
01@ecph分布式存储理论 --02
分布式存储ceph
一、ceph介绍
1.1、ceph是什么
nfs 网络存储
ceph是一个统一的、分布式的存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
# “统一的”:意味着我们可以仅凭ceph这一套存储系统,同时提供对象存储、块存储和文件系统存储三种功能,这极大地简化了不同应用需求下的部署和运维工作。
# “分布式”:ceph实现了真正的去中心化,理论上可以无限扩展集群系统的规模
# ceph:
统一的:同时支持多种存储的应用形式
1、块存储
2、文件存储
3、对象存储
分布式:
传统集群架构:集群规模增大,mysql数据库的集群规模必然也要随之增大,这完全就是集中式思想带来的弊端
了解:
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果手2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
1.2什么是块存储、文件存储、对象存储
1.21 备知识: 块级与文件级
- 1、块级
磁盘的最小读写单位为扇区,1个或多个连续的扇区组成一个block块,也叫物理块,是操作系统读写硬盘的单位
[root@admin ~]# blockdev --getbsz /dev/sda1
512
- 文件级
文件是文件系统提供的功能,单个文件可能由于一个或多个逻辑块组成,且逻辑块之间是不连续分布。逻辑块大于或等于物理块整数倍
物理块与文件系统之间的映射关系为:
逻辑文件----切分----》多个逻辑文件块----》物理块block---->扇区
# 注意:
这么多层转换,肯定是需要耗费效率的,如果操作的是对象,则可以直接省去这么多层映射关系,效率自然是高

1.2.2 块存储、文件存储、对象存储
1.块存储
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WuvfCFGl-1621094374941)(C:\Users\17155\Desktop\下载图片\1620976049755.png)]](https://img-blog.csdnimg.cn/20210516000542889.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21tOTcwOTE5,size_16,color_FFFFFF,t_70)
块存储:存储设备共享给客户端的是一块裸盘,那么该存储设备提供的就是块存储
特点:
1、客户端可定制性强,可以自己可以制作文件系统,然后挂载使用,或者直接把操作系统安装在块存储里
用途:
主要用于vm的本地硬盘
2. 文件存储
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mcVcI4Gz-1621094374945)(C:\Users\17155\Desktop\下载图片\1620976241729.png)]](https://img-blog.csdnimg.cn/2021051600060367.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21tOTcwOTE5,size_16,color_FFFFFF,t_70)
文件存储:为了解决多服务器之间共享数据,并且保证一致
存储设备中分出一块空间,然后制作文件系统,然后在存储设备中完成挂载,然后把文件夹共享给客户端用
特点:
1、客户端定制性差,不能自己制作文件系统,文件系统是在存储设备中制作好的,客户端使用的就是一个文件夹
2、文件检索与存储过程都是在存储设备中完成的,意味着随着客端数目的增多,存储设备的压力会越来越大,所以文件存储会限制集群的扩展规模
用途:
中小规模集群的多服务器之间共享数据,并且保证一致
3.对象存储
对象存储:为了解决多服务器之间共享数据,并且保证一致,并且没有文件系统的概念,数据的存储分为两部分:元数据+内容
客户端通过url地址的方式提交元数据与内容
特点:
1、没有文件检索的压力,服务端不会随着客端数目的增多压力成倍增大
用途: 分布式
1.3 为何要用ceph
Ceph本身确实具有较为突出的优势,晚听這求电最廉价的设备做最牛逼的存储。
其先进的核心设计思想,概括为人“无需查表,算算就好"。
# 1、高性能
a.摒球不转统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考实了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c.能够支得上千个存储节点的规模,支持TB到PB级的数据。
# 2、高可透性
a.副本数可以灵活控制。
b.支持故障域分隔,数据强一致性。
c.多种故障场景自动进步烧豐自愈。
d.没有单点故障,自动管理。高可扩展性场丢中心化。
# 3、去中心化
b.扩展灵活。
c.随着节点增加而线性增长。
# 4、特性丰富
a.支持三种存储接口:块存储、文件存储、对象存储。
b.支持自定义接口,支持多种语言驱动。
二 ceph系统的层次结构
1.简介
自下向上,可以将Ceph系统分为四个层次:
