对象的构造和析构
1. 初始化和清理
我们大家在购买一台电脑或者手机,或者其他的产品,这些产品都有一个初始设置,也就是这些产品对被创建的时候会有一个基础属性值。那么随着我们使用手机和电脑的时间越来越久,那么电脑和手机会慢慢被我们手动创建很多文件数据,某一天我们不用手机或电脑了,那么我们应该将电脑或手机中我们增加的数据删除掉,保护自己的信息数据。
从这样的过程中,我们体会一下,所有的事物在起初的时候都应该有个初始状态,当这个事物完成其使命时,应该及时清除外界作用于上面的一些信息数据。
那么我们c++中OO思想也是来源于现实,是对现实事物的抽象模拟,具体来说,当我们创建对象的时候,这个对象应该有一个初始状态,当对象销毁之前应该销毁自己创建的一些数据。
对象的初始化和清理也是两个非常重要的安全问题,一个对象或者变量没有初始时,对其使用后果是未知,同样的使用完一个变量,没有及时清理,也会造成一定的安全问题。c++为了给我们提供这种问题的解决方案,构造函数和析构函数,这两个函数将会被编译器自动调用,完成对象初始化和对象清理工作。
无论你是否喜欢,对象的初始化和清理工作是编译器强制我们要做的事情,即使你不提供初始化操作和清理操作,编译器也会给你增加默认的操作,只是这个默认初始化操作不会做任何事,所以编写类就应该顺便提供初始化函数。
为什么初始化操作是自动调用而不是手动调用?既然是必须操作,那么自动调用会更好,如果靠程序员自觉,那么就会存在遗漏初始化的情况出现。
构造函数和析构函数
构造函数主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
析构函数主要用于对象销毁前系统自动调用,执行一些清理工作。
构造函数语法:
|
n 构造函数函数名和类名相同,没有返回值,不能有void,但可以有参数。 n ClassName(){} |
析构函数语法:
|
n 析构函数函数名是在类名前面加”~”组成,没有返回值,不能有void,不能有参数,不能重载。 n ~ClassName(){} |
class Person{ public: Person(){ cout << "构造函数调用!" << endl; pName = (char*)malloc(sizeof("John")); strcpy(pName, "John"); mTall = 150; mMoney = 100; } ~Person(){ cout << "析构函数调用!" << endl; if (pName != NULL){ free(pName); pName = NULL; } } public: char* pName; int mTall; int mMoney; }; void test(){ Person person; cout << person.pName << person.mTall << person.mMoney << endl; }
2.构造函数的分类及调用
按参数类型:分为无参构造函数和有参构造函数
按类型分类:普通构造函数和拷贝构造函数(复制构造函数)
class Person{ public: Person(){ cout << "no param constructor!" << endl; mAge = 0; } //有参构造函数 Person(int age){ cout << "1 param constructor!" << endl; mAge = age; } //拷贝构造函数(复制构造函数) 使用另一个对象初始化本对象 Person(const Person& person){ cout << "copy constructor!" << endl; mAge = person.mAge; } //打印年龄 void PrintPerson(){ cout << "Age:" << mAge << endl; } private: int mAge; }; //1. 无参构造调用方式 void test01(){ //调用无参构造函数 Person person1; person1.PrintPerson(); //无参构造函数错误调用方式 //Person person2(); //person2.PrintPerson(); } //2. 调用有参构造函数 void test02(){ //第一种 括号法,最常用 Person person01(100); person01.PrintPerson(); //调用拷贝构造函数 Person person02(person01); person02.PrintPerson(); //第二种 匿名对象(显示调用构造函数) Person(200); //匿名对象,没有名字的对象 Person person03 = Person(300); person03.PrintPerson(); //注意: 使用匿名对象初始化判断调用哪一个构造函数,要看匿名对象的参数类型 Person person06(Person(400)); //等价于 Person person06 = Person(400); person06.PrintPerson(); //第三种 =号法 隐式转换 Person person04 = 100; //Person person04 = Person(100) person04.PrintPerson(); //调用拷贝构造 Person person05 = person04; //Person person05 = Person(person04) person05.PrintPerson(); }
