
从高斯过程到贝叶斯优化
第一篇博客,浅谈自己对高斯过程和贝叶斯优化的理解,有误处欢迎指正。
一. 高斯过程回归
1. 高斯过程到底是个什么东西?!
简单来说,高斯过程可以看成是一个函数,函数的输入是x,函数的输出是高斯分布的均值和方差。
对于一些X值有对应的Y值,从X到Y存在映射关系f,即f(X)=Y,这里我们假设所有的Y是服从正态分布的!而高斯过程可以拟合出这个函数f的分布。
下图1中的两个黑点是我们已知的二维平面上的(x,y)对,我们需要通过这些点去拟合、评估、估计、猜测X与Y间真实的映射关系,通过不同的构造方法我们可以得到无数种不同的可能性。前文提到Y服从正太分布,可以这样理解:在X取某一值的时候,根据拟合的函数不同可以得到不同的Y值,但是这些不同的Y是服从正太分布的,亦如图2所示。所以高斯过程得到的是Y的分布,而非具体的Y值,Y的方差觉得了图2中阴影的宽度(y轴方向)。随着已知(x,y)对的增加,阴影面积会减小,即方差变小,函数f结构会越来越确定。
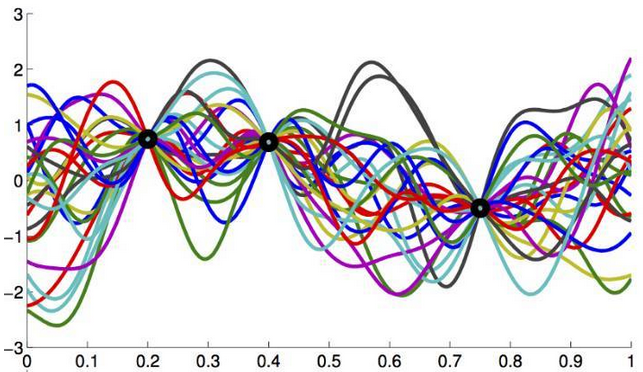
图1
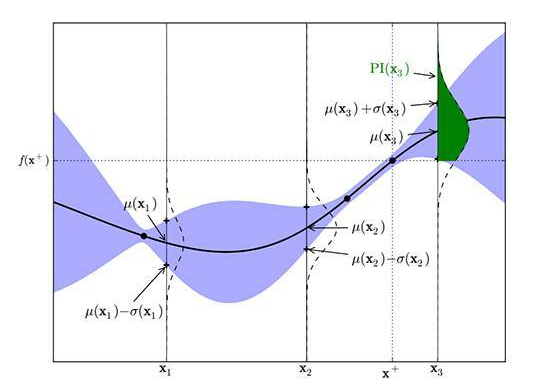
图2
2. 联合正太分布
高斯过程通过假设Y值服从联合正态分布,来考虑yn和yn+1之间的关系,因此需要给定参数包括:均值向量和协方差矩阵,即:
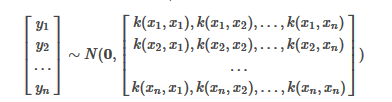
其中协方差矩阵又叫做 核矩阵, 记为K,仅和特征x有关,和y无关。
高斯过程的思想是: 假设Y服从高维正态分布(先验),而根据训练集可以得到最优的核矩阵 ,从而得到后验以估计测试集Y*,我们有后验:
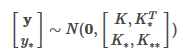
其中:
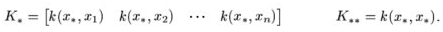
有了联合分布接下来就可以比较容易的求出预测数据y*的条件分布p(y*|y)了,经过推导其条件分布也服务高斯分布,如下:
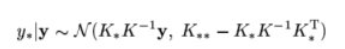
对y*估计,则可使用均值作为其估计值,即
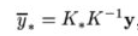
3. 为什么要使用核函数
上文提到假设Y值服从联合正态分布,需要给定参数包括:均值向量和协方差矩阵,这里我们先回顾一下什么是协方差矩阵,以及为什么可以用核矩阵代替协方差矩阵。
首先协方差矩阵的相关定义如下:

补充:相关系数和协方差的关系。

引入核函数的目的是为了拟合的函数更加光滑,在计算协方差时,我们先0均值化,可发现其就是两个向量内积的形式,由此我们可以联想到支持向量机中对核函数的使用,
核函数在低维计算的结果可以完全等价于两个变量高维映射后的内积,如图4,在低位拟合得到的曲线是不光滑的,若增加维数肯定可以使拟合曲线更加光滑。这个过程可以拆分为X1和X2求内积,转化到先将X1和X2映射到高维后再求内积,而核函数的使用可以直接取代这个过程,且可以映射到无限高的维度上。
图4
二. 贝叶斯优化