基础存储系统RADOS(ReliableAutonomicDistributed Object Store,即可靠的、自动化的、分布式的对象存储)
基础库LIBRADOS
2.高层应用接口:包括了三个部分
1、对象存储接口:RADOS GW(RADOS Gateway)
2、块存储接口:RBD(Reliable Block Device)
3、文件存储接口:Ceph FS(Ceph File Svstem)
应用层:基于高层接口或者基础库librados开发出来的各种APP,或者主机、VM等诸多客户端
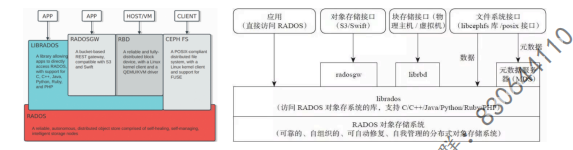
提示:rados集群是ceph的服务端,依据高层接口封装的应用则是客户端。
3.ceph四层层次结构
第一层:那些存储接口
第二层:radosge ceph对象网关 (对象存储) librdb (块存储) MDS(文件存储)
第三层:librados基础库
第四层:rados (ceph集群)
三、基础存储系统RADOS(ceph集群)
3.1引入
如果单台单块服务器在牛逼,也是有限的,我们需要考虑它的IO速度和容量。
解决方案:
纵向扩展---->不可能实现一瓶装下长江水
横向扩展---->n盘做raid,相当于一块大盘,在本机使用,但是单台机器可插硬盘的总数也是有限的,仍然会受到限制
如果能通过网络通信,那么就可以打破单台机器的限制:一堆硬盘+软件控制起来
做成硬盘的集群,相当于一个大的网络raid,这就是分布式存储,比如ceph # (横向扩展)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KCWp42PI-1621094374947)(C:\Users\17155\Desktop\下载图片\1620978321030.png)]](https://img-blog.csdnimg.cn/20210516000409318.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21tOTcwOTE5,size_16,color_FFFFFF,t_70)
3.2 RADOS 特点
ceph的底层是RADOS,而RADOS由多个子集群构成
ceph内部集群的数据共享完全通过crush算法算出来,根本不需要数据库这个组件,完全式分布式的!
ceph分布式的缺点:
1、耗费cpu
任何集群追求的三大特点:
1、性能-》IO
2、可靠性:没有单点故障
3、可扩展性:未来可以理论上无限扩展集群规模
3.2 RADOS的子集群
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JnwdNclD-1621094374950)(C:\Users\17155\Desktop\下载图片\1620979628852.png)]](https://img-blog.csdnimg.cn/20210516000344935.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21tOTcwOTE5,size_16,color_FFFFFF,t_70)
pg 归规组
mds 文件系统提供元数据 (文件存储)
monitor 监控集群
osd 复制响应客户端请教返回具体数据的进程
mds 依赖源数据的服务
libradio 基础库
radosge ceph对象网关 (对象存储)
librdb (块存储)
osd daemon相当于套接字 # 默认4M为单位
切割的点叫objiect
# 哈希算法 crush算法
object -- > pg ---> osd daemon
# pg相当于raisdi
ceph: 伪数据平衡,哈希算法达到的
ceph: 适用于海量小文件,或者单个文件容量大(云计算才会用ceph)
object -- > pg # 哈希算法达到的
pg ---> osd daemon # crush算法
1、若干个数据盘:一个Ceph存储节点上可以有一个或者多个数据盘,每个数据盘上部署有特定的文件系统,比如xfs,ext4或者btrfs。可以是一个分区当一个disk,可以是一个raid当一个 disk,也可以是一整块盘当一个disk
#1.btrfs(B-tree 文件系统):功能强大,但耗费资源也高
btrfs是个很新的文件系统(oracel在2014年8月发布第一个稳定版),它将会支持许多非常高大上的功能,比如透明压缩( transparent compression),可写的cow 快照(writable oopy-on-write snapshots)、去重(deduplication)和加密(encryption) 。因此,Ceph 建议用户在非关键应用上使用该文件系统。
#2、xfs(推荐)
xfs和 btrfs 相比较ext3/4而言,在高伸缩性数据存储方面具有优势。
# 一整块盘当一个disk
2.OSD(Object Storage Device) 集群:一个OSD daemon 就是一个套接字应用程序,唯一对应一块数据盘
(数据盘的组成可以是一块机械硬盘 + 一个固态盘的两个分区)

1、负责控制数据盘上的文件读写操作,与client(客户端)通信完成各种数据对象操作等等。
2、负责数据的拷贝和恢复
