

16 | 函数对象和lambda:进入函数式编程
C++98 的函数对象
函数对象(function object) 自 C++98 开始就已经被标准化了。从概念上来说,函数对象是一个可以被当作函数来用的对象。它有时也会被叫做 functor,但这个术语在范畴论里有着完全不同的含义,还是不用为妙——否则玩函数式编程的人可能会朝着你大皱眉头的。
下面的代码定义了一个简单的加 n 的函数对象类(根据一般的惯例,我们使用了 struct 关键字而不是 class 关键字):
struct adder {
adder(int n) : n_(n) {}
int operator()(int x) const
{
return x + n_;
}
private:
int n_;
};
它看起来相当普通,唯一有点特别的地方就是定义了一个 operator(),这个运算符允许我们像调用函数一样使用小括号的语法。随后,我们可以定义一个实际的函数对象,如 C++11 形式的:
auto add_2 = adder(2);
或 C++98 形式的:
adder add_2(2);
得到的结果 add_2 就可以当作一个函数来用了。你如果写下 add_2(5) 的话,就会得到结果 7。
C++98 里也定义了少数高阶函数:你可以传递一个函数对象过去,结果得到一个新的函数对象。最典型的也许是目前已经从 C++17 标准里移除的 bind1st 和 bind2nd 了(在
auto add_2 = bind2nd(plus<int>(), 2);
这样产生的 add_2 功能和前面相同,是把参数 2 当作第二个参数绑定到函数对象 plus
binder2nd<plus<int> > add_2(
plus<int>(), 2);
因此,在 C++98 里我们通常会直接使用绑定的结果:
#include <algorithm>
#include <functional>
#include <vector>
using namespace std;
vector v{1, 2, 3, 4, 5};
transform(v.begin(), v.end(),
v.begin(),
bind2nd(plus<int>(), 2));
函数的指针和引用
除非你用一个引用模板参数来捕捉函数类型,传递给一个函数的函数实参会退化成为一个函数指针。不管是函数指针还是函数引用,你也都可以当成函数对象来用。
假设我们有下面的函数定义:
int add_2(int x)
{
return x + 2;
};
如果我们有下面的模板声明:
template <typename T>
auto test1(T fn)
{
return fn(2);
}
template <typename T>
auto test2(T& fn)
{
return fn(2);
}
template <typename T>
auto test3(T* fn)
{
return (*fn)(2);
}
当我们拿 add_2 去调用这三个函数模板时,fn 的类型将分别被推导为 int ()(int)、int (&)(int) 和 int ()(int)。不管我们得到的是指针还是引用,我们都可以直接拿它当普通的函数用。当然,在函数指针的情况下,我们直接写 *value 也可以。因而上面三个函数拿 add_2 作为实参调用的结果都是 4。
很多接收函数对象的地方,也可以接收函数的指针或引用。但在个别情况下,需要通过函数对象的类型来区分函数对象的时候,就不能使用函数指针或引用了——原型相同的函数,它们的类型也是相同的。
Lambda 表达式
看一下上一节给出的代码在使用 lambda 表达式时可以如何简化。
auto add_2 = [](int x) {
return x + 2;
};
显然,定义 add_2 不再需要定义一个额外的类型了,我们可以直接写出它的定义。理解它只需要注意下面几点:
- Lambda 表达式以一对中括号开始(中括号中是可以有内容的;稍后我们再说)
- 跟函数定义一样,我们有参数列表
- 跟正常的函数定义一样,我们会有一个函数体,里面会有 return 语句
- Lambda 表达式一般不需要说明返回值(相当于 auto);有特殊情况需要说明时,则应使用箭头语法的方式:[](int x) -> int
- 每个 lambda 表达式都有一个全局唯一的类型,要精确捕捉 lambda 表达式到一个变量中,只能通过 auto 声明的方式
当然,我们想要定义一个通用的 adder 也不难:有点像python函数装饰器
auto adder = [](int n) {
return [n](int x) {
return x + n;
};
};
一个 lambda 表达式除了没有名字之外,还有一个特点是你可以立即进行求值。这就使得我们可以把一段独立的代码封装起来,达到更干净、表意的效果。
[](int x) { return x * x; }(3)
这个表达式的结果是 3 的平方 9。即使这个看似无聊的例子,都是有意义的,因为它免去了我们定义一个 constexpr 函数的必要。只要能满足 constexpr 函数的条件,一个 lambda 表达式默认就是 constexpr 函数。
