

玩转SpringBoot中的那些连接池
hello~各位读者新年好!
回想起前几天在部署springboot项目到正线时,线上环境要求jdk7,可项目是基于jdk8开发的,springboot也是用的springboot2以上的版本,可以说缝缝补补一整天才搞好能满足线上环境的代码,搞完后当然需要小小的了解一下背后的秘密。
好了,话不多说,我们直接进入正题。
其实切换还不算太麻烦,坑就坑在SpringBoot2切换到SpringBoot1后,默认使用的连接池发生了变化,之前做的压力测试又重新搞了一遍。

怨天尤人貌似消极了哈,小编我可是一个正能量满满的人,所以总结下自己就是:虽然会用,但是没了解技术背后的真相而闹出的乌龙。
接下里我们就一起来检验下SpringBoot2和SpringBoot1使用的默认数据源吧!
一、SpringBoot2的HikariCP
- 首先在pom文件中需要引入的依赖包:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<mybatis.spring.boot.version>1.3.1</mybatis.spring.boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring.boot.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
- 其次在配置文件中需要定义如下属性(不定义时会自动使用默认值)
# spring的相关配置
spring:
application:
name: HikariCP测试
# 数据源的配置
datasource:
# 连接池的配置
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 5
maximum-pool-size: 15
connection-test-query: SELECT 1
max-lifetime: 1800000
connection-timeout: 30000
pool-name: DatebookHikariCP
- 配置好后,启动成功时你能看到类似这样子的打印信息:
2020-01-16 16:23:12.911 INFO 9996 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2020-01-16 16:23:12.913 INFO 9996 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'dataSource' has been autodetected for JMX exposure
2020-01-16 16:23:12.924 INFO 9996 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Located MBean 'dataSource': registering with JMX server as MBean [com.zaxxer.hikari:name=dataSource,type=HikariDataSource]
2020-01-16 16:23:12.994 INFO 9996 --- [ main ] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 18001 (http) with context path ''
2020-01-16 16:23:13.002 INFO 9996 --- [ main ] c.j.mmzsblog.DatasourceTestApplication : Started DatasourceTestApplication in 6.724 seconds (JVM running for 8.883)
其中第3行[com.zaxxer.hikari:name=dataSource,type=HikariDataSource]这部分就点明了使用的连接池类型
二、SpringBoot1的tomcat-jdbc
降低版本后,我没有看到上面的信息打印,一时差点不知道使用了什么连接池,不过网上都说是tomcat-jdbc;但是相信眼见为实的我,肯定要在哪里打印一下才放心,于是乎,我进行了如下操作:
搞了一个controller来简单的打印一下连接池的信息
@RestController
public class testController {
@Resource
private DataSource dataSource;
@GetMapping("/query")
public void query(){
System.out.println("查询到的数据源连接池信息是:"+dataSource);
System.out.println("查询到的数据源连接池类型是:"+dataSource.getClass());
System.out.println("查询到的数据源连接池名字是:"+dataSource.getPoolProperties().getName());
}
}
然后我就看到了如下的打印信息,果真是用的tomcat-jdbc
查询到的数据源连接池信息是:org.apache.tomcat.jdbc.pool.DataSource@181d8899{ConnectionPool[defaultAutoCommit=null; defaultReadOnly=null; defaultTransactionIsolation=-1; defaultCatalog=null; driverClassName=com.mysql.jdbc.Driver; maxActive=100; maxIdle=100; minIdle=10; initialSize=10; maxWait=30000; testOnBorrow=true; testOnReturn=false; timeBetweenEvictionRunsMillis=5000; numTestsPerEvictionRun=0; minEvictableIdleTimeMillis=60000; testWhileIdle=false; testOnConnect=false; password=********; url=jdbc:mysql://localhost:3306/xxxxxx; username=xxxx; validationQuery=SELECT 1; validationQueryTimeout=-1; validatorClassName=null; validationInterval=3000; accessToUnderlyingConnectionAllowed=true; removeAbandoned=false; removeAbandonedTimeout=60; logAbandoned=false; connectionProperties=null; initSQL=null; jdbcInterceptors=null; jmxEnabled=true; fairQueue=true; useEquals=true; abandonWhenPercentageFull=0; maxAge=0; useLock=false; dataSource=null; dataSourceJNDI=null; suspectTimeout=0; alternateUsernameAllowed=false; commitOnReturn=false; rollbackOnReturn=false; useDisposableConnectionFacade=true; logValidationErrors=false; propagateInterruptState=false; ignoreExceptionOnPreLoad=false; useStatementFacade=true; }
查询到的数据源连接池类型是:class org.apache.tomcat.jdbc.pool.DataSource
查询到的数据源连接池名字是:Tomcat Connection Pool[1-1715657818]
其实,我们从pom文件也能看出其中的门道:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
依赖文件中的这一个依赖其实就是表明了SpringBoot1使用的是tomcat-jdbc连接池。
哎,现在才知道SpringBoot2.0和SpringBoot1.0版本使用的默认数据库是不一样的。
现在原因是找到了,可是如何解决呢?要不然把SpringBoot1版本的默认连接池修改成和SpringBoot2版本的一样。好,有了想法,那就开干。

