002 MySQL 库表属性、数据类型、约束、库函数
MySQL命令
客户端接口自带命令 服务端自带命令:
- 一般自带都是发送到连接层
- 其他发送到SQL层
\h 帮忙名
\G 客户端格式化命令 列和行翻转 ,以键值对的形式显示。
tee /tmp/1.log 记录日志的功能
\c 中断命令
\s status 状态信息 或者
source 导入SQL脚本 恢复数据库
显示服务端自带命令:
help contents
mysqladmin -uroot -p ping 数据库的状态是否存活
mysqladmin -uroot -p status 查看数据库的状态
mysqladmin -uroot -p variables 查看数据库的参数
函数包括 数值型函数、字符串型函数、日期时间函数、聚合函数
VERSION() 获取数据库的版本号。
DATABASE()、SCHEMA() 获取当前数据库名。
USER()、SYSTEM_USER()、SESSION_USER() 获取当前用户名。
CURRENT_USER()、CURRENT_USER 获取当前用户名。
CONNECTION_ID() 获取服务器的连接数。
CHARSET(str) 获取字符串str的字符集。
COLLATION(str) 获取字符串str的字符排序方法。
LAST_INSERT_ID() 获取最近生成的AUTO_INCREMENT值
NOW() 返回当前时间
引用 OLDGUO
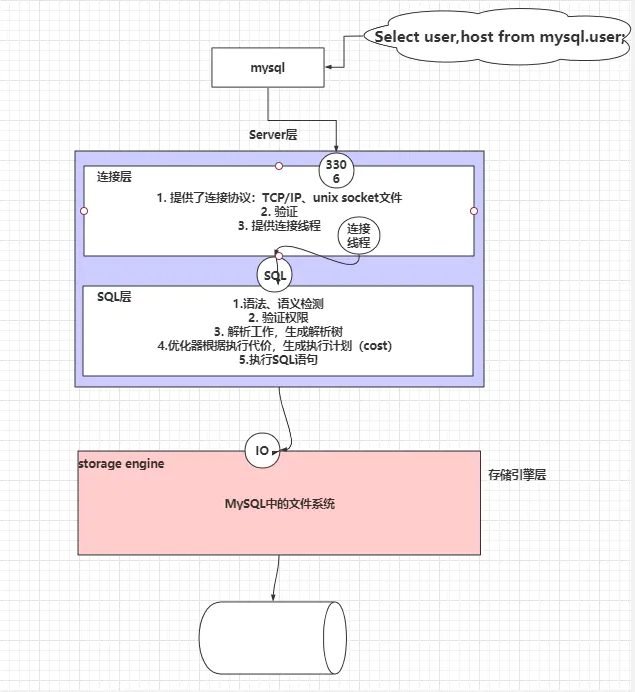
SQL 含义
SQL是什么? 结构化的语言
数据作为对象为不同种类的数据操作 做了不同的分类
DDL 数据定义语言
DCL 数据控制语言
DML 数据操作语言
DQL 数据查询语言
1. 库的定义
库名和表名必须使用小写 切记!
故障分析:测试环境正常,正式环境报错,windows大小写不敏感,库名或者表名使用了大小字母。
DDL 数据定义语言
定义库: 库名 库属性
查看库
show databases;
show create database user; 查看库的属性。
添加数据库
CREATE DATABASE `test` CHARACTER SET 'utf8mb4' COLLATE 'utf8mb4_general_ci';
删
drop database test;
修改库
alter database db charset gbk;
进入库的命令:
use 库名
不指定字符集的时候,默认字符集是什么?
拉丁语
创建数据的时候的字符集的指定:
utf8mb4 能够兼容4个字节的unicode编码
面试题: 在mysql中存储表情的话,创建库的时候应该指定什么字符集?为什么?
