


 阿里云优惠
阿里云优惠 副业
副业序列化到底是什么?
阅读正文:
我们都知道,新建一个对象的时候实现 Serializeable 接口,但为什么要这么做?什么时候这样子做?这样子做会不会出现幺蛾子?阿淼一个三连差点把自己都问懵逼了……

那接下来,大家就和阿淼一起简单了解一下这个知识点吧……
序
序列化的定义是:将一个对象编码成一个字节流(I/O);而与之相反的操作被称为反序列化。
序列化的目的是为了方便数据的传递以及存储到磁盘上(把一个Java对象写入到硬盘或者传输到网路上面的其它计算机,这时我们就需要将对象转换成字节流才能进行网络传输。对于这种通用的操作,就出现了序列化来统一这些格式)。
简单来说序列化就是一种用来处理对象流的机制。将对象转化成字节序列后可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
使用场景:所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的java对象都必须是可序列化的。比如 Redis 将对象当做字符串存储的时候,如果对象实现了序列化,则只需要将对象直接存储即可(java会自动将对象转换成序列化后的字节流);否则需要自己将对象转换成 json 字符串存储,不过 json 字符串相对更加节省内存空间一些。
通常建议:程序创建的每个JavaBean类都实现 Serializeable 接口。但是实现 Serializeable 接口也需要小心谨慎。正如《Effective Java》中第 74 条提到的那样:

如何实现序列化
在 Java 中,只要一个类实现了 java.io.Serializable 接口,它就可以被序列化(枚举类也可以被序列化)。
例如:每个枚举类型都会默认继承类java.lang.Enum,而Enum类实现了Serializable接口,所以枚举类型对象都是默认可以被序列化的。
// DeletedEnum 类,表示删除状态
@Getter
@AllArgsConstructor
public enum DeletedEnum {
NO_DELETED(0,"未删除"),
DELETED(1,"已删除");
public final Integer status;
public final String name;
}
下图是 java.lang.Enum 类:

而一个普通的类想实现序列化,只需要实现 Serializable 接口即可:
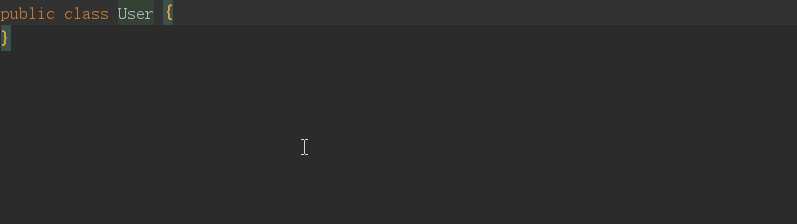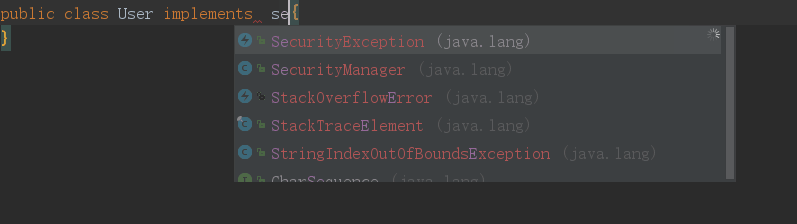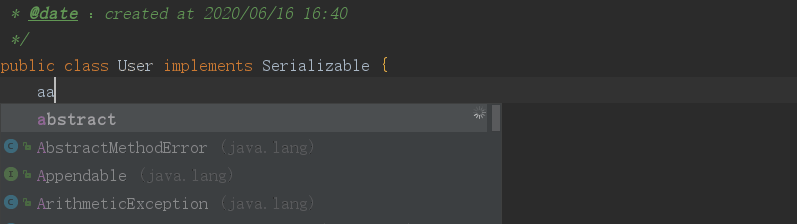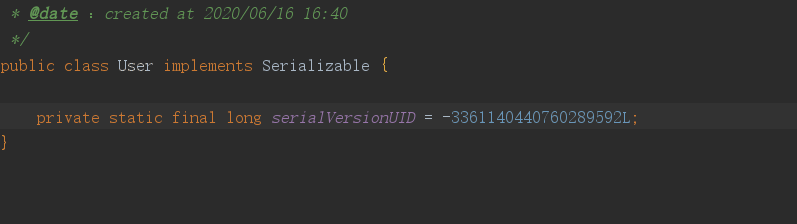
@Data
public class User implements Serializable {
//序列化版本号
private static final long serialVersionUID = 1111013L;
transient private String name;
private int age;
public static void main(String[] args) {
User user = new User();
user.setAge(12);
user.setName("小路飞");
System.out.println(user);
}
}
输出结果如下:
User(name=小路飞, age=12)
那为什么一个类实现了 Serializable 接口,它就可以被序列化呢?
这是因为它使用 ObjectOutputStream 来持久化对象到文件中,使用了 writeObject 方法,该方法又调用了如下方法:
/**
* Underlying writeObject/writeUnshared implementation.
*/
private void writeObject0(Object obj, boolean unshared) throws IOException {
……
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
……
}
从上述代码可知,如果被写对象的类型是String,或数组,或 Enum,或 Serializable,那么就可以对该对象进行序列化,否则将抛出 NotSerializableException。
即:String 类型的对象、枚举类型的对象、数组对象,都是默认可以被序列化的,并生成默认的序列化版本号。
我看网上的资料都有讲使用 Externalizable 接口和使用 transient 关键字来实现序列化的方法,但阿淼感觉用的不多,所以在这里就不过多的赘述了,况且它们其实都是基于 Serializable 接口实现的序列化。