3、每个OSD 守护进程监视它自己的状态 以及别的OSD的状态,并且报告给 Monitor
# 一块硬盘 一个保存元数据,一个存放日志
# 在一个服务器上,一个数据对应一个OSD Daemon,而一个服务器上可以有多块数据盘,所以仅在一台服务器上,就会运行多个OSD Daemon,该服务称之为OS D节点,一个CEPH集群中有n个OSD节点,综合算下来,OSD集群由一定数目的(从几十个到几万个)OSD Daemon组成。

3、MON(Montior)集群:MON集群由少量的、数目为奇数个的Monitor守护进程(Daemon)组成,负责监控ceph所有集群中所有OSD状态及montior集群,一般至少三个。
补充:Ceph核心组件及概念介绍
# Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。
# OSD
OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。
#MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
#Object
Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据。
#PG
PG全称Placement Grouops(规制组),是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
# RADOS
RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
# Libradio
Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
#CRUSH
CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
#RBD
RBD全称RADOS block device,是Ceph对外提供的块设备服务。
#RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
#CephFS
CephFS全称Ceph File System,是Ceph对外提供的文件系统服务
例:
# ceph
1、伪数据平衡,是通过算法达到的
object ---hash算法---》pg---crush算法-----》osd daemon
2、ceph适用于海量小文件,或者单个文件容量大
# 1.一个osd daemon应该属于多少个pg组呢?
首先一个osd daemon肯定不能属于一个pg组,因为ceph是pg组为单位来分配数据的,如果一个osd daemon只属于一个pg组,那么该osd daemon将只能收这一个pg组发来的数据如果该pg组没有被hash算法算到,那么就不会收到数据,于是该osd daemon就被闲置了所以一个osd 应该属于多个pg组,到底应该属于多少个呢?
#官方建议:
ceph集群很长一段时间不会拓展:一个osd deamon属于100个pg,否则:一个osd deamon属于200个pg
# 2.ceph的逻辑单位:
1、pool(存储池):
在创建存储池时需要指定pg个数,来创建pg,
创建pg需要用到crush算法,crush决定了pg与osd daemon的对应关系,所以说,在客户端往ceph中写入数据之前,pg与osd daemon的对应关系是已经确定的,虽然是确定的,但是pg与osd daemon的对应关系是动态的
2、pg(归置组):是分配数据的最小单位,一个pg内包含多个osd daemon
hammer-》filestore osd daemon---》xfs文件系统----》disk
luminous-》bluestore osd daemon---》裸盘disk
primary osd
replication osd
3、osd deamon负责三件事:(负责具体干活的)
1、读写数据
2、数据的拷贝与恢复
3、监控自己以及pg组内的其它成员的状态,汇报给monitor节点
monitor节点(整个集群的大管家)
# 1、监控全局状态(cluster map)
1、osd daemon map
2、monitor map
3、pg map
4、crush map
# 2、负责管理集群内部状态(osd daemon挂掉,数据恢复等操作)
# 3、负责授权
客端在访问时会先通过monitor验证操作权限
客户端需要根monitor要到cluster map
ps:monitor节点的个数=2*n+1
1、必须为奇数个
2、一个monitor也可以,但是不应该这么做,因为有单点故障
所以最少3个起
1、为何monitor节点个数应该为奇数个
因为monitor节点同步数据用的是paxos算法(分布式强一致性算法)
paxos算法规定至少有三个节点
2、可以挂掉几个monitor节点
paxos算法下,monitor集群不能超过半数挂掉
3、monitor进程与osd daemon能否在同一个物理节点上
可以,但是不好,但是这就是一种集中式的思想了
如果考虑到成本,可以这么做
3.3rados的网络结构

rados作为ceph最核心的部分,是整个ceph的大后端,应该如何架设呢???
