
分享知识-快乐自己:运行(wordcount)案例
运行 wordcount 案例:
-----------------------------------------------------------------
Hadoop集群测试wordcount程序:
1):在bigData目录下创建wordcount文件夹
mkdir wordcount //创建文件夹

2):在wordcount文件夹下创建两个文件并输入内容
//创建 file1.txt
vim file1.txt
//输入内容如下:
hello word
hello java
//创建 file2.txt
vim file2.txt
hello hadoop
hello wordcount
3):在HDFS中创建input文件夹
hadoop fs -mkdir /input
// hadoop fs :可以理解为 hadoop系统文件目录
查看创建的文件(是否存在)

4):把刚才创建的两个文件上传到HDFS中input文件夹
//上传所有以 .txt 结尾的文件
hadoop fs -put ./*.txt /input/
//查看上传的文件
hadoop fs -ls /

注意:可能存在的问题:
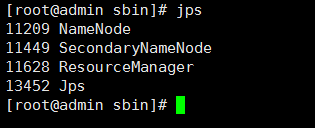
查看当前正在运行的相关服务:
jps //没有规定要在哪一个目录执行
1):上传过程中可能出现以下错误:

解决方案:
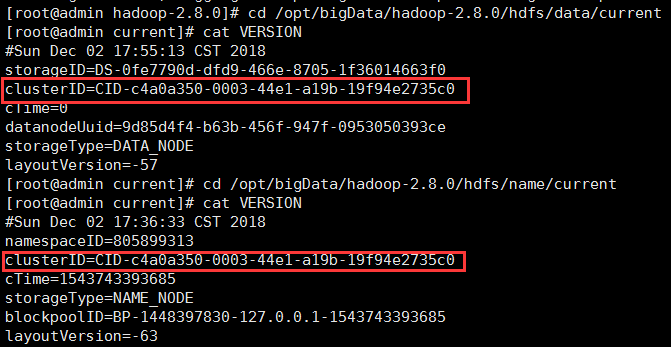
查看 配置 hdfs-site.xml 节点指定的路径【 name 和 data 】目录是否自动生成了(查看主机是否存在 name 和子机器上的 data)。
小编这里是没有生成 data 目录。
