(put); 384 //获取行的所有列族 385 Map<String, Map<String, Object>> familyMap=entry.getValue(); 386 Set<Entry<String, Map<String, Object>>> familyEntrys=familyMap.entrySet(); 387 for(Entry<String, Map<String, Object>> familyEntry:familyEntrys){ 388 //获取列族名称 389 byte[] familyName=familyEntry.getKey().getBytes(); 390 //获取列族下左右的键值对 391 Map<String, Object> keyVals=familyEntry.getValue(); 392 Set<Entry<String, Object>> keyValEntrys=keyVals.entrySet(); 393 for(Entry<String, Object> keyValEntry:keyValEntrys){ 394 byte[] key=keyValEntry.getKey().getBytes(); 395 byte[] value=getBytes(keyValEntry.getValue()); 396 put.addColumn(familyName, key, value); 397 } 398 } 399 } 400 401 TableName tabName=TableName.valueOf(tabNameStr); 402 try { 403 Table table=conn.getTable(tabName); 404 table.put(putList); 405 System.out.println("操作完成!"); 406 } catch (IOException e) { 407 e.printStackTrace(); 408 } 409 } 410 }
测试结果:
在命令端查看,查看方式,可参考:http://www.cnblogs.com/mmzs/p/8135327.html
测试小结:
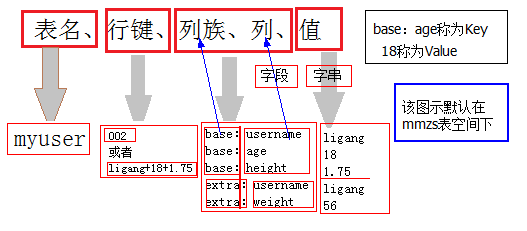
HBase是分布式的、可扩展的、且基于Hadop的大数据NOSQL存储数据库(号称十亿行、百万列),该数据库的每一行也是保存一条记录,但是与关系数据库不同的是,该数据库无需事先定义字段和表结构,只需要指定表名和列族;每一行由指定的一到多个族组成,每个族上可以保存若干个键值对(每一行的每个族上的键值对数量可以是任意的),即每一行的单元格数量不一定相等,每一个单元格中保存同一个键名但不同版本值的若干个键值对(即同一个字段名中有不同版本的字段值),当需要查询某一个字段值时需要指定的坐标是:
表名(table name)—>行健(row key)—>列族(column family)—>字段名(column name)—>版本号(version code)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}