


python 交流
基础部分
1.看代码
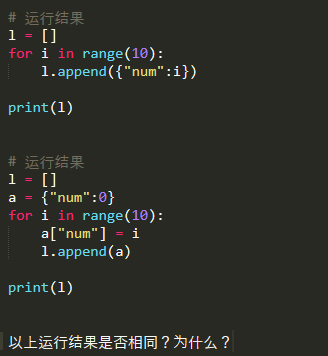
解释:

字典是可变对象,在下方的 l.append(a)的操作中是把字典 a 的引用传到列表 l 中,当后续操作修改 a[‘num’]的值的时候,l 中的值也会跟着改变,相当于浅拷贝。
2. 4G 内存怎么读取一个 5G 的数据?
方法一: 可以通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后在读取后面的 500MB 的数据。 方法二: 可以通过 linux 命令 split 切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行数切割,可以按照文件大小切割。
3.输入某年某月某日,判断这一天是这一年的第几天?
import datetime
def day_of_year():
year = input("年份:")
month = input("月份:")
day = input("天:")
date1 = datetime.date(year=int(year),month=int(month),day=int(day))
date2 = datetime.date(year=int(year),month=1,day=1)
return (date1-date2).days + 1
print(day_of_year())
4. os.path 和 sys.path 分别代表什么
os.path 主要是用于对系统路径文件的操作。 sys.path 主要是对 Python 解释器的系统环境参数的操作(动态的改变 Python 解释器搜索路径)。
5.模块和包的区别
python中,模块是搭建程序的一种方式,每一个Python代码文件都是一个模块,并可以引用其他模块,比如对象和属性 一个包含许多 Python 代码的文件夹是一个包。一个包可以包含模块和子文件夹
6.对字典d = {'a':24,'g':52,'i':12,'k':33}的values进行排序
d = {'a':24,'g':52,'i':12,'k':33}
temp = sorted(d.items(),key=lambda x:x[1])
print(temp)
from operator import itemgetter
sorted_ed = sorted(d.items(), key=itemgetter(1))
print(sorted_ed)
7.分析下列三个函数执行效率大小

利用程序分析包分析代码性能
import random
import cProfile
lIn = [random.random() for i in range(100**3)] # 随机赋值,值越大越明显
cProfile.run('f1(lIn)')
cProfile.run('f2(lIn)')
cProfile.run('f3(lIn)')
利用装饰器分析执行性能
import time
def outter(func):
def inner(*args):
beign = time.time()
func(*args)
use_time = time.time()-beign
print(use_time)
return inner
@outter # f1=outter(f1)(lIn)
def f1(lIn):
l1 = sorted(lIn)
l2 = [i for i in l1 if i<0.5]
return [i*i for i in l2]
@outter
def f2(lIn):
l1 = [i for i in lIn if i<0.5]
l2 = sorted(l1)
return [i*i for i in l2]
@outter
def f3(lIn):
l1 = [i*i for i in lIn]
l2 = sorted(l1)
return [i for i in l2 if i<(0.5**0.5)]
import random
temp = [random.random() for i in range(100000)]
f1(temp)
f2(temp)
f3(temp)
8.python内存管理机制
内存管理机制:引用计数,垃圾回收,内存池
应用计数制:python内部使用应用计数,来保持追踪内存中的对象,所有对象都有引用计数;
垃圾回收机制:当一个对象的引用计数为0的时候,它将会被垃圾回收机制处理;
内存池机制:python提供了对内存的垃圾收集机制,它将不用的内存放到内存池而不是返回给操作系统
垃圾回收机制:引用计数,标记清除,分代回收
9.filter、map、reduce的作用?
1:Map:主要包括两个参数,函数和列表。 将函数的结果以列表的形式返回。
会将一个函数映射到一个输入列表的所有元素。
规范:map(lambda x: x * x,[y for y in range(3)])
大多数时候,我们要把列表中的所有元素一个个的传递给一个函数,并收集输出。
2:Filter:包括两个参数function,list。根据function的返回值是True, 来过滤list的参数中的项,最后返回结果。
过滤列表中的元素,并且返回一个由所有符合要求的元素构成的列表。
符合要求 即函数映射到该元素时返回值为True.
3: Reduce:从列表中取出头两个元素并传递到一个二元函数中去, 求出值,再添加到序列中继续循环下一个值,直到最后一个值。
当需要对一个列表进行计算并返回结果时,reduce是一个很有用的函数。
例:当你需要计算一个整数列表的乘积时。通常在python中,你可能会使用基本的for循环来完成任务。
10.什么是可变,不可变类型?
 View Code
View Code11. 1,2,3,4,5可以组成多少个互不相同且不重复的三位数?
使用python内置的排列组合函数itertools(不放回抽样排列)
product 笛卡尔积 (有放回抽样排列)
permutations 排列 (不放回抽样排列)
combinations 组合,没有重复 (不放回抽样组合)
combinations_with_replacement 组合,有重复 (有放回抽样组合)
import itertools
goal = list(itertools.permutations('12345',3))
print(goal) # 返回所有结果
12.metaclass的作用:

设计模式相关
1.手写一个单例模式,或者通过装饰器实现一个单例模式
2.单例模式应用场景有哪些?
资源共享的情况下,避免由于资源操作时导致的性能或损耗等。如日志文件,应用配置
控制资源的情况下,方便资源之间的互相通信。如线程池等
3.函数装饰器的作用?
让其他函数在不需要做任何代码的变动的前提下增加额外的功能
如:插入日志、性能测试、事务处理、缓存、权限的校验等场景
4.谈谈对面向对象的理解?
面向对象是相对于面向过程而言的
面向过程是一种基于功能分析的,以算法为中心的程序设计方法
面向对象是一种基于结构,以数据为中心的程序设计思想
网络编程相关
1. 谈谈你对多进程,多线程,以及协程的理解,项目是否用?
进程:一个运行的程序(代码)就是一个进程,进程是系统资源分配的最小单位。进程都拥有自己独立的内存空间,之间数据不共享,开销大
线程:调度执行的最小单位,也叫执行路径,不能独立存在,一个进程至少有一个线程,叫主线程。多个线程之间共享内存(数据共享,全局变量共享),从而极大提高了程序的运行效率
协程:用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快
2.什么是线程竞争?
线程是非独立的,同一个进程里线程是数据共享的,当各个线程访问数据资源时会出现竞争状态即:数据几乎同步会被多个线程占用,造成数据混乱 ,即所谓的线程不安全那么解决多线程竞争利用了锁。
锁的好处:确保某段共享数据资源只能由一个线程从头到尾完整执行
锁的坏处:阻止了线程并发执行。包含锁定某段代码实际只能以单线程模式执行,效率降低
锁的致命问题:死锁
3.死锁概念?
若干子线程在系统资源竞争时,都在等待对方对某部分资源解除占用状态,结果是谁也不愿先解锁,互相干等着,程序无法执行下去,这就是死锁。
4.GIL锁?
GIL 锁:全局解释器锁(只在 cpython 里才有)
作用:限制多线程同时执行,保证同一时间只有一个线程执行,所以 cpython 里的多线程其实是伪多线程
5.进程和线程的使用场景?
多进程适合在 CPU 密集型操作(cpu 操作指令比较多,如位数多的浮点运算)。
多线程适合在 IO 密集型操作(读写数据操作较多的,比如爬虫)。
6.请简述浏览器是如何获取一枚网页的?
1.在用户输入目的 URL 后,浏览器先向 DNS 服务器发起域名解析请求
2.在获取了对应的 IP 后向服务器发送请求数据包
3.服务器接收到请求数据后查询服务器上对应的页面,并将找到的页面代码回复给客户端
4.客户端接收到页面源代码后,检查页面代码中引用的其他资源,并再次向服务器请求该资源
5.在资源接收完成后,客户端浏览器按照页面代码将页面渲染输出显示在显示器上
7.cookie和session的区别?
1.cookie 数据存放在客户的浏览器上,session 数据放在服务器上
2.cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗考虑到安全应当使用session
3.session 会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能考虑到减轻服务器性能方面,应当使用 cookie
4.单个 cookie 保存的数据不能超过 4K,很多浏览器都限制一个站点最多保存 20 个 cookie
5.将登陆信息等重要信息存放为 SESSION 其他信息如果需要保留,可以放在 cookie 中
8.说说 HTTP 和 HTTPS 区别?
HTTP 协议传输的数据都是未加密的,也就是明文的,因此使用 HTTP 协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了 SSL(Secure Sockets Layer)协议用于对 HTTP 协议传输的数据进行加密,从而就诞生了 HTTPS。简单来说,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 http 协议安全。
主要区别:
1.https 协议需要到 ca 申请证书,一般免费证书较少,因而需要一定费用。
2.http 是超文本传输协议,信息是明文传输,https 则是具有安全性的 ssl 加密传输协议。
3.http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
4.http 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全。
代码优化
1.优化算法时间复杂度
2.减少冗余数据
3.合理使用深浅拷贝
4.使用dict和set查找元素
5.合理使用生成器和yield
6.循环的优化
7.优化多个判断表达式的顺序
8.使用join合并迭代器中的字符串
9.使用合适的格式化字符串方式
10.不借用中间变量交换连个两个变量的值
数据库相关
数据库优化方案:
1、创建数据表时把固定长度的放在前面()
2、将固定数据放入内存: 例如:choice字段 (django中有用到,数字1、2、3…… 对应相应内容)
3、char 和 varchar 的区别(char可变, varchar不可变 )
4、联合索引遵循最左前缀(从最左侧开始检索)
5、避免使用 select *
6、读写分离 - 实现:两台服务器同步数据
- 利用数据库的主从分离:主,用于删除、修改、更新;从,用于查; 读写分离:利用数据库的主从进行分离:主,用于删除、修改更新;从,用于查
7、分库 - 当数据库中的表太多,将某些表分到不同的数据库,例如:1W张表时
- 代价:连表查询
8、分表
- 水平分表:将某些列拆分到另外一张表,例如:博客+博客详情
- 垂直分表:讲些历史信息分到另外一张表中,例如:支付宝账单
9、加缓存
- 利用redis、memcache (常用数据放到缓存里,提高取数据速度)
如果只想获取一条数据:
- select * from tb where name=‘alex’ limit 1
