

YARN集群的mapreduce测试(四)
将手机用户使用流量的数据进行分组,排序;
测试准备:
首先同步时间,然后master先开启hdfs集群,再开启yarn集群;用jps查看:
master上: 先有NameNode、SecondaryNameNode;再有ResourceManager;
slave上: 先有DataNode;再有NodeManager;
如果master启动hdfs和yarn成功,但是slave节点有的不成功,则可以使用如下命令手动启动:
| hadoop-daemon.sh start datanode |
| yarn-daemon.sh start nodemanager |
然后在本地"/home/hadoop/test/"目录创建phoneflow文件夹,将所有需要统计的数据放到该文件夹下;
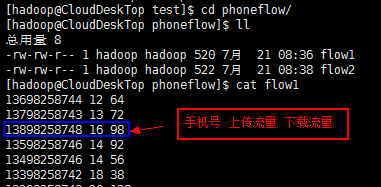
测试目标:
目标一:输出结果是:按手机号分组后,按照上传流量和下载流量的总和排序的结果;
目标二:输出结果是:按手机号分组后,先按照上传流量排序,遇到相同时再按照上传流量和下载流量的总和排序;
测试代码:
目标一:
因为涉及到了排序,我们输出的结果是一个包装好的flow对象(它自身就包含了很多信息);
分组必须必须要让flow类实现Serializable接口;
排序就必须要让flow类在分组的基础上再实现WritableComparable接口,并且重写write、readFields方法和重写compareTo方法;


1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 import java.io.Serializable; 7 8 import org.apache.hadoop.io.WritableComparable; 9 10 public class Flow implements WritableComparable<Flow>,Serializable{ 11 12 private String phoneNum;//手机号 13 private Long upFlow; //上传流量 14 private Long downFlow; //下载流量 15 public Flow() {} 16 public Flow(String phoneNum, Long upFlow, Long downFlow) { 17 super(); 18 this.phoneNum = phoneNum; 19 this.upFlow = upFlow; 20 this.downFlow = downFlow; 21 } 22 public Long getTotalFlow() { 23 return upFlow+downFlow; 24 } 25 26 27 //按照怎样的顺序写入到reduce中,在reduce中就按照怎样的顺序读 28 //write是一个序列化的过程 29 @Override 30 public void write(DataOutput out) throws IOException { 31 out.writeUTF(phoneNum); 32 out.writeLong(upFlow); 33 out.writeLong(downFlow); 34 } 35 //read是一个反序列化的过程 36 @Override 37 public void readFields(DataInput in) throws IOException { 38 this.phoneNum = in.readUTF(); 39 this.upFlow = in.readLong(); 40 this.downFlow = in.readLong(); 41 } 42 //reduce任务排序的依据 43 @Override 44 public int compareTo(Flow flow) { 45 Long curTotalFlow = this.getTotalFlow(); 46 Long paramTotalFlow = flow.getTotalFlow(); 47 Long resFlow = curTotalFlow-paramTotalFlow; 48 return resFlow>0?-1:1; 49 } 50 51 52 public String getPhoneNum() { 53 return phoneNum; 54 } 55 public void setPhoneNum(String phoneNum) { 56 this.phoneNum = phoneNum; 57 } 58 public Long getUpFlow() { 59 return upFlow; 60 } 61 public void setUpFlow(Long upFlow) { 62 this.upFlow = upFlow; 63 } 64 public Long getDownFlow() { 65 return downFlow; 66 } 67 public void setDownFlow(Long downFlow) { 68 this.downFlow = downFlow; 69 } 70 //此方法只是单纯的为了方便一次性设置值,只set一次 71 public void setFlow(String phoneNum, Long upFlow, Long downFlow) { 72 this.phoneNum = phoneNum; 73 this.upFlow = upFlow; 74 this.downFlow = downFlow; 75 } 76 @Override 77 public String toString() { 78 return new StringBuilder(phoneNum).append("\t") 79 .append(upFlow).append("\t") 80 .append(downFlow).append("\t") 81 .append(getTotalFlow()) 82 .toString(); 83 } 84 85 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Mapper; 8 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 9 10 public class PhoneFlowMapper01 extends Mapper<LongWritable, Text, Text, Flow> { 11 12 private Text outKey; 13 private Flow outValue; 14 15 @Override 16 protected void setup(Mapper<LongWritable, Text, Text, Flow>.Context context) 17 throws IOException, InterruptedException { 18 outKey = new Text(); 19 outValue = new Flow(); 20 } 21 22 @Override 23 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Flow>.Context context) 24 throws IOException, InterruptedException { 25 26 String line = value.toString(); 27 String[] fields = line.split("\\s+"); 28 29 //过滤无效不完整的数据 30 if(fields.length<3) return; 31 32 String phoneNum = fields[0]; 33 String upFlow = fields[1]; 34 String downFlow = fields[2]; 35 36 outKey.set(phoneNum); 37 outValue.setFlow(phoneNum, Long.parseLong(upFlow), Long.parseLong(downFlow));; 38 context.write(outKey, outValue); 39 40 41 } 42 43 @Override 44 protected void cleanup(Mapper<LongWritable, Text, Text, Flow>.Context context) 45 throws IOException, InterruptedException { 46 outKey = null; 47 outValue = null; 48 } 49 50 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.Iterator; 6 import java.util.List; 7 8 import org.apache.hadoop.io.NullWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 12 public class PhoneFlowReducer01 extends Reducer<Text, Flow, NullWritable, Flow> { 13 14 private NullWritable outKey; 15 private Flow outValue; 16 17 @Override 18 protected void setup(Reducer<Text, Flow, NullWritable, Flow>.Context context) throws IOException, InterruptedException { 19 outKey = NullWritable.get(); 20 outValue = new Flow(); 21 } 22 23 @Override 24 protected void reduce(Text key, Iterable<Flow> values, Reducer<Text, Flow, NullWritable, Flow>.Context context) 25 throws IOException, InterruptedException { 26 Iterator<Flow> its = values.iterator(); 27 28 Long totalUpFlow = 0L;//此处是Long类型,不能设置成null; 29 Long totalDownFlow = 0L; 30 while (its.hasNext()) { 31 Flow flow = its.next(); 32 totalUpFlow += flow.getUpFlow();//求和千万别忘记+号 33 totalDownFlow += flow.getDownFlow(); 34 } 35 36 outValue.setFlow(key.toString(), totalUpFlow, totalDownFlow); 37 context.write(outKey, outValue); 38 39 } 40 41 @Override 42 protected void cleanup(Reducer<Text, Flow, NullWritable, Flow>.Context context) throws IOException, InterruptedException { 43 outValue = null; 44 } 45 46 47 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.LongWritable; 11 import org.apache.hadoop.io.NullWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 /** 18 * @author hadoop 19 * 20 */ 21 public class PhoneFlowDriver01 { 22 23 private static FileSystem fs; 24 private static Configuration conf; 25 static { 26 String uri = "hdfs://master01:9000/"; 27 conf = new Configuration(); 28 try { 29 fs = FileSystem.get(new URI(uri), conf, "hadoop"); 30 } catch (IOException e) { 31 e.printStackTrace(); 32 } catch (InterruptedException e) { 33 e.printStackTrace(); 34 } catch (URISyntaxException e) { 35 e.printStackTrace(); 36 } 37 } 38 39 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 40 41 Job pfJob01 = getJob(args); 42 if (null == pfJob01) { 43 return; 44 } 45 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 46 boolean flag = false; 47 flag = pfJob01.waitForCompletion(true); 48 System.exit(flag?0:1); 49 } 50 51 /** 52 * 获取Job实例 53 * @param args 54 * @return 55 * @throws IOException 56 */ 57 public static Job