其实,在SpringBoot1的版本也是可以使用HikariCP连接池的,操作就是:
- 首先引入默认配置的数据源处排除掉tomcat-jdbc
<!--配置默认数据源 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<exclusions>
<!-- 排除默认的tomcat-jdbc数据源 -->
<exclusion>
<groupId>org.apache</groupId>
<artifactId>tomcat-jdbc</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 引用SpringBoot2默认的HikariCP数据源 -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.3.1</version>
</dependency>
- 再在.yml文件中配置HikariCP数据源的相关信息
# spring的相关配置
spring:
# 数据源的配置
datasource:
# 连接池的配置
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 5
maximum-pool-size: 15
connection-test-query: SELECT 1
max-lifetime: 1800000
connection-timeout: 30000
为什么说我此处要将数据源切换成SpringBoot2.0使用的默认数据源呢?因为使用SpringBoot1.0的tomcat-jdbc数据源我怕压力测试出来达不到要求,为了不给测试增加工作压力(小编我就是这么好的一个人)

所以我进行了上面的替换操作。
不过这样做肯定也是有好处的。好处就在于HikariCP那迷人的优势:
- 1、字节码级别优化(很多方法通过JavaAssist生成)
- 2、大量小改进
- 用FastStatementList代替ArrayList
- 无锁集合ConcurrentBag
- 代理类的优化(比如:,用invokestatic代替invokevirtual)
正如官网的这个对比图显示的一样:它更快

其实话又说回来,要是我一开始就是用第三方数据库,岂不是就不存在这些自己搞出来的幺蛾子了!

