


13 | 字符串哈希(字符串的哈希判等、前缀和的思想)
题目描述
给定一个含有 26 个小写英文字母的字符串。有m次询问,每次给出2个区间,请问这两个区间里的子字符串是否一样?
输入
第一行输入一个字符串 S。
第二行一个数字 m,表示 m 次询问。
接下来 m 行,每行四个数字 l1,r1,l2,r2,分别表示此次询问的两个区间,注意字符串的位置从1开始编号。
数据范围:
1≤length(S),m,l1,r1,l2,r2≤1000000。
输出
对于每次询问,输出一行表示结果。
如果两个子串完全一样,输出 Yes,否则输出 No(注意大小写)。
样例
输入
aabbaabb 3 1 3 5 7 1 3 6 8 1 2 1 2
输出
Yes No Yes
#include <bits/stdc++.h> using namespace std; typedef unsigned long long ULL; const int N=1e6+10,P=131; //h[i]:代表 1~i 区间中字串的哈希值 //p[i]:代表P的i次方 ULL h[N],p[N]; char s[N]; int m; //返回字符串子区间的哈希值 ULL get(int l,int r){ return h[r]-h[l-1]*p[r-l+1]; } int main(){ scanf("%s",s+1); //计算出 h[] 和 p[] 的值 p[0]=1; int len = strlen(s+1); for(int i=1;i<=len;i++){ p[i]=p[i-1]*P; h[i]=h[i-1]*P+(s[i]-'a'+1); } scanf("%d",&m); int l1,r1,l2,r2; while(m--){ scanf("%d%d%d%d",&l1,&r1,&l2,&r2); //如果两个子区间的哈希值相同 if(get(l1,r1)==get(l2,r2)) printf("Yes\n"); else printf("No\n"); } return 0; }
字符串哈希
什么是哈希
哈希算法是:通过哈希函数将字符串、较大的数等转换为能够用变量表示的或者是直接能作为数组下标的数,通过哈希算法转换到的值,称之为哈希值。哈希值可以实现快速查找和匹配。
比如:用数组下标计数法,统计一个字符串中,每种字母出现的次数就是一个简单的哈希,将每个字母都映射为了对应的ascii码。
如何构造哈希
原理:将字符串中的每一个字母都看作是一个数字(例:从a-z,视为1一26);将字符串视为是一个b进制的数。(注意,不能映射为0,因为如果a为0,那么a、aa、aaa的值将都为0)
比如:可以将字符串s="abcd"视为26进制的整数,则可以计算出:
hash(s):1 * 26^3+2 * 26^2+ 3 * 26^1+4* 26^0。如果字符串很长,h(s)很容易超出long long的范畴,为防止溢出,我们取一个固定的值h用hash(s)%h,使得结果在long long范围内。
选取两个合适的互质常数 b和h (b<h),其中h要尽可能的大一点,为了降低冲突(不同字符串计算到同一个哈希值)的概率。
一般来说: b取 131 或13331, h取26^4,最终产生的哈希值的冲突的概率极低。

滚动哈希优化
如果针对一个很长的字符串,判断其中两个长度为len的子串是否相同,如果采用0(len)的时间复杂度计算出对应的子串hash,那和直接取出子串比较的时间复杂度并无差异,因此我们需要使用滚动哈希优化的技巧,可以在0(1)的时间复杂度下取出子串的hash值。
滚动计算到前缀哈希 h(K)
设:h(k)为字符串C前k个字符构成的子串的哈希值,(先不考虑取模):
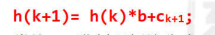
类比10进制理解该公式,比如10进制的12345,取出前3个数是123,如果要取前4个数,可以使用: 123 * 10(进制) + 4(Ck+1) = 1234 的方法来取出。
利用前缀哈希 H(k) 计算区间哈希值
设

由.上述公式可知,只需要预处理出b",就可以在0(1)的时间内求得任意子串的哈希值。
时间复杂度
综上,如果在一个长度为n的字符串中,任意取长度为m的子串进行匹配,时间复杂度
为0(n+m)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)