


15 | 哈希表(链表前向性,数组实现邻接表)
哈希表
哈希表原理
使用数组下标直接标记元素
哈希表(也叫散列表):是一种高效的、通过把关键码值映射到表中一个位置来访问记录的数据结构。
类似字符串,查找的时间复杂度是常数时间,缺点是,需要消耗更多的内存。
现在要存储和使用下面的线性表: A(12, 83,284, 49, 183, 13491, 58)。
为了用0(1)的时间实现查找,可以开一个一维数组A[1...13491],使得A[key]=key,
但显然造成了空间上的很大浪费,尤其是数据范围很大时。
除余法构造哈希值
例如:我们定义哈希函数H(x) = x mod 16, 对数组A(12,83, 284,49,183, 13491, 58)
进行哈希运算后,插入一些数据的效果如下图。
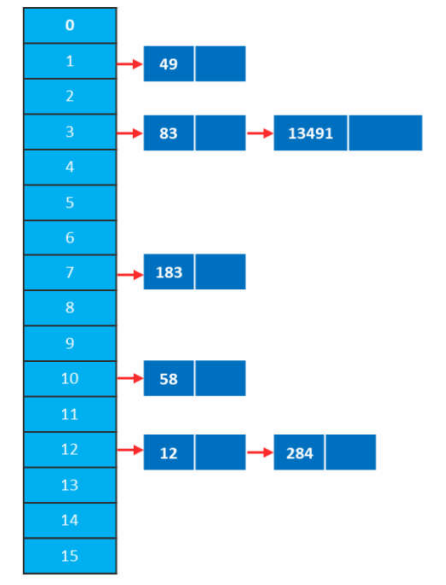
哈希函数的构造
取余法构造哈希: H(key) = key % b,为了尽量避免冲突,一般选为能够存储下并且尽量大的素数(一般情况下我们根据空间取10^6左右的素数)。一般地说,如果b的约数越多,那么冲突的几率就越大。.
使用数组来模拟邻接表(模板)
插入关键操作
v = hash(x);//计算x的哈希值
idx++;
e[idx] = x;
ne[idx] = h[v];
h[v] = idx;
查找关键操作
int v = hash(x);//计算 x的哈希值
//循环链表
for(int i = h[v];i!=0;i=ne[i]){
if(e[i] == x){
return true ;
}
}
例如:读入整数2 5 6 8 311,假设h[x]=x% 6。
则:每个元素的哈希值是2 5 0 2 3 5
存储数组如下:
element数组:按读入的顺序,存储每个元素的值。