**首先:Ceph使用以太网连接内部各存储节点以及连接client 和rados集群。**
然后:Ceph推荐使用两个网络,这么做,主要是从性能(OSD节点之间会有大量的数据拷贝操作)和安全性(两网分离)考虑。
南北网络(apublic(frontside)network)连接客户端和集群
东西网络(acluster(back-side)network)来连接Ceph各存储节点
你可以在Ceph配置文件的[global]部分配置两个网络
public network =(public-network/netmask}
cluster network ={cluster-network/netmask}
四、Ceph集群的逻辑结构
LTS 长期稳定版ceph
4.1核心逻辑概念总览

rados构建完毕后,为客户端提供存储服务,需要。
1、创建存储池poo1,存储池中包含100个pg
ceph osd pool create rbdtest 1oo
2、设置poo池的副本数,即一个的包含多少个OSD Daemon,往某一个pg中存的数据会在其包含的osd中都保存一份
ceph osd pool set rhatest size 3
3、在存储池rdbtest中创建一个镜像给客户端用,一个image用的是存储池中的pg(并非指定的pg,而是只要是存在与pool中的pg都可能会用到),相当于一个配额
rbd create -p rdbtest --size 10000 yzl # image名为yzl,大小为10000M
在客户端文件会被以4M为单位切成3块,
每块对应一个object
object多对一pg
pg多对多osd daemon
一个pool中有多个pg
从pool中划分出image给用户用,image只是一个配额
写入数据流程大致如下:
librbd
crush算法
file ----->object ------>pool中划分出来的image(一堆pg)------->osd daemon
ceph存储小文件效率不高
底层osd daemon越多,存大文件效率越高
ceph是伪数据平衡,如果只有一个PG,一个PG里副本数为3,永远只有一块盘被用到
ceph的逻辑结构与Ivm有点像
pv->osd
vg > pool
lv ->image
4.2 pool
4.2.1 ceph pool介绍
在rados集群构建完毕后、使用ceph时,需要用到诸多逻辑概念/结构,我们才能理解一个文件到底是如何写入到ceph中。
4.2.2ceph的pool有四大属性
1、所有性和访问权限
2、对象副本数目,默认pool池中的一个pg只包含两个osd daemon,即一份数据交给pg后会存下2个副本,生产环境推荐设置为3个副本
3、PG数目,PG是pool的存储单位,pool的存储空间就由pg组成
4、CRUSH 规则集合
4.2.3 ceph的pool有两种类型
# 1. Replicated pool(默认):
默认的存储池类型,把每个存入的对象(Object)存储为多个副本,其中分为主副本和从副本,从副本相当于备份副分,从而确保在部分OSD丢失的情况下数据不丢失。这种类型的 pool 需要更多的裸存储空闻,但是它支持所有的pool 操作。
如果客户端在上传对象的时候不指定副本数,默认为3个副本。在开始存数据之前会计算出该对象存储的主副本与从副本的位置,首先会将数据存入到主副本,然后主副本再将数据分别同步到从副本。主副本与从副本同步完毕后,会通知主副本,这时候主副本再响应客户端,并表示数据上传成功。所以如果客户端收到存储成功的请求后,说明数据已经完成了所有副本的存储。
# 2. Erasure-coded pool:
此类型会将数据存储为K+M,其中K数据块数量。每个对象存储到Ceph集群的时候会分成多个数据块分开进行存储。而M为编码块,也代表最多容忍可坏的数据块数量。类似于磁盘阵列RAID5,在最大化利用空间的同时,还能保证数据丢失可恢复性,相比副本池更节约磁盘的空间。
# 列如:
如果将100M资源分为25块,如果将M指定为2,那么总共只需要108M空间即可,计算公式为100+100/25*2。
4.2.4 ceph的pool提供如下能力
# 1.Resilience(弹力):
即在确保数据不丢失的情况允许一定的OSD失败,这个数目取决于对象的拷贝(copy/replica)份数或称副本数。对拷贝型pool来说,Ceph中默认的拷贝份数是2,这意味着除了对象自身外,它还有一个另外的备份,你可以自己决定一个Pool中的对象的烤贝份数。生产环境推荐为3,副本数越多数据越安全、真正可以使用的空间越少
# 2.PG(placement group,放置组):ceph用pg把存放相同副本的osd daemon归为一组。
客户端的文件会被切成多个object然后交给ceph存储,ceph中真正负责存储的是osd daemon守护进程,在存储时,ceph需要找到n个osd daemon、归类好哪些osd daemon存放的是同一个副本、然后把object交给它们,为了降低查找与归类成本,于是引入了pg的概念,将存放相同副本的 osd daemon归为一个pg组
# 3.CRUSH Rules(CRUSH规则):数据映射的策略。系统默认提供"reolicated_ruleset"。
用户可以自定义策略来灵活地设置object存放的区域。比如可以指定po011中所有objecst放置在机架1上,所有objects的第1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务器B上。pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的服务器上,第2个副本分布在机架3的服器上,第3个副本分布在机架4的服务器上。后续小猿会详细介绍 crush rules.
