

Hive环境搭建及测试
前提条件:已经安装好如下软件
Eclipse4.5 hadoop-2.7.3 jdk1.7.0_79
此篇文章基于上一篇文章:zookeeper高可用集群搭建
什么是Hive?
1、Hive是一个基于Hadoop文件系统之上的数据仓库结构。它为数据仓库的管理提供了许多功能:数据ETL(抽取、转换和加载)工具、数据存储管理和大型数据集的查询和分析能力。
2、同时Hive定义了类SQL的语句;它能够将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。还允许开发人员方便的使用Mapper和Reducer操作,可以将SQL语句转化为MapReduce任务运行,这对MapReduce框架来说是一个强有力的支持。
3、Hive的优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高;主要延迟是发生在启动线程部分。
一、开始安装Hive:(仅在CloudDeskTop上安装)
上传安装文件到/software目录下;
下载地址:http://mirrors.shuosc.org/apache/hive/
解压到/software目录下,并修改它的名字;
[hadoop@CloudDeskTop software]$ mv apache-hive-1.2.2-bin/ hive-1.2.2
配置Hive:
[hadoop@CloudDeskTop software]$ cd /software/hive-1.2.2/conf/
[hadoop@CloudDeskTop conf]$ cp hive-default.xml.template hive-site.xml
[hadoop@CloudDeskTop conf]$ vi hive-site.xml
334行:hdfs集群存放hive仓库元数据的位置
333 <property> 334 <name>hive.metastore.warehouse.dir</name> 335 <value>/user/hive/warehouse</value> 336 <description>location of default database for the warehouse</description> 337 </property>
46行
45 <property>
46 <name>hive.exec.scratchdir</name>
47 <value>/tmp/hive</value>
48 <description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<userna me> is created, with ${hive.scratch.dir.permission}.</description>
49 </property>
2911行
2910 <property>
2911 <name>hive.server2.logging.operation.log.location</name>
2912 <value>/tmp/hive/operation_logs</value>
2913 <description>Top level directory where operation logs are stored if logging functionality is enabled</description>
2914 </property>
51行
50 <property>
51 <name>hive.exec.local.scratchdir</name>
52 <value>/tmp/hive</value>
53 <description>Local scratch space for Hive jobs</description>
54 </property>
56行
55 <property>
56 <name>hive.downloaded.resources.dir</name>
57 <value>/tmp/hive/resources</value>
58 <description>Temporary local directory for added resources in the remote file system.</description>
59 </property>
[hadoop@CloudDeskTop conf]$ vi hive-log4j.properties
使用[tail -f hive.log]可以动态实时查看日志的最新情况;
17 # Define some default values that can be overridden by system properties 18 hive.log.threshold=ALL 19 hive.root.logger=INFO,DRFA
#logs目录需要自己创建,用来存放你操作hive数据库后产生的日志 20 hive.log.dir=/software/hive-1.2.2/logs 21 hive.log.file=hive.log
72 #log4j.appender.EventCounter=org.apache.hadoop.hive.shims.HiveEventCounter
73 log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
[hadoop@CloudDeskTop software]$ vi /software/hive-1.2.2/bin/hive-config.sh
在最后添加:
export JAVA_HOME=/software/jdk1.7.0_79 export HADOOP_HOME=/software/hadoop-2.7.3 export HIVE_HOME=/software/hive-1.2.2
二、启动Hive前的准备:
【1、在slave节点启动zookeeper集群(小弟中选个leader和follower)】
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh start && cd - && jps
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh status && cd -
【2、master01启动HDFS集群】cd /software/ && start-dfs.sh && jps
【3、master01启动YARN集群】cd /software/ && start-yarn.sh && jps
【YARN集群启动时,不会把另外一个备用主节点的YARN集群拉起来启动,所以在master02执行语句:】
cd /software/ && yarn-daemon.sh start resourcemanager && jps
【4、查看两个master谁是主节点:】
[hadoop@master01 software]$ hdfs haadmin -getServiceState nn1
active (主节点)
[hadoop@master01 software]$ hdfs haadmin -getServiceState nn2
standby (备用主节点)
【5、查看两个resourcemanager谁是主:】
[hadoop@master01 hadoop]$ yarn rmadmin -getServiceState rm1
active(主)
[hadoop@master01 hadoop]$ yarn rmadmin -getServiceState rm2
standby(备用)
启动Hive:
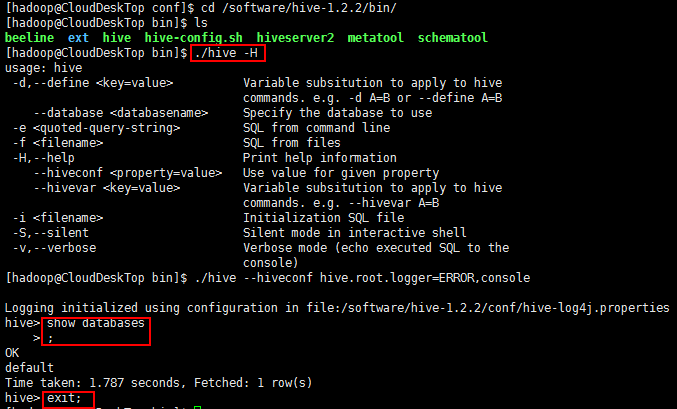