有了目录还需要注意:name 和 data 目录中的 id 必须一致:(如果不一致可以修改一下 或者 删除 name data logs tem 生成的目录 重新格式化并启动集群:查看是否有相应信息)
5):运行wordcount程序
Hadoop的 jar 包中已经给我们提供了 mapreduce 程序!都在 /bigData/hadoop-2.8.0/share/hadoop/mapreduce文件夹中!
切换到 share/hadoop/mapreduce 目录下:
cd share/hadoop/mapreduce
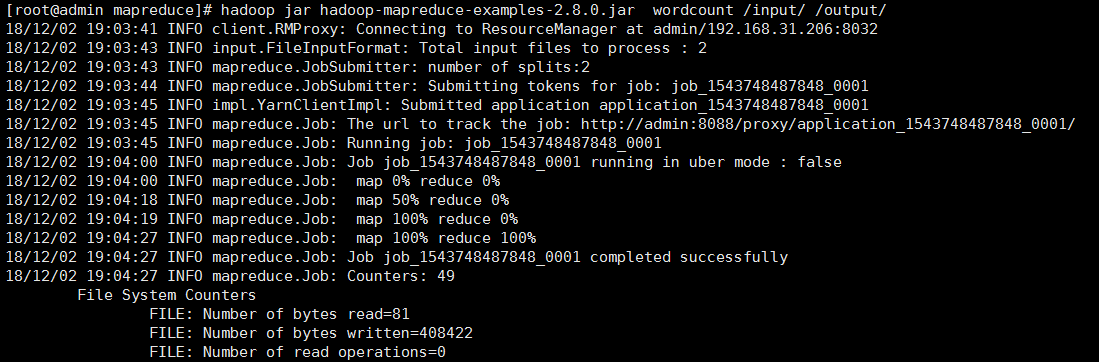
执行以下命令:
hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordcount /input/ /output/
/input/ :是指需要计算文件所在的位置
/output/:是指计算之后的结果文件存放位置
