


TNAS、超级网络、权重共享、MOEA
一.模型介绍
文章提出一种自动transformer NAS系统(automatic transformer NAS),命名为TNAS。所提出的基于TNAS的情绪识别是一个端到端系统,它可以从原始EEG信号中捕捉全局交互,以用于情绪分类任务。
TNAS首先构建一个覆盖设计空间中所有候选对象的超级网络(super network),并对其进行训练,使其在训练集上收敛,(在训练过程中,模型通过不断调整其参数来最小化损失函数。收敛意味着这些调整最终导致损失函数达到一个最小值或足够小的值。)然后通过多目标进化算法(MOEA)进行搜索,得到用于基于脑电图的情感识别的最优网络架构。
TNAS流程如下:
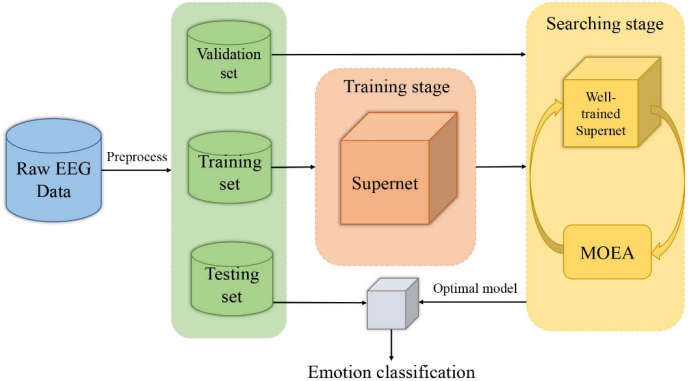
首先对EEG数据进行预处理,将其分为训练、验证和测试三部分,然后在训练集上训练构建的超级网络,使其收敛。应用MOEA从训练有素的超级网络中搜索最优架构,期望在出色的性能和有限的资源消耗(模型大小)之间取得平衡。最后,在测试数据上对最优架构进行评估,并将平均分类准确率作为系统的最终性能。
1.1 Raw EEG Data(原始EEG数据)
脑电信号是多通道时间序列信号,本文采用的是二维脑电数据。(多通道时间序列信号:多通道脑电图设备可以同时从多个位置(电极)记录脑电活动,每个电极都是一个通道,多通道意味着可以同时获取大脑不同区域的电活动信息。不同脑区在不同的生理和心理状态下可能表现出不同的电活动模式,通过多通道记录能够更全面地反映大脑的整体状态。脑电信号是随时间变化的信号,它们记录了大脑在连续时间点上的电活动,因此是时间序列信号。)这是从脑电图设备收集的原始数据,通常包含大量的噪声和不相关的信息。
1.2 Preprocess(预处理)
在这个阶段,原始EEG数据会经过清洗和转换,以便于后续处理。
1.3 Training set, Validation set, Testing set(训练集、验证集、测试集)
预处理后的数据被分为三部分:训练集用于模型学习,验证集用于在训练过程中调整超参数和避免过拟合,测试集用于评估模型的最终性能。
1.4 搜索阶段(包括Training stage(训练阶段)和Searching stage(搜索阶段))
为了搜索最佳子网α∗,我们创建了一个巨大的搜索空间,其中包含各种具有不同模型复杂性的ViT结构。此外,搜索空间中的结构涵盖了关键超参数组合。我们在每一层使用不同结构的构建块,将搜索空间S编码为超级网络N(S,W),其中W为超级网络的权值,在所有候选子网α∈S中共享。
因此,超级网络就是在神经架构搜索(NAS)过程中构建的一个包含所有候选网络结构的大型网络,包含了搜索空间中所有可能的子网络结构。
超级网络的构建基于ViT(vision transformer)架构。
1.4.1 关键概念介绍
训练和搜索阶段的两个关键概念——权重共享机制和MOEA策略。
本文提出的基于 MOEA 的 TNAS 主要解决了 ViT 结构优化的两个难题:
1)如何有效地组合模型的关键超参数,例如嵌入维度、MLP比率(MLP中隐藏维度与嵌入维度的比率)、MSA中的头数量和模型深度。
2)如何高效地搜索适合不同资源受限应用场景的各种ViT架构(端到端系统无法支持大型模型)。
从权重共享机制和MOEA策略两个方面详细阐述所提出方法的原理
权重共享机制
配置权重共享的TNAS可以快速、低资源消耗地搜索ViT结构。ViT中的模块具有同质性,如多头自注意力(MSA)模块和多层感知器(MLP)模块,它们虽然在某些参数(如MSA的头数、MLP的隐藏层维度)上有所不同,但它们的结构相似。这种相似性使得在构建超级网络时,可以使同构构件在结构上兼容,从而实现相互权重共享。
提出的TNAS首先构建一个覆盖设计空间中所有候选对象(子网)的超级网络,并对其进行训练,使其在训练集上收敛。超级网络堆叠了最大数量的编码器块,这些编码器块包含了各种可能的关键超参数组合(如不同的嵌入维度、MSA头数、MLP比例和模型深度等),形成了搜索空间中的所有候选子网结构。
搜索到的最优子网直接继承来自训练良好的超级网络的权重,可以获得比比较方法更好的性能。权重共享的核心是使不同的块在同一层上共享公共部分的权重。假设搜索空间中有一个l层的子网络,其结构及其权重可以表示如下:
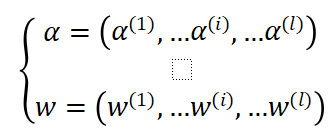