# 4.Snapshots(快照):你可以对pool 做快照。
# 5.Set Ownership:设置pool的owner的用户ID。
# 6.Ceph集群创建后,默认创建了data metadata 和 rbd 三个存储池。
4.3 pg
4.3.1pg的概念
# PG英文全称 Placement group,中文称之为归置组。
PG的作用:PG相当于一个虚拟组件,出于集群伸缩,性能方面的考虑。
Ceph将每个存储池分为多个PG,如果存储池为副本池类型,并会给该存储池每个PG分配一个主OSD和多个从OSD,当数据量大的时候PG将均衡的分布行不同集群中的每个OSD上面。
PG概念非常复杂,主要有如下几点:
PG也是对象的逻集合,pool中的副本数设置为3,则一个pg中包含3个osd daemon,同一个PG接收到的所有object在这3个osddaemon上被复制。
一个PG组里有三个组员/OSD daemon,三个组员第一个是组长,组长负责对外提供服务,组员负责备份,一旦组长挂掉后,相当于公司中一个部门的项目经理挂了,公司会招聘一个新的项目经理,但新的项目经理刚来的时候还什么都不知道(即新加进来的osd daemon是没有任何组内数据的),此时公司会让某个组员先临时接替一下组长的职务、对外提供服务,一旦新来的组长了解了业务(即新加进来的osd daemon已经同步好数据了),那么就可以让新组长出山了.
3.2 pg的特点
一、基本特点
1、Ceph引入PG的目的主要是为了减少直接将对象object映射到OSD的复杂度,即PG 确定了pool中的对象object和pSD之间的映射关系,一个object只会存在于一个 PG 中,但是多个object可以在同一介PG内。PG-Object-OSD的关系如下图所示:
object与PG是多对一的关系
PG与OSDdaemon是多对多的关系
OSD daemon与disk是一对一的关系

2、一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均匀性问题。PG 和 OSD 之间的映射关系由CRUSH 决定,而它做决定的依据是CRUSH 规则
(rules)。CRUSH将所有的存储设备(OSD)组织成一个分层结构,该结构能区分故障域(failure domain),该结构中每个节点都是一个CRUSH bucket。详细情况后续介绍。
3、对象的副本数目,也就是被拷贝的次数,是在创建Pool时指定的。该分数决定了每个PG会在几个 OSD 上保存对象。如果一个拷贝型 Pool 的size(拷贝份数)为2,它会包含指定数目的PG,每个PG使用两O其中,第一个为主OSD(primary),其它的为从OSD(secondary)。不同的PG可能会共享一个 OSD。
4、PG也是Ceph集群做清理(scrubbing)的基本单位,也就是说数据清理是一个一个PG来做的。
、PG和 OSD 的关系是动态的
librbd crush算法
file—————————> object—————-—> pool中划分出来的image(一堆pg)—————— >
osd daemon
1)一开始在PG被创建的时候,MON根据CRUSH算法计算出PG所在的OSD。这是它们之间的初始关系。
2)Ceph集群中OSD的状态是不断变化的,它会在如下状态之间做切换
up:守护进程运行中,能够提供1O服务; down:守护进程不在运行,无法提供1O服务; in:包含数据;
out:不包含数据
3)部分PG和OSD的关系会随着OSD状态的变化而发生变化
当新的OSD被加入集群后,已有OSD上部分PG将可能被挪到新OSD上;此时PG和 OSD的关系会发生改变。
当已有的某OSDdown了并变为out后,其上的PG会被挪到其它已有的OSD上。但是大部分的PG和OSD的关系将会保持不变,在状态变化时,Ceph 尽可能只挪动最少的数据。
4)客户端根据Cluster map 以及CRUSH Ruleset 使用CRUSH算法查找出某个PG所在的 OSD 列表。
4.3.3 PG的创建过程
Pool的PG数目是创建pool时候指定的,Ceph官方有推荐的计算方法。其值与OSD的总数的关系密切。当Ceph集群扩展OSD增多时,根据需要,可以增加pool的PG 数目。
306