如何自动生成序列化版本号
idea IDE
安装 serialVersionUID 插件即可。
eclipse
一般来说有两种生成方式:
- 一个是默认的1L,比如:
private static final long serialVersionUID = 1L; - 一个是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段。实现序列化后,类名上会出现黄色波浪下划线,选择第一项,添加已生成的串行版本标识即可自动生成一个。
序列化版本号的用处
在 java.io.Serializable 的文档中的解释是这样的:
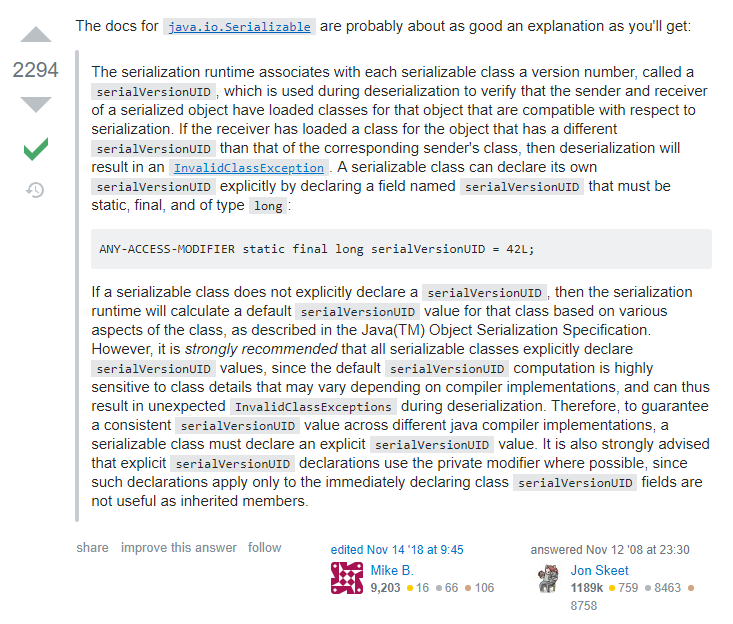
大致意思是如下:
因为反序列化必须拥有 class 文件,但随着项目的升级,class 文件也会升级,序列化怎么保证升级前后的兼容性呢?
序列化运行时与每个可序列化的类关联一个版本号,称为 serialVersionUID,在反序列化期间使用该版本号来验证序列化对象的发送者和接收者是否已加载了该对象的与序列化兼容的类。如果接收方已为该对象加载了一个与相应发送方类具有不同的 serialVersionUID 的类,则反序列化将导致 InvalidClassException。可序列化的类可以通过声明一个名为 serialVersionUID 的字段来显式声明其自己的 serialVersionUID,该字段必须是静态的,最终的且类型为 long:
ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
只要版本号相同,即使更改了序列化属性,对象也可以正确被反序列化回来。
@Data
public class User implements Serializable {
//序列化版本号
private static final long serialVersionUID = 1111013L;
private String name;
private int age;
}
如果反序列化使用的 class 的版本号与序列化时使用的不一致,反序列化会报 InvalidClassException 异常。
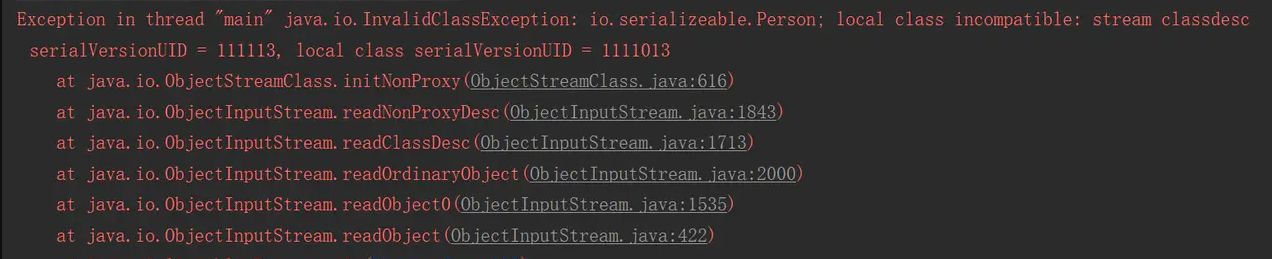
如果可序列化的类未明确声明 serialVersionUID ,则序列化运行时将根据该类的各个方面为该类计算默认的 serialVersionUID 值,如Java(TM)对象序列化规范中所述。但是,强烈建议所有可序列化的类显式声明 serialVersionUID 值,因为默认的 serialVersionUID 计算对类详细信息高度敏感,而类详细信息可能会根据编译器的实现而有所不同,因此可能在反序列化期间导致意外的 InvalidClassExceptions。
而且,默认值不利于 jvm 间的移植,可能class文件没有更改,但不同 jvm 可能计算的规则不一样,这样也会导致无法反序列化。
因此,为了保证不同Java编译器实现之间的 serialVersionUID 值一致,可序列化的类必须声明一个显式的 serialVersionUID 值。强烈建议显式 serialVersionUID 声明在可能的情况下使用 private 修饰符,因为此类声明仅适用于立即声明的类 serialVersionUID字段作为继承成员不起作用。
最后,使用默认机制在序列化对象时,不仅会序列化当前对象,还会对该对象引用的其它对象也进行序列化,同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2018-06-26 SpringBoot学习(三)-->Spring的Java配置方式之读取外部的资源配置文件并配置数据库连接池
2018-06-26 SpringBoot学习(二)-->Spring的Java配置方式
2018-06-26 eclipse创建的maven项目,pom.xml文件报错解决方法
2018-06-26 SpringBoot学习(一)-->Spring的发展