|
b为A的实例化对象,A a = A(b) 和 A(b)的区别? 当A(b) 有变量来接的时候,那么编译器认为他是一个匿名对象,当没有变量来接的时候,编译器认为你A(b) 等价于 A b. |
注意:不能调用拷贝构造函数去初始化匿名对象,也就是说以下代码不正确:
class Teacher{ public: Teacher(){ cout << "默认构造函数!" << endl; } Teacher(const Teacher& teacher){ cout << "拷贝构造函数!" << endl; } public: int mAge; }; void test(){ Teacher t1; //error C2086:“Teacher t1”: 重定义 Teacher(t1); //此时等价于 Teacher t1; }
拷贝构造函数的调用时机
对象以值传递的方式传给函数参数
函数局部对象以值传递的方式从函数返回(vs debug模式下调用一次拷贝构造,qt不调用任何构造)
用一个对象初始化另一个对象
class Person{ public: Person(){ cout << "no param contructor!" << endl; mAge = 10; } Person(int age){ cout << "param constructor!" << endl; mAge = age; } Person(const Person& person){ cout << "copy constructor!" << endl; mAge = person.mAge; } ~Person(){ cout << "destructor!" << endl; } public: int mAge; }; //1. 旧对象初始化新对象 void test01(){ Person p(10); Person p1(p); Person p2 = Person(p); Person p3 = p; // 相当于Person p2 = Person(p); } //2. 传递的参数是普通对象,函数参数也是普通对象,传递将会调用拷贝构造 void doBussiness(Person p){} void test02(){ Person p(10); doBussiness(p); } //3. 函数返回局部对象 Person MyBusiness(){ Person p(10); cout << "局部p:" << (int*)&p << endl; return p; } void test03(){ //vs release、qt下没有调用拷贝构造函数 //vs debug下调用一次拷贝构造函数 Person p = MyBusiness(); cout << "局部p:" << (int*)&p << endl; }
[Test03结果说明:]
编译器存在一种对返回值的优化技术,RVO(Return Value Optimization).在vs debug模式下并没有进行这种优化,所以函数MyBusiness中创建p对象,调用了一次构造函数,当编译器发现你要返回这个局部的对象时,编译器通过调用拷贝构造生成一个临时Person对象返回,然后调用p的析构函数。
我们从常理来分析的话,这个匿名对象和这个局部的p对象是相同的两个对象,那么如果能直接返回p对象,就会省去一个拷贝构造和一个析构函数的开销,在程序中一个对象的拷贝也是非常耗时的,如果减少这种拷贝和析构的次数,那么从另一个角度来说,也是编译器对程序执行效率上进行了优化。
所以在这里,编译器偷偷帮我们做了一层优化:
当我们这样去调用: Person p = MyBusiness();
编译器偷偷将我们的代码更改为:
void MyBussiness(Person& _result){ _result.X:X(); //调用Person默认拷贝构造函数 //.....对_result进行处理 return; } int main(){ Person p; //这里只分配空间,不初始化 MyBussiness(p); }
构造函数调用规则
默认情况下,c++编译器至少为我们写的类增加3个函数
1.默认构造函数(无参,函数体为空)
2.默认析构函数(无参,函数体为空)
3.默认拷贝构造函数,对类中非静态成员属性简单值拷贝
如果用户定义拷贝构造函数,c++不会再提供任何默认构造函数
如果用户定义了普通构造(非拷贝),c++不在提供默认无参构造,但是会提供默认拷贝构造
深拷贝和浅拷贝
浅拷贝
同一类型的对象之间可以赋值,使得两个对象的成员变量的值相同,两个对象仍然是独立的两个对象,这种情况被称为浅拷贝.