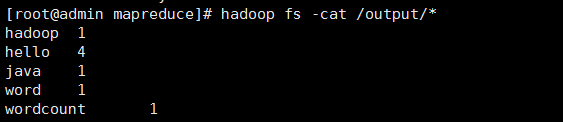
6):查看执行运算后的结果
hadoop fs -cat /output/*
Eclipse集成Hadoop插件:点我下载源码
如果eclipse是装在了真机windows系统中,需要我们在真机上安装hadoop!(同样将 hadoop 压缩包在 windows 上解压一份:【以管理员方式运行解压】)
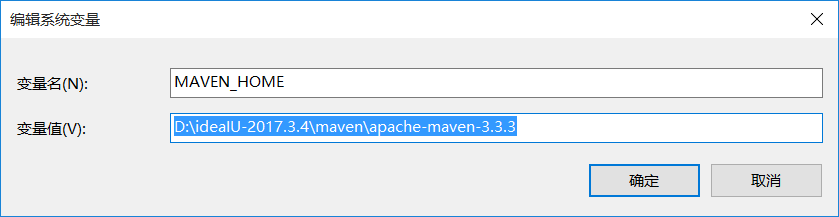
1):配置 windows hadoop环境变量:
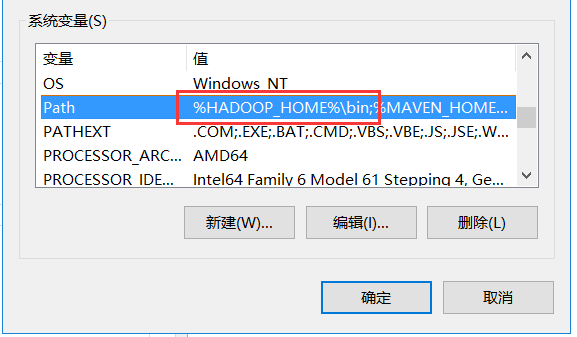
2):使用 hadoop version 查看是否配置成功:

3):下载指定版本的插件:下载地址一 下载地址二
把插件放进 eclipse 安装目录下的 plugins 文件夹下
