

总结遇到的一些面试问题(一)
1、jvm的内存分配?
栈区,堆区(创建对象的方法),方法区
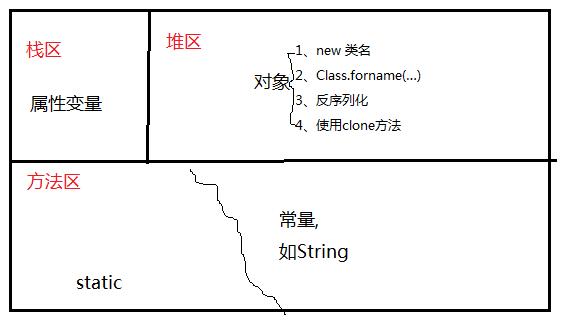
堆区的对象不被引用时,会被jvm的GC回收;看是否被引用主要是看有没有被栈区和方法区引用。
创建对象的前2者方式都需要显式地调用构造方法. 造成耦合性最高的恰好是第一种,因此你发现无论什么框架,只要涉及到解耦必先减少new的使用.
栈中用来存放一些原始数据类型的局部变量数据和对象的引用(String,数组.对象等等)但不存放对象内容;
堆中存放使用new关键字创建的对象。
1、基本数据类型的变量和对象的引用都是在栈分配的;
2、堆内存用来存放由new创建的对象和数组;
3、类变量:(static修饰的变量),程序在一加载的时候就在堆中为类变量分配内存,堆中的内存地址
存放在栈中;
4、实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量,是根
据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的"物理位置”,实例变量的
生命周期--当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释
放堆中内存;
5、局部变量: 由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局
部变量一但脱离作用域,内存立即释放。
2、jsp为啥不用try……catch……,或者说jsp如何抛异常?
JSP里应该不强制捕捉任何异常的。服务器框架已经帮你捕捉了。
JSP获取异常信息的exception对象:用来处理JSP文件执行时发生的所有错误和异常,只有在
page指令中设置isErrorPage="true"的页面中才能使用;
3、数据库分页查询
#查看表结构
DESC t_user
MySql中:limit函数
#此处的2表示索引为2的数据;如果id从1开始,那么查询出来的就是从id为3开始的连续4个结果
SELECT * FROM t_user LIMIT 2,4;
Oracle中: --oracle分页


select * from (select rownum r,e1.* from (select * from emp order by sal) e1 where rownum <=8 ) where r >=5;
rownum是e1表的行号不是e2表的行号,所以用别名避免重复;
然后可以使用>和>=符号
Hive中:--和Oracle比较类似
//row_number()是标识添加行号的关键字,按照over内的条件进行排列后,添加行号seq字段, //over内不写条件,默认是在,将按照第一个字段降序排列后的结果,前加行号 select * from (select row_number() over(order by sal desc) seq,e.* from emp e) mid where mid.seq>5 and mid.seq<11; //分页查询
4、hibernate一级缓存是否能够取消?调用哪个API可以调用二级缓存
不能,因为hibernate的底层封装的时jdbc,如果取消了,这个框架将没有意义。
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <!-- 一个sessionFactory代表数据库的一个连接 --> <session-factory> <!-- 链接数据库的用户名 --> <property name="connection.username">root</property> <!-- 链接数据库的密码 --> <property name="connection.password">root</property> <!-- 链接数据库的驱动 --> <property name="connection.driver_class"> com.mysql.jdbc.Driver </property> <!-- 链接数据库的url --> <property name="connection.url"> jdbc:mysql://localhost:3306/itheima12_hibernate </property> <!-- 方言 告诉hibernate使用什么样的数据库,hibernate就会在底层拼接什么样的sql语句 --> <property name="dialect"> org.hibernate.dialect.MySQLDialect </property> <!-- 二级缓存的供应商 --> <property name="cache.provider_class"> org.hibernate.cache.EhCacheProvider </property> <!-- 开启二级缓存 --> <property name="cache.use_second_level_cache">true</property> <!-- <class-cache usage="read-only" class=""/> --> <!