pandas常用函数详解——drop()函数
drop函数基本介绍:
功能:删除数据集中多余的数据
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
常用参数详解:
labels:待删除的行名or列名;
axis:删除时所参考的轴,0为行,1为列;
index:待删除的行名
columns:待删除的列名
level:多级列表时使用,暂时不作说明
inplace:布尔值,默认为False,这是返回的是一个copy;若为True,返回的是删除相应数据后的版本
errors一般用不到,这里不作解释
举例说明:
#构件一个数据集 df1=pd.DataFrame(np.arange(36).reshape(6,6),columns=list('ABCDEF'))

'1.删除行数据' #下面两种删除方式是等价的,传入labels和axis 与只传入一个index 作用相同 df2=df1.drop(labels=0,axis=0) df22=df1.drop(index=0)
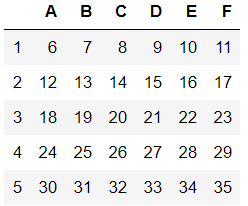
#删除多行数据 df3=df1.drop(labels=[0,1,2],axis=0) df33=df1.drop(index=[0,1,2])
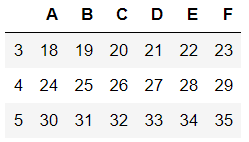
'2.删除列数据' df4=df1.drop(labels=['A','B','C'],axis=1) df44=df1.drop(columns=['A','B','C'])
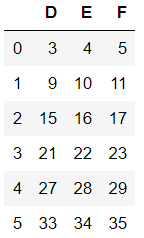
'3.inplace参数的使用' dfs=df1 #inplace=None时返回删除前的数据 dfs.drop(labels=['A','B','C'],axis=1)
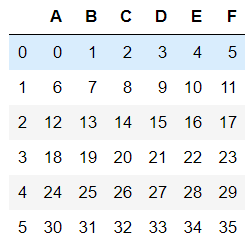
#inplace=True时返回删除后的数据 dfs.drop(labels=['A','B','C'],axis=1,inplace=True)
'4.drop函数在多级列表中的应用(实例copy自pandas官方帮助文档)‘ #构建多级索引 midx = pd.MultiIndex(levels=[['lama', 'cow', 'falcon'], ['speed', 'weight', 'length']], codes=[[0, 0, 0, 1, 1, 1, 2, 2, 2], [0, 1, 2, 0, 1, 2, 0, 1, 2]]) #构造数据集 df = pd.DataFrame(index=midx, columns=['big', 'small'], data=[[45, 30], [200, 100], [1.5, 1], [30, 20], [250, 150], [1.5, 0.8], [320, 250], [1, 0.8], [0.3, 0.2]])

#同时删除行数据和列数据 df.drop(index='cow', columns='small')

#删除某级index的对应行 df.drop(index='length',level=1)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号