【此时会在当前目录下生成:】

【如果发生问题,删除如下两个文件】

【如果问题依旧不能解决,直接删除metastore_db文件试一试】
大数据学习交流群:217770236 让我我们一起学习大数据
三、Hive测试
【下面的测试都遵循如下两图的目录准则:】


【1、首先 cd /home/hadoop/test/hive/src】
新增t_user数据文件:并上传到hdfs集群;[hdfs dfs -put t_user /user/hive/warehouse/mmzs.db/t_user/]


新增myuser数据文件:并上传到hdfs集群;[hdfs dfs -put myuser /user/hive/warehouse/mmzs.db/t_user/]


新增myuser02数据文件:暂时不上传,后面用另外一种方式上传;

【2、首先 cd /software/hive-1.2.2/bin】
【创建测试数据库:】create database mmzs;

【3、将结果写入test.sql文件,将执行其结果输出到指定目录的文件中】
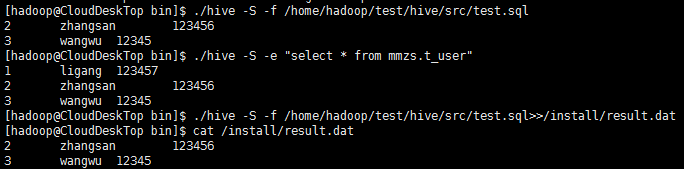
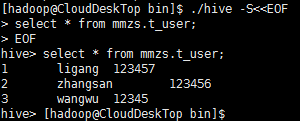
【不进入./hive命令终端,动态执行sql语句】
【4、在hive数据库中创建表,[row format delimited fields terminated by '\t']是指定数据每行按照空白进行分割】
create table mmzs.t_user(userId int, username string, userage int, userheight double) row format delimited fields terminated by '\t';


【另外一种上传数据文件到集群hive数据库的方式,load data就是上传的关键字,local是将本地文件拷贝到hive数据库,不加就是导入hdfs集群数据到hive数据库是一种剪切方式】
【使用overwrite本地文件覆盖上传】./hive -S -e "load data local inpath '/home/hadoop/test/hive/src/myuser02' overwrite into table mmzs.t_user;"
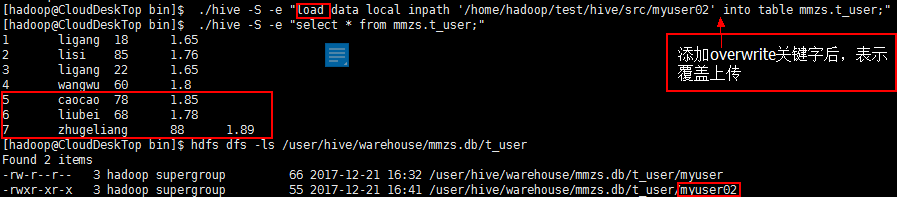
【hdfs文件不覆盖上传 】./hive -S -e "load data local inpath '/data/myuser' into table mmzs.t_user;"

【小结:】注意:

【6、hive支持大多数sql语句,但也有不支持的sql语句:】
【7、聚合函数有个统计过程,会产生MapTask和ReduceTask】
select count(userid) from t_user ;
select avg(userage) from t_user;

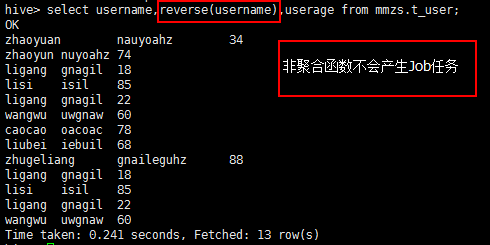
【8、非聚合函数,不会产生Job任务】
select username,reverse(username),userage from mmzs.t_user;
select username,length(username),userage from mmzs.t_user;
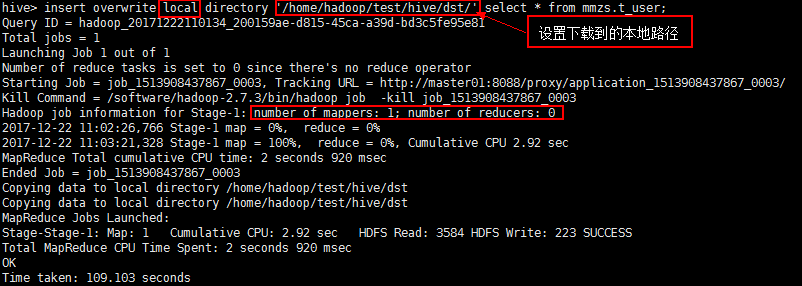
【9、hive数据库结果的下载】
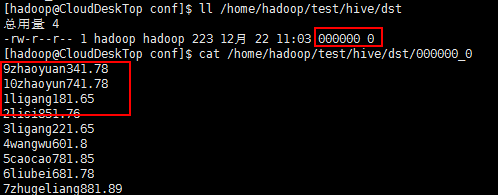
下载到本地:(1个Job)

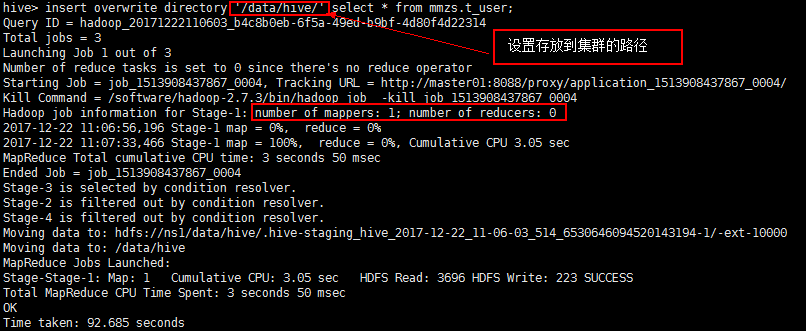
下载到hdfs集群:(3个Job,应该是因为有3个slave,有3个备份的原因)