-- 根据持久化类生成表的策略 validate 通过映射文件检查持久化类与表的匹配 update 每次hibernate启动的时候,检查表是否存在,如果不存在,则创建,如果存在,则什么都不做了 create 每一次hibernate启动的时候,根据持久化类和映射文件生成表 create-drop --> <property name="hbm2ddl.auto">update</property> <property name="show_sql">true</property> <property name="current_session_context_class">thread</property> <property name="format_sql">true</property> <!-- 开启二级缓存的统计机制 --> <property name="generate_statistics">true</property> <mapping resource="com/itheima12/hibernate/domain/Classes.hbm.xml" /> <mapping resource="com/itheima12/hibernate/domain/Student.hbm.xml" /> </session-factory> </hibernate-configuration>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"> <diskStore path="e:\\TEMP1"/> <defaultCache maxElementsInMemory="12" eternal="false" timeToIdleSeconds="1200" timeToLiveSeconds="1200" overflowToDisk="false" maxElementsOnDisk="10000000" diskPersistent="false" diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU" /> <Cache name="com.itheima12.hibernate.domain.Classes" maxElementsInMemory="3" //缓存最大数目 eternal="false" //属性指定是否永不过期 timeToIdleSeconds="120" //处于空闲状态最大秒数 timeToLiveSeconds="120" //处于缓存状态最大秒数 overflowToDisk="true" //内存溢出时,是否将溢出对象写入硬盘 maxElementsOnDisk="10000000" diskPersistent="false" diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU" /> </ehcache>
5、数据库索引怎么建立?
MySql中:CREATE INDEX 索引名称 ON 表名称(列名称);
eg: CREATE INDEX t_user_user_id ON t_user(user_id);
创建多重索引,eg: CREATE INDEX t_user_user_id_user_name ON t_user(user_id,user_name);
Oracle中:

数据库中索引的结构和什么情况下不适合建索引,数据库索引是如何实现的?
1>数据库中索引的结构是一种排序的数据结构。
2>数据库索引是通过B树和变形的B+树实现的。
3>什么情况下不适合建立索引?
1.对于在查询过程中很少使用或参考的列,不应该创建索引。
2.对于那些只有很少数据值的列,不应该创建索引。
3.对于那些定义为image,text和bit数据类型的列,不应该创建索引。
4.当修改性能远大于检索性能,不应该建立索引。
4>建立索引的优点?
1.通过创建唯一性的索引,可以保证表中每一行数据的唯一性;
2.可以大大加快表中数据的检索素的,这也是创建索引的主要原因;
3.可以加快表与表之间的链接,特别是在实现表与表之间的参考完整性实现有特别的意义;
4.通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统性能。
5>建立索引的缺点?
1.创建索引和维护索引耗时,时间随着数据的增加而增加,成正比;
2.索引需要占物理空间,除了数据表占数据空间外,每一个索引还要占一定的物理空间,如果建立聚簇索引,占得物理空间会更大;
3.当对表中的数据进行维护时,对索引也要进行维护,这样就降低了数据的维护速度。
可以在数据库中建立三种索引:唯一索引,主键索引,聚集索引。
唯一索引(unique) :不允许任意两行具有相同索引值的索引。
主键索引(primary):数据表中经常有一列或多列组合,其职唯一标识要求主键中的每表中的每一行,则该列称为主键。个值都是唯一的,当查询时使用主键索引,他还允许对数据的快速访问。
聚集索引():表中行的物理顺序和表中的逻辑顺序相同。一个标志能有一个聚集索引。
如果一个索引不是聚集索引,则表中的数据的物理顺序和表中的逻辑顺序不相同。
6、GC:守护线程?