解:1、表情是使用4个字节存储, 在MySQL中可以使用utf-32 或者 utf8mb4
2、utf-32 太过于浪费空间,不推荐使用
3、mysql的utf-8的字符集能够兼容3个字节的unicode编码,而不是4个。为了兼容utf-8,MySQL推出发布utf-8mb4字符集。
排序规则:
utf8mb4_unicode_ci 根据unicode进行排序,排序精确
utf8mb4_general_ci 排序的效率更高,排序的精度不要求,所以通常情况推荐general
2. 表定义
# 创建表的时候,不指定字符集的话,默认继承库的属性。
CREATE TABLE `test`.`test` (
`id` int
);
----------
CREATE TABLE `student` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
查看表的属性或者叫查看建表的信息 show create table student;
删表
delete database userdb;
表的数据清空
清空表 delete from 表名; 或 truncate table 表名;(速度快、无法回滚撤销等)
表的列 增删改查
表的字段的增删改查
添加列
alter table 表名 add 列名 类型;
alter table 表名 add 列名 类型 DEFAULT 默认值;
alter table 表名 add 列名 类型 not null default 默认值;
alter table 表名 add 列名 类型 not null primary key auto_increment;
```
- 删除列
alter table 表名 drop column 列名;
- 修改列 类型
alter table 表名 modify column 列名 类型;
- 修改列 类型 + 名称
alter table 表名 change 原列名 新列名 新类型;
alter table tb change id nid int not null;
alter table tb change id id int not null default 5;
alter table tb change id id int not null primary key auto_increment;
alter table tb change id id int; -- 允许为空,删除默认值,删除自增。
- 修改列 默认值
ALTER TABLE 表名 ALTER 列名 SET DEFAULT 1000;
- 删除列 默认值
ALTER TABLE 表名 ALTER 列名 DROP DEFAULT;
只能有一个自增列【自增列,一般都是主键】
- 添加主键
alter table 表名 add key(列名);
- 删除主键
alter table 表名 drop primary key;
3 字段类型的说明
数字
数字类型 int [(m)][unsigned][zerofill]
int 表示有符号,取值范围:-2147483648 ~ 2147483647
建表语句: create table stone(id int);
show create table stone1
# 默认是int字节数是11个
int unsigned 表示无符号,取值范围:0 ~ 4294967295
建表语句: create table stone5(id int unsigned) default charset=utf8;
# 不需要使用负数的时候 默认10字节
int(5)zerofill 仅用于显示,当不满足5位时,按照左边补0,
例如:00002;满足时,正常显示。
create table stone6 (id int(5)zerofill) default charset=utf8;
默认5字节
tinyint[(m)] [unsigned] [zerofill]
有符号,取值范围:-128 ~ 127.
无符号,取值范围:0 ~ 255
建表语句: create table stone7(id tinyint unsigned );
一般使用作为年龄的字段
bigint[(m)][unsigned][zerofill]
有符号,取值范围:-9223372036854775808 ~ 9223372036854775807
无符号,取值范围:0 ~ 18446744073709551615
一般用不到
mysql> create table stone(id int, uid int unsigned, zid int(5) zerofill);
Query OK, 0 rows affected (0.03 sec)
浮点型的
decimal[(m[,d])] [unsigned] [zerofill]
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
如果存入的小数的位数超过规定的位数,那么后一位是四舍五入的。
例如:
create table L2(
id int not null primary key auto_increment,
salary decimal(8,2)
)default charset=utf8;
mysql> select * from L2;
+----+-----------+
| id | salary |
+----+-----------+
| 1 | 1.28 |
| 2 | 5.29 |
| 3 | 5.28 |
| 4 | 512132.28 |
| 5 | 512132.28 |
+----+-----------+
5 rows in set (0.00 sec)
FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
单精度浮点数,非准确小数值,m是数字总个数,d是小数点后个数。
32位的存储
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
64位的存储
总结 : 根据业务的量去选择类型,结合数据库的性能去优化,
比如人类的年龄是1-100之间,如果直接用int ,浪费空间 选择 tinyint unsigned 才是切合实际的优化方向。
字符串
char(m)
char(10) 就是就划定10个字节,爱用不用,数据超过就报错,数据小于10个字节,剩下的空着就空着
缺点: 如果设置过大会,浪费空间
优点: 不会对插入有影响。
定长字符串,m代表字符串的长度,最多可容纳255个字符。
定长的体现:即使内容长度小于m,也会占用m长度。例如:char(5),数据是:yes,底层也会占用5个字符;如果超出m长度限制(默认MySQL是严格模式,所以会报错)。
知道就好,不要用。。。。。
如果在配置文件中加入如下配置,
sql-mode="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
保存并重启,此时MySQL则是非严格模式,此时超过长度则自动截断(不报错)。。
注意:默认底层存储是固定的长度(不够则用空格补齐),但是查询数据时,会自动将空白去除。
如果想要保留空白,在sql-mode中加入 PAD_CHAR_TO_FULL_LENGTH 即可。
查看模式sql-mode,执行命令:show variables like 'sql_mode';
一般适用于:固定长度的内容。
create table L3(
id int not null primary key auto_increment,
name varchar(5),
depart char(3)
)default charset=utf8;