一般情况下,浅拷贝没有任何副作用,但是当类中有指针,并且指针指向动态分配的内存空间,析构函数做了动态内存释放的处理,会导致内存问题。

深拷贝
当类中有指针,并且此指针有动态分配空间,析构函数做了释放处理,往往需要自定义拷贝构造函数,自行给指针动态分配空间,深拷贝。
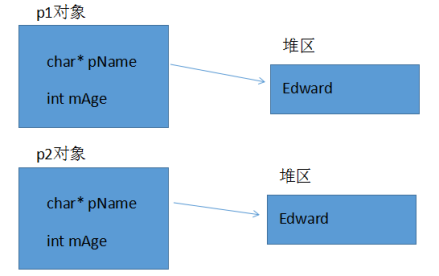
class Person{ public: Person(char* name,int age){ pName = (char*)malloc(strlen(name) + 1); strcpy(pName,name); mAge = age; } //增加拷贝构造函数 Person(const Person& person){ pName = (char*)malloc(strlen(person.pName) + 1); strcpy(pName, person.pName); mAge = person.mAge; } ~Person(){ if (pName != NULL){ free(pName); } } private: char* pName; int mAge; }; void test(){ Person p1("Edward",30); //用对象p1初始化对象p2,调用c++提供的默认拷贝构造函数 Person p2 = p1; }
初始化列表
构造函数和其他函数不同,除了有名字,参数列表,函数体之外还有初始化列表。
初始化列表简单使用:
class Person{ public: #if 0 //传统方式初始化 Person(int a,int b,int c){ mA = a; mB = b; mC = c; } #endif //初始化列表方式初始化 Person(int a, int b, int c):mA(a),mB(b),mC(c){} void PrintPerson(){ cout << "mA:" << mA << endl; cout << "mB:" << mB << endl; cout << "mC:" << mC << endl; } private: int mA; int mB; int mC; };
注意:初始化成员列表(参数列表)只能在构造函数使用。
类对象作为成员
在类中定义的数据成员一般都是基本的数据类型。但是类中的成员也可以是对象,叫做对象成员。
C++中对对象的初始化是非常重要的操作,当创建一个对象的时候,c++编译器必须确保调用了所有子对象的构造函数。如果所有的子对象有默认构造函数,编译器可以自动调用他们。但是如果子对象没有默认的构造函数,或者想指定调用某个构造函数怎么办?
那么是否可以在类的构造函数直接调用子类的属性完成初始化呢?但是如果子类的成员属性是私有的,我们是没有办法访问并完成初始化的。
解决办法非常简单:对于子类调用构造函数,c++为此提供了专门的语法,即构造函数初始化列表。
当调用构造函数时,首先按各对象成员在类定义中的顺序(和参数列表的顺序无关)依次调用它们的构造函数,对这些对象初始化,最后再调用本身的函数体。也就是说,先调用对象成员的构造函数,再调用本身的构造函数。
析构函数和构造函数调用顺序相反,先构造,后析构。
//汽车类 class Car{ public: Car(){ cout << "Car 默认构造函数!" << endl; mName = "大众汽车"; } Car(string name){ cout << "Car 带参数构造函数!" << endl; mName = name; } ~Car(){ cout << "Car 析构函数!" << endl; } public: string mName; }; //拖拉机 class Tractor{ public: Tractor(){ cout << "Tractor 默认构造函数!" << endl; mName = "爬土坡专用拖拉机"; } Tractor(string name){ cout << "Tractor 带参数构造函数!" << endl; mName = name; } ~Tractor(){ cout << "Tractor 析构函数!" << endl; } public: string mName; }; //人类 class Person{ public: #if 1 //类mCar不存在合适的构造函数 Person(string name){ mName = name; } #else //初始化列表可以指定调用构造函数 Person(string carName, string tracName, string name) : mTractor(tracName), mCar(carName), mName(name){ cout << "Person 构造函数!" << endl; } #endif void GoWorkByCar(){ cout << mName << "开着" << mCar.mName << "去上班!" << endl; } void GoWorkByTractor(){ cout << mName << "开着" << mTractor.mName << "去上班!" << endl; } ~Person(){ cout << "Person 析构函数!" << endl; } private: string mName; Car mCar; Tractor mTractor; }; void test(){ //Person person("宝马", "东风拖拉机", "赵四"); Person person("刘能"); person.GoWorkByCar(); person.GoWorkByTractor(); }
explicit关键字