next数组: next[i ]存储和element[i]哈希值相同的上一一个数的编号

header数组: header[i]存 储哈希值为i的最后一个元素的编号

注意:element数组和next数组是等长的,而header数组的长度与取余法的商相关
🔧题目 1(书号管理)
题目描述
图书管理是一件十分繁杂的工作,在一个图书馆中每天都会有许多新书加入。为了更方便的管理图书(以便于帮助想要借书的客人快速查找他们是否有他们所需要的书),我们需要设计一个图书查找系统。
该系统需要支持 2 种操作:
add(x) 表示新加入一本书号为 x 的图书。
find(x) 表示查询是否存在一本书号为 x 的图书。
输入
第一行包括一个正整数 n,表示操作数。 以下 n 行,每行给出 2 种操作中的某一个指令条,指令格式为:
add x
find x
在书号 x 与指令(add,find)之间有一个隔开,我们保证所有书号都是一个值在[-109≤x≤109]之间的整数。
本题n≤106。
输出
对于每个 find(x) 指令,我们必须对应的输出一行 yes 或 no,表示当前所查询的书是否存在于图书馆内。
注意:一开始时图书馆内是没有一本图书的,本题允许加入到图书馆的书号 x 出现重复。
样例
输入
8
add 3
add 100006
add 6
find 6
add 100009
find 9
add -100000
find 3
输出
yes
no
yes
#include <bits/stdc++.h>
using namespace std;
const int N=1e6+3;
//e[i]:代表读入的每个数
//ne[i]:代表和e[i]哈希值相同的上-一个数的编号
//h[i]:代表哈希值为i的最后一个数的编号
int e[N],ne[N],h[N], idx;
int n;
//插入到哈希表
void insert(int x){
//计算x的哈希值
int v=(x%N+N) %N;
idx++;
e[idx]= x;
ne[idx] = h[v];
h[v] = idx;
}
//查询
bool query(int x){
int v=(x%N+N) %N;
//遍历链表
for(int i = h[v];i != 0;i=ne[i]){
if(e[i] == x) return true;
}
return false;
}
int main(){
scanf( "%d",&n);
char order[10];
int x;
while(n--){
scanf( "%s%d" ,order,&x);
//插入到哈希表
if(order[0] == 'a') insert(x);
else{
if(query(x)) printf("yes\n");
else printf("no\n");
}
return 0;
}
}
这道题同样可以用开放寻址法来处理,而不是用邻接表。开放寻址法数组长度要开到题目要求的2~3倍
#include<bits/stdc++.h>
using namespace std;
//开放寻址法
//数组大小开到要求的2倍,找到>200000 的最小的质数
const int N = 200003;
//这是一个>10的9次方的数,不在题目规定的范围内
const int INF = 0x3f3f3f3f ;
int h[N];
//如果x在hash表中存在,返回其下标
//如果x不在hash表中,返回x应该存储的位置
int find(int x) {
int k= (x%N + N) %N;
//当这个位置有数值,且数值不是x
while(h[k] != INF && h[k] != x) {
k++;
if(k==N){
k=0;
}
}
return k;
}
int main() {
int n;
scanf("%d",&n);
//清空h
memset(h, 0x3f, sizeof(h));
while(n--) {
char op[10];
int x;
scanf( "%s%d", op, &x);
int k = find(x);
if(*op == 'a') {
h[k] = x;
} else {
if(h[k] != INF) puts("yes");
else puts("no");
}
}
return 0;
}
🔧题目 2(图书管理)
题目描述
图书管理是一件十分繁杂的工作,在一个图书馆中每天都会有许多新书加入。为了更方便的管理图书(以便于帮助想要借书的客人快速查找他们是否有他们所需要的书),我们需要设计一个图书查找系统。
该系统需要支持 2 种操作:
add(s) 表示新加入一本书名为 s 的图书。
find(s) 表示查询是否存在一本书名为 s 的图书。
输入
第一行包括一个正整数 n,表示操作数。 以下 n 行,每行给出 2 种操作中的某一个指令条,指令格式为:
add s
find s
在书名 s 与指令(add,find)之间有一个隔开,我们保证所有书名的长度都不超过 200。可以假设读入数据是准确无误的。
本题n≤30000。
输出
对于每个 find(s) 指令,我们必须对应的输出一行 yes 或 no,表示当前所查询的书是否存在于图书馆内。
注意:一开始时图书馆内是没有一本图书的。并且,对于相同字母不同大小写的书名,我们认为它们是不同的。
样例
输入复制
4
add Inside C#
find Effective Java
add Effective Java
find Effective Java
输出
no
yes
#include <bits/stdc++.h>
using namespace std;
/*
1.算出每本书 (字符串) 的哈希值
2.将该哈希值 % MOD,构建哈希表
*/
typedef unsigned long long ULL;
const int N =3e4+10,MOD = 1e6 +3,P=131;
ULL e[N],ne[N],idx; // 书籍名称的哈希值, 数组大小为书的个数
ULL h[MOD]; // h[i] 哈希值为 i 的最后一个数的位置
int n;
//计算字符串的哈希值
ULL gethash(char s[]){
ULL r = 0;
for(int i=1;s[i];i++){
r=r*P + s[i];
}
return r;
}
//插入哈希表
void insert(ULL x){
int v=x%MOD;
idx++;
e[idx]=x;
ne[idx]=h[v];
h[v]=idx;
}
//查询
bool query(ULL x){
int v = x%MOD;
for(int i=h[v];i;i=ne[i]){
if(e[i]==x){
return true;
}
}
return false;
}
int main(){
scanf("%d",&n);
char order[10],name[210];
while(n--){
scanf("%s",order); //读到空格之前
// 读到这一行的结尾
// 注意要对字符串求哈希值,我们的习惯就是 从 1 开始。 第一个字符……
cin.getline(name+1,205); // 注意这样读取可以一直读取到换行
if (order[0]=='a')
{
insert(gethash(name));
}
else{
if(query(gethash(name))) printf("yes\n");
else printf("no\n");
}
}
}