1)MON节点上有PGMonitotor,它发现有pool被创建后,判断该pool 是否有PG。如果有 PG,则逐一判断这些PG是否已经存在,如果不存在,则开始下面的创建PG的过程。
2)创建过程的开始,设置PG状态为Creating,并将它加入待创建PG队列 creatingpgs,等待被处理。
3)开始处理后,使用CRUSH算法根据当前的OSDmap 找出来up/acmgset,确定哪些osd属于哪些pg,然后加入队列 creating_pgs_by_osd, 等待被处理
4)队列处理函数将该OSD上需要创建的PG合并,生成消息MOSDPGCreate,通过消息通道发给OSD。
5)OSD收到消息字为 MSG_OSD_PG_CREATE的消息,得到消息中待创建的 PG 信息,判断类型,并获取该PG的其它OSD,加入队列creating_pgs似乎是由主 OSD 负责发起创建次 OSD上
的PG),再创建具体的PG。
6)PG 被创建出来以后,开始 Peering 过程。
4.3.4 PG 数目的确定(非常非常非常重要!!!)
创建pool 时需要确定其 PG的数目,在 poo被创建后也可以调整该数字,但是增加池中的PG数是影响ceph集群的重大事件之一,生成环境中应该避免这么做,因为pool中pg的数目会影响到
ceph 重点笔记
ceph
1、伪数据平衡,是通过算法达到的
object ---hash算法---》pg---crush算法-----》osd daemon
object
2、ceph适用于海量小文件,或者单个文件容量大
ps:一个osd daemon应该属于多少个pg组呢?
首先一个osd daemon肯定不能属于一个pg组,因为ceph
是pg组为单位来分配数据的,如果一个osd daemon只属于
一个pg组,那么该osd daemon将只能收这一个pg组发来的数据
如果该pg组没有被hash算法算到,那么就不会收到数据,于是
该osd daemon就被闲置了,
所以一个osd 应该属于多个pg组,到底应该属于多少个呢?
官方建议:
ceph集群很长一段时间不会拓展:一个osd deamon属于100个pg
否则:一个osd deamon属于200个pg
ceph的逻辑单位:
1、pool(存储池):
在创建存储池时需要指定pg个数,来创建pg,
创建pg需要用到crush算法,crush决定了pg与osd daemon的对应关系,所以说,在客户端往ceph中写入
数据之前,pg与osd daemon的对应关系是已经确定的
,虽然是确定的,但是pg与osd daemon的对应关系是动态
的
2、pg(归置组):是分配数据的最小单位,一个pg内包含多个osd daemon
hammer-》filestore osd daemon---》xfs文件系统----》disk
luminous-》bluestore osd daemon---》裸盘disk
primary osd
replication osd
osd deamon负责三件事:(负责具体干活的)
1、读写数据
2、数据的拷贝与恢复
3、监控自己以及pg组内的其它成员的状态,汇报给monitor节点
monitor节点(整个集群的大管家)
1、监控全局状态-》
cluster map
1、osd daemon map
2、monitor map
3、pg map
4、crush map
2、负责管理集群内部状态(osd daemon挂掉,数据恢复等操作)
3、负责授权,
客端在访问时会先通过monitor验证操作权限
客户端需要根monitor要到cluster map
ps:monitor节点的个数=2*n+1
1、必须为奇数个
2、一个monitor也可以,但是不应该这么做,因为有单点故障
所以最少3个起
1、为何monitor节点个数应该为奇数个
因为monitor节点同步数据用的是paxos算法(分布式强一致性算法)
paxos算法规定至少有三个节点
2、可以挂掉几个monitor节点
paxos算法下,monitor集群不能超过半数挂掉
3、monitor进程与osd daemon能否在同一个物理节点上
可以,但是不好,但是这就是一种集中式的思想了
如果考虑到成本,可以这么做

 浙公网安备 33010602011771号
浙公网安备 33010602011771号