其中α(i)和w(i)分别表示第i层中选定的块及其权重。每层中有多个块可供选择,α(i)和w(i)从搜索空间中的n个候选块集合中抽取,如下所示
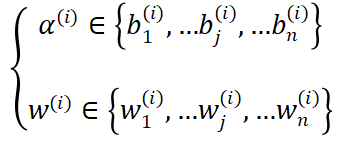
其中, 是搜索空间中的候选块及其相应权重。由于这些候选块结构相似,在训练过程中发现,对于同一层的不同候选块,较小块的权重所包含的信息是最大块权重信息的子集。【这意味着最大块权重涵盖了较小块权重所包含的所有关键信息,且可能包含更多额外信息。例如在处理EEG信号特征时,较小块可能学习到了部分基础特征的权重表示,而最大块在此基础上学习到了更全面、更复杂的特征关系权重。此时较小块直接使用最大块权重,可获取完整的特征表达,避免重复学习已包含在最大块中的信息。这类似于在一个知识体系中,较小块掌握了部分基础知识(权重),而最大块不仅包含这些基础知识,还拥有更深入、更广泛的知识内容(更多权重信息),较小块当然可以直接采用最大块的权重】。
是搜索空间中的候选块及其相应权重。由于这些候选块结构相似,在训练过程中发现,对于同一层的不同候选块,较小块的权重所包含的信息是最大块权重信息的子集。【这意味着最大块权重涵盖了较小块权重所包含的所有关键信息,且可能包含更多额外信息。例如在处理EEG信号特征时,较小块可能学习到了部分基础特征的权重表示,而最大块在此基础上学习到了更全面、更复杂的特征关系权重。此时较小块直接使用最大块权重,可获取完整的特征表达,避免重复学习已包含在最大块中的信息。这类似于在一个知识体系中,较小块掌握了部分基础知识(权重),而最大块不仅包含这些基础知识,还拥有更深入、更广泛的知识内容(更多权重信息),较小块当然可以直接采用最大块的权重】。
因此,较小的块可以直接利用最大块的权重,而无需单独训练自己的权重。我们只需要每层n个候选块中最大块的权重。超级网络由每层中最大的块组成。因此,子网可以继承训练有素的超级网络的权重。
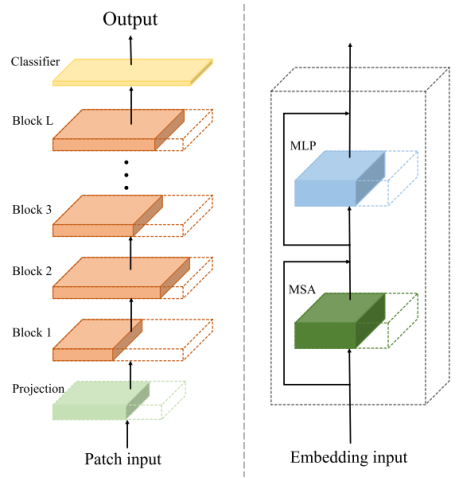
【(左图)采用权重共享策略构建超级网络。
超级网络的基础是ViT:包括Patch Input:将输入数据(如图像或文本)分割成块,并平铺;Projection:将这些patches通过一个线性层(即投影层)将每个patch映射到一个固定维度的向量空间,以便它们可以被Transformer模型处理;Block 1 to Block L:堆叠的编码块,MSA这一部分允许模型在序列的不同位置之间建立联系,捕捉全局依赖关系,MLP是一个前馈神经网络,用于进一步处理经过自注意力层的数据,穿插的残差连接层有助于缓解深层网络中的梯度消失问题;Classifier:在最后一个编码块之后的分类器层,用于将Transformer的输出转换为最终的预测结果。在图像分类任务中,这是一个全连接层,用于将特征向量映射到类别概率;Output:这是模型的最终输出,可以是类别标签、连续值或其他类型的预测,取决于任务的具体需求。
超级网络由L个编码器块组成,子网继承超级网络实心部分的权重。虚线中的块表示超级网络的权重,但目前不继承(子网的层数可能少于L,因此子网可以灵活地继承任何一层的权重)。
(右图)左图的局部放大——编码器块中MLP和MSA的权重共享。
我们为子网中的每一层寻找具有最佳嵌入维度、头数和MLP比率的最佳块。此外,我们还搜索了最佳深度。】
在实际操作中,通过这种权重共享机制,超级网络在训练时只需关注最大块的权重训练,其他较小块可以直接继承最大块的权重。这样避免了对每个子网重复训练所有层的权重,这样做不仅减少了训练过程中的计算资源消耗,还加快了搜索最优子网结构的速度。
最终,搜索到的最优子网能够直接继承超级网络中训练好的权重,基于这些共享权重进行微调或直接使用,从而在基于EEG的情绪识别任务中取得较好的性能表现。
MOEA
在搜索阶段,使用多目标进化算法(MOEA)来寻找最佳的网络架构或超参数配置。这个过程涉及到在预定义的搜索空间内进行优化,以找到在多个目标——准确率、模型大小上表现最好的模型。
MOEA的基本流程如下:
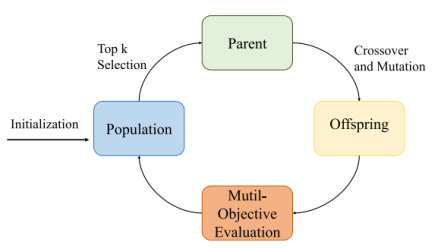
①Initialization Population(初始化种群)
随机抽取一定数量的子网作为原始种群。
②Top k Selection(父代选择)
计算每个子网的得分:
我们利用帕累托理论来解决多目标优化问题。帕累托前沿意味着一组最优解决方案,它代表了标准之间的权衡,并允许与决策变量建立联系。因此,我们采用加权和的方法,对每个目标函数分配不同的权重得分,如下所示:

其中,val表示子网α在验证数据集上的准确率
取得分前K个子网作为下一代的父代(Parent)。
③Crossover and Mutation(交叉和变异)
交叉是通过随机选择两个前K个候选子网进行交叉,生成新的子网。对于突变,被选中的候选者会突变其深度和区块,从而生成新的子网。然后得到Offspring(子代)。
④ Multi-Objective Evaluation(多目标评估)
对子代进行多目标评估,以确定其适应度,为下一轮的选择做准备。这个循环不断重复,逐步找到更优的解。
最后,我们选择得分最高的候选者作为最优模型。
1.4.2 搜索最优模型α∗分两个阶段——训练超级网络和使用MOEA搜索
第一阶段,训练共享权重的超级网络:
优化超级网络的权重W如下:

其中L表示训练过程中的损失函数。我们采用随机抽样的方式,从超级网络N(S,W)中选择子网α,以较少的资源代价训练参数W。

在余弦学习率调度器中使用交叉熵损失和Adam优化来训练超级网络的W。
第二阶段:使用MOEA搜索
通过(MOEA)在训练良好的超网上搜索最优子网α:
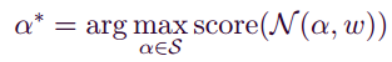
其中子网α由MOEA采样,MOEA从训练良好的WA中继承权重w。计算权重得分验证采样子网α的准确度和模型大小。

1.5 Testing stage(测试阶段)
经过MOEA优化后的超网络,被认为是训练良好的模型(Well-trained Supernet),最优选的模型用于在测试集上进行情感分类,这是模型的最终评估阶段。
1.6 Emotion classification(情感分类)
最终目标是使用训练好的模型对EEG数据进行情感状态的分类。
二.创新点
- 提出基于多目标进化算法的自动 Transformer 架构搜索框架(TNAS)。
传统的 Transformer 架构大多由人工专家手动设计,过程耗时且资源密集。本文提出的 TNAS 框架基于多目标进化算法(MOEA),能够自动搜索最优的 Transformer 架构,减少了人工设计的成本和工作量,提高了效率。
在搜索过程中,TNAS 不仅考虑模型的准确性,还兼顾模型大小。通过 MOEA 策略,在训练好的超网络中寻找最优模型,使得模型在保证高性能的同时,能够满足资源受限场景的需求,避免了过拟合和资源浪费。
- 将 Vision Transformer(ViT)架构应用于基于 EEG 的情绪识别任务。
ViT 架构最初应用于自然语言处理(NLP)任务,本文将其引入到 EEG 信号处理领域。考虑到 EEG 数据是多通道时间序列信号(二维数据),对 ViT 进行了适应性调整在数据输入阶段,将 EEG 数据分割成一系列二维块,并进行线性投影、添加位置嵌入等操作,将其转换为适合 Transformer 处理的格式。
- 采用权重共享机制优化超网络训练和模型搜索过程 高效训练超网络。
在 TNAS 框架中,提出了一种特殊的权重共享机制。通过构建包含所有候选子网的超网络,利用同质模块的结构兼容性,实现了权重共享。这使得在训练超网络时,只需优化最大模块的权重,较小模块可直接继承,大大减少了训练所需的计算资源和时间。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具