贝叶斯优化用于机器学习调参由J. Snoek(2012)提出,主要思想是,给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(高斯过程,直到后验分布基本贴合于真实分布。简单的说,就是考虑了上一次参数的信息**,从而更好的调整当前的参数。
他与常规的网格搜索或者随机搜索的区别是:
- 贝叶斯调参采用高斯过程,考虑之前的参数信息,不断地更新先验;网格搜索未考虑之前的参数信息
- 贝叶斯调参迭代次数少,速度快;网格搜索速度慢,参数多时易导致维度爆炸
- 贝叶斯调参针对非凸问题依然稳健;网格搜索针对非凸问题易得到局部优最
贝叶斯优化是基于数据使用贝叶斯定理估计目标函数的后验分布,然后再根据分布选择下一个采样的超参数组合。它充分利用了前一个采样点的信息,其优化的工作方式是通过对目标函数形状的学习,并找到使结果向全局最大提升的参数
高斯过程 用于在贝叶斯优化中对目标函数建模,得到其后验分布
通过高斯过程建模之后,我们尝试抽样进行样本计算,而贝叶斯优化很容易在局部最优解上不断采样,这就涉及到了开发和探索之间的权衡。
- 开发 (exploitation): 根据后验分布,在最可能出现全局最优解的区域进行采样, 开发高意味着均值高
- 探索 (exploration): 在还未取样的区域获取采样点, 探索高意味着方差高
而如何高效的采样,即开发和探索,我们需要用到 Acquisition Function, 它是用来寻找下一个 x 的函数。
探测(exploration)就是在还未取样的区域获取采样点。开发(exploitation)就是根据后验分布,在最可能出现全局最优解的区域进行采样。我们下一个选取点(x)应该有比较大的均值(开发)和比较高的方差(探索)。
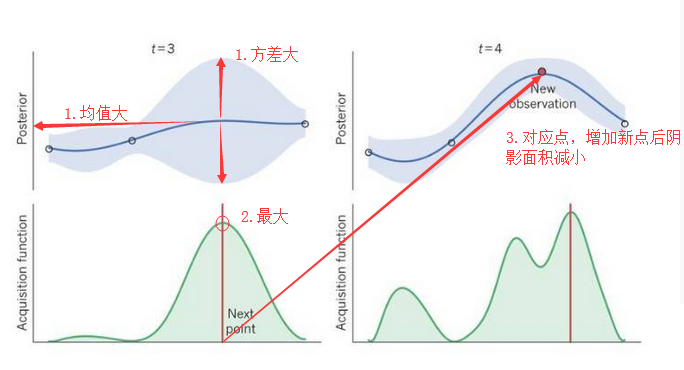
图5
使用不同的采集函数对比如下:
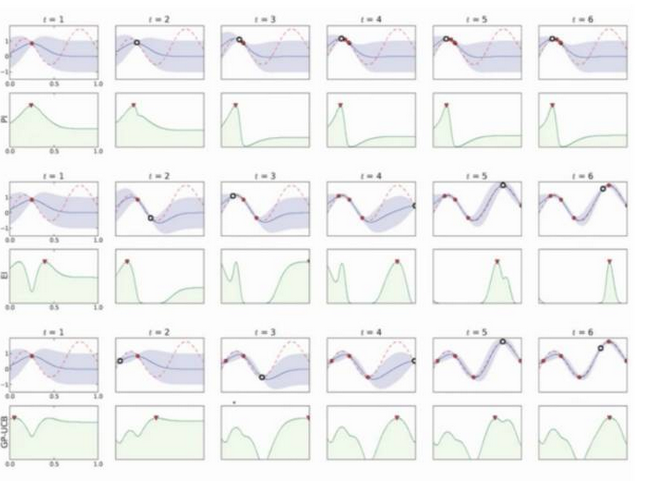
图6
贝叶斯优化过程
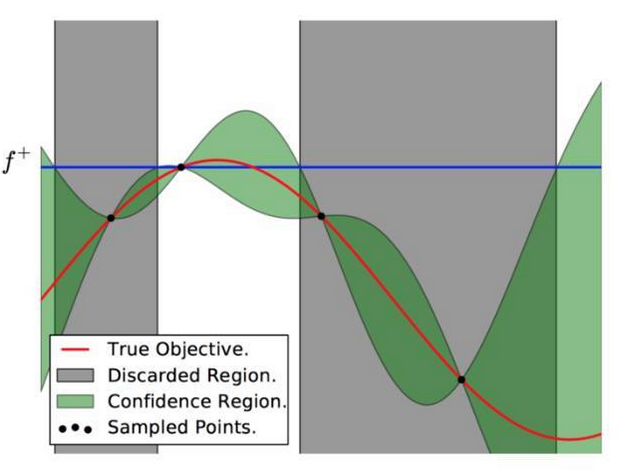
图7
上图可以直观地解释贝叶斯优化。其中红色的曲线为实际的目标函数,并且我们并不知道该函数确切的表达式。所以我们希望使用高斯过程逼近该目标函数。通过采样点(上图有 4 个抽样点),我们能够得出直观或置信曲线以拟合观察到的样本点。所以上图绿色的区域为置信域,即目标曲线最有可能处于的区域。从上面的先验知识中,我们确定了第二个点(f+)为最大的样本观察值,所以下一个最大点应该要比它大或至少与之相等。因此,我们绘制出一条蓝线,并且下一个最大点应该位于这一条蓝线之上。因此,下一个采样在交叉点 f+和置信域之间,我们能假定在 f+点以下的样本是可以丢弃的,因为我们只需要搜索令目标函数取极大值的参数。所以现在我们就缩小了观察区域,我们会迭代这一过程,直到搜索到最优解。
动态化过程:
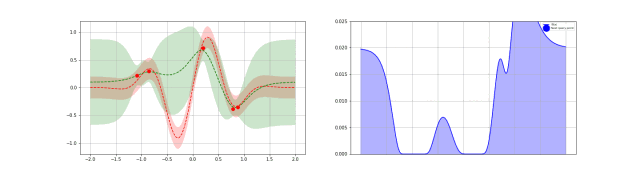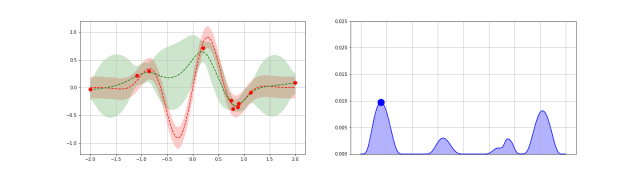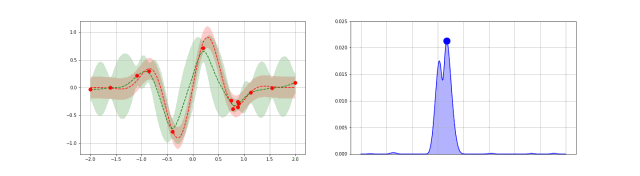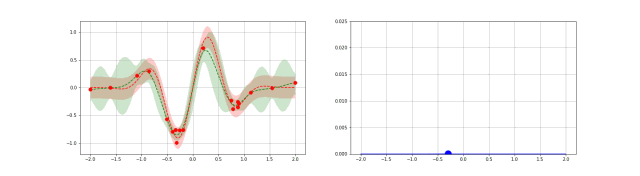