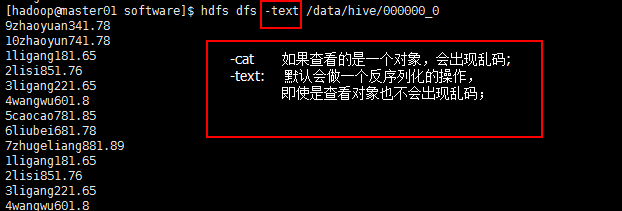
【10、通过子查询的方式来创建表和创建数据:显示的是3个Job(Total jobs只是计划的任务数),实际运行了1个;请用浏览器的方式查看或者你可以看到只出现了Launching Job 1 out of 3】
create table mmzs.t_user as select * from mmzs.t_user where 1=2;(拷贝后的表,读取数据时的分隔符会回复到默认的)
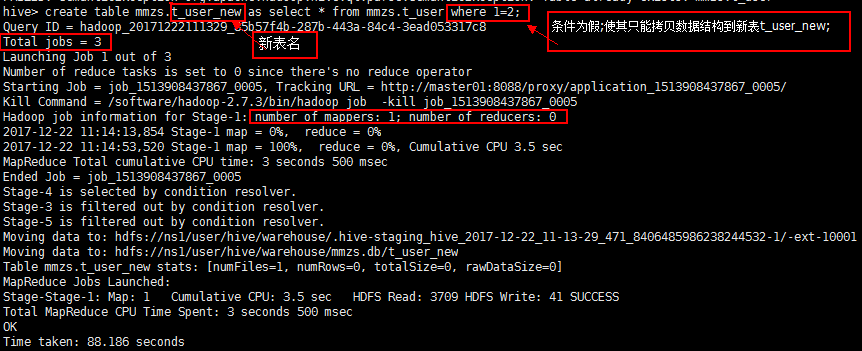
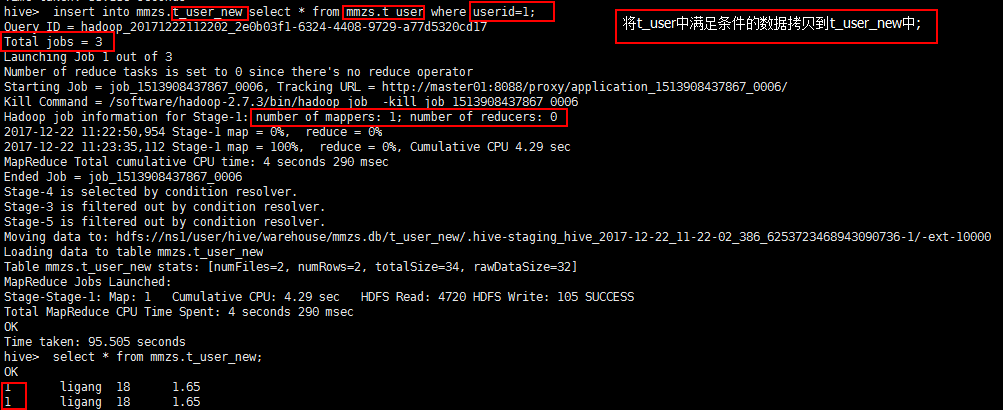
【11、在10的基础上,通过hdfs集群的方式为表新增数据】
通过hdfs集群,直接将原表中的数据文件拷贝到新表中:

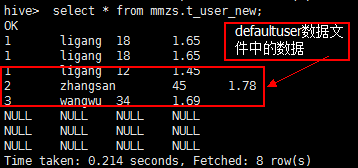
由于myuser02中的数据文件创建时使用的是Tab键作为分隔符,所以出现如下情况:
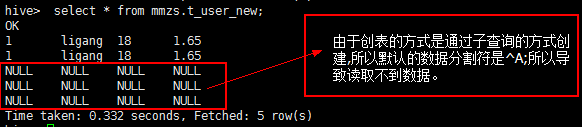
所以我们重新传了用^A(hive的默认分隔符,通过按"ctrl+V"和"ctrl+A"键产生)作为分隔符的数据文件:

然后我们就能看到表中新增的数据了:
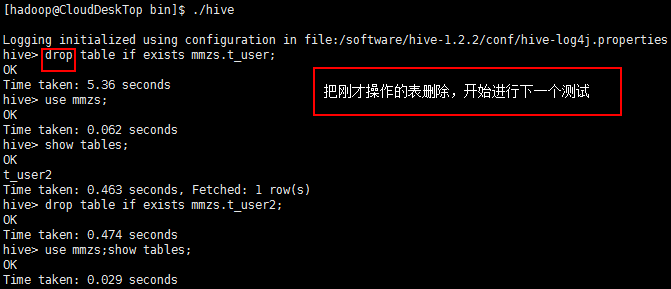
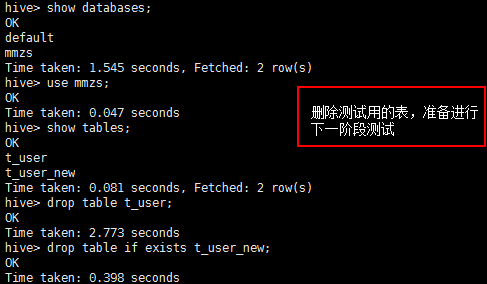
【12、第一阶段测试完成,删除所有测试的表】
hive> show databases; hive> use mmzs; hive> show tables; hive> drop table t_user; hive> drop table if exists t_user_new;
四、Hive高级测试(一)
【hive>均是在 cd /software/hive-1.2.2/bin 目录下执行./hive命令或者./hive --hiveconf hive.root.logger=ERROR,console命令】
【1、创建测试所需表】
hive> use mmzs;
hive> create table if not exists emp(eno int,ename string,eage int,bithday date,sal double,com double,gender string,dno int) row format delimited fields terminated by '\t';
hive> create table if not exists dept(dno int,dname string,loc string) row format delimited fields terminated by '\t';
【2、创建测试所需表的数据】
cd /home/hadoop/test/hive/src
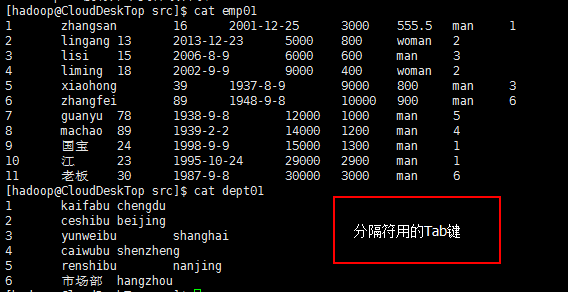
hdfs dfs -put emp01 /user/hive/warehouse/mmzs.db/emp
hdfs dfs -put dept01 /user/hive/warehouse/mmzs.db/dept
【3、测试开始】
hive> use mmzs;
【遇到create和insert操作会产生Job作业(只有Map作业)】
【遇到含有group by、order by操作或聚合函数操作时都会产生Job作业(有Map和Reduce)】

【当有同时含有group by和order by时会产生两个Job:(有Map,也有Reduce)】
select dno,gender,count(1) renshu from emp where eage>25 group by gender,dno order by renshu desc;


【产生一个Job:(只有Map,没有Reduce)】
select e.*,d.* from emp e,dept d where e.dno=d.dno;
select eno,ename,e.dno,d.dname from emp e inner join dept d on e.dno=d.dno;
select dno,eno,ename,sal,com from emp order by sal desc,com desc;
【产生两个Job:(因为多了个group by)(有Map,也有Reduce)】
select dno,eno,ename,sal,com from emp group by dno,eno,ename,sal,com order by sal desc,com desc;
select d.dno,avg(sal) avgsal from emp e inner join dept d on e.dno=d.dno where eage>20 group by d.dno order by avgsal;
select d.dname,avgsal from (select d.dno,avg(sal) avgsal from emp e inner join dept d on e.dno=d.dno where eage>20 group by d.dno order by avgsal)mid,dept d where mid.dno=d.dno;
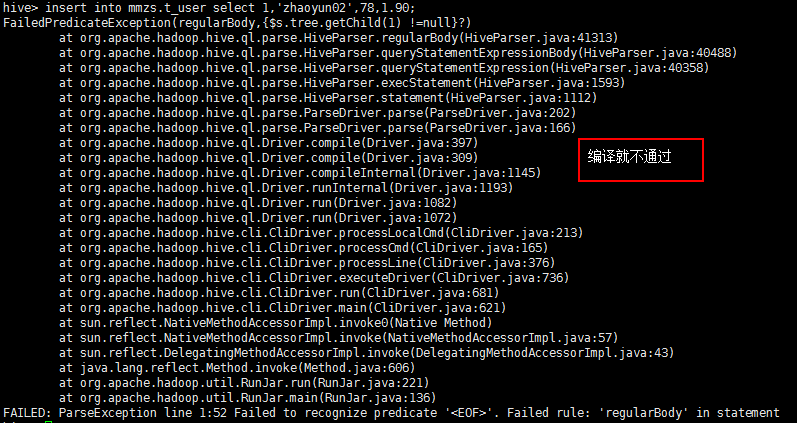
遇到子查询不能处理的,可以将子查询结果用去做关联查询;
以下语句会出错:(因为hive目前不支持where后面子查询的语法)
select e.* from emp e where e.sal>(select avg(sal) from emp dno=e.dno);