4):启动eclipse配置hadoop的安装目录
4-1):
4-2):
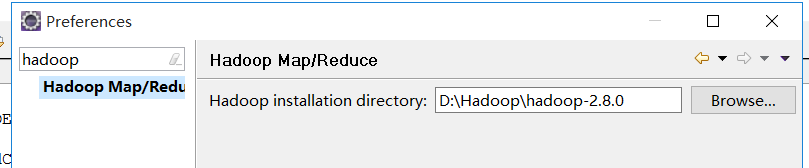
4-3):eclipse中显示插件的页面:

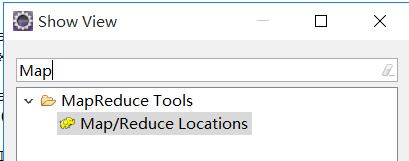
4-):
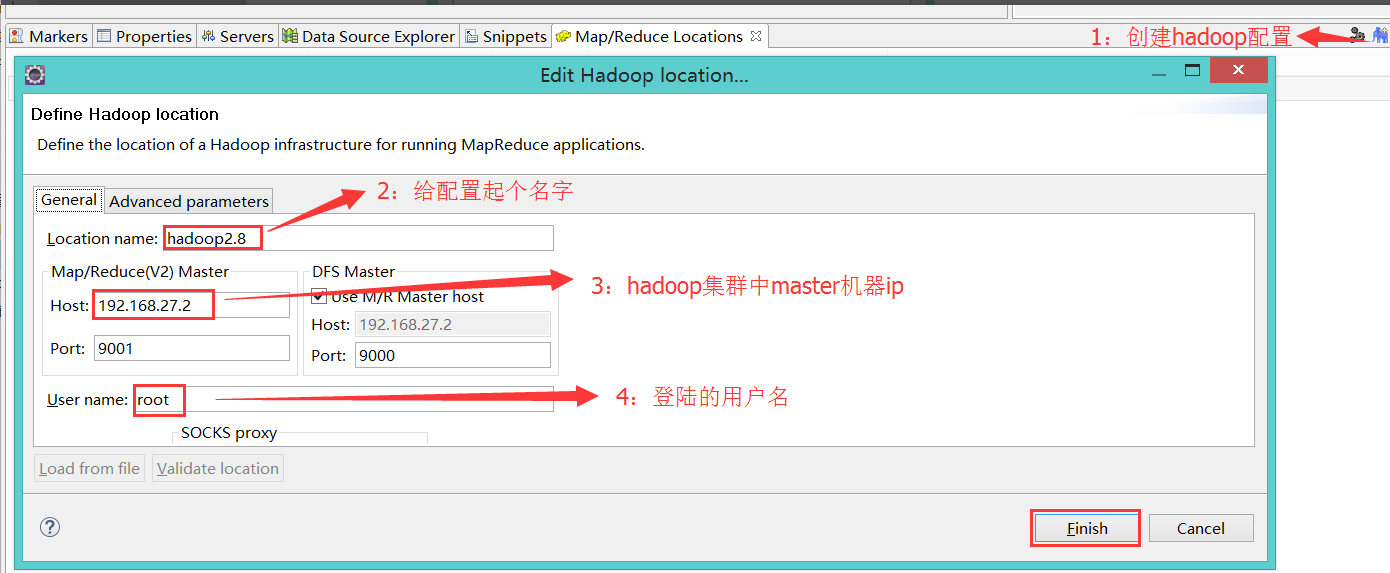
5):使用eclipse创建并运行wordcount程序
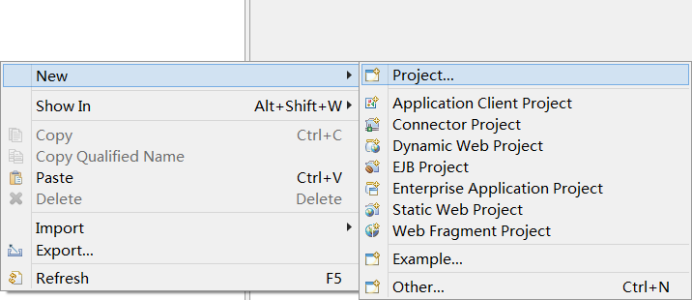
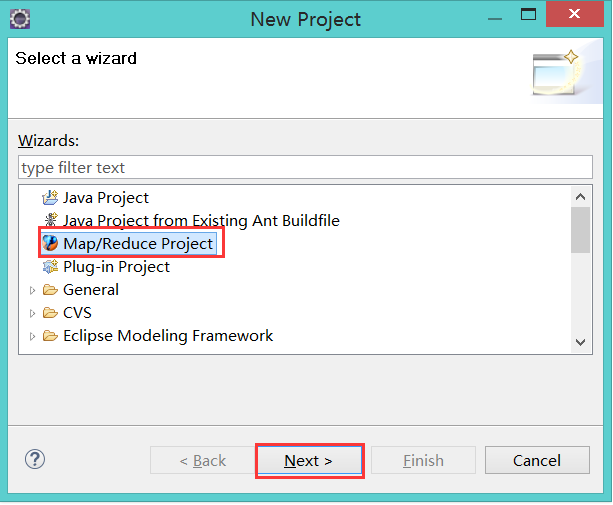

导入计算程序:
1):
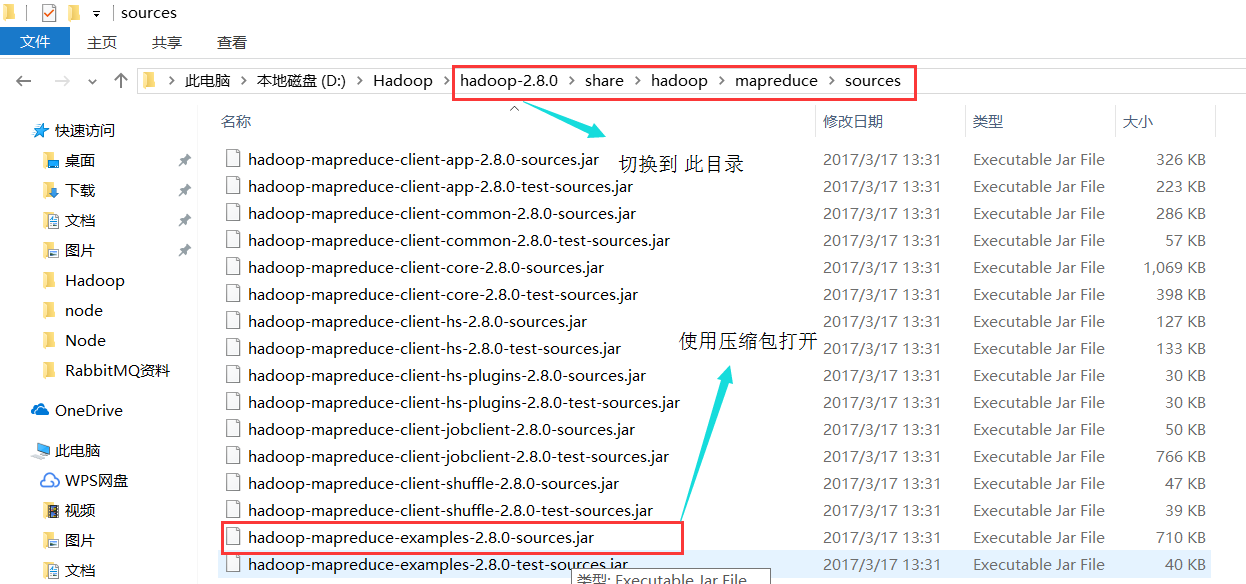
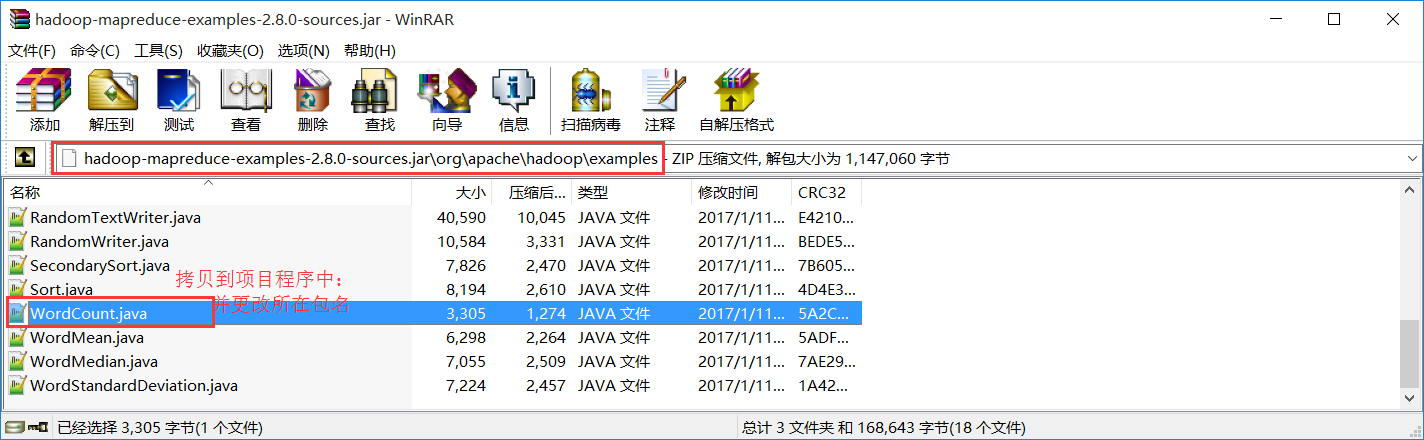
2):