代码示例:
1 from sklearn.datasets import make_classification 2 from sklearn.ensemble import RandomForestClassifier 3 from sklearn.cross_validation import cross_val_score 4 from bayes_opt import BayesianOptimization 5 6 # 产生随机分类数据集,10个特征, 2个类别 7 x, y = make_classification(n_samples=1000,n_features=10,n_classes=2)
我们先看看不调参的结果:
1 rf = RandomForestClassifier() 2 print(np.mean(cross_val_score(rf, x, y, cv=20, scoring='roc_auc'))) 3 4 >>> 0.965162
可以看到,不调参的话模型20此交叉验证AUC均值是0.965162,算是一个不错的模型,那么如果用bayes调参结果会怎么样呢
我们先定义一个目标函数,里面放入我们希望优化的函数。比如此时,函数输入为随机森林的所有参数,输出为模型交叉验证5次的AUC均值,作为我们的目标函数。因为bayes_opt库只支持最大值,所以最后的输出如果是越小越好,那么需要在前面加上负号,以转为最大值。由于bayes优化只能优化连续超参数,因此要加上int()转为离散超参数。
1 def rf_cv(n_estimators, min_samples_split, max_features, max_depth): 2 val = cross_val_score( 3 RandomForestClassifier(n_estimators=int(n_estimators), 4 min_samples_split=int(min_samples_split), 5 max_features=min(max_features, 0.999), # float 6 max_depth=int(max_depth), 7 random_state=2 8 ), 9 x, y, scoring='roc_auc', cv=5 10 ).mean() 11 return val
然后我们就可以实例化一个bayes优化对象了:
1 rf_bo = BayesianOptimization( 2 rf_cv, 3 {'n_estimators': (10, 250), 4 'min_samples_split': (2, 25), 5 'max_features': (0.1, 0.999), 6 'max_depth': (5, 15)} 7 )
里面的第一个参数是我们的优化目标函数,第二个参数是我们所需要输入的超参数名称,以及其范围。超参数名称必须和目标函数的输入名称一一对应。
完成上面两步之后,我们就可以运行bayes优化了!