另外一种用途是解决多重初始化路径的问题。假设你有这样的代码:
Obj obj;
switch (init_mode) {
case init_mode1:
obj = Obj(…);
break;
case init_mode2;
obj = Obj(…);
break;
…
}
这样的代码,实际上是调用了默认构造函数、带参数的构造函数和(移动)赋值函数:既可能有性能损失,也对 Obj 提出了有默认构造函数的额外要求(case语句中要求不能声明和初始化变量,也就倒逼我们用了对象的默认构造函数!)。
对于这样的代码,有一种重构意见是把这样的代码分离成独立的函数。不过,有时候更直截了当的做法是用一个 lambda 表达式来进行改造,既可以提升性能(不需要默认函数或拷贝 / 移动),又让初始化部分显得更清晰:
auto obj = [init_mode]() {
switch (init_mode) {
case init_mode1:
return Obj(…);
break;
case init_mode2:
return Obj(…);
break;
…
}
}(); //注意最后的()
变量捕获
现在我们来细看一下 lambda 表达式中变量捕获的细节。
变量捕获的开头是可选的默认捕获符 = 或 &,表示会自动按值或按引用捕获用到的本地变量,然后后面可以跟(逗号分隔):
- 本地变量名标明对其按值捕获(不能在默认捕获符 = 后出现;因其已自动按值捕获所有本地变量)
- & 加本地变量名标明对其按引用捕获(不能在默认捕获符 & 后出现;因其已自动按引用捕获所有本地变量)
- this 标明按引用捕获外围对象(针对 lambda 表达式定义出现在一个非静态类成员内的情况);注意默认捕获符 = 和 & 号可以自动捕获 this(并且在 C++20 之前,在 = 后写 this 会导致出错)
- *this 标明按值捕获外围对象(针对 lambda 表达式定义出现在一个非静态类成员内的情况;C++17 新增语法)
- 变量名 = 表达式 标明按值捕获表达式的结果(可理解为 auto 变量名 = 表达式)
- &变量名 = 表达式 标明按引用捕获表达式的结果(可理解为 auto& 变量名 = 表达式)
从工程的角度,大部分情况不推荐使用默认捕获符。更一般化的一条工程原则是:显式的代码比隐式的代码更容易维护。当然,在这条原则上走多远是需要权衡的,你也不愿意写出非常啰嗦的代码吧?否则的话,大家就全部去写 C 了。
一般而言,按值捕获是比较安全的做法。按引用捕获时则需要更小心些,必须能够确保被捕获的变量和 lambda 表达式的生命期至少一样长,并在有下面需求之一时才使用
- 需要在 lambda 表达式中修改这个变量并让外部观察到
- 需要看到这个变量在外部被修改的结果
- 这个变量的复制代价比较高
如果希望以移动的方式来捕获某个变量的话,则应考虑 变量名 = 表达式 的形式。表达式可以返回一个 prvalue 或 xvalue,比如可以是 std::move(需移动捕获的变量)。
按引用捕获:
vector<int> v1;
vector<int> v2;
…
auto push_data = [&](int n) {
// 或使用 [&v1, &v2] 捕捉
v1.push_back(n);
v2.push_back(n)
};
push_data(2);
push_data(3);
这个例子很简单。我们按引用捕获 v1 和 v2,因为我们需要修改它们的内容。
按值捕获外围对象:
#include <chrono>
#include <iostream>
#include <sstream>
#include <string>
#include <thread>
using namespace std;
int get_count()
{
static int count = 0;
return ++count;
}
class task {
public:
task(int data) : data_(data) {}
auto lazy_launch()
{
return
[*this, count = get_count()]() //[*this] 按值捕获外围对象(task);[count = get_count()] 捕获表达式可以在生成 lambda 表达式时计算并存储等号后表达式的结果。
mutable { //mutable 标记使捕获的内容可更改(缺省不可更改捕获的值,相当于定义了 operator()(…) const);
ostringstream oss;
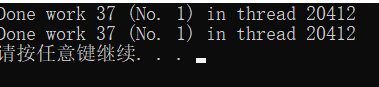
oss << "Done work " << data_
<< " (No. " << count
<< ") in thread "
<< this_thread::get_id()
<< '\n';
msg_ = oss.str();
calculate();
};
}
void calculate()
{
this_thread::sleep_for(100ms);
cout << msg_;
}