insert into L3(name,depart) values("alexsb","sbalex");
varchar(m)
varchar(30) 大白话就是先申请30个字节空间,有多少数据,就插入多少数据。
缺点: 先提前计算数据的大小,对插入性能有影响
优点:索引会对数值进行计算,数值越小,树就越小,性能查询就越快。
变长字符串,m代表字符串的长度,最多可容纳65535个字节。
变长的体现:内容小于m时,会按照真实数据长度存储;如果超出m长度限制((默认MySQL是严格模式,所以会报错)。
知道就好,不要用。。。。。
如果在配置文件中加入如下配置,
sql-mode="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
保存并重启,此时MySQL则是非严格模式,此时超过长度则自动截断(不报错)。
例如:
create table L3(
id int not null primary key auto_increment,
name varchar(5),
depart char(3)
)default charset=utf8;
mysql> create table L3(id int not null primary key auto_increment,name varchar(5),depart char(3))default charset=utf8;
-- 如果 sql-mode 中加入了 PAD_CHAR_TO_FULL_LENGTH ,则查询时char时空白会保留。
mysql> select name,length(name),depart,length(depart) from L3;
+-------+--------------+--------+----------------+
| name | length(name) | depart | length(depart) |
+-------+--------------+--------+----------------+
| w | 2 | WU | 3 |
| w1 | 5 | ALS | 3 |
+-------+--------------+--------+----------------+
4 rows in set (0.00 sec)
text
text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
一般情况下,长文本会用text类型。例如:文章、新闻等。
create table L4(
id int not null primary key auto_increment,
title varchar(128),
content text
)default charset=utf8;
mediumtext
A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters.
longtext
A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1)
总结 通常使用字符串是 varchar(255)
时间
datetime
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59)
timestamp
YYYY-MM-DD HH:MM:SS(1970-01-01 00:00:00/2037年)
对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储,查询时,将其又转化为客户端当前时区进行返回。
对于DATETIME,不做任何改变,原样输入和输出。
mysql> create table L5(
-> id int not null primary key auto_increment,
-> dt datetime,
-> tt timestamp
-> )default charset=utf8;
Query OK, 0 rows affected (0.03 sec)
mysql> insert into L5(dt,tt) values("2025-11-11 11:11:44", "2025-11-11 11:11:44");
mysql> select * from L5;
+----+---------------------+---------------------+
| id | dt | tt |
+----+---------------------+---------------------+
| 1 | 2025-11-11 11:11:44 | 2025-11-11 11:11:44 |
+----+---------------------+---------------------+
1 row in set (0.00 sec)
mysql> show variables like '%time_zone%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| system_time_zone | CST |
| time_zone | SYSTEM |
+------------------+--------+
2 rows in set (0.00 sec)
-- “CST”指的是MySQL所在主机的系统时间,是中国标准时间的缩写,China Standard Time UT+8:00
mysql> set time_zone='+0:00';
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%time_zone%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| system_time_zone | CST |
| time_zone | +00:00 |
+------------------+--------+
2 rows in set (0.01 sec)
mysql> select * from L5;
+----+---------------------+---------------------+
| id | dt | tt |
+----+---------------------+---------------------+
| 1 | 2025-11-11 11:11:44 | 2025-11-11 03:11:44 |
+----+---------------------+---------------------+
1 row in set (0.00 sec)
date
YYYY-MM-DD(1000-01-01/9999-12-31)
time
HH:MM:SS('-838:59:59'/'838:59:59')
总结 时间使用 datetime
如果是国际网站的话 使用timestamp ,会根据系统的时区转换。
枚举类型
ENUM('m','f')
相当于布尔
通常使用 男 女 开启关闭等状态的场景
1 2 3 从其中的选项选择,不一定只有2个。
约束
主键 相当于身份证号码 只能唯一。
既然唯一,那么就不能为null值,
第一个约束: not null 不能为空
第二个约束: primary key 主键 或者 unique key
第三个约束: AUTO_INCREMENT 自增长
第四个约束: defaulf 'True' 默认值
第五个约束: conment '注释123' 注释 一定要加

 浙公网安备 33010602011771号
浙公网安备 33010602011771号