select * from emp limit 6; //不产生Job select * from emp limit 2,5;//会产生错误
【Hive的分页查询:只产生一个Job,(有Map,也有Reduce)】
select row_number() over() seq,e.* from emp e; //row_number()是标识添加行号的关键字,按照over内的条件进行排列后,添加行号seq字段, //over内不写条件,默认是在,将按照第一个字段降序排列后的结果,前加行号
select * from (select row_number() over(order by sal desc) seq,e.* from emp e) mid where mid.seq>5 and mid.seq<11; //分页查询
五、Hive高级测试(二)
【Hive目前不支持索引】
【Hive支持分区:静态分区和动态分区的创建表的方式是一样的】
create table t_user(userid int,username string,userage int) partitioned by(dno int) row format delimited fields terminated by '\t';//单级分区;dno是分区的字段名,添加分区时必须名字一样 create table t_user(userid int,username string,userage int) partitioned by(dno int,gender string) row format delimited fields terminated by '\t';//多级分区;dno是分区的字段名,添加分区时必须名字一样
【测试数据:】
进入目录:cd /home/hadoop/test/hive/src

【静态分区:】
alter table t_user add partition(dno=1);//添加分区,分区名是"dno=1" alter table t_user drop partition(dno=1);//删除分区名是"dno=1"的分区
添加1、2、3、4共四个分区;
// 集群中操作 hdfs dfs -put bak /user/hive/warehouse/mmzs.db/t_user/dno=1//① // ./hive中操作 load data local inpath '/home/hadoop/test/hive/src/bak' into table t_user partition(dno=1);//② load data local inpath '/home/hadoop/test/hive/src/bak' overwrite into table t_user partition(dno=1);//② insert into t_user partition(dno=3) select eno,ename,eage from emp where eno<4;//③必须添加所有字段,不可以写t_user(userid,username,userage)的方式 insert overwrite table t_user partition(dno=4) select eno,ename,eage from emp where eno>4 and eno<9;//④分页
//临时修改,启动动态分区;也可在配置文件hive-site.xml配置,永久生效 set hive.exsec.dynamic.partition.mode=nonstrict;//hive-site.xml
insert into t_user partition(dno) values(1,"liganggang",89,1);//插入数据,分区确定在后面指定; insert into t_user partition(dno=5) select eno,ename,eage from emp where eno<4;//如果没有的分区会自动创建
//多级动态分区;多级静态和单级静态类似 insert into t_user partition(dno,gender) select eno,ename,eage,dno,gender from emp;//select中的dno,gender的顺序要和建表是的partition(dno,gender)的顺序和保持一致;否则会乱建分区 //into改变成overwrite table表示有相同的时,覆盖插入;
truncate table t_user;//清空表中的数据 drop table t_user;//删除表
数据移植小结:
A、从本地到Hive表:
使用HDFS的put命令上传数据文件
使用Hive的load data local inpath句法导入数据文件
B、从Hive表到Hive表
使用HDFS的cp命令实现数据文件拷贝
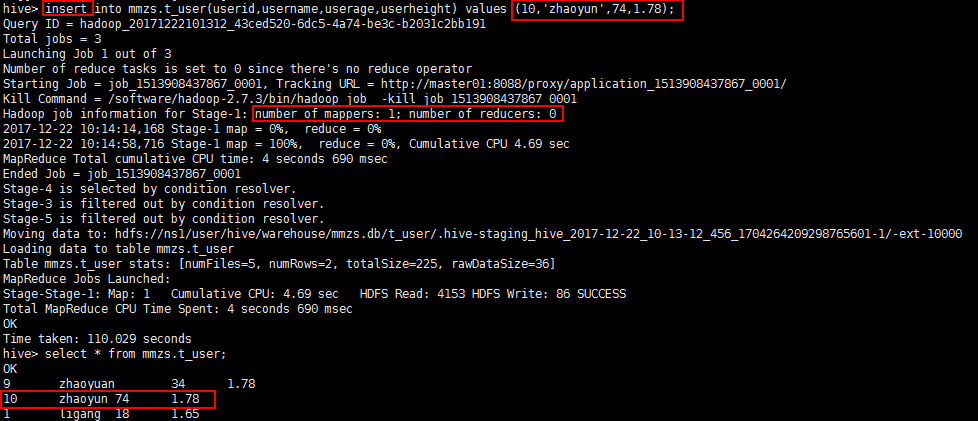
使用普通的insert into句法插入单条记录数据
使用insert....select...from...句法实现批量条件数据拷贝
