
stanford cs 110l lec2
为什么放弃cpp,选择rust
- 因为cpp存在大量的memory safety
- 空悬指针,返回指向栈中的变量的指针
![]() Rust编译器会对其做识别
Rust编译器会对其做识别 - double free
![]() Rust编译器保证一旦内存被释放,那么就不能够去使用该内存
Rust编译器保证一旦内存被释放,那么就不能够去使用该内存 - 访问已经释放的内存
![]() Rust编译器使得我们不能够去修改n指向的数据
Rust编译器使得我们不能够去修改n指向的数据 - 内存泄漏
![]() 这里不就是GC吗
这里不就是GC吗
- 空悬指针,返回指向栈中的变量的指针
 Rust编译器会对其做识别
Rust编译器会对其做识别 Rust编译器保证一旦内存被释放,那么就不能够去使用该内存
Rust编译器保证一旦内存被释放,那么就不能够去使用该内存 Rust编译器使得我们不能够去修改n指向的数据
Rust编译器使得我们不能够去修改n指向的数据 这里不就是GC吗
这里不就是GC吗语言与编译器
- 由于Rust的限制,也就是编译器过于保守,一些程序很难写出并通过编译器的检查,这时就需要unsafe关键字
![]() Rust的高新能得益于其编译器的优化
Rust的高新能得益于其编译器的优化
 Rust的高新能得益于其编译器的优化
Rust的高新能得益于其编译器的优化owership
![]()
- 基本数据类型的CopyTrait
![]()
- 对于refernece(引用),在可变作用域内,只能存在一个可变引用。对于不可变引用,可以存在多个
![]()



Lifetimes
- 对于已经超出了作用域的变量,Rust编译器会调用drop函数(destructor)去回收其内存?
![]()

1如何找到程序中的bugs
1.1 动态分析
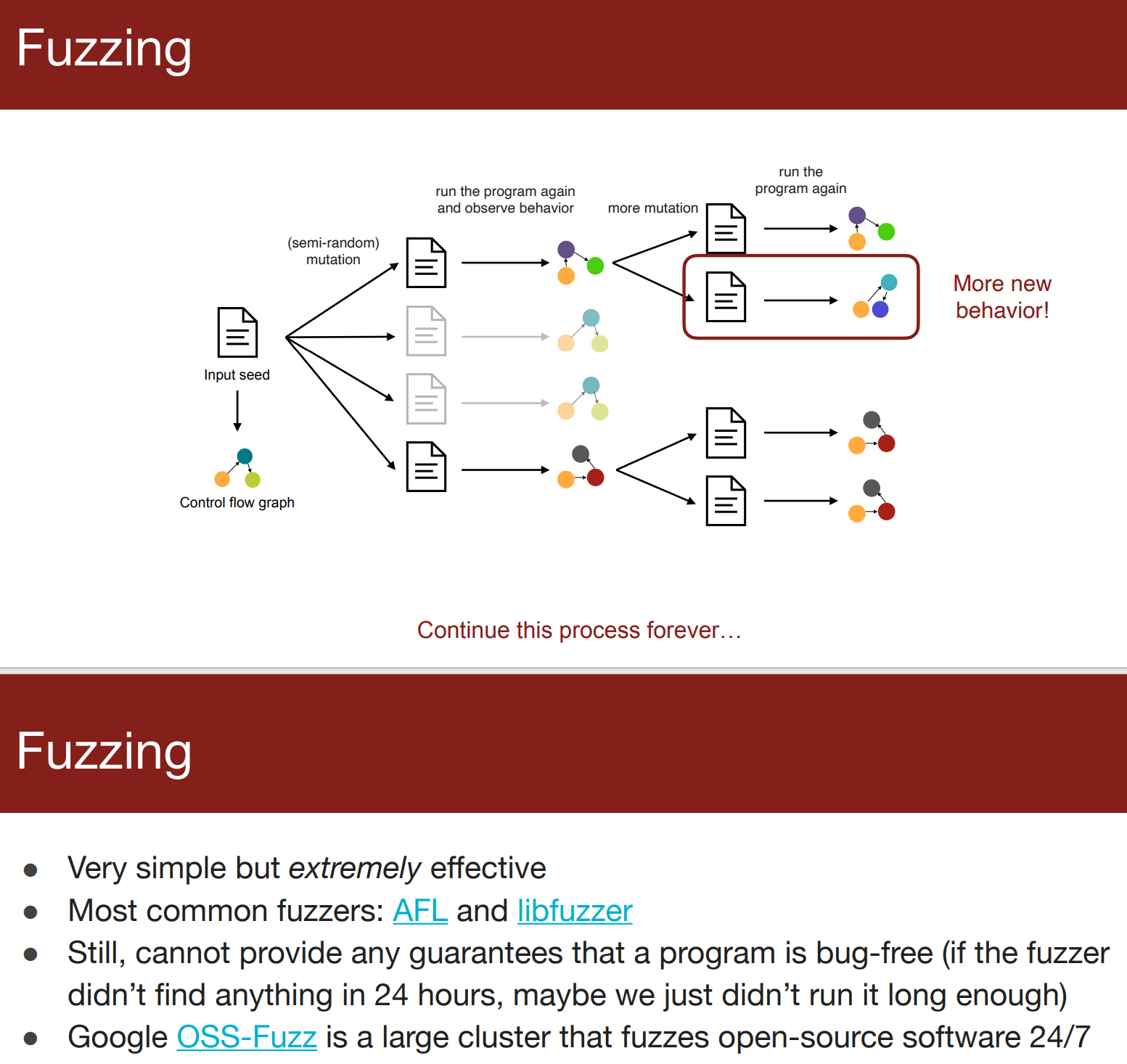
- 通过你给的输入数据,运行代码,检测错误行为。通常会在运行代码时,附带一些技术,并尝试大量的不同的输入数据(fuzzing模糊测试)
valgrind
- 将二进制代码反汇编,并对代码打桩,valgrind会使用一些元数据,来记录内存的使用情况,以此检测内存的错误
![]()
- valgrind并不能够检测处gets函数的错误,因为stack就是一段内存,但是其中的变量被覆盖了,并不会被valgrind检测出来。