getJob(String[] args) throws IOException { 58 if (null==args || args.length<2) return null; 59 //放置需要处理的数据所在的HDFS路径 60 Path inputPath = new Path(args[0]); 61 //放置Job作业执行完成之后其处理结果的输出路径 62 Path outputPath = new Path(args[1]); 63 64 //获取Job实例 65 Job pfJob01 = Job.getInstance(conf, "pfJob0102"); 66 //设置运行此jar包入口类 67 //pfJob01的入口是WordCountDriver类 68 pfJob01.setJarByClass(PhoneFlowDriver01.class); 69 //设置Job调用的Mapper类 70 pfJob01.setMapperClass(PhoneFlowMapper01.class); 71 //设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句) 72 pfJob01.setReducerClass(PhoneFlowReducer01.class); 73 74 //设置MapTask的输出键类型 75 pfJob01.setMapOutputKeyClass(Text.class); 76 //设置MapTask的输出值类型 77 pfJob01.setMapOutputValueClass(Flow.class); 78 79 //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句) 80 pfJob01.setOutputKeyClass(NullWritable.class); 81 //设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句) 82 pfJob01.setOutputValueClass(Flow.class); 83 84 //设置整个Job需要处理数据的输入路径 85 FileInputFormat.setInputPaths(pfJob01, inputPath); 86 //设置整个Job计算结果的输出路径 87 FileOutputFormat.setOutputPath(pfJob01, outputPath); 88 89 return pfJob01; 90 } 91 92 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 // import java.io.IOException; 4 // import org.apache.hadoop.io.LongWritable; 5 // import org.apache.hadoop.io.NullWritable; 6 // import org.apache.hadoop.io.Text; 7 // import org.apache.hadoop.mapreduce.Mapper; 8 // import org.apache.hadoop.mapreduce.lib.input.FileSplit; 9 10 // public class PhoneFlowMapper02 extends Mapper<LongWritable, Text, Flow, NullWritable> { 11 12 // private Flow outKey; 13 // private NullWritable outValue; 14 15 // @Override 16 // protected void setup(Mapper<LongWritable, Text, Flow, NullWritable>.Context context) 17 // throws IOException, InterruptedException { 18 // outKey = new Flow(); 19 // outValue = NullWritable.get(); 20 // } 21 22 // @Override 23 // protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Flow, NullWritable>.Context context) 24 // throws IOException, InterruptedException { 25 26 // String line = value.toString(); 27 // String[] fields = line.split("\\s+"); 28 29 // String phoneNum = fields[0]; 30 // String upFlow = fields[1]; 31 // String downFlow = fields[2]; 32 33 因为获取过来的都是String类型,所以需要转换参数类型 34 // outKey.setFlow(phoneNum, Long.parseLong(upFlow), Long.parseLong(downFlow));; 35 // context.write(outKey, outValue); 36 37 // } 38 39 // @Override 40 // protected void cleanup(Mapper<LongWritable, Text, Flow, NullWritable>.Context context) 41 // throws IOException, InterruptedException { 42 // outKey = null; 43 // outValue = null; 44 // } 45 46 // }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.Iterator; 6 import java.util.List; 7 8 import org.apache.hadoop.io.NullWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 12 public class PhoneFlowReducer02 extends Reducer<Flow, NullWritable, Flow, NullWritable> { 13 14 private NullWritable outValue; 15 16 @Override 17 protected void setup(Reducer<Flow, NullWritable, Flow, NullWritable>.Context context) throws IOException, InterruptedException { 18 outValue = NullWritable.get(); 19 } 20 21 @Override 22 protected void reduce(Flow key, Iterable<NullWritable> values, Reducer<Flow, NullWritable, Flow, NullWritable>.Context context) 23 throws IOException, InterruptedException { 24 //此reduce不能少,它会自动调用compareTo方法进行排序 25 //排序的工作是在shuffle的工程中进行的 26 context.write(key, outValue); 27 } 28 29 @Override 30 protected void cleanup(Reducer<Flow, NullWritable, Flow, NullWritable>.Context context) throws IOException, InterruptedException { 31 outValue = null; 32 } 33 34 35 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.LongWritable; 11 import org.apache.hadoop.io.NullWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 /** 18 * @author hadoop 19 * 20 */ 21 public class PhoneFlowDriver02 { 22 23 private static FileSystem fs; 24 private static Configuration conf; 25 static { 26 String uri = "hdfs://master01:9000/"; 27 conf = new Configuration(); 28 try { 29 fs = FileSystem.get(new URI(uri), conf, "hadoop"); 30 } catch (IOException e) { 31 e.printStackTrace(); 32 } catch (InterruptedException e) { 33 e.printStackTrace(); 34 } catch (URISyntaxException e) { 35 e.printStackTrace(); 36 } 37 } 38 39 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 40 41 Job pfJob02 = getJob(args); 42 if (null == pfJob02) { 43 return; 44 } 45 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 46 boolean flag = false; 47 flag = pfJob02.waitForCompletion(true); 48 System.exit(flag?0:1); 49 } 50 51 /** 52 * 获取Job实例 53 * @param args 54 * @return 55 * @throws IOException 56 */ 57 public static Job getJob(String[] args) throws IOException { 58 if (null==args || args.length<2) return null; 59 //放置需要处理的数据所在的HDFS路径 60 Path inputPath = new Path(args[1]); 61 //放置Job作业执行完成之后其处理结果的输出路径 62 Path outputPath = new Path(args[2]); 63 64 //获取Job实例 65 Job pfJob02 = Job.getInstance(conf, "pfJob02"); 66 //设置运行此jar包入口类 67 //pfJob02的入口是WordCountDriver类 68 pfJob02.setJarByClass(PhoneFlowDriver02.class); 69 //设置Job调用的Mapper类 70 pfJob02.setMapperClass(PhoneFlowMapper02.class); 71 //设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句) 72 pfJob02.setReducerClass(PhoneFlowReducer02.class); 73 74 //设置MapTask的输出键类型 75 pfJob02.setMapOutputKeyClass(Flow.class); 76 //设置MapTask的输出值类型 77 pfJob02.setMapOutputValueClass(NullWritable.class); 78 79 //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句) 80 pfJob02.setOutputKeyClass(Flow.class); 81 //设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句) 82 pfJob02.setOutputValueClass(NullWritable.class); 83 84 //设置整个Job需要处理数据的输入路径 85 FileInputFormat.setInputPaths(pfJob02, inputPath); 86 //设置整个Job计算结果的输出路径 87 FileOutputFormat.setOutputPath(pfJob02, outputPath); 88 89 return pfJob02; 90 } 91 92 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.File; 4 import java.io.IOException; 5 import java.net.URI; 6 import java.net.URISyntaxException; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.mapreduce.Job; 12 13 public class PhoneFlowDriver { 14 15 private static FileSystem fs; 16 private static Configuration conf; 17 private static final String TEMP= "hdfs://master01:9000/data/phoneflow/tmp"; 18 static { 19 String