使用insert overwrite table....select....句法实现数据拷贝
C、从Hive表到本地
使用HDFS的get命令下载数据文件
使用insert overwrite local directory句法实现Hive表批量条件数据导出
使用输出定向符(>或>>)直接通过标准输出流将select查询结果其写入本地文件
[hadoop@CloudDeskTop src]$ pwd
/home/hadoop/test/hive/src
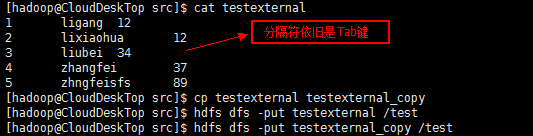
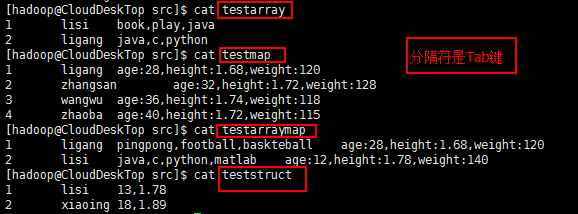
//创建表后 hdfs dfs -put testarray /user/hive/warehouse/mmzs.db/tuser01 hdfs dfs -put testmap /user/hive/warehouse/mmzs.db/tuser02 hdfs dfs -put testarraymap user/hive/warehouse/mmzs.db/tuser03 hdfs dfs -put teststruct /user/hive/warehouse/mmzs.db/tuser04
#首先
[hadoop@CloudDeskTop ~]$ cd /software/hive-1.2.2/bin [hadoop@CloudDeskTop bin]$ ./hive
#创建的外部表不会因为表的删除而删除数据; #外部表不会在默认的数据存放地址新建文件夹,从始至终都只有指定的目录下有数据 //表的数据存放在指定外部hdfs集群地址"/test"目录中: hive> create external table tuser00(userid int,username string,userage int) row format delimited fields terminated by '\t' location '/test'; //在数据库下创建外部表就需要添加数据库的前缀 hive> use mmzs; hive> create external table mmzs.tuser00(userid int,username string,userage int) row format delimited fields terminated by '\t' location '/test';
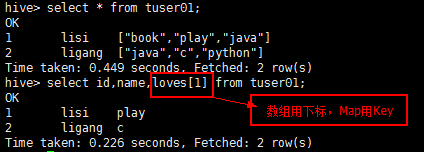
//创建一个带有数组的表: hive> create table if not exists mmzs.tuser01(id bigint,name string,loves array<string>) row format delimited fields terminated by '\t' collection items terminated by ',';
select id,name,loves[1] from mmzs.tuser01;
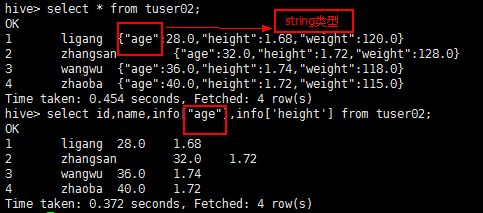
//创建一个带有map的表: hive> create table if not exists mmzs.tuser02(id bigint,name string,info map<string,double>) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':'; //注:map keys terminated by ':'中的 :号是元素之间的分隔符,为了解析数据,可以是任意符号。 hive> select id,name,info["age"],info['height'] from mmzs.tuser02;//(如果查询的字段没有,会返回一个人Null)
//创建一个带有数组和map的表 hive> create table mmzs.tuser03(id bigint,name string,loves array<string>,info map<String,double>) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':';

//Struct类型(info是一个STRUCT类型,那么可以通过info.height得到这个用户的身高) hive> create table mmzs.tuser04(id bigint,name string,info struct<age:int,height:double>) row format delimited fields terminated by '\t' collection items terminated by ','; //(如果查询的字段没有,会报异常) hive> select id,name,info.age,info.height from mmzs.tuser04;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}