c++提供了关键字explicit,禁止通过构造函数进行的隐式转换。声明为explicit的构造函数不能在隐式转换中使用。
|
[explicit注意] explicit用于修饰构造函数,防止隐式转化。 是针对单参数的构造函数(或者除了第一个参数外其余参数都有默认值的多参构造)而言。 |
class MyString{ public: explicit MyString(int n){ cout << "MyString(int n)!" << endl; } MyString(const char* str){ cout << "MyString(const char* str)" << endl; } }; int main(){ //给字符串赋值?还是初始化? //MyString str1 = 1; MyString str2(10); //寓意非常明确,给字符串赋值 MyString str3 = "abcd"; MyString str4("abcd"); return EXIT_SUCCESS; }
动态对象创建
当我们创建数组的时候,总是需要提前预定数组的长度,然后编译器分配预定长度的数组空间,在使用数组的时,会有这样的问题,数组也许空间太大了,浪费空间,也许空间不足,所以对于数组来讲,如果能根据需要来分配空间大小再好不过。
所以动态的意思意味着不确定性。
为了解决这个普遍的编程问题,在运行中可以创建和销毁对象是最基本的要求。当然c早就提供了动态内存分配(dynamic memory allocation),函数malloc和free可以在运行时从堆中分配存储单元。
然而这些函数在c++中不能很好的运行,因为它不能帮我们完成对象的初始化工作。
对象创建
当创建一个c++对象时会发生两件事:
- 为对象分配内存
- 调用构造函数来初始化那块内存
第一步我们能保证实现,需要我们确保第二步一定能发生。c++强迫我们这么做是因为使用未初始化的对象是程序出错的一个重要原因。
C动态分配内存方法
为了在运行时动态分配内存,c在他的标准库中提供了一些函数,malloc以及它的变种calloc和realloc,释放内存的free,这些函数是有效的、但是原始的,需要程序员理解和小心使用。为了使用c的动态内存分配函数在堆上创建一个类的实例,我们必须这样做:
class Person{ public: Person(){ mAge = 20; pName = (char*)malloc(strlen("john")+1); strcpy(pName, "john"); } void Init(){ mAge = 20; pName = (char*)malloc(strlen("john")+1); strcpy(pName, "john"); } void Clean(){ if (pName != NULL){ free(pName); } } public: int mAge; char* pName; }; int main(){ //分配内存 Person* person = (Person*)malloc(sizeof(Person)); if(person == NULL){ return 0; } //调用初始化函数 person->Init(); //清理对象 person->Clean(); //释放person对象 free(person); return EXIT_SUCCESS; }
问题:
|
1) 程序员必须确定对象的长度。 2) malloc返回一个void*指针,c++不允许将void*赋值给其他任何指针,必须强转。 3) malloc可能申请内存失败,所以必须判断返回值来确保内存分配成功。 4) 用户在使用对象之前必须记住对他初始化,构造函数不能显示调用初始化(构造函数是由编译器调用),用户有可能忘记调用初始化函数。 |
c的动态内存分配函数太复杂,容易令人混淆,是不可接受的,c++中我们推荐使用运算符new 和 delete.
new operator
C++中解决动态内存分配的方案是把创建一个对象所需要的操作都结合在一个称为new的运算符里。当用new创建一个对象时,它就在堆里为对象分配内存并调用构造函数完成初始化。
Person* person = new Person; 相当于: Person* person = (Person*)malloc(sizeof(Person)); if(person == NULL){ return 0; } person->Init();
New操作符能确定在调用构造函数初始化之前内存分配是成功的,所有不用显式确定调用是否成功。
现在我们发现在堆里创建对象的过程变得简单了,只需要一个简单的表达式,它带有内置的长度计算、类型转换和安全检查。这样在堆创建一个对象和在栈里创建对象一样简单。
delete operator
new表达式的反面是delete表达式。delete表达式先调用析构函数,然后释放内存。正如new表达式返回一个指向对象的指针一样,delete需要一个对象的地址。
delete只适用于由new创建的对象。
如果使用一个由malloc或者calloc或者realloc创建的对象使用delete,这个行为是未定义的。因为大多数new和delete的实现机制都使用了malloc和free,所以很可能没有调用析构函数就释放了内存。
如果正在删除的对象的指针是NULL,将不发生任何事,因此建议在删除指针后,立即把指针赋值为NULL,以免对它删除两次,对一些对象删除两次可能会产生某些问题。