比如阿里巴巴的Druid连接池不就是个优秀的产品么!它到底有多优秀呢?你先看它的使用:
三、其它连接池(如:Druid)
3.1、SpringBoot1.0中引用Druid
和前文的SpringBoot1.0中引用HikariCP一样,先排除默认数据源tomcat-jdbc再引用想要使用的连接池
- 3.1.1、首先引入默认配置的数据源处排除掉tomcat-jdbc
<!--配置默认数据源 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<exclusions>
<!-- 排除默认的tomcat-jdbc数据源 -->
<exclusion>
<groupId>org.apache</groupId>
<artifactId>tomcat-jdbc</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 引用阿里巴巴的druid数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.31</version>
</dependency>
- 3.1.2、再在.yml文件中配置Druid数据源的相关信息
spring:
# 数据源的配置
datasource:
# 连接池的配置
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 5
max-active: 10
min-idle: 5
max-wait: 30000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
validation-query: SELECT 1 FROM DUAL
validation-query-timeout: 60000
test-on-borrow: false
test-on-return: false
test-while-idle: true
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 100000
- 3.1.3、再写个配置类加载数据源
@Configuration
@ConditionalOnClass(DruidDataSource.class)
@ConditionalOnProperty(name = "spring.datasource.type", havingValue = "com.alibaba.druid.pool.DruidDataSource", matchIfMissing = true)
public class DataSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid")
public DataSource dataSourceOne() {
return DruidDataSourceBuilder.create().build();
}
}
- 3.1.4、启动效果:
2020-01-17 16:59:32.804 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2020-01-17 16:59:32.806 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'dataSourceOne' has been autodetected for JMX exposure
2020-01-17 16:59:32.808 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'statFilter' has been autodetected for JMX exposure
2020-01-17 16:59:32.818 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Located MBean 'dataSourceOne': registering with JMX server as MBean [com.alibaba.druid.spring.boot.autoconfigure:name=dataSourceOne,type=DruidDataSourceWrapper]
2020-01-17 16:59:32.822 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Located MBean 'statFilter': registering with JMX server as MBean [com.alibaba.druid.filter.stat:name=statFilter,type=StatFilter]
2020-01-17 16:59:32.932 INFO 8520 --- [ main ] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 18001 (http)
2020-01-17 16:59:32.943 INFO 8520 --- [ main ] c.j.mmzsblog.DatasourceTestApplication : Started DatasourceTestApplication in 8.328 seconds (JVM running for 10.941)
3.2、SpringBoot2.0中引用Druid
在SpringBoot2.0中引用Druid和在SpringBoot1.0中引入类似;
- 3.2.1、不需要排除默认配置的数据源,直接引入置Druid数据源
<!-- 引用阿里巴巴的druid数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.31</version>
</dependency>
- 3.2.2、在.yml文件中配置的Druid数据源的相关信息同3.1.3一样
- 3.2.3、再写个配置类加载数据源同3.1.3一样
- 3.2.4、启动后你同样能看到打印出类似的信息
Located MBean 'dataSourceOne': registering with JMX server as MBean [com.alibaba.druid.spring.boot.autoconfigure:name=dataSourceOne,type=DruidDataSourceWrapper]
3.3、优秀在哪?
看了上面的使用,超级简单又木有?
首先我们看看druid官网给出的几个传统连接池之间的对比吧:
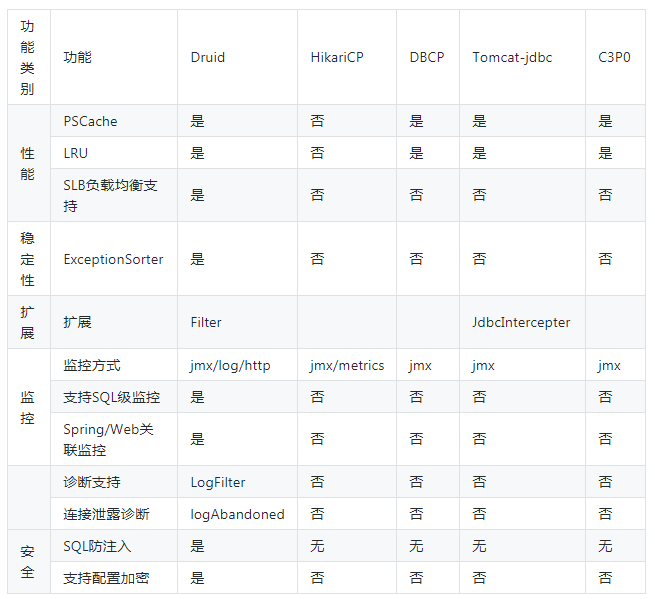
从上表可以看出,Druid连接池在性能、监控、诊断、安全、扩展性这些方面远远超出竞品。
官网是这样介绍它的:
Druid连接池是阿里巴巴开源的数据库连接池项目。Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
所以,小编我倒腾了这么久,想明白了一件事,我以后还是用阿里爸爸的Druid连接池吧,接入简单,还自带监控,并且它可是经过阿里巴巴各大系统考验过的产品,值得信赖,省事省心啊。

参考:
- 1:HikariCP的优点:https://www.jianshu.com/p/129efe2c8e49
- 2、druid官网:https://github.com/alibaba/druid/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}