1 rf_bo.maximize()
完成的时候会不断地输出结果,如下图所示:
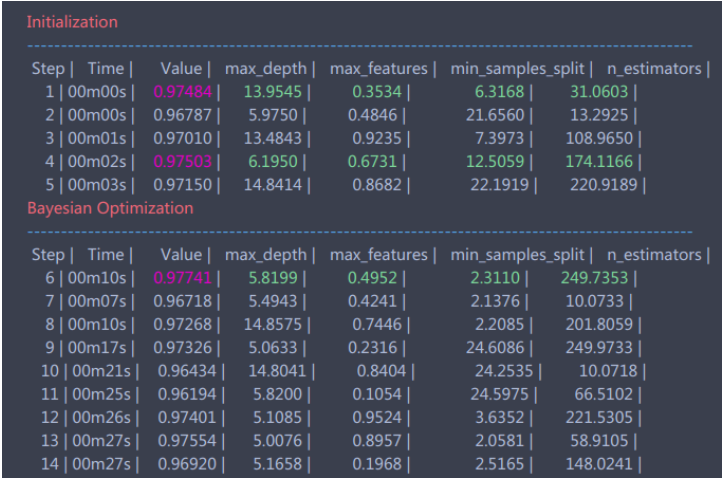
等到程序结束,我们可以查看当前最优的参数和结果:
1 rf_bo.res['max'] 2 3 >>> {'max_params': {'max_depth': 5.819908283575526, 4 'max_features': 0.4951745603509127, 5 'min_samples_split': 2.3110014720414958, 6 'n_estimators': 249.73529231990733}, 7 'max_val': 0.9774079407940794}
上面bayes算法得到的参数并不一定最优,当然我们会遇到一种情况,就是我们已经知道有一组或是几组参数是非常好的了,我们想知道其附近有没有更好的。这个操作相当于上文bayes优化中的Explore操作,而bayes_opt库给了我们实现此方法的函数:
1 rf_bo.explore( 2 {'n_estimators': [10, 100, 200], 3 'min_samples_split': [2, 10, 20], 4 'max_features': [0.1, 0.5, 0.9], 5 'max_depth': [5, 10, 15] 6 } 7 )
这里我们添加了三组较优的超参数,让其在该参数基础上进行explore,可能会得到更好的结果。
同时,我们还可以修改高斯过程的参数,高斯过程主要参数是核函数(kernel),还有其他参数可以参考sklearn.gaussianprocess
1 gp_param={'kernel':None} 2 rf_bo.maximize(**gp_param)
最终我们的到参数如下:
1 {'max_params': {'max_depth': 5.819908283575526, 2 'max_features': 0.4951745603509127, 3 'min_samples_split': 2.3110014720414958, 4 'n_estimators': 249.73529231990733}, 5 'max_val': 0.9774079407940794}
运行交叉验证测试一下:
1 rf = RandomForestClassifier(max_depth=6, max_features=0.39517, min_samples_split=2, n_estimators=250) 2 np.mean(cross_val_score(rf, x, y, cv=20, scoring='roc_auc')) 3 >>> 0.9754953
得到最终结果是0.9755,比之前的0.9652提高了约0.01。
Reference
1. https://www.cnblogs.com/yangruiGB2312/p/9374377.html
2. http://www.sohu.com/a/165565029_465975
3. https://zhuanlan.zhihu.com/p/32152162
4. https://baijiahao.baidu.com/s?id=1593374440671439305&wfr=spider&for=pc