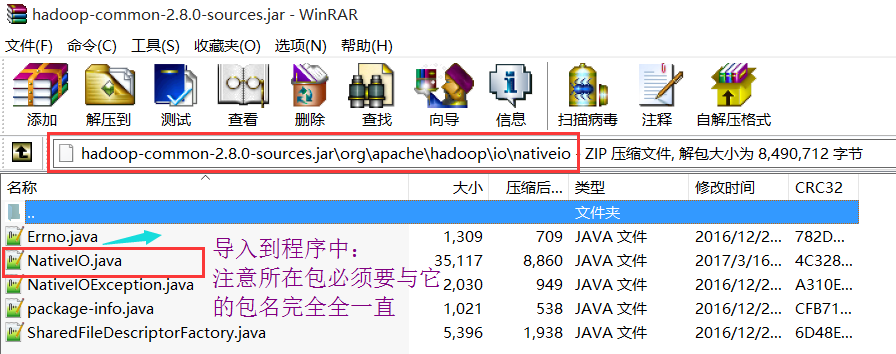
NativeIO:更改以下配置

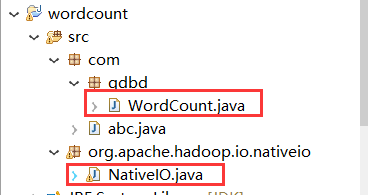
目录结构:
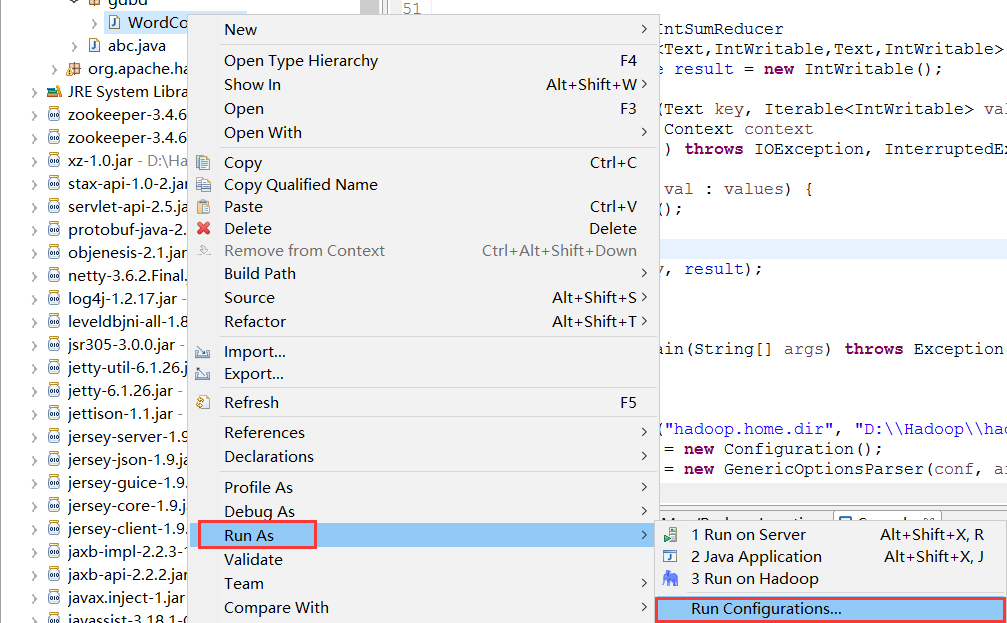
右键点击WordCount====》Run As ===》Run Configuration:
java Application 上 new:
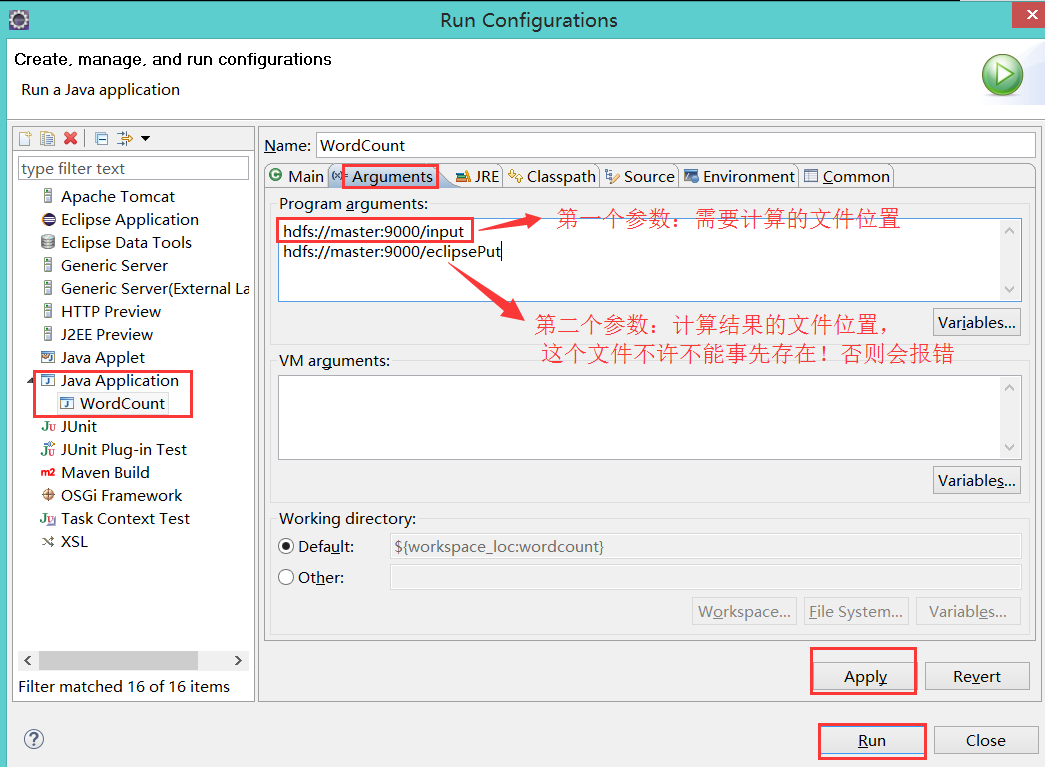
hdfs://admin:9000/input
hdfs://admin:9000/eclipseoutput
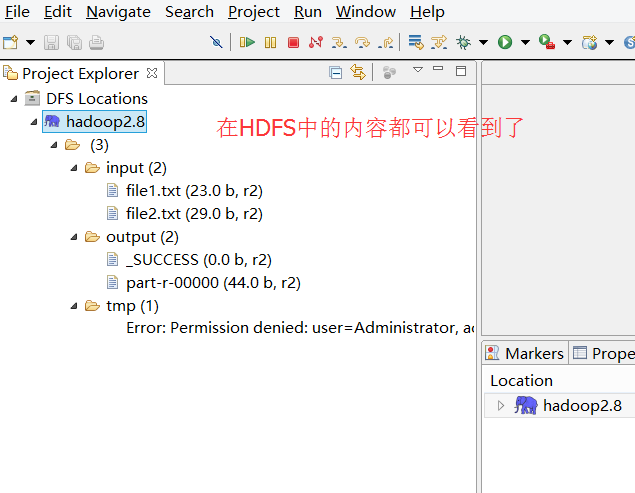
得到结果:
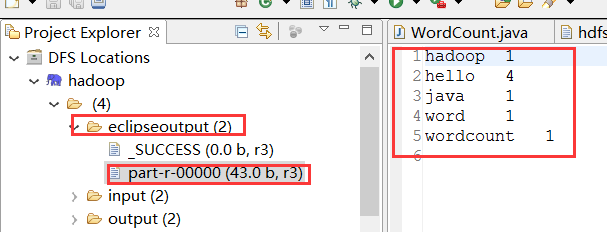
注意:Error 可能出现的错误...