7、springmvc和structs2的线程安全问题?
spring mvc:controller
1.spring mvc 默认controller是单实例(通过注解@Scope(“prototype”)变了多实例);
2.单实例时非线程安全,不要在controller中定义成员变量(实例变量);
3.单实例时,web容器启动时便开始实例化controller,全局唯此实例,每次访问都使用此实例
响应;
4.多实例时,每一次访问,基本&多数(发现偶尔也会重复使用实例)会产出新实例对应响应;
5.单实例时,并发请求,访问synchronized同步方法时,彼此阻塞影响(synchronized方法实
例锁);
6.多实例时,并发请求,访问synchronized同步方法时,彼此不影响(synchronized方法实例
锁);
struts2:action
1.struts2为每个线程提供一个action实例,多线程访问时不会出现问题。当使用spring管理
struts2的action实例对象时,scope必须配置为prototype或者session;若配置为singleton则多
线程访问时会出现问题,例如actionMessage,fieldError等信息会累加,多用户访问时有的用户
访问到的是另一个用户的数据。
2.scope=“prototype”是为每个请求提供一个action实例(与struts2的机制是一样的)。
scope=“session”是为每个会话提供一个action实例。
3.通常使用prototype,即让spring容器为每个请求提供一个action实例,好处是服务器端不用维
护用户状态信息,否则使用session服务器端必须存储状态信息,用户多时占用服务器端内存过多
。使用prototype时,必须自己在客户端维护用户的状态,每次访问服务端时将相应状态信息提交
给服务器。
例如scope=“prototype”时,页面一般< input name="id" type="hidden" value="${id}"/>用
来存储用户的id信息,访问action时提交到server端供action中函数使用。而使用
scope=“session”时,页面不必使用hidden的对象隐藏id信息,只要服务端获取过用户的
id,action中的id属性即会保存这个信息。
8、性能优化
a.运行速度由快到慢:native>static>构造方法(private,超类的方法)>虚方法(实例方法 、抽 象方法) b.性能消耗由小到大(读取数据由快到慢):创建对象,内存;线程;进程;磁盘IO,socket 的IO;
9、反射和动态代理性能对比
无参数的加载类,响应时间排序:CGLIB Reflect<ASM<JDK Reflect,CGLIB最快;
有参数的加载类,响应时间排序:JDK Reflect<CGLIB,JDK反射最快;
方法的调用,响应时间排序:ASM<CGLIB Reflect<JDK Reflect;
加载类建议采用JDK反射
方法调用建议采用CGLIB
10、学习Oracle的笔记:
SQL优化原则:
1.使用列名代替*;(指定列名进行查询) 2.where解析顺序,从右向左 where A and B;先检查B,尽量将假的放右边 where A or B; 先检查B,尽量将真的放右边 3. 尽量使用where 4:理论上,尽量使用多表查询,少使用子查询 5:尽量不要使用集合运算,运算速度慢
SQL中null值:
1.包含null的表达式都为null;
2.null永远!= null
3.如果集合中,含有null,不能使用not in(相当于<> all或!= all); 但可以使用in(相当于
=any);
select * from emp where empno in (select mgr from emp); select * from emp where empno not in (select mgr from emp where mgr is not null); a not in (10,20,null)就相当于a!=10 and a!=20 and a!=null
(因为a!=null始终为假,故该条语句始终为假,所以没结果)
4. null值排序;(Oracle中,null最大)
(升序没问题;降序时需要在最后加一句:nulls last)
select * from emp order by comm;
select * from emp order by comm desc nulls last;
5. 组函数会自动过滤null;可以嵌套滤空函数来屏蔽他的滤空功能
count(*)等价于count(nvl(comm,0));
select count(*),count(nvl(comm,0)) from emp;
oracle自动开启事务,mysql手动开启(start transaction)
连接符concat,||
select concat('Hello','World') from dual;
select 'Helle'||"world" from dual;
双引号表示别名,单引号表示日期或者字符串
修改日期格式
alter session set NLS_DATE_FORMAT='yyyy-mm-dd';
转义字符: select * from emp where ename like '%\_%' escape '\';
where和having最大的区别:where后面不能使用组函数;
order by 后面可以+列,表达式,别名,序号;
在SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中。
desc只对离自己最近的一列有效,
日期函数:
MONTH_BETWEEN
ADD_MONTHS
NEXT_DAY
LAST_DAY
ROUND
TRUNC
select * from emp where sal> any(select sal from emp where deptno =30);结果会按照 sal排序desc

{kind=link}