uri = "hdfs://master01:9000/"; 20 conf = new Configuration(); 21 try { 22 fs = FileSystem.get(new URI(uri), conf, "hadoop"); 23 } catch (IOException e) { 24 e.printStackTrace(); 25 } catch (InterruptedException e) { 26 e.printStackTrace(); 27 } catch (URISyntaxException e) { 28 e.printStackTrace(); 29 } 30 } 31 32 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 33 if (null == args || args.length<2) { 34 System.out.println("参数至少是两个"); 35 return; 36 } 37 38 Path inputPath = new Path(args[0]); 39 Path outputPath = new Path(args[1]); 40 Path tmpPath = new Path(TEMP); 41 //主机文件路径 42 File localPath = new File("/home/hadoop/test/phoneflow"); 43 //如果输入的集群路径存在,则删除 44 if (fs.exists(outputPath)) fs.delete(outputPath, true); 45 if (fs.exists(tmpPath)) fs.delete(tmpPath, true); 46 if (!fs.exists(inputPath)) { 47 //创建并且将数据文件拷贝到创建的集群路径 48 Boolean flag = fs.mkdirs(inputPath); 49 if (!flag) { 50 System.out.println("创建集群路径失败"); 51 } 52 File[] files = localPath.listFiles(); 53 Path[] localPaths = new Path[files.length]; 54 for (int i = 0; i < files.length; i++) { 55 localPaths[i] = new Path(files[i].getAbsolutePath()); 56 } 57 fs.copyFromLocalFile(false, false, localPaths, inputPath); 58 } 59 60 String[] params = {args[0], TEMP, args[1]}; 61 62 //运行第1个Job 63 Job pfJob01 = PhoneFlowDriver01.getJob(params); 64 if (null == pfJob01) return; 65 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 66 boolean flag01 = pfJob01.waitForCompletion(true); 67 if (!flag01) { 68 System.out.println("pfJob01 running failure......"); 69 System.exit(1); 70 } 71 System.out.println("pfJob01 running success......"); 72 73 //运行第2个Job 74 Job pfJob02 = PhoneFlowDriver02.getJob(params); 75 if (null == pfJob02) return; 76 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 77 boolean flag02 = pfJob02.waitForCompletion(true); 78 if (flag02) {//等待Job02完成后就删掉中间目录并退出; 79 fs.delete(new Path(TEMP), true); 80 System.out.println("pfJob02 running success......"); 81 System.exit(0); 82 } 83 System.out.println("pfJob02 running failure......"); 84 System.exit(1); 85 } 86 87 }
目标二:
想要达到目标二,只需将排序的方法做一定的修改即可;
所以我们需要修改Flow类中作排序依据比较的compareTo方法;
1 @Override 2 public int compareTo(Flow flow) { 3 //目标一:按照总流量进行排序 4 // Long curTotalFlow=this.getTotalFlow(); 5 // Long paramTotalFlow=flow.getTotalFlow(); 6 // Long resFlow=curTotalFlow-paramTotalFlow; 7 8 //目标二:先按照上行流量进行排序,如果相同再比较总流量 9 Long curUpFlow=this.getUpFlow(); 10 Long paramUpFlow=flow.getUpFlow(); 11 Long resFlow=curUpFlow-paramUpFlow; 12 //如果上行流量相同就比较总流量 13 if(resFlow==0){ 14 Long curTotalFlow=this.getTotalFlow(); 15 Long paramTotalFlow=flow.getTotalFlow(); 16 resFlow=curTotalFlow-paramTotalFlow; 17 } 18 19 return resFlow>0?-1:1; 20 }
测试结果:
运行时传入参数是:
如果在客户端eclipse上运行:传参需要加上集群的master的uri即 hdfs://master01:9000
输入路径参数: /data/phoneflow/src
输出路径参数: /data/phoneflow/dst
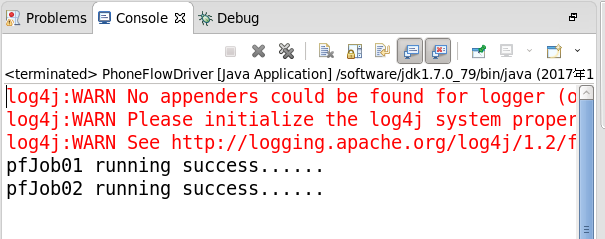
目标一:
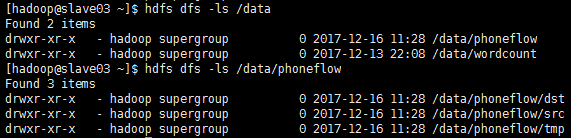

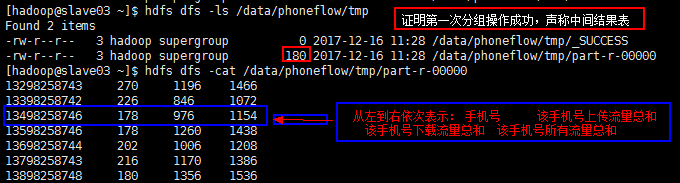
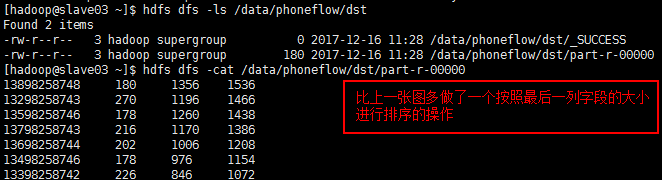
目标二:
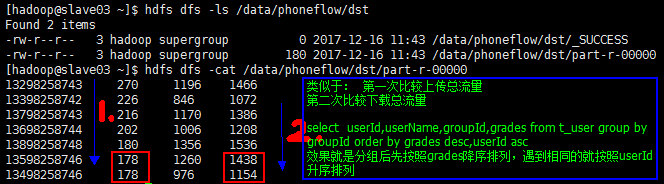

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}