3、jvm内存溢出排查
一般来说内存溢出主要分为以下几类:
堆溢出(java.lang.OutOfMemoryError: Java heap space)
栈深度不够( java.lang.StackOverflowError)
栈线程数不够(java.lang.OutOfMemoryError: unable to create new native thread)
元空间溢出(java.lang.OutOfMemoryError: Metaspace)
元空间溢出(java.lang.OutOfMemoryError: Metaspace)
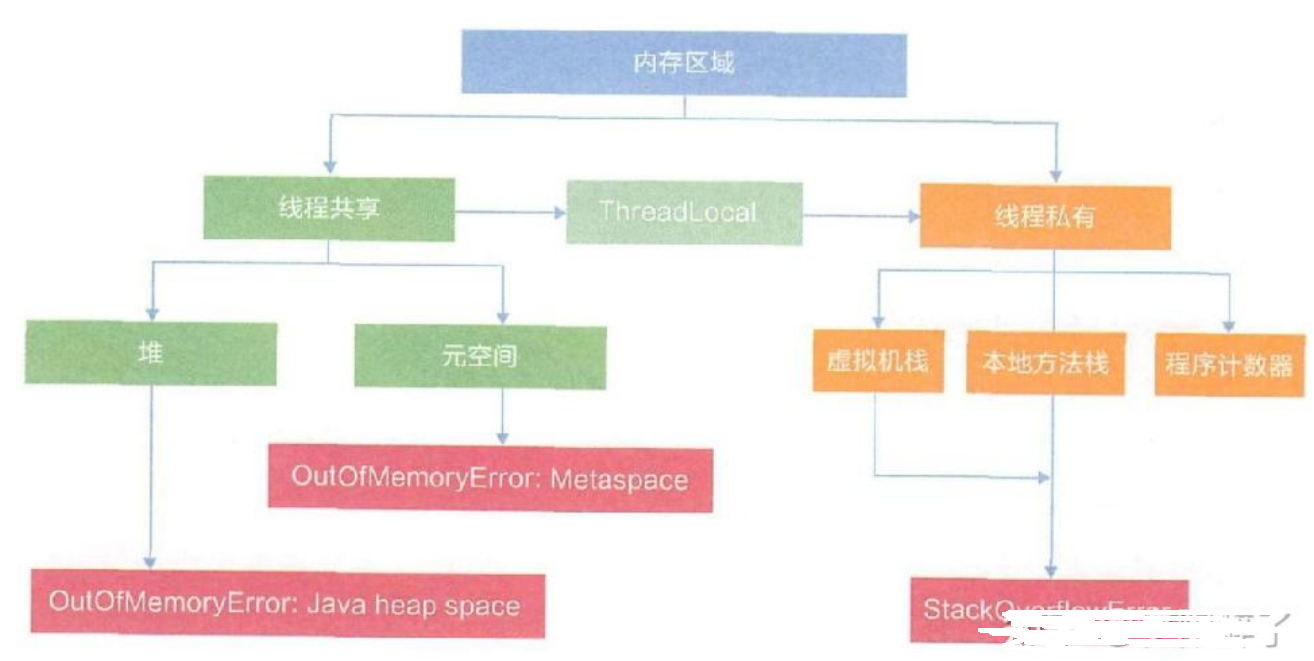
Metaspace元空间主要是存储类的元数据信息,各种类描述信息,比如类名、属性、方法、访问限制等,按照一定的结构存储在Metaspace里。 一般来说,元空间大小是固定不变的。在出现溢出后,首先通过命令或监控工具(如下图)查看元空间大小,再检查是否-XX:MaxMetaspaceSize配置太小导致。

如果发现元空间大小是持续上涨的,则需要检查代码是否存在大量的反射类加载、动态代理生成的类加载等导致。可以通过-XX:+TraceClassLoading -XX:+TraceClassUnloading记录下类的加载和卸载情况,反推具体问题代码。
2、栈深度不够(java.lang.StackOverflowError)
引发StackOverFlowError的常见原因有:
- • 无限循环递归调用
- • 同一时间执行大量方法,资源耗尽
- • 方法中声明大量局部变量
- • 其它消耗栈资源的方法
- • xss配置太小导致
/**
* VM Args: -Xss128k
*/
public class JavaStackSOF {
private int stackLength = 1;
public void stackLeak() {
stackLength++;
stackLeak();
}
public static void main(String[] args) {
JavaStackSOF oom = new JavaStackSOF();
try{
oom.stackLeak();
}catch(Throwable e) {
System.out.println("stack length:" + oom.stackLength);
throw e;
}
}
}
stack length:2101
Exception in thread "main" java.lang.StackOverflowError
at com.sandy.jvm.chapter02.JavaStackSOF.stackLeak(JavaStackSOF.java:13)
at com.sandy.jvm.chapter02.JavaStackSOF.stackLeak(JavaStackSOF.java:14)
at com.sandy.jvm.chapter02.JavaStackSOF.stackLeak(JavaStackSOF.java:14)3、栈线程数不够(java.lang.OutOfMemoryError: unable to create new native thread)
这类错误目前在生成系统只遇到过一次,
原因是:linux系统中非root用户默认创建线程数最多是1024。
解决办法是修改文件:/etc/security/limits.d/90-nproc.conf
还有一种情况是-xss配置太大,那么操作系统可创建的最大线程数太小导致,一般除非误操作是不会出现此问题的。
4、堆溢出(java.lang.OutOfMemoryError: Java heap space)
堆溢出是常见也是最复杂的一种情况。导致堆溢出可能的情况有:
- • 堆内存配置太小
- • 超出预期的访问量:访问量飙升
- • 超出预期的数据量:系统中是否存在一次性提取大量数据到内存的代码
- • 内存泄漏
解决思路一般是:
一、堆dump文件获取
1、通过参数配置自动获取dump文件(推荐)
2、jmap -dump:format=b,file=filename.hprof pid
二、MAT工具分析
1、分析大对象、堆中存储信息、可能存在的内存泄漏地方,便于定位问题位置
五、JVM监控
常用的监控工具或命令有:jstack、jstat、jConsole、jvisualvm。监控指标主要是各内存区域大小是否合理、fullGC频率及耗时、youngGC耗时、线程数等。
1、jstack
jstack主要用于打印线程堆栈信息,帮助问题的定位。一般配合top -Hp PID使用。
通过top命令发现某个java服务占用1234%的CPU,如图:

通过top -Hp PID命令可以看到占用CPU比较高的线程,如图:

再次通过jstack PID>log.txt,输出堆栈信息即可进行排查定位。
2、jstat
jstat命令是分析JVM运行状况的常用命令。
jstat -options -class 用于查看类加载情况的统计
-compiler 用于查看HotSpot中即时编译器编译情况的统计
-gc 用于查看JVM中堆的垃圾收集情况的统计
-gccapacity 用于查看新生代、老生代及持久代的存储容量情况
-gcmetacapacity 显示metaspace的大小
-gcnew 用于查看新生代垃圾收集的情况
-gcnewcapacity 用于查看新生代存储容量的情况
-gcold 用于查看老生代及持久代垃圾收集的情况
-gcoldcapacity 用于查看老生代的容量
-gcutil 显示垃圾收集信息
-gccause 显示垃圾回收的相关信息(通-gcutil),同时显示最后一次仅当前正在发生的垃圾收集的原因
-printcompilation 输出JIT编译的方法信息
以jstat -gcutil为例:
[root@hadoop ~]# jstat -gcutil 3346 #显示垃圾收集信息
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
52.97 0.00 42.10 13.92 97.39 98.02 8 0.020 0 0.000 0.020 - • S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
- • S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
- • E:年轻代中Eden(伊甸园)已使用的占当前容量百分比
- • O:old代已使用的占当前容量百分比
- • M:元数据区已使用的占当前容量百分比
- • CCS:压缩类空间已使用的占当前容量百分比
- • YGC :从应用程序启动到采样时年轻代中gc次数
- • YGCT :从应用程序启动到采样时年轻代中gc所用时间(s)
- • FGC :从应用程序启动到采样时old代(全gc)gc次数
- • FGCT :从应用程序启动到采样时old代(全gc)gc所用时间(s)
- • GCT:从应用程序启动到采样时gc用的总时间(s)
3、jConsole
JConsole是基于JMX的可视化监视、管理工具。可以很方便的监视本地及远程服务器的java进程的内存使用情况。
3.1 被监控的程序运行时给虚拟机添加一些运行的参数
无需认证的远程监控配置 -Dcom.sun.management.jmxremote.port=60001 //监控的端口号 -Dcom.sun.management.jmxremote.authenticate=false //关闭认证 -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=192.168.1.2
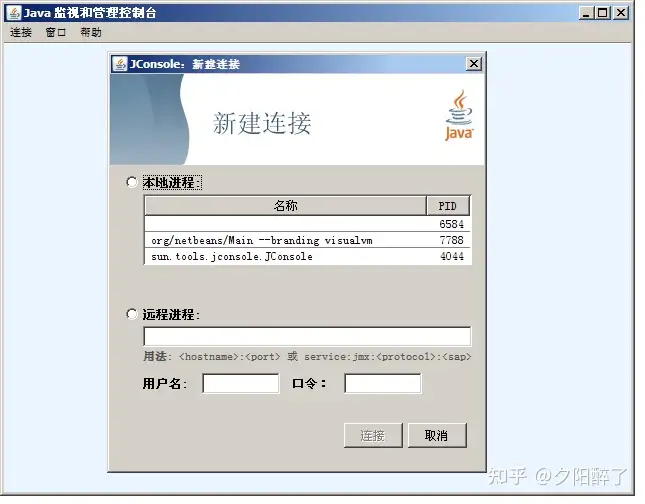
3.2 客户端连接被监控程序
找到 JDK 安装路径,打开bin文件夹,双击jconsole.exe,在已经打开的JConsole界面操作“连接->新建连接->选择远程进程->输入远程主机IP和端口号->点击“连接
4、jvisualvm
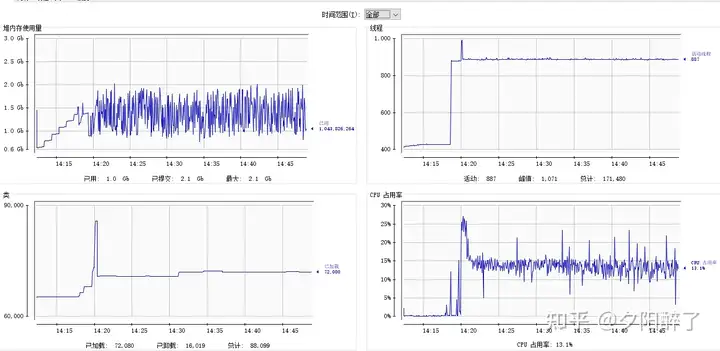
jvisualvm与jConsole连接方式一致,连接后界面如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号