1):有可能是本机的hadoop/bin目录下缺少hadoop.dll和winutils.exe等文件。(建议全部替换 hadoop/bin 下的所有文件。bin包在上述的下载地址中)
2):
org.apache.hadoop.security.AccessControlException: Permissiondenied: user=zhengcy, access=WRITE,inode="/user/root/output":root:supergroup:drwxr-xr-x
在集群中运行hadoop fs -chmod -R 777 /
或者
修改三个虚拟机的配置:hdfs-site.xml
添加如下配置:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
3):
Exception in thread "main" java.lang.RuntimeException:
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
解决方式:在 WordCount类中的main 方法中添加如下配置
System.setProperty("hadoop.home.dir", "hadoop安装目录");
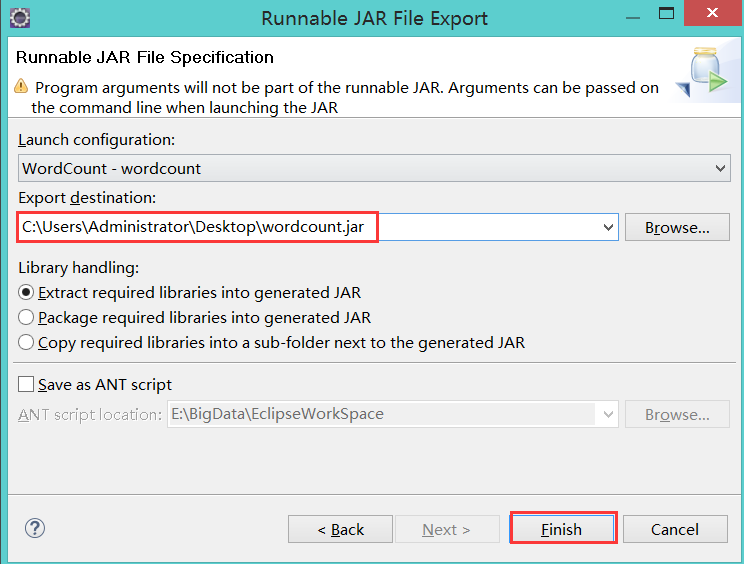
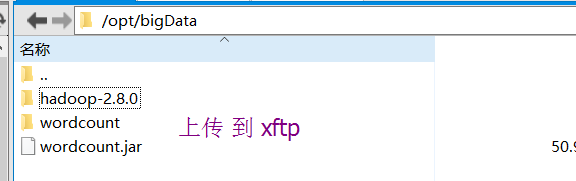
6):使用eclipse打成jar包发布到linux中运行
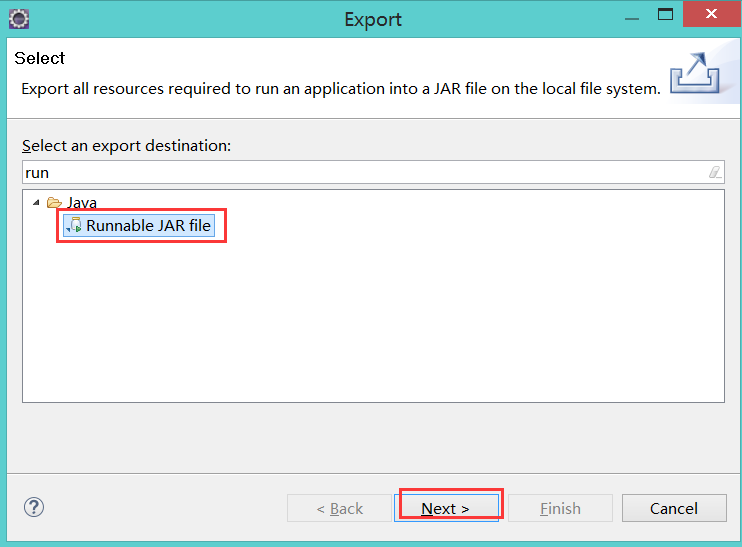

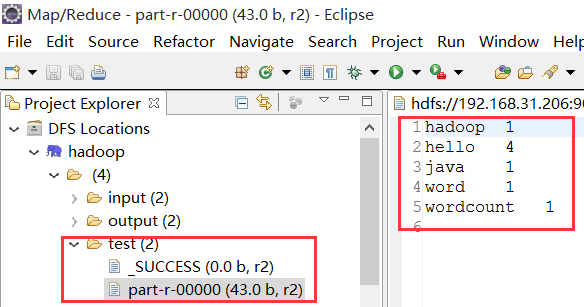
7):运行完毕之后,在eclipse中查看效果图!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号