private:
int data_;
string msg_;
};
int main()
{
auto t = task{37};
thread t1{t.lazy_launch()};
thread t2{t.lazy_launch()};
t1.join();
t2.join();
}
这样,多个线程复制了任务对象,可以独立地进行计算。

请自行运行一下代码,并把 *this 改成 this,看看输出会有什么不同。
泛型 lambda 表达式
函数的返回值可以 auto,但参数还是要一一声明的。在 lambda 表达式里则更进一步,在参数声明时就可以使用 auto(包括 auto&& 等形式)。不过,它的功能也不那么神秘,就是给你自动声明了模板而已。毕竟,在 lambda 表达式的定义过程中是没法写 template 关键字的。
template <typename T1,
typename T2>
auto sum(T1 x, T2 y)
{
return x + y;
}
//跟上面的函数等价的 lambda 表达式是
auto sum = [](auto x, auto y)
{
return x + y;
}
//是不是反而更简单了?😂
你可能要问,这么写有什么用呢?问得好。简单来说,答案是可组合性。上面这个 sum,就跟标准库里的 plus 模板一样,是可以传递给其他接受函数对象的函数的,而 + 本身则不行。下面的例子虽然略有点无聊,也可以演示一下:
#include <array> // std::array
#include <iostream> // std::cout/endl
#include <numeric> // std::accumulate
using namespace std;
int main()
{
array a{1, 2, 3, 4, 5};
auto s = accumulate(
a.begin(), a.end(), 0,
[](auto x, auto y) {
return x + y;
});
cout << s << endl;
}
虽然函数名字叫 accumulate——累加——但它的行为是通过第四个参数可修改的。我们把上面的加号 + 改成星号 *,上面的计算就从从 1 加到 5 变成了算 5 的阶乘了。
bind 模板
我们上面提到了 bind1st 和 bind2nd 目前已经从 C++ 标准里移除。原因实际上有两个:
- 它的功能可以被 lambda 表达式替代
- 有了一个更强大的 bind 模板
拿我们之前给出的例子:
transform(v.begin(), v.end(),
v.begin(),
bind2nd(plus<int>(), 2));
现在我们可以写成:
using namespace std::
placeholders; // for _1, _2...
transform(v.begin(), v.end(),
v.begin(),
bind(plus<>(), _1, 2));
原先我们只能把一个给定的参数绑定到第一个参数或第二个参数上,现在则可以非常自由地适配各种更复杂的情况!当然,bind 的参数数量,必须是第一个参数(函数对象)所需的参数数量加一。而 bind 的结果的参数数量则没有限制——你可以无聊地写出 bind(plus<>(), _1, _3)(1, 2, 3),而结果是 4(完全忽略第二个参数)。
你可能会问,它的功能是不是可以被 lambda 表达式替代呢。回答是“是”。对 bind 只需要稍微了解一下就好——在 C++14 之后的年代里,已经没有什么地方必须要使用 bind 了。
function 模板
每一个 lambda 表达式都是一个单独的类型,所以只能使用 auto 或模板参数来接收结果。
在很多情况下,我们需要使用一个更方便的通用类型来接收,这时我们就可以使用 function 模板。function 模板的参数就是函数的类型,一个函数对象放到 function 里之后,外界可以观察到的就只剩下它的参数、返回值类型和执行效果了。注意 function 对象的创建还是比较耗资源的,所以请你只在用 auto 等方法解决不了问题的时候使用这个模板。
下面是个简单的例子。
map<string, function<int(int, int)>>
op_dict{
{"+",
[](int x, int y) {
return x + y;
}},
{"-",
[](int x, int y) {
return x - y;
}},
{"*",
[](int x, int y) {
return x * y;
}},
{"/",
[](int x, int y) {
return x / y;
}},
};
这儿,由于要把函数对象存到一个 map 里,我们必须使用 function 模板。随后,我们就可以用类似于 op_dict.at("+")(1, 6) 这样的方式来使用 function 对象。这种方式对表达式的解析处理可能会比较有用。
在ptyhon中的字典更加灵活,value值可以为函数名

 浙公网安备 33010602011771号
浙公网安备 33010602011771号