class Person{ public: Person(){ cout << "无参构造函数!" << endl; pName = (char*)malloc(strlen("undefined") + 1); strcpy(pName, "undefined"); mAge = 0; } Person(char* name, int age){ cout << "有参构造函数!" << endl; pName = (char*)malloc(strlen(name) + 1); strcpy(pName, name); mAge = age; } void ShowPerson(){ cout << "Name:" << pName << " Age:" << mAge << endl; } ~Person(){ cout << "析构函数!" << endl; if (pName != NULL){ delete pName; pName = NULL; } } public: char* pName; int mAge; }; void test(){ Person* person1 = new Person; Person* person2 = new Person("John",33); person1->ShowPerson(); person2->ShowPerson(); delete person1; delete person2; }
用于数组的new和delete
使用new和delete在堆上创建数组非常容易。
//创建字符数组 char* pStr = new char[100]; //创建整型数组 int* pArr1 = new int[100]; //创建整型数组并初始化 int* pArr2 = new int[10]{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; //释放数组内存 delete[] pStr; delete[] pArr1; delete[] pArr2;
当创建一个对象数组的时候,必须对数组中的每一个对象调用构造函数,除了在栈上可以聚合初始化,必须提供一个默认的构造函数。
class Person{ public: Person(){ pName = (char*)malloc(strlen("undefined") + 1); strcpy(pName, "undefined"); mAge = 0; } Person(char* name, int age){ pName = (char*)malloc(sizeof(name)); strcpy(pName, name); mAge = age; } ~Person(){ if (pName != NULL){ delete pName; } } public: char* pName; int mAge; }; void test(){ //栈聚合初始化 Person person[] = { Person("john", 20), Person("Smith", 22) }; cout << person[1].pName << endl; //创建堆上对象数组必须提供构造函数 Person* workers = new Person[20]; }
delete void*可能会出错
如果对一个void*指针执行delete操作,这将可能成为一个程序错误,除非指针指向的内容是非常简单的,因为它将不执行析构函数.以下代码未调用析构函数,导致可用内存减少。
class Person{ public: Person(char* name, int age){ pName = (char*)malloc(sizeof(name)); strcpy(pName,name); mAge = age; } ~Person(){ if (pName != NULL){ delete pName; } } public: char* pName; int mAge; }; void test(){ void* person = new Person("john",20); delete person; }
|
问题:malloc、free和new、delete可以混搭使用吗?也就是说malloc分配的内存,可以调用delete吗?通过new创建的对象,可以调用free来释放吗? |
使用new和delete采用相同形式
|
Person* person = new Person[10]; delete person; |
以上代码有什么问题吗?(vs下直接中断、qt下析构函数调用一次)
使用了new也搭配使用了delete,问题在于Person有10个对象,那么其他9个对象可能没有调用析构函数,也就是说其他9个对象可能删除不完全,因为它们的析构函数没有被调用。
我们现在清楚使用new的时候发生了两件事: 一、分配内存;二、调用构造函数,那么调用delete的时候也有两件事:一、析构函数;二、释放内存。
那么刚才我们那段代码最大的问题在于:person指针指向的内存中到底有多少个对象,因为这个决定应该有多少个析构函数应该被调用。换句话说,person指针指向的是一个单一的对象还是一个数组对象,由于单一对象和数组对象的内存布局是不同的。更明确的说,数组所用的内存通常还包括“数组大小记录”,使得delete的时候知道应该调用几次析构函数。单一对象的话就没有这个记录。单一对象和数组对象的内存布局可理解为下图:
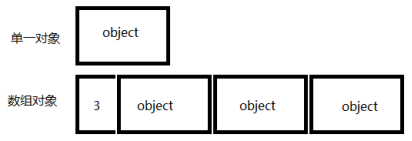
本图只是为了说明,编译器不一定如此实现,但是很多编译器是这样做的。
当我们使用一个delete的时候,我们必须让delete知道指针指向的内存空间中是否存在一个“数组大小记录”的办法就是我们告诉它。当我们使用delete[],那么delete就知道是一个对象数组,从而清楚应该调用几次析构函数。
结论:
|
如果在new表达式中使用[],必须在相应的delete表达式中也使用[].如果在new表达式中不使用[], 一定不要在相应的delete表达式中使用[]. |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号