![]()


LLVM Sanitizers
- 做修饰,但是是在源代码级别上的。
- 因为有更多的信息可以利用,在编译之前,sanitizers可以利用这些信息做处理
- 有很多的Sanitizer
- AddressSanitizer,用于检测内存越界,doule free,使用释放后的内存
- LeakSanitizer,找到内存泄漏
- MemorySanitizer,找到使用未初始化的内存
- UndefinedBehaviorSanitizer, 找到使用空指针,整数/浮点溢出
- ThreadSanitizer,不恰当的使用线程
动态分析的限制
- 动态分析只能够发现运行时出现的错误,如果输入的样例不足,那么一些错误边界条件难以检测到,可以通过fuzzing勉强处理,不一样的control flow graph
![]()
1.2 静态分析
linting
- linter,(来自于,衣服在烘干机中脱落的纤维绒毛,那么linter就是像烘干机中的绒毛(lint)过滤器),
![]() clang-tidy甚至可以自动修复很多问题。
clang-tidy甚至可以自动修复很多问题。
 clang-tidy甚至可以自动修复很多问题。
clang-tidy甚至可以自动修复很多问题。dataflow analysis
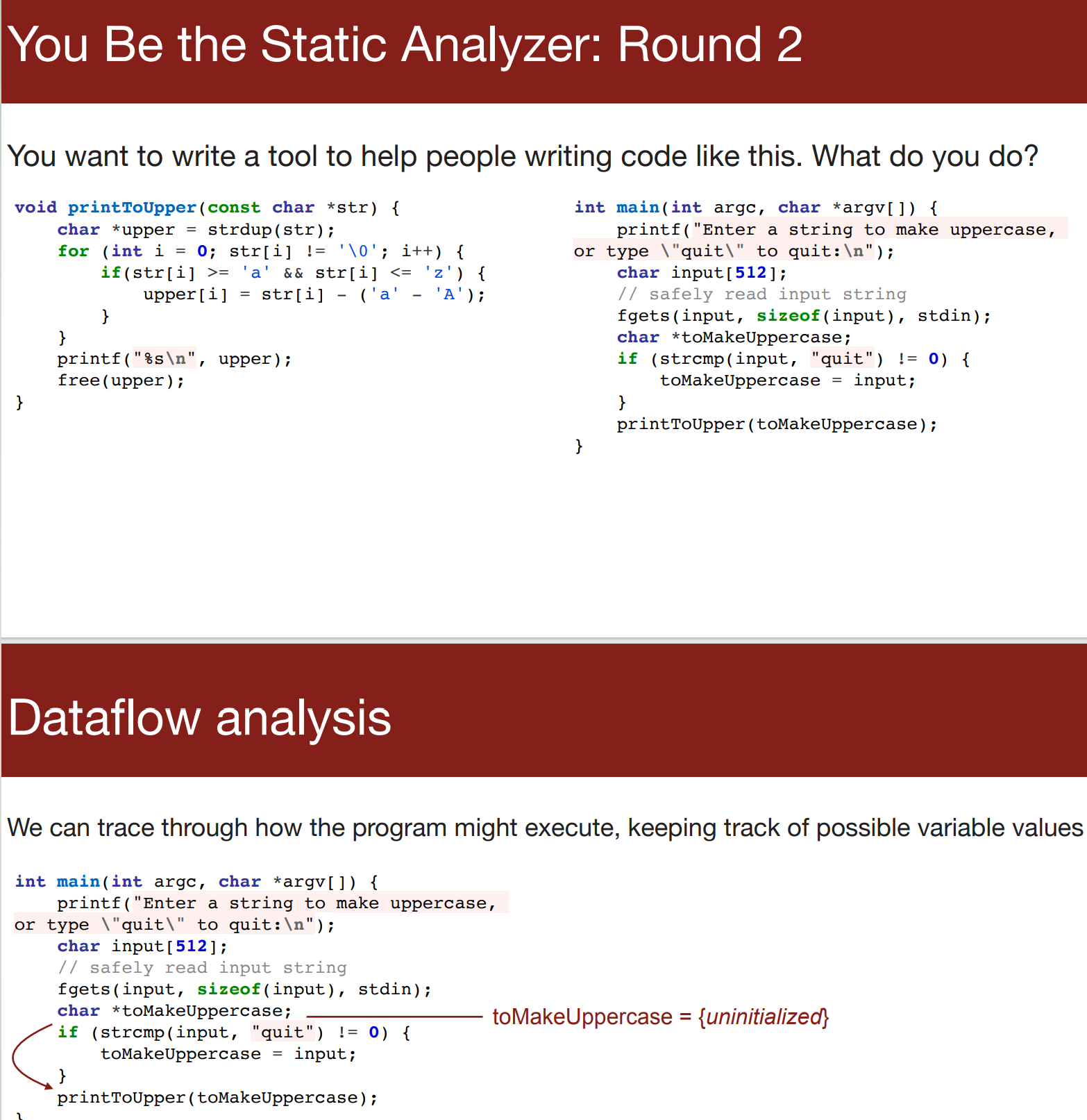
- 动态追踪数据的变化
![]()
- 在这里
toMakeUppercase可能是一个未初始化的值![]()
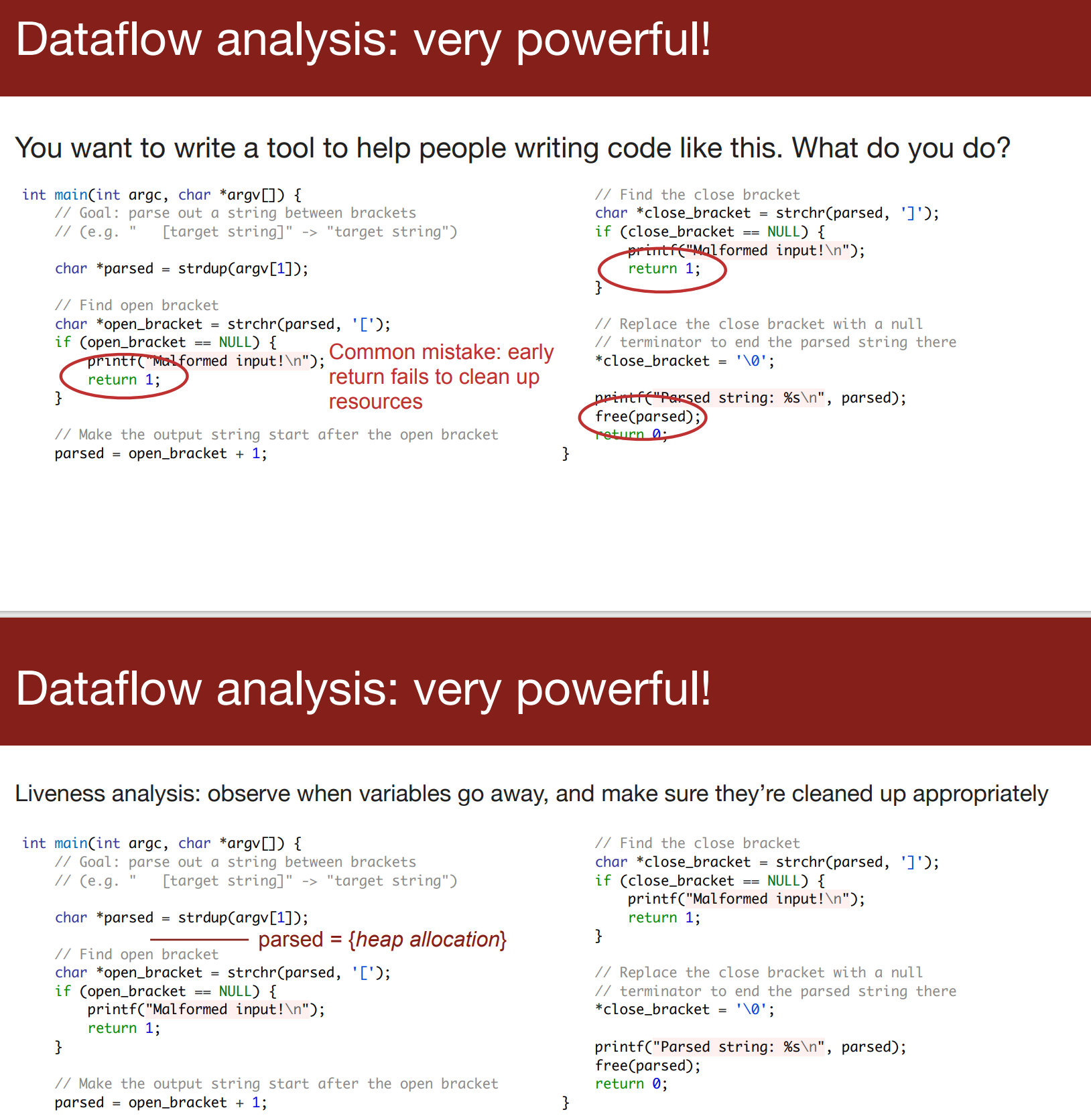
- if 语句(statement与expression的区别在于expression有值)多处返回造成的内存泄漏,RAII出现的原因
![]()
![]()
- call与if statement类似,会出现可能的leak of memory
![]()
- 在这里
- 静态分析存在false positives的缺点,也就是可能会把不可能的错误报出。以及代码中如果存在过多的分支以及条件判断,那么可能静态分析的性能会很低,这其中存在着一个